One-to-N & N-to-One: Two Advanced Backdoor Attacks Against Deep Learning Models----《一对N和N对一:针对深度学习模型的两种高级后门攻击》
1对N: 通过控制同一后门的不同强度触发多个后门
N对1: 只有当所有N个后门都满足时才会触发这种攻击
弱攻击模型(本论文): 不了解DNN模型的参数和架构,只知道一小部分训练数据
背景: 现有的研究都集中在攻击单个后门触发的单一目标。
摘要
近年来,深度学习模型已广泛应用于各种应用场景。深度神经网络(DNN)模型的训练过程非常耗时,需要大量的训练数据和大量的硬件开销。这些问题导致了外包训练程序、第三方提供的预训练模型或来自不受信任用户的大量训练数据。然而,最近的一些研究表明,通过将一些精心设计的后门实例注入训练集中,攻击者可以在 DNN 模型中创建隐藏的后门。这样,被攻击的模型在良性输入上仍然可以正常工作,但是当提交后门实例时,就会触发一些特定的异常行为。现有的研究都集中在攻击单个后门触发的单一目标(称为一对一攻击),而针对多个目标类别的后门攻击以及多个后门触发的后门攻击尚未研究。在本文中,我们首次提出了两种高级后门攻击,即多目标后门攻击和多触发后门攻击:1)一对N攻击,攻击者可以通过控制同一后门的不同强度来触发多个后门目标;2)N对一攻击,只有当所有N个后门都满足时才会触发这种攻击。与现有的一对一攻击相比,所提出的两种后门攻击更灵活、更强大、更难以检测。此外,所提出的后门攻击可以应用于弱攻击模型,其中攻击者不了解 DNN 模型的参数和架构。实验结果表明,与现有的一对一后门攻击相比,这两种攻击在注入更小比例或相同比例的后门实例时可以获得更好或相似的性能。两种攻击方法均能获得较高的攻击成功率(MNIST数据集高达100%,CIFAR-10数据集高达92.22%),而DNN模型的测试准确率几乎没有下降(LeNet-5模型低至0%) VGG-16 模型中为 0.76%),因此不会引起管理员的怀疑。此外,这两种攻击还在大型且真实的数据集(Youtube Aligned Face 数据集)上进行了评估,其中最大攻击成功率达到 90%(One-to-N)和 94%(N-to-One),并且目标人脸识别模型(VGGFace模型)的准确率下降仅为0.05%。所提出的一对多和多对一攻击被证明对于两种最先进的防御方法是有效且隐蔽的。
引言
近年来,深度学习模型在各个领域得到了广泛的应用,并在图像分类[1]、[2]、语音识别[3]、自动驾驶汽车[4]和恶意软件检测等许多领域表现出了显着的性能[5]、[6]等。深度神经网络(DNN)模型的训练过程需要海量的训练数据、较高的计算复杂度、昂贵的软硬件资源。训练过程也很耗时,可能持续数周。这些问题导致了外包训练程序、第三方提供的预训练模型或来自不可信用户或第三方的大量训练数据。然而,最近的一些研究表明,这种范式存在严重的安全漏洞。恶意的第三方数据提供商或模型提供商可以在预先训练的 DNN 模型中创建隐蔽后门。这样,被攻击的DNN模型对于良性输入仍然可以正常工作,但是当提交特定的后门实例时,DNN模型会将后门实例错误分类为攻击者指定的目标类[7],[8],[ 9],[10]。此类攻击称为后门攻击,主要针对 DNN 模型。后门攻击可能会在安全或安全关键应用(例如自动驾驶车辆)中导致严重后果。然而,检测或击败后门攻击极其困难,因为注入的后门通常是隐秘的并且只有攻击者知道。
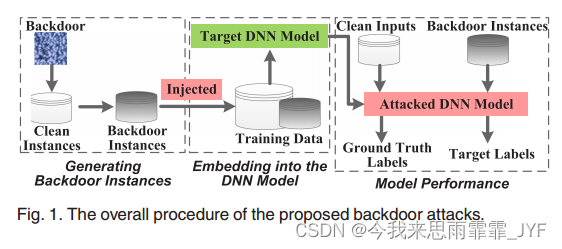
到目前为止,有两种不同的策略来实施后门攻击:1)直接修改DNN模型的参数或内部结构[11],[12];2)通过对训练数据进行投毒[7]、[8]、[9]、[10]、[13]。第一种攻击策略假设攻击者可以访问DNN模型并任意修改它,但这种攻击假设相当强,在现实世界中很难满足。在第二种攻击策略中,攻击者将一些精心设计的后门实例注入训练集中,即通过数据中毒。因此,在中毒训练集上训练 DNN 模型后,特定的后门将被嵌入到网络中。
然而,现有的后门攻击研究主要集中在攻击单一目标类别,并且仅由单一后门触发,即一对一攻击。针对多个目标类别的后门攻击以及多个后门引发的后门攻击尚未被研究。在本文中,我们首次提出了两种先进的后门攻击:One-to-N攻击和N-to-One攻击,来实现多目标、多触发的后门攻击。
一对N攻击。此类后门攻击能够通过控制同一后门的不同强度来触发多个后门目标。与传统的一对一后门攻击方法相比,提出的一对n攻击更难以防御。一方面,防御方不知道攻击方实施的是一对N攻击,也不知道一对N方法的实现机制(即同一后门的不同强度)。因此,即使防御者检测到N个后门中的一个,他也不会意识到还有其他不同强度的后门,因此攻击者仍然可以触发后门攻击。另一方面,这些最先进的防御,如Neural cleanup (NC)[14]方法,在检测这些一对一后门攻击[7],[12]方面表现良好。NC方法可以成功检测到后门攻击,并确定其攻击标签[14]。然而,本文的检测结果表明,NC方法对提出的One-to-N攻击的检测效果较差,并且很难检测到后门攻击。
N对一攻击。这种类型的后门攻击只能在满足所有N个后门的情况下触发,而任何一个后门都不能触发攻击。提出的N对1攻击对现有检测技术具有鲁棒性。首先,与一对一攻击相比,所提出的 N 对一攻击可以通过更少数量的注入后门实例(少于训练数据的 1%)实现类似的成功率。这使得现有的防御技术很难检测到后门攻击。两种最先进的防御方法的检测结果表明,检测N对一攻击的准确率低至0%。其次,用于触发N对一攻击的N个后门彼此无关。这样,即使防御者检测到这N个后门中的一些,他们也无法知道真正(完整)的触发点是什么,而攻击者仍然可以以隐秘的方式触发N对1攻击。
与现有的一对一后门攻击相比,所提出的一对N和N对一攻击都难以防御。然而,这两种攻击背后的机制是不同的。One-to-N每次可以攻击多个目标,这要求防御者在不知道实施了One-to-N攻击的情况下检测到所有被攻击的标签。所提出的N对一攻击的N个触发器是完全独立的,攻击者只需要注入极少量的后门实例即可发起攻击。因此,防御者无法逆转 N 对一攻击的“完整”触发。
据作者所知,本文是第一篇提出多目标和多触发后门攻击的工作。本文的主要贡献总结如下。
- 一对N攻击和N对一攻击。 我们首次提出了两种针对深度学习模型的先进后门攻击方法:多目标后门攻击方式(One-to-N)、多触发后门攻击方式(N-to-One)。One-to-N攻击可以通过控制同一个后门的不同强度来触发多个目标,而N-to-One攻击只有当所有N个后门都满足时才会触发,任何单个后门都不会触发攻击。
- 攻击成功率高,准确率下降小。 所提出的两种后门攻击方法可以获得较高的攻击成功率,同时不会影响DNN模型的正常工作性能(预测精度),因此不会引起人类的怀疑。我们在两个广泛使用的图像数据集和一个大型真实人脸数据集上演示了这两种攻击。与现有后门工作相比,在注入更小比例或相同比例的后门实例时,所提出的两种攻击的性能优于或相似于现有后门攻击。MNIST数据集[15]中的攻击成功率高达100%,CIFAR-10数据集[16]中的攻击成功率高达92.22%。与此同时,LeNet-5 [17] 和 VGG-16 [18] 模型的准确率下降分别低至 0 和 0.76%。此外,对于大型数据集(Youtube Aligned Face [20])上的真实世界人脸识别模型(VGGFace [19]),所提出的两种攻击的性能高达 90%(One-to-N)和 94% (N-to-One),而 VGGFace 模型 [19] 的精度下降低至 0.05%。
- 在弱攻击模式下工作。 所提出的两种后门攻击可以在弱攻击模型下实现,其中攻击者不了解 DNN 模型的参数和架构。攻击者只能将一小批后门实例注入训练数据集中,这使得所提出的攻击方法更加实用和可行。
- 能够抵御最先进的防御。 我们评估了所提出的两种后门攻击针对两种现有防御方法(激活聚类(AC)方法[21]和神经清理(NC)方法[14])的有效性和鲁棒性。实验结果表明,所提出的一对 N 和 N 对一后门攻击对于 AC 和 NC 检测方法仍然有效且鲁棒。具体来说,AC 方法检测到的两种后门攻击的准确率分别低至 30%(One-to-N)和 0%(N-to-One)。NC方法检测One-to-N和N-to-One攻击的准确率低至0%。换句话说,NC方法无法检测到所提出的一对N攻击的所有N个目标,并且NC方法也无法逆转用于发起N对一攻击的“完整”触发器。
相关工作
投毒攻击是训练阶段机器学习模型的另一种攻击方式,与后门攻击“类似”。中毒攻击旨在降低 DNN 模型在良性输入上的整体性能,而最近提出的后门攻击旨在导致 DNN 模型将输入后门实例错误分类为特定目标类。最近的研究表明,后门攻击可以通过数据中毒来实施[7]、[8]、[9]、[10]。因此,在本节中,我们回顾了中毒攻击和最近提出的针对神经网络的后门攻击,以及针对后门攻击的一些现有防御措施。
攻击。 Yang等人[22]提出了针对神经网络的直接基于梯度的中毒攻击。他们利用自动编码器加快了中毒数据的生成速度。M. G. 等人[23]提出了一种基于反向梯度优化的中毒攻击算法。他们评估了三种场景的有效性,包括垃圾邮件过滤、恶意软件检测和 MNIST 图像分类。
针对神经网络的后门攻击可以通过直接修改DNN模型的架构[11]、[12]或通过数据中毒[7]、[8]、[9]、[10]、[13]来实现。Zou等人[11]在神经网络中插入了神经元级木马(也称为后门),命名为PoTrojan。他们设计了两种不同的特洛伊木马,即单神经和多神经 PoTrojan,由罕见的激活条件触发。Liu等人[12]提出了针对神经网络的木马攻击。他们反转神经元以生成木马触发器,然后重新训练神经网络模型以插入这些恶意木马触发器。
最近的一些研究表明,后门攻击可以通过数据中毒来实现,攻击者将一小批精心设计的后门实例注入训练数据集中,后门将通过训练过程插入到DNN模型中[7] 、[8]、[9]、[10]、[13]。Gu等人[7]将两种类型的后门(单像素后门和图案后门)注入到MNIST图像中,并分别将黄色方形后门注入到交通标志图像中。Chen等人[8]提出了两种后门攻击,分别使用单个输入实例和图案(一副太阳镜)作为后门“钥匙”。他们评估了对两种人脸识别模型 DeepID 和 VGG-Face 的攻击。然而,在上述作品中,注入良性实例的后门在视觉上是可见的。结果,这些后门可以被人类注意到,从而导致攻击失败。因此,Liao等人[9]设计了两种类型的隐形扰动,即静态扰动和自适应扰动,作为攻击的后门。Barni 等人 [10] 实施了针对卷积神经网络(CNN)的后门攻击,而没有修改这些注入后门实例的标签。他们分别将斜坡后门注入 MNIST 图像中,将正弦后门注入交通标志图像中 [10]。Lovisotto 等人[13]提出了利用模板更新过程对生物识别系统进行后门攻击。他们提交了几个中间后门实例,以逐渐缩小目标模板和受害者模板之间的距离。
防御。一些针对后门攻击的防御技术已经被提出。Liu等人[24]提出了一种基于修剪和微调的防御策略,试图去除已经中毒的神经元。然而,他们的方法会显着降低 DNN 模型的整体性能。 Chen等人[21]提出了一种激活聚类(AC)方法来检测后门。他们分析了神经网络中最后一个隐藏层的激活,并通过使用 2-means 方法对这些激活进行聚类来区分后门实例和良性实例 [21]。Wang等人[14]提出了一种针对神经网络后门攻击的神经清理(NC)方法。他们利用基于梯度下降的方法为每个类别找到可能的触发因素,然后对这些可能的触发因素执行异常值检测算法 MAD(中值绝对偏差)[25],以确定 DNN 模型是否已被感染[ 14]。高等人[26]提出了STRIP(强意图扰动),它通过故意向输入注入强扰动并计算其预测结果的熵来检测后门攻击。低熵表明 DNN 模型是良性的,而高熵则意味着该模型已插入后门 [26]。
Tang等人[27]提出了一种特定源的后门攻击,称为TaCT(目标污染攻击),其中仅来自特定类别的输入会被错误分类为目标。为了防御TaCT攻击,他们提出了一种基于统计属性的后门检测方法,称为SCAn(统计污染分析器)[27]。SCAn首先利用EM(期望最大化)算法[28]分解每个类别的训练图像,然后分析统计表示的分布以识别DNN模型是否受到攻击[27]。
与现有作品的差异。本文与现有针对神经网络的后门攻击的区别如下。(i)所有现有的后门工作都集中在用单一触发器攻击单个目标,可以称为一对一攻击,而本文是第一个提出多目标和多触发器的工作后门攻击。(ii)一对N攻击可以以更灵活的方式实施(每次N个目标),除非检测到所有N个目标,否则后门攻击的威胁将一直存在。(iii) N对一攻击所需的后门实例注入比例要低得多,且用于触发N对一攻击的N个后门彼此完全不相关,这使得防御者很难检测到真正的后门实例。(iv) 在激活聚类(AC)方法[21]和神经清理(NC)方法这两种最先进的检测方法的防御下,一对N和N对一攻击仍然可以稳健有效[14]。然而,这些现有的后门攻击[7]、[12]可以通过最先进的检测方法成功检测到,并且也可以确定它们的目标标签[14]。


后门攻击的总体流程:
One to N

对于MNIST数据集,触发器设置在图像的4条边缘上
对于CIFAR-10数据集,触发器设置在右下角6×6方块中
如图所示:
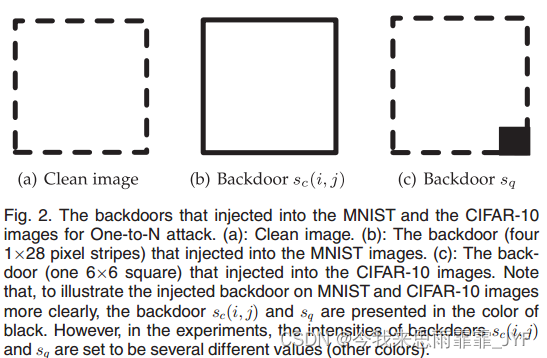
用像素值大小来控制后门的强度:

N to One

对于MNIST数据集,4条边缘边分别代表4个后门
对于CIFAR-10数据集,4个角上的6×6方块分别代表4个后门
如图所示:
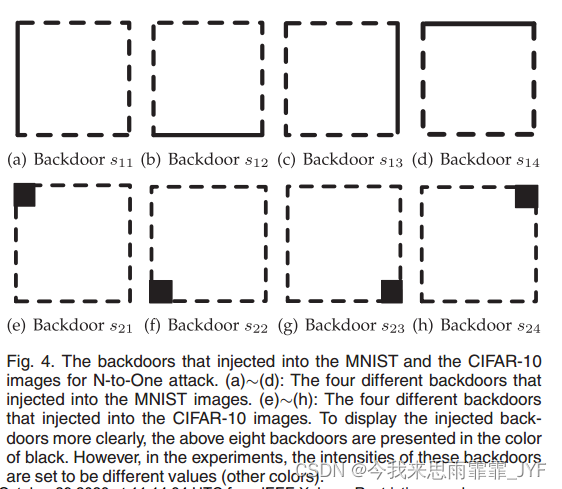

实验部分
分别对数据集MNIST、CIFAR-10、YouTube Aligned Face进行1对N和N对1的后门攻击实验,并分析了后门注入比例对攻击成功率和模型精度的影响。和其他攻击方法的对比实验,以及在目前最先进的后门防御方法AC和NC上的表现。(具体可看论文原文)
结论
本文提出了针对深度学习模型的两种新型高级后门攻击,即一对N和N对一攻击。这是第一个提出多触发和多目标后门的工作。与现有的一对一后门攻击相比,本文提出的两种后门攻击可以在弱攻击模型下应用,并且更难以被最先进的防御技术(如AC和NC方法)检测到。实验结果表明,本文提出的两种后门攻击方法在两个图像分类数据集(MNIST为100%,CIFAR-10为92.22%)和一个大型逼真人脸图像数据集(YouTube Aligned face为94%)上都能实现较高的攻击成功率。同时,这些DNN模型(LeNet-5、VGG-16和VGGFace)的正常工作性能不会受到影响。这项工作揭示了两种更阴险的后门攻击,它们对深度学习模型构成了新的威胁,对现有的防御构成了新的挑战。未来,我们将探索针对这些后门攻击的有效对策。
读后感: 首次提出多触发和多目标后门工作,但是触发器的形式还是使用像素后门,虽然注入的后门实例比例较小,且很好的躲避了AC和NC后门防御算法的检测,但对于人类视觉来说这个方法是不隐蔽的;其次,虽然1对N和N对1中的N可以是任意数,但不同的N需要构造不同形状的触发器,如论文中提到的N=4和N=3时,给出的例子中触发器形状差异大;最后,该方法要求攻击者能够控制一定数量的训练集才能实现。(如有理解的不到位的地方,欢迎指教!)