概述
目标:
- 栈存储结构与特点
- 基于数组实现栈
- 基于单链表实现栈
- 刷题(有效的括号)
存储结构与特点
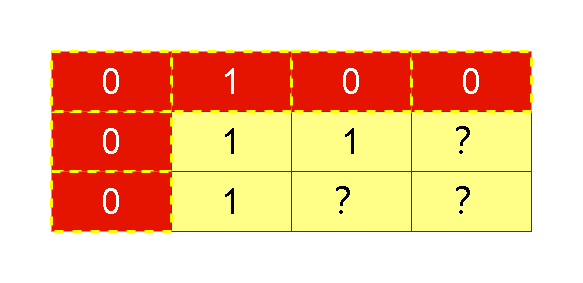
栈(Stack)并非指某种特定的数据结构,它是有着相同典型特征的一数据结构的统称,因为栈可以用数组实现,也可以用链表实现,典型的特征是:后进先出,Last In First Out 即 LIFO,只要满足这种特点的数据结构,可以说这是栈,为了理解这种数据结构,如下图

从栈的操作特点上来看,栈就是一种操作受限的线性表,只允许在栈的一端进行数据的插入和删除,这两种操作分别叫做入栈(push)和出栈(pop),时间复杂度均为O(1)
- 此处说的栈和
java语言中的栈空间不是一回事,此处的栈指的是一种数据,而java语言中的栈空间指的是java内存结构的一种表示,不能等同 - 栈操作虽受限,但当某个数据集合如果只涉及到,在其一端进行数据的插入与删除操作,并且满足
先进后出,后进先出的特性时,应首选栈这种数据结构来进行数据的存储
栈的实现
栈既可以数组实现,也可以用链表实现,用数组实现的栈叫顺序栈,用链表实现的叫链式栈
功能如下:
- 返回栈中元素个数
- 判断栈是否为空
- 将元素压入栈
- 获取栈顶元素,但并不移除,如果栈为空,则返回
null - 移除栈顶元素并返回,如果栈为空,则返回
null
数组实现栈
目标:
- 基于数组实现一个栈,满足以上定义的方法
- 基于数组的栈,要支持动态扩容
代码如下:
package com.example.demo.data;
import java.util.Arrays;
public class Stack<E> {
// 存储数据的数组
public E[] elementData;
// 栈中元素的个数
public int size;
/**
* 指定初始化大小
*
* @param initCapacity 初始化值
*/
public Stack(int initCapacity) {
this.elementData = (E[]) new Object[initCapacity];
}
/**
* 默认构造 栈大小 10
*/
public Stack() {
this(10);
}
/**
* 返回栈中元素个数
*/
public int size() {
return this.size;
}
/**
* 判断栈是否为空
*/
public boolean empty() {
return this.size == 0;
}
/**
* 将元素压入栈
*/
public E push(E item) {
// 压入栈之前判断一下当前的是否还有空间
ensureCapacity(size + 1);
// 注意 size++ 后置加法 ,就是此行执行完,才加1
this.elementData[size++] = item;
return item;
}
/**
* 获取栈顶元素,但并不移除,如果栈空则返回null
* 在数组中即最后位置的数据
*/
public E peek() {
if (empty()) {
return null;
}
return elementAt(size - 1);
}
/**
* 移除栈顶元素并返回
*/
public E pop() {
E peek = peek();
removeElementAt(size - 1);
return peek;
}
private void removeElementAt(int index) {
if (index < 0 || index >= this.elementData.length) {
throw new IndexOutOfBoundsException("下标越界!");
}
// 栈中元素个数减一
size--;
this.elementData[index] = null;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("[");
for (int i = 0; i < this.size; i++) {
sb.append(this.elementData[i]);
if (i < this.size - 1) {
sb.append(",");
}
}
sb.append("]");
return sb.toString();
}
private E elementAt(int index) {
if (index < 0 || index >= this.size) {
throw new ArrayIndexOutOfBoundsException("下标越界!");
}
return this.elementData[index];
}
private void ensureCapacity(int minCapacity) {
if (minCapacity > this.elementData.length) {
grow(minCapacity);
}
}
private void grow(int minCapacity) {
int oldCapacity = this.elementData.length;
// 增加原来一半的量,要注意 oldCapacity =1 的情况
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity < minCapacity) {
newCapacity = minCapacity;
}
this.elementData = Arrays.copyOf(this.elementData, newCapacity);
}
}
测试类如下:
public class StackTest {
public static void main(String[] args) {
Stack stack = new Stack();
System.out.println("栈中元素个数:" + stack.size() + ",栈是否为空:" + stack.empty());
//元素入栈
stack.push(1);
stack.push(3);
stack.push(5);
stack.push(7);
System.out.println("栈中元素个数:" + stack.size() + ",栈是否为空:" + stack.empty());
System.out.println("打印输出栈:" + stack);
System.out.println("栈顶元素为:" + stack.peek());
System.out.println("元素出栈" + stack.pop());
System.out.println("打印输出栈" + stack);
}
}
链表实现栈

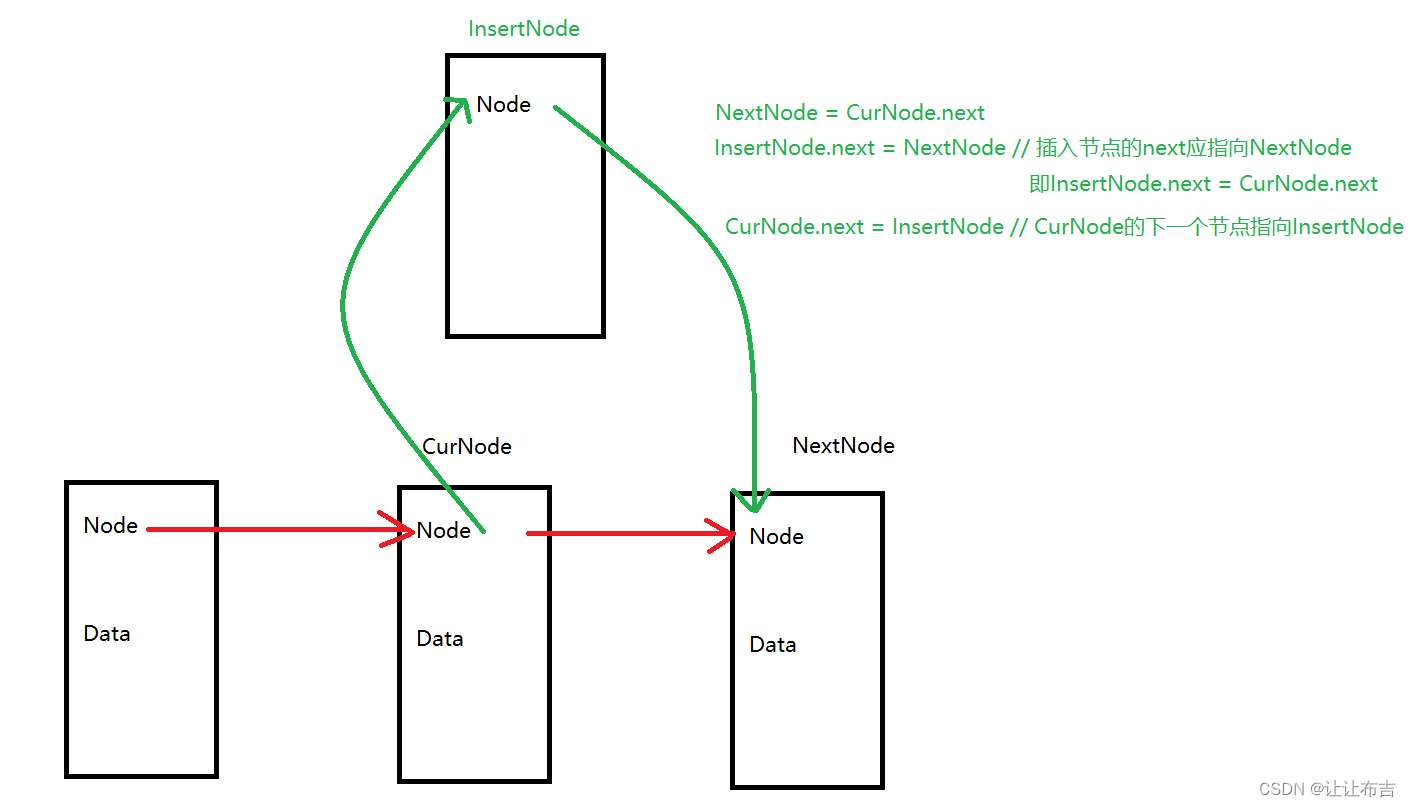
由上图:因为是单向链表,如查每次元素入栈将其添加到链表尾的话(相当于将链表尾当栈顶),后面在进行出栈要删除栈顶元素时,没办法找到它的前一个元素,因此将链表头节点当作栈顶
public class LinkedListStack<E> {
// 栈中元素个数
int size;
// 栈顶指针,链表头结点指针
Node<E> head;
/**
* 返回栈中元素个数
*/
public int size() {
return this.size;
}
/**
* 判断栈是否为空
*/
public boolean empty() {
return this.size == 0;
}
public E push(E item) {
Node<E> node = new Node<>(item, head);
head = node;
size++;
return item;
}
public E peek(){
if (head == null) {
return null;
}
return head.val;
}
public E pop() {
if (head == null) {
return null;
}
Node<E> top = head;
head = head.next;
top.next = null;
return top.val;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Node cur = head;
while (cur != null) {
sb.append(cur.val).append("->");
cur = cur.next;
}
sb.append("null");
return sb.toString();
}
/**
* 定义单链表节点类
*
* @param <E>
*/
private static class Node<E> {
E val;
Node<E> next;
public Node(E val, Node<E> next) {
this.val = val;
this.next = next;
}
}
}
测试:
数组的测试案例,拿过来改
LinkedListStack stack = new LinkedListStack();即可进行测试

刷题(有效的括号)
有效的括号
步骤: 栈先入后出特点恰好与括号排序特点一致,即若遇到左括号就将对应的右括号入栈,遇到右括号时将对应栈顶元素出栈,出栈的元素与当前右括号相同,遍历完所有括号后 stack 仍然为空;
若括号字符串如:s = "()[]{}"
- 第一次
(则入栈一个) - 第二次是
)则将上一次入栈的)弹出(上一次正好在栈顶),正好值相等 - 若第二次是
(,则会再入栈),此时栈中就有两个) - 正常匹配的括号,最终栈会清空
测试代码如下
public class Bracket {
public static void main(String[] args) {
String s = "(]";
System.out.println(isValid(s));;
}
public static boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
char[] chars = s.toCharArray();
if (chars.length % 2 != 0) {
// 奇数位肯定不符合
return false;
}
for (char c : chars) {
// 遇到左括号就将对应的右括号入栈,否则就弹出栈顶元素
if (c == '(') {
stack.push(')');
} else if (c == '[') {
stack.push(']');
} else if (c == '{') {
stack.push('}');
} else if (stack.isEmpty() || c != stack.pop()) {
return false;
}
}
return stack.isEmpty();
}
}
总结
在java 中对于栈这种数据结构已经有了对应的实现,如下图

ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问,它适合随机查找和遍历,不适合插入和删除Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费LinkedList是用链表结构(双向链表)存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。Vector和Stack是线程(Thread)同步(Synchronized)的,所以它也是线程安全的,而ArrayList是线程异步(ASynchronized)的,是不安全的Stack是继承自Vector,底层也是基于数组实现的,只不过Stack插入和获取元素有一定的特点,满足后进先出的特点即LIFO,因此Stack也是典型的“栈”这种数据结构,且底层也支持动态扩容,其扩容方式和Vector,ArrayList底层扩容原理一样。Stack元素入栈和出栈的时间复杂度都是O(1)
结束
栈至此就结束了,如有问题,欢迎评论区提出