参考:https://www.youtube.com/watch?v=mlk0rddP3L4&list=PLuhqtP7jdD8CftMk831qdE8BlIteSaNzD
视频3:什么是激活函数?为什么我们需要激活函数?它的类型有哪些?
为什么需要激活函数?如果没有激活函数,那么神经网络的向前传播就会变成线性的。一个隐藏层和多个隐藏层实际上没有区别,如下图

因此,我们需要 非线性 的激活函数。(除了上面的原因,还有一个原因,那就是现实世界,一个物品的特征之间的关系通常也是非线性的,所以要用非线性的激活函数才能更好的去模拟它们)
接下来介绍激活函数的类型,首先是 sigmoid 函数,如下图
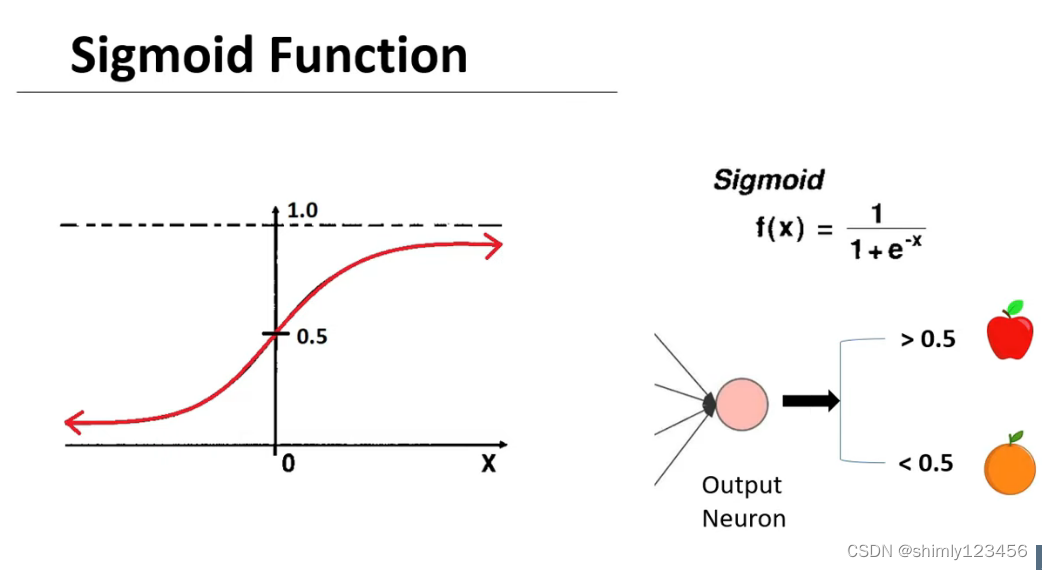
sigmoid 函数的特点是,定义域是负无穷到正无穷,而值域是 (0, 1)
sigmoid 函数很适合用来作为 二元分类 模型的 output nero 的激活函数。
但 sigmoid 函数不适合用作 隐藏层 的激活函数
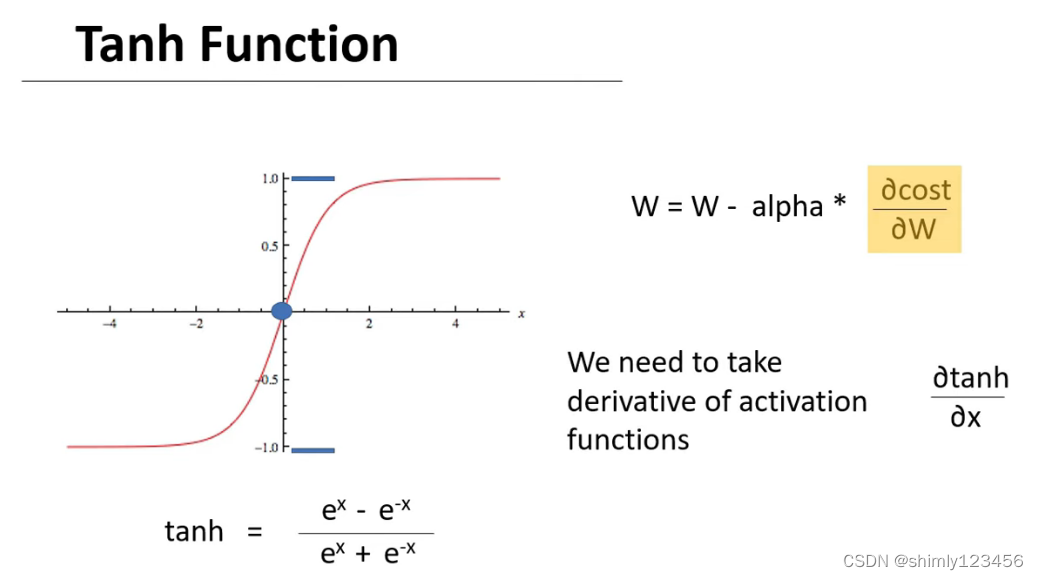
随后是 Tanh 函数,如下图
当我们在用梯度下降法做训练时,我们会计算激活函数的导数,下图是 sigmoid 和 tanh 的导数图像
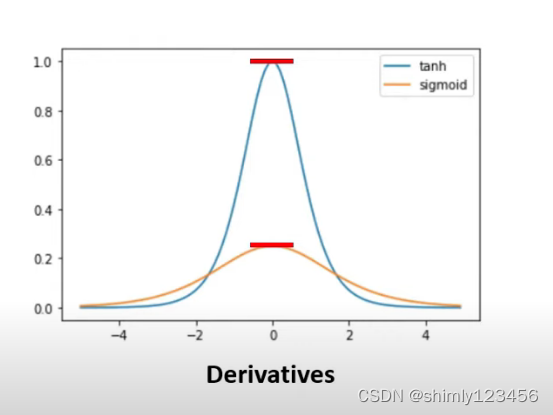
可以看到 tanh 的斜率变化远强于 sigmoid,因此使用 tanh 作为隐藏层的激活函数,模型训练速度会比 sigmoid 快很多
tanh 还有其它好的特性,那就是它的输出值是 (-1, 1)。相当于一个自动的 ”正则化“。这样一来在训练时,隐藏层之间的数据传输会简单很多。
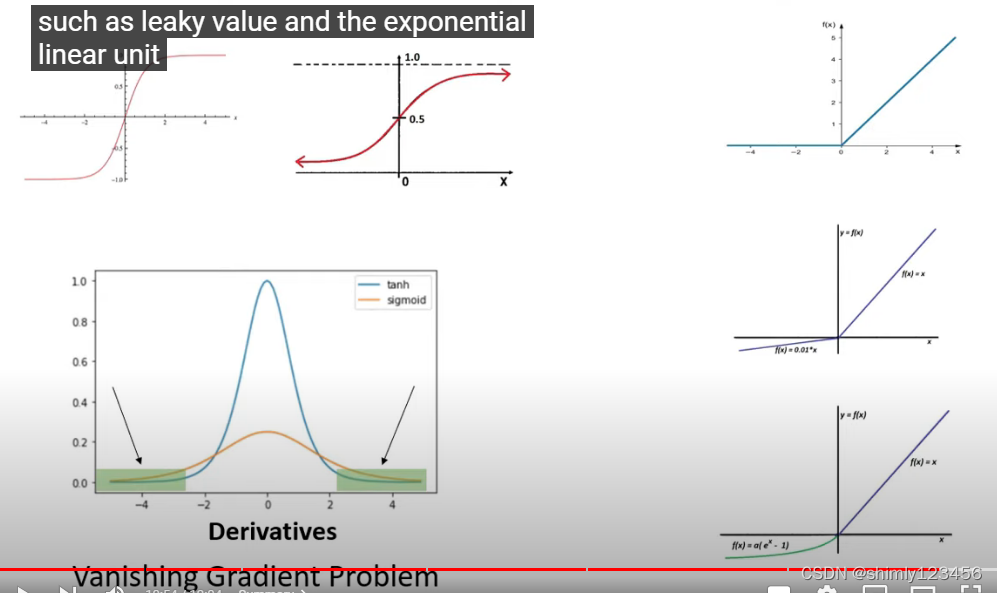
不过 tanh 也有缺点,从导数图像来看,当 x 的绝对值大时,斜率很低,这会导致训练速度极其缓慢,这也叫做 ”vanishing gradient problem“
为了解决 vanishing gradient problem,我们提出了下面这种激活函数 ReLU 函数
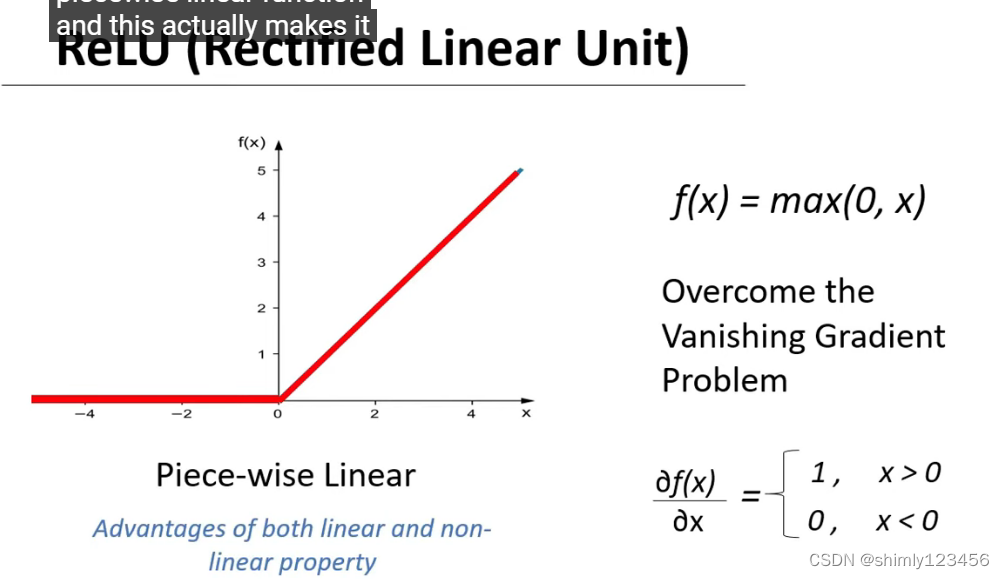
tanh 是 piece-wise linear,因此它包含了 Linear 和 non-linear 的性质和优势
TODO:感觉这里有问题,如果 x > 0 则 f(x) = x,那感觉后边会出现 “线性退化”
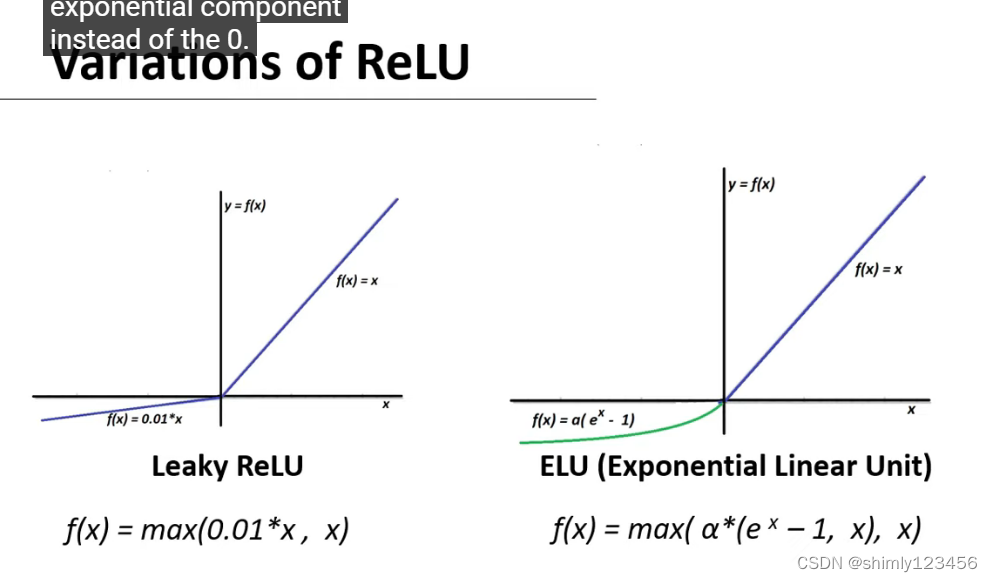
以下是 ReLU 的变种
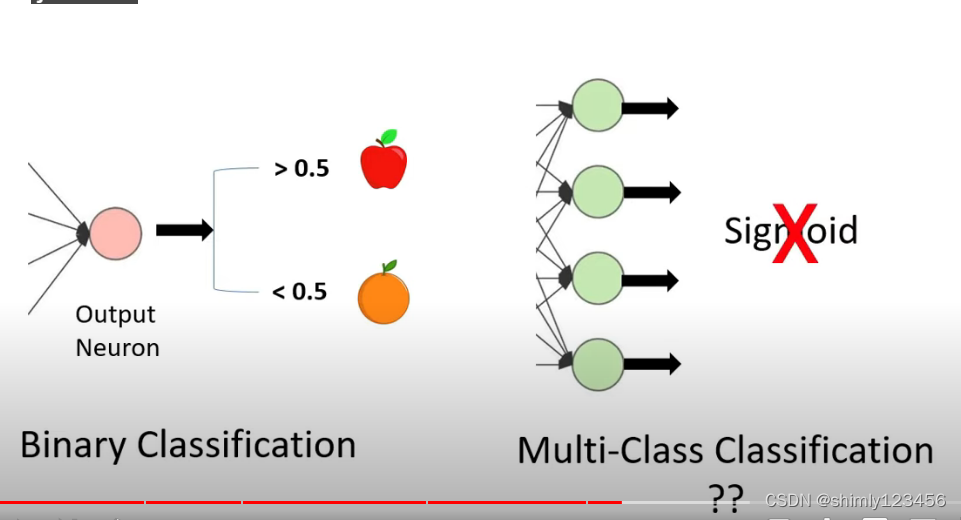
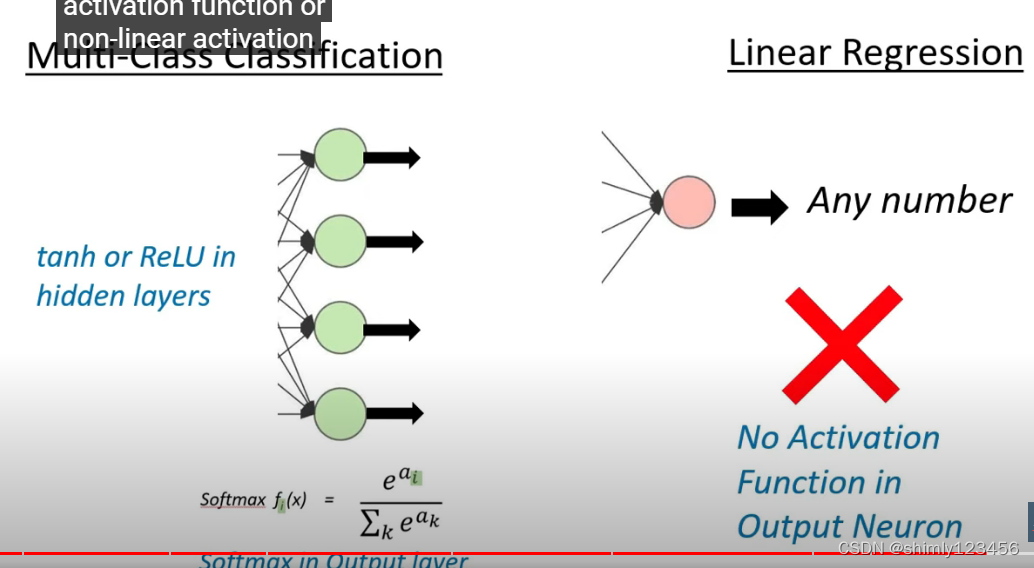
在遇到多分类问题的时候,我们不能使用 sigmoid 函数,它不合适
适用于多分类问题的激活函数是 softmax 函数,如下图
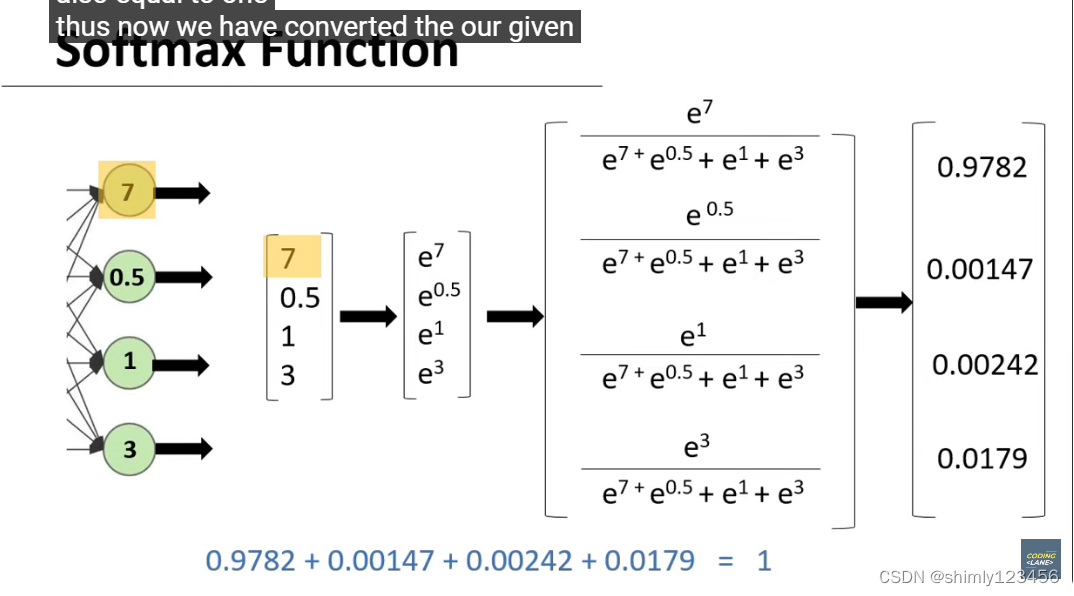
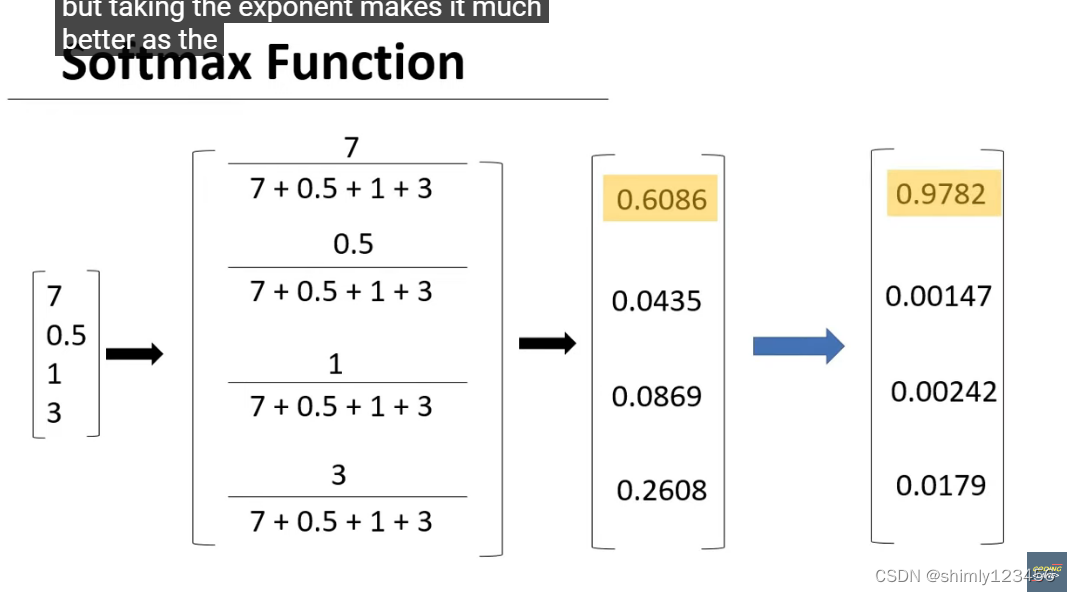
如上图,使用 e^x 的原因是,指数函数会随着 x 的增加爆炸性增长,从而让我们的最大可能性的可能性变得更加突出
如下图是 softmax 函数的一个更加严格的定义

在面对回归问题的时候,通常我们不对 output neuron 使用任何激活函数

接下来做个总结
对于二元分类问题,我们通常使用 sigmoid 函数作为 output neuron 的激活函数,而使用 ReLU/tanh 作为隐藏层的激活函数,如下图
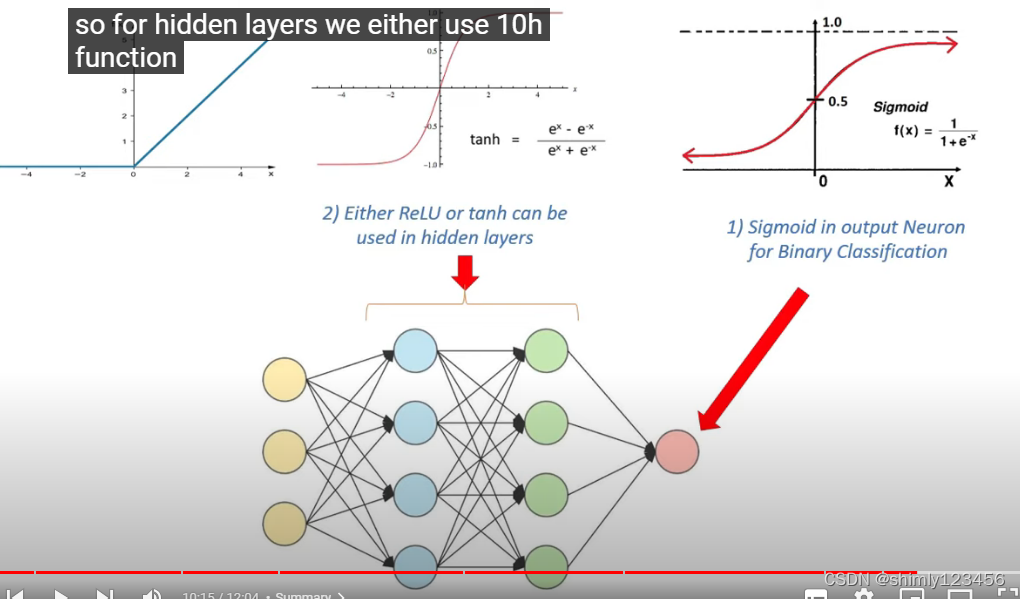
sigmoid 和 tanh 都有一个问题:vanishing gradient problem。这个问题可以由 ReLU 函数解决,ReLU 函数还有很多变种
在解决多分类问题的时候,我们通常使用 tanh/ReLU 作为隐藏层的激活函数,使用 Softmax 作为 output layer 的激活函数
而面对回归问题时,通常 output layer 没有激活函数
视频4:TODO
TODO: here