目录
- 1 SQL简介
- 2 MySQL基本语法
- 2.1 语法规则
- 2.2 数据类型
- 3 DDL
- 3.1 操作数据库
- 3.2 操作表
- 4 DML
- 4.1 添加数据
- 4.2 修改数据
- 4.3 删除数据
- 5 DQL
- 5.1 基础查询
- 5.2 条件查询
- 5.3 排序查询
- 5.4 聚合查询
- 5.5 分组查询
- 5.6 分页查询
1 SQL简介
SQL :Structured Query Language,结构化查询语言,简称 SQL,一门操作关系型数据库的编程语言,是定义操作所有关系型数据库的统一标准
SQL 的通用语法
- SQL 语句可以单行或多行书写,以分号结尾
- Mysql数据库的SQL语句不区分大小写,关键字建议使用大写
- 注释
- 单行注释:
-- 注释内容(和注释内容之间必须有空格)或者#注释内容(有没有空格都可以,且是 MySQL特有 的) - 多行注释:
/*注释内容*/
- 单行注释:
SQL语言主要分为:
DML:数据操作语言,对数据进行增加、修改、删除,如insert、update、deleteDQL:数据查询语言,用于对数据进行查询,如selectDDL:数据定义语言,进行数据库、表的管理等,如create、dropDCL:数据控制语言,进行授权与权限回收,如grant、revokeTPL:事务处理语言,对事务进行处理,包括begin transaction、commit、rollback
❗️注意:
- 对于程序员来讲,重点是数据的增、删、改、查,必须熟练编写 DQL、DML,能够编写DDL完成数据库、表的操作,其它操作如TPL、DCL了解即可.
2 MySQL基本语法
2.1 语法规则
- 别名尽量别有空格,用下划线连接,如果是有空格则要用双引号引起来别名
- sql 语言对大小写输入不敏感
- 关键字不能被缩写,也不能分行
- 各子句之间一定要分行写
- 使用缩进提高代码的可读性(如嵌套时)
2.2 数据类型
MySQL支持多种数据类型,可以分为三类:
- 数值
- 日期
- 字符串
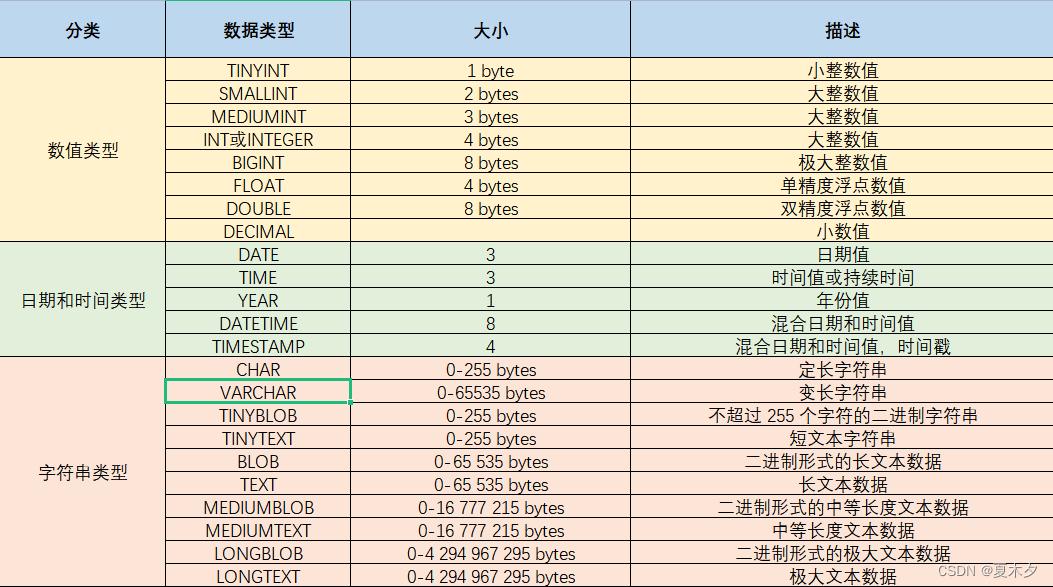
注意:
- 如果对分数设置
double型可以这样写:score double(总长度/总位数,小数点后保留的位数)- 对于
char()与varchar(),
char()是定长的,不足的部分用隐藏空格填充,会浪费空间;varchar()则是会记录字符串的实际大小,会更加节省空间- char查找效率会很高,varchar查找效率会更低。
CHAR:CHAR数据类型是固定长度的,这意味着每个CHAR列中的数据都具有相同的字符数。这使得在查找时,数据库系统可以更轻松地计算数据的位置,因为每个值都具有相同的大小。这可以提高查找效率。
VARCHAR:VARCHAR数据类型是可变长度的,不同行的数据长度可以不同。这使得在查找时需要更多的计算,因为数据库系统必须跟踪每个值的实际长度,这可能会导致查找效率略有降低。
3 DDL
DDL 是指操作数据库、表
3.1 操作数据库
- 查看 mysql 中有哪些数据库:
SHOW DATABASES;
- 使用指定名称的数据库:
USE 数据库名称;
- 创建数据库:
CREATE DATABASE [IF NOT EXISTS] 数据库名称;
IF NOT EXISTS: 加上该关键字库存在则不报错。如果没有该关键字库存在则报错。
CREATE DATABASE db1;
- 指定数据库的编码集:
CREATE DATABASE db2 CHARACTER SET 'gbk';
- 修改数据库的编码集:
ALTER DATABASE db1 CHARACTER SET 'utf8';
- 查看系统中的属性和值:
SHOW VARIABLES LIKE '%char%';
- 删除数据库:
DROP DATABASE [IF EXISTS] 数据库名称;
IF EXISTS: 加上该关键字库不存在则不报错。如果没有该关键字库不存在则报错。
DROP DATABASE db1;
- 查看当前使用的数据库:
SELECT DATABASE();
3.2 操作表
- 查看指定的数据库中有哪些数据表:
SHOW TABLES;
- 查看表的结构:
DESC 表名称;
- 查看表信息:
SHOW CREATE TABLE 表名称;
例如:
SHOW CREATE TABLE employees;
- 创建表
方式一:
CREATE TABLE [IF NOT EXISTS] 表名(
字段名1 类型1,
字段名2 类型2,
.....
字段名n 类型n
)CHARACTER SET '编码集';
❗️注意:
- 最后一行末尾不能加逗号
CREATE TABLE emp(
id INT,
ename VARCHAR(20)
);
#if not exists : 加上该关键字表存在则不报错。如果没有该关键字库表在则报错。
CREATE TABLE IF NOT EXISTS emp(
id INT,
ename VARCHAR(20)
);
CREATE TABLE emp(
id INT,
ename VARCHAR(20)
)CHARACTER SET 'gbk';
注意:表的默认的编码集和库的编码集一致。
方式二:基于查询结果创建一张新表
CREATE TABLE emp
AS
SELECT first_name,salary
FROM myemployees.employees; #库名.表名
方式三:基于现有的表结构创建一张新表(表中没有内容)
CREATE TABLE [IF NOT EXISTS] 表名 LIKE 库名.表名;
CREATE TABLE emp LIKE myemployees.employees;
- 删除表
DROP TABLE [IF EXISTS] 表名;
- 修改表的名字
ALTER TABLE 原表名 RENAME TO 新表名;
- 向表中添加列
ALTER TABLE 表名 ADD 列名 列的数据类型;
- 修改某一列的数据类型
ALTER TABLE 表名 MODIFY 列名 新的数据类型;
- 修改表中列名和数据类型
ALTER TABLE 表名 CHANGE 原列名 新列名 新列的数据类型;
- 删除表中的某一列
ALTER TABLE 表名 DROP 列名;
4 DML
DML 对表中的数据进行增、删、改
4.1 添加数据
- 给指定列添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);
- 给全部列添加数据(添加单行数据)
INSERT INTO 表名 VALUES(值1,值2,…);
- 批量添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
注意:
- 查询的字段的类型和个数要和被插入的字段的类型和个数保持一致
- 如果插入的是全字段那么可以省略表名后的字段名,但实际开发时不建议
4.2 修改数据
修改表数据
UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件];
修改语句中如果不加条件,则将所有数据都修改!
4.3 删除数据
删除数据
DELETE FROM 表名 [WHERE 条件] ;
删除语句中如果不加条件,则将所有数据都删除!
5 DQL
DML 对表中的数据进行查询
查询的完整语法
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组后条件
ORDER BY
排序字段
LIMIT
分页限定
已存在 stu 表如下
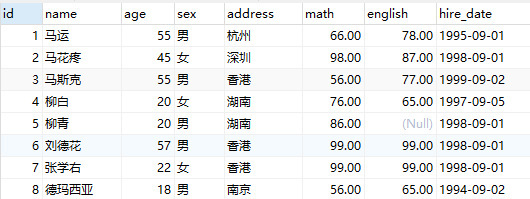
5.1 基础查询
- 查询多个字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名; -- 查询所有数据
- 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
- 起别名
AS
举例
SELECT name as 姓名,math as 数学成绩 FROM stu;
SELECT name 姓名,math 数学成绩 FROM stu; -- AS也可以省略
5.2 条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件列表可以使用以下运算符
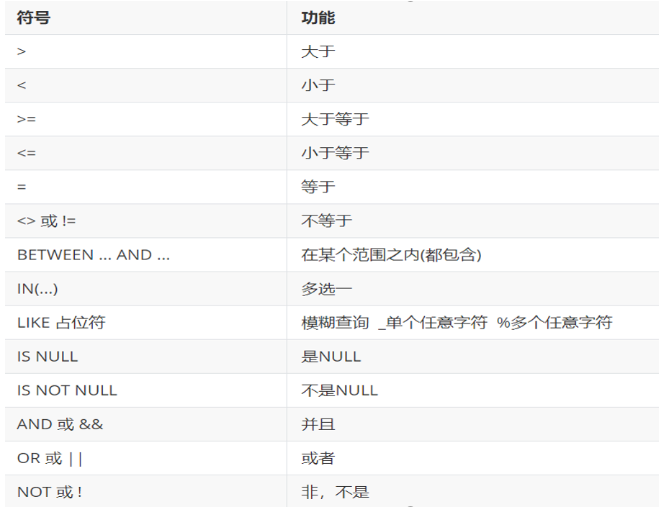
示例代码
-- 1. 查询年龄大于20岁的学员信息
select * from stu where age > 20;
-- 2. 查询年龄大于等于20岁 并且 年龄 小于等于 30岁 的学员信息
-- && 和 and 都表示并且的意思。建议使用 and
-- 也可以使用 between ... and 来实现该需求
select * from stu where age >= 20 && age <= 30;
select * from stu where age >= 20 and age <= 30;
select * from stu where age BETWEEN 20 and 30;
-- 3. 查询入学日期在'1998-09-01' 到 '1999-09-01' (日期类型)之间的学员信息
select * from stu where hire_date BETWEEN '1998-09-01' and '1999-09-01';
-- 4. 查询年龄等于18岁的学员信息
-- 注意不能使用==
select * from stu where age = 18;
-- 5. 查询年龄不等于18岁的学员信息
select * from stu where age != 18;
select * from stu where age <> 18;
-- 6. 查询年龄等于18岁 或者 年龄等于20岁 或者 年龄等于22岁的学员信息
select * from stu where age = 18 or age = 20 or age = 22;
select * from stu where age in (18,20 ,22);
-- 7. 查询英语成绩为(不为) null的学员信息
-- null值的比较不能使用 = 或者 != ,需要使用 is 或者 is not
-- select * from stu where english = null; -- 这个语句是不行的
select * from stu where english is null;
select * from stu where english is not null;
模糊查询 使用 like关键字,可以使用通配符进行占位:
_: 代表单个任意字符%: 代表多个任意字符\:转义字符escape:指定转义字符
示例代码
-- 1. 查询姓'马'的学员信息
select * from stu where name like '马%';
-- 2. 查询第二个字是'花'的学员信息
select * from stu where name like '_花%';
-- 3. 查询名字中包含 '德' 的学员信息
select * from stu where name like '%德%';
5.3 排序查询
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
上述语句中的排序方式有两种,分别是:
ASC: 升序排列 (默认值)DESC: 降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
示例代码
-- 1. 查询学生信息,按照年龄升序排列
select * from stu order by age asc;
select * from stu order by age ; -- asc可省略
-- 2. 查询学生信息,按照数学成绩降序排列
select * from stu order by math desc ;
-- 3. 查询学生信息,按照数学成绩降序排列,如果数学成绩一样,再按照英语成绩升序排列
select * from stu order by math desc , english asc ;
select * from stu order by math desc , english;
5.4 聚合查询
聚合:将一列数据作为一个整体,进行纵向计算。
SELECT 聚合函数名(列名) FROM 表;
聚合函数分类
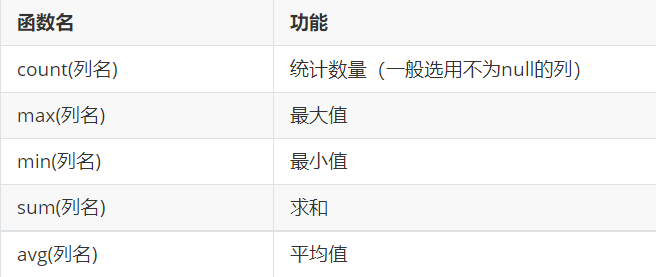
注意:
null值不参与所有聚合函数运算
示例代码
-- 1. 统计班级一共有多少个学生
select count(*) from stu;
select count(id) from stu; -- 8
select count(english) from stu; -- 7,有一个学生的英语成绩为null
/*
上面语句根据某个字段进行统计,如果该字段某一行的值为null的话,将不会被统计。
所以count()里面的字段一般取主键或者*,
其中count(*)表示一行中只有有一个字段不为null,就会被统计。
*/
-- 2. 查询数学成绩的最高分
select max(math) from stu;
-- 3. 查询数学成绩的最低分
select min(math) from stu;
-- 4. 查询数学成绩的总分
select sum(math) from stu;
-- 5. 查询数学成绩的平均分
select avg(math) from stu;
-- 6. 查询英语成绩的最低分
select min(english) from stu; -- 不统计null
5.5 分组查询
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
示例代码
-- 1. 查询男同学和女同学各自的数学平均分
-- 分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
select sex, avg(math) from stu group by sex;
-- 2. 查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math),count(*) from stu group by sex;
-- 3. 查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组
select sex, avg(math),count(*) from stu where math > 70 group by sex;
-- 4. 查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
注意:
- 分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
- where 和 having 区别:
- 执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
- 可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
- 执行顺序:
where>聚合函数>having
5.6 分页查询
大家在很多网站都见过分页的效果,如京东、百度、淘宝等。分页查询是将数据一页一页的展示给用户看,用户也可以通过点击查看下一页的数据。
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询条目数;
注意: 上述语句中的起始索引是从0开始,是针对数据条目
示例代码
-- 1. 从0开始查询,查询3条数据
select * from stu limit 0 , 3;
-- 2. 每页显示3条数据,查询第1页数据
select * from stu limit 0 , 3;
-- 3. 每页显示3条数据,查询第2页数据
select * from stu limit 3 , 3;
-- 4. 每页显示3条数据,查询第3页数据
select * from stu limit 6 , 3;
从上面的练习推导出起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数
注意:分页查询
limit是Mysql特有的,Oracle分页查询使用的是rownumber,SQL Server使用的是top








![js 异常数组 [空白,Array(10),空白,Array(10),空白]](https://img-blog.csdnimg.cn/cf9592a178694837b4c40003032b6b38.png#pic_center)