高级特性篇(十)
多进程
多进程就是指通过应用程序利用计算机的多核资源达到同时执行多个任务的目的,以此来提升程序的执行效率
import os
from multiprocessing import Process
def hello(name):
#获取当前进程
#os.getpid()
print('process {}'.format(os.getpid()))
print('hello '+name)
#hello('world')
def main():
#main()函数就运行再主进程中
print('process {}'.format(os.getpid()))
#process对象他是一个子任务,运行的时候会自动创建一个子进程
#参数 args 是一个元组
p = Process(target=hello,args=('world',))
print('child process start')
#开始子进程
p.start()
#阻塞主进程,直到子进程终止
p.join()
print('child process stop')
if __name__ == '__main__':
main()
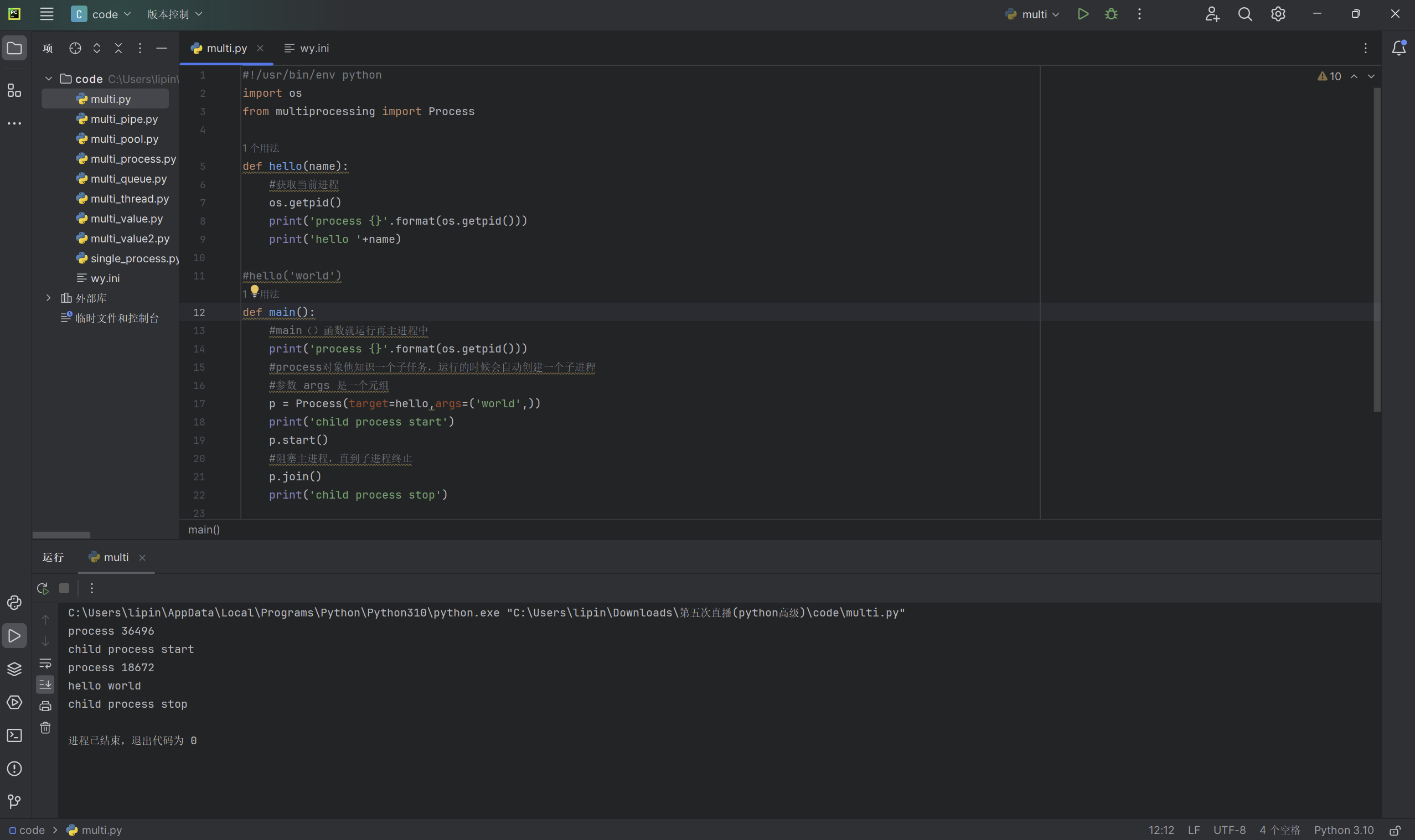
process对象他是一个子任务,运行的时候会自动创建一个子进程,参数 args 是一个元组,我们可以通过它进行传参。我们运行代码时,通过Process创建了一个子进程 p,这个子进程 p 运行hello()函数,我们的main()函数在作为主进程运行时,同时运行了hello()子进程。以上代码输出的实列:
接下来,我们再来看一个实例
import time
from multiprocessing import Process
def io_task():
print("-")
# 挂起当前进程1秒
time.sleep(1)
def main():
#获取开始程序时的时间
start_time = time.time()
process_list = []
for i in range(10):
process_list.append(Process(target=io_task))
for pro in process_list:
pro.start()
for pro in process_list:
pro.join()
#获取结束程序时的时间
end_time = time.time()
#获得程序运行的时间
print('程序运行耗时 {:.2f}'.format(end_time - start_time))
if __name__ == '__main__':
main()
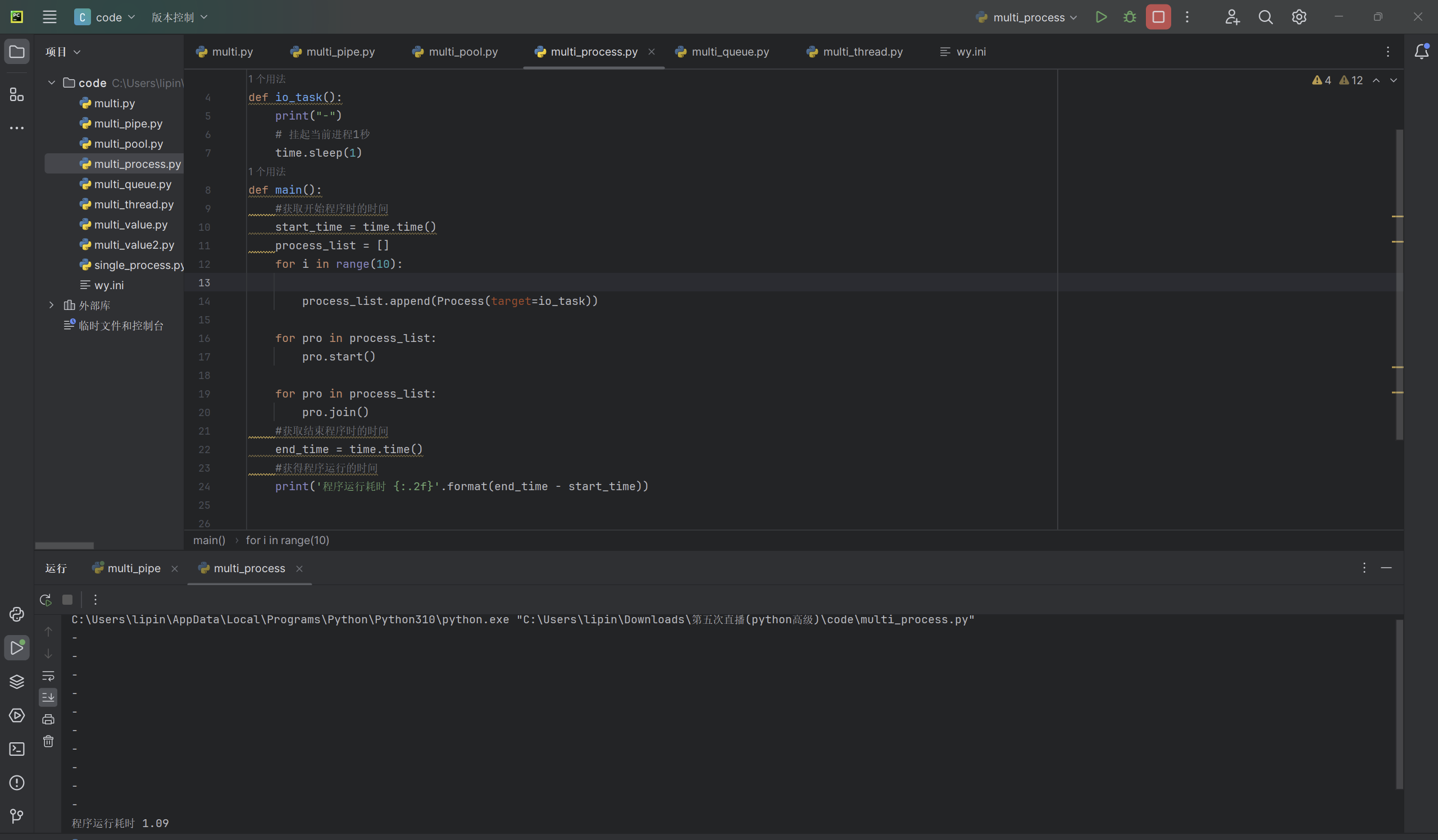
我们定义了一个函数io_task(),这个函数的作用是输出一个“-”并休眠一秒,我们在主进程main()函数中通过for循环Process创建了十个运行io_task()函数的子进程,然后最后在输出整体程序运行的时间,我们可以通过修改for循环的次数,会发现无论我们创建了一个子进程还是十个子进程,程序整体运行的消耗时间变化不大,以上代码的实列输出:
进程通信
进程有自己独立的运行空间,它们之间所有的变量、数据是隔绝的,A进程中的变量与B进程的变量是没有任何关系,这就意味要使用一些特殊的手段才能实现它们之间的数据交换。
接下来我们介绍一种使用管道进行子进程之间通讯的方式
from multiprocessing import Process,Pipe
#创建管道
conn1,conn2 = Pipe()
def send():
data = 'handsome wuyue'
#发送数据
conn1.send(data)
print('Send Data: {}'.format(data))
def recv():
#接收数据
data = conn2.recv()
print('Receive Data: {}'.format(data))
def main():
#创建子进程
Process(target=send).start()
Process(target=recv).start()
if __name__ == '__main__':
main()
首先我们通过Pipe()函数创建了一个管道,并将其赋予了两个变量conn1和conn2,conn1是管道的一端,conn2是管道的另一端。然后我们定义了一个函数send(),通过conn1.send()这个方法去发送数据,然后我们定义了一个函数recv(),通过conn2.recv()接收了conn1.send()这个方法发送来的数据,然后再main()函数主进程中通过Process对象创建了两个子进程,这样我们就完成了两个进程之间的通信:

接下来我们再来看看使用队列进行子进程通讯的方式
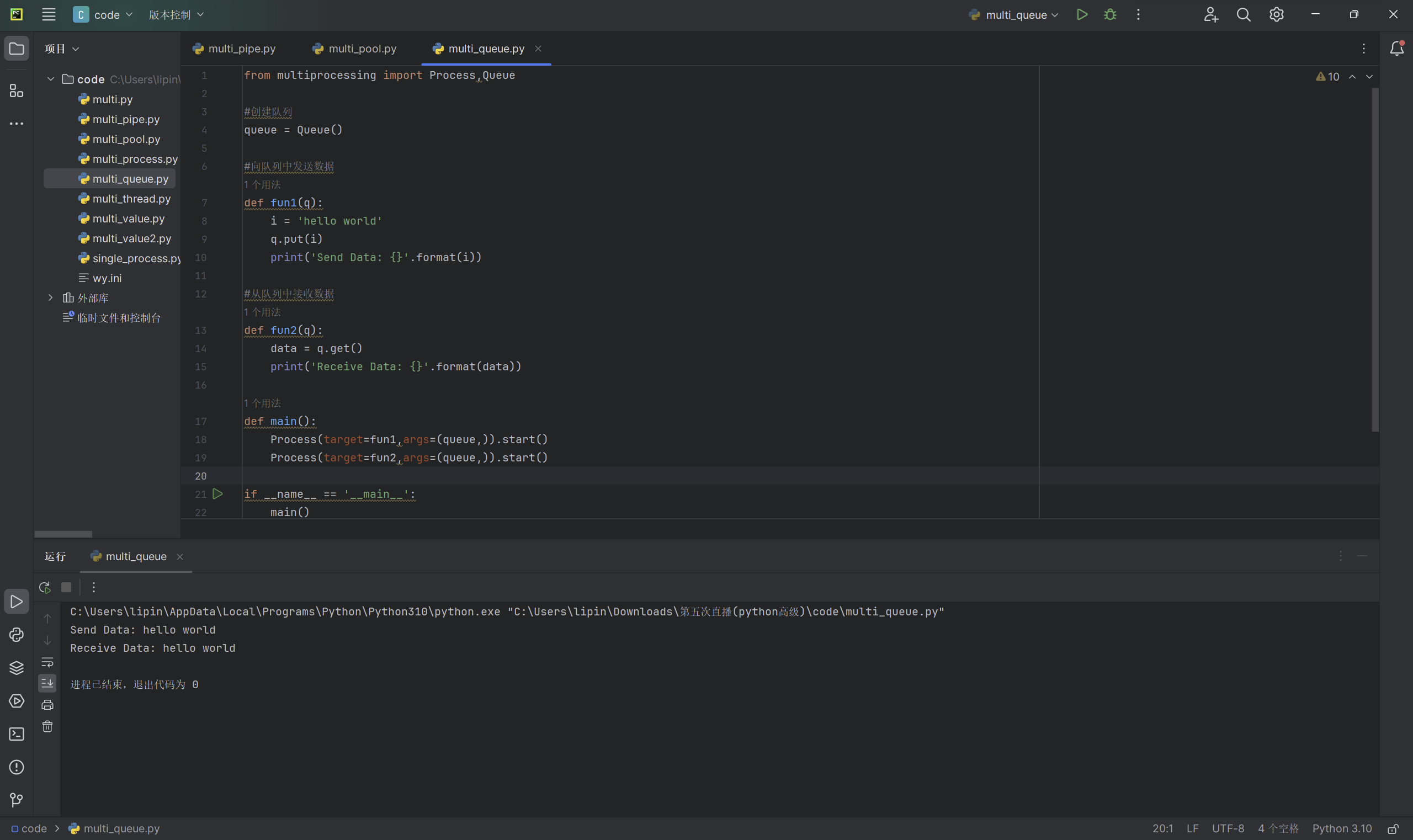
from multiprocessing import Process,Queue
#创建队列
queue = Queue()
#向队列中发送数据
def fun1(q):
i = 'hello world'
q.put(i)
print('Send Data: {}'.format(i))
#从队列中接收数据
def fun2(q):
data = q.get()
print('Receive Data: {}'.format(data))
def main():
Process(target=fun1,args=(queue,)).start()
Process(target=fun2,args=(queue,)).start()
if __name__ == '__main__':
main()
首先我们通过 Queue()创建了一个队列,然后去定义了一个函数fun1,通过put()方法像队列中发送数据,然后在定义了一个函数fun2,通过get()的方法从队列中接受数据,最后再主进程中,通过Process创建了两个子进程对象,其接收的实参都是queue这个队列,这样我们就实现了通过队列完成子进程之间数据通信:
进程锁
在python的多线程和多进程中,当我们需要对多线程或多进程的共享资源或对象进行修改操作时,往往会出现因cpu随机调度而导致结果和我们预期不一致的问题,这时就需要对线程或者进程加锁,以保证一个线程或进程在对共享对象进行修改时,其他的线程或进程无法访问这个对象,直至获取锁的线程的操作执行完毕后释放锁。所以,锁在多线程和多进程中起到一个同步的作用,以保护每个线程和进程必要的完整执行。
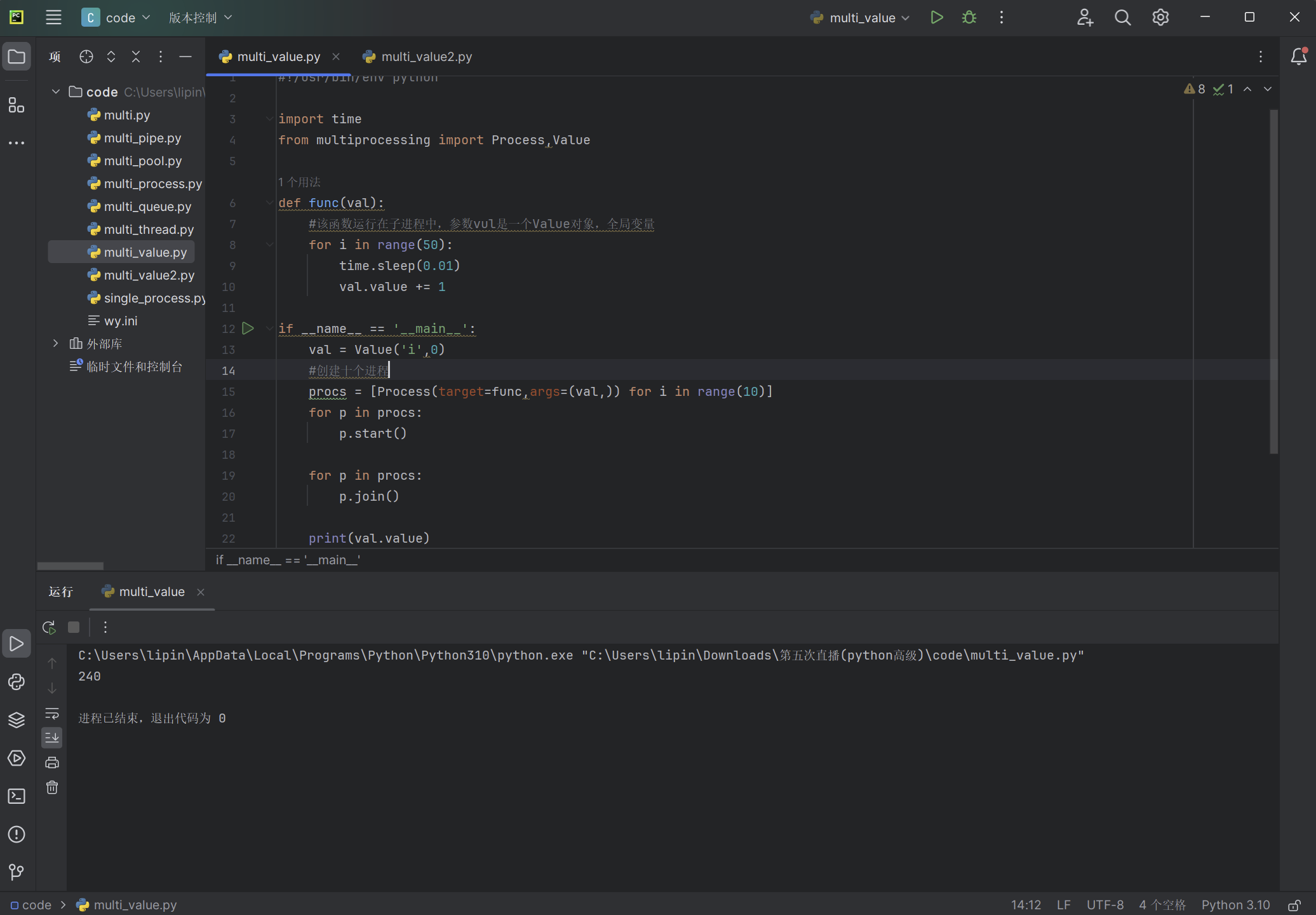
import time
from multiprocessing import Process,Value
def func(val):
#该函数运行在子进程中,参数vul是一个Value对象,全局变量
for i in range(50):
time.sleep(0.01)
val.value += 1
if __name__ == '__main__':
val = Value('i',0)
#创建十个进程
procs = [Process(target=func,args=(val,)) for i in range(10)]
for p in procs:
p.start()
for p in procs:
p.join()
print(val.value)
val.value是一个全局变量,我们循环五十次每次给这个变量加一,然后我们创建了十个子进程,这十个子进程都在改变着这个变量,也就是说A进程在改变这个变量时,B进程也可能在改变着这个变量,这导致了,每次输出的这个全局变量是不同的,通过以上代码的输出,可以看到我们每次运行时val.value的数量都是不一样的:
接下来,我们稍微改变一下这串代码,来给它加上进程锁
from multiprocessing import Process,Value,Lock
#正确的做法是每次进行+1操作的时候,为i加上一把锁
def func(val,lock):
#该函数运行在子进程中,参数vul是一个Value对象,全局变量
for i in range(50):
time.sleep(0.01)
#加锁
lock.acquire()
val.value += 1
#释放锁
lock.release()
if __name__ == '__main__':
val = Value ('i',0)
lock = Lock()
#创建十个进程
procs = [Process(target=func,args=(val,lock)) for i in range(10)]
for p in procs:
p.start()
for p in procs:
p.join()
print(val.value)
我们在每次进行+1操作的时候,为i加上一把锁,当val.value这个全局变量每次被增加一后,我们释放这个锁,然后我们在main()函数中创建了十个子进程,会发现每次我们输出的val.value这个全局变量的数量都被固定在500了:
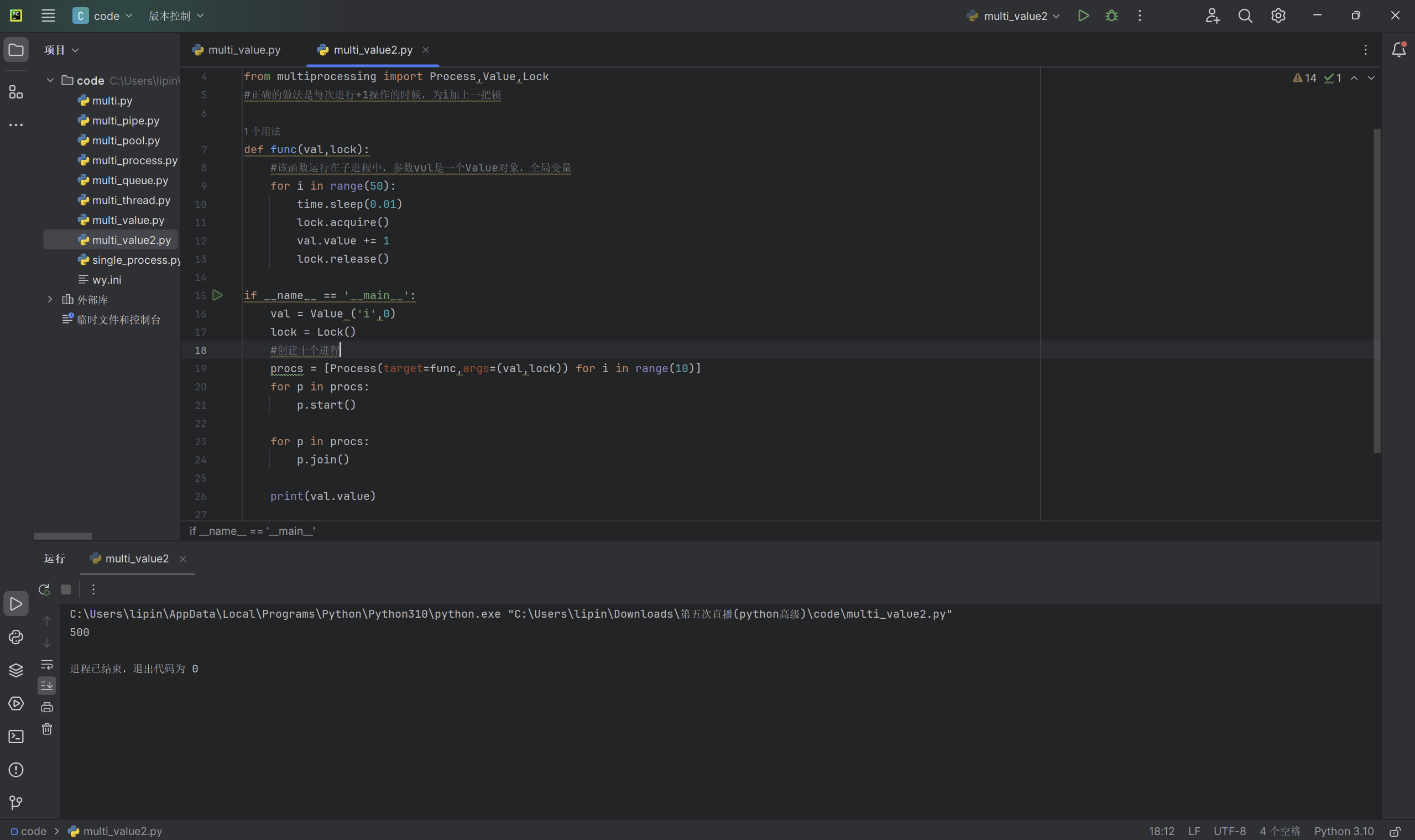
进程池
进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要扽会给带之前的进程任务执行完毕归来,拿到空闲进程才能继续执行。也就是说,池中的进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
from multiprocessing import Pool
#任务在子进程中运行
def task(name):
#打印进程 id
print('process {} 启动运行, id: {}'.format(name,os.getpid()))
start_time = time.time()
#假设有个比较费时的操作
#生成一个随机数
time.sleep(random.random() * 3)
end_time = time.time()
print('任务{}结束运行,耗时: {:.2f}秒'.format(name,(end_time-start_time)))
if __name__ == '__main__':
print('当前是主进程,id {}'.format(os.getpid()))
print('==========================================')
p = Pool(4)
for i in range(1,6):
#异步方式启动进程池
#池子内的进程随机接收任务,直到所有的任务完成
p.apply_async(task,args=(i,))
p.close()
print('开始运行子进程')
p.join()
print('==============================================')
print('子进程运行完毕,当前是主进程,id :{}'.format(os.getpid()))
以上代码输出的实例:
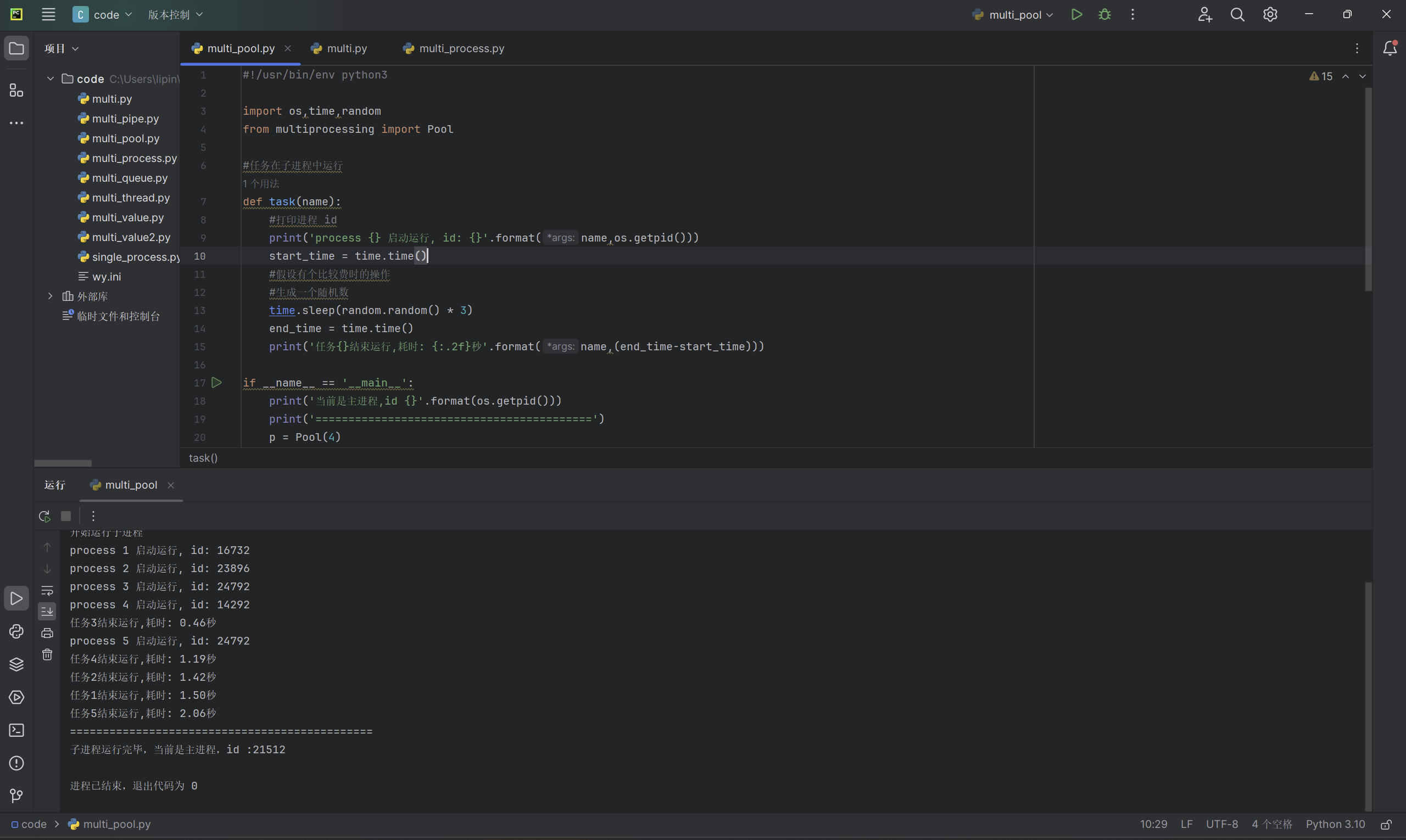
多线程
线程是CPU分配资源的基本单位。当一程序开始运行,这个程序就变成了一个进程,而一个进程相当于一个或者多个线程。当没有多线程编程时,一个进程就相当于是一个主线程;当有多线程编程时,一个进程包含多个线程(含主线程)。使用线程可以实现程序大的开发。
多个线程可以在同一个程序中去运行,并且每一个线程完成不同的任务。多线程实现后台服务程序可以同时处理多个任务,并不发生阻塞的现象。多线程的程序设计的特点就是能够提高程序执行的效率和处理速度。
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
-
使用线程可以把占据长时间的程序中的任务放到后台去处理。
-
用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
-
程序的运行速度可能加快。
-
在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
-
线程可以被抢占(中断)。
-
在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
-
_thread
-
threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
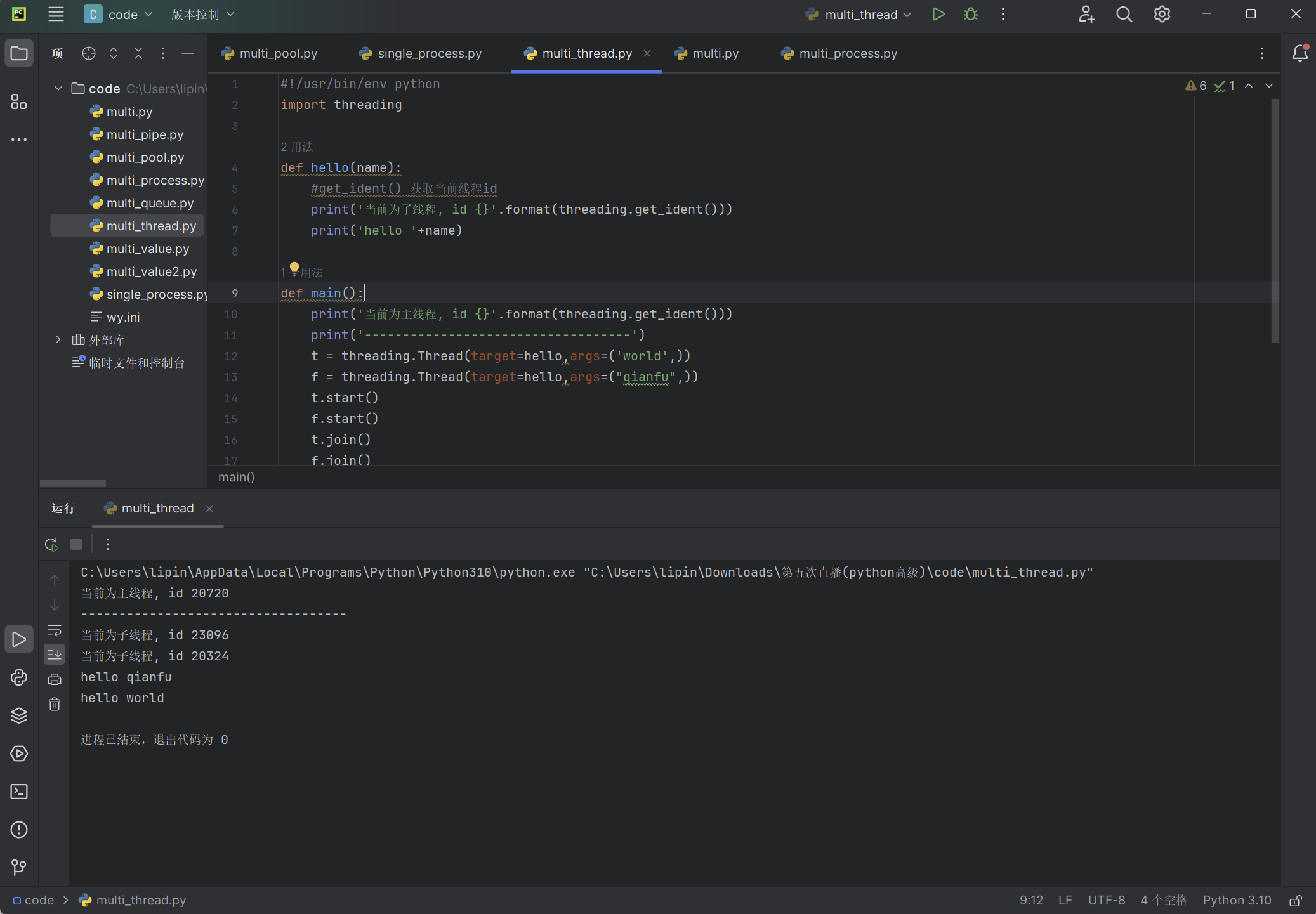
import threading
def hello(name):
#get_ident() 获取当前线程id
print('当前为子线程, id {}'.format(threading.get_ident()))
print('hello '+name)
def main():
print('当前为主线程, id {}'.format(threading.get_ident()))
print('-----------------------------------')
t = threading.Thread(target=hello,args=('world',))
f = threading.Thread(target=hello,args=("qianfu",))
t.start()
f.start()
t.join()
f.join()
if __name__ == '__main__':
main()
执行以上程序输出结果如下: