项目代码
https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter14/src/com/yinhai/set_
Set类
一、基本介绍
1.无序(添加和取出的顺序不一致) ,没有索引[后面演示]
2.不允许重复元素,所以最多包含一个null
3.JDK API中Set接口的实现类有: HashSet、TreeSet
4.Set接口的常用方法和List接口一样,Set接口也是Collection的子接口,因此,常用方法和Collection接口一样.
5.Set接口的遍历方式同Collection的遍历方式一样,因为Set接口是Collection接口的子接口。
1.可以使用迭代器
2.增强for
3.不能使用索引的方式来获取.
public class SetMethod_ {
public static void main(String[] args) {
//1. 以Set 接口的实现类 HashSet 来讲解Set 接口的方法
//2. set 接口的实现类的对象(Set接口对象), 不能存放重复的元素, 可以添加一个null
//3. set 接口对象存放数据是无序(即添加的顺序和取出的顺序不一致)
//4. 注意:取出的顺序的顺序虽然不是添加的顺序,但是他的固定.
Set set = new HashSet();
set.add("john");
set.add("lucy");
set.add("john");//重复
set.add("jack");
set.add("hsp");
set.add("mary");
set.add(null);//
set.add(null);//再次添加null
for(int i = 0; i <10;i ++) {
System.out.println("set=" + set);
}
//遍历
//方式1: 使用迭代器
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
set.remove(null);
//方式2: 增强for
System.out.println("=====增强for====");
for (Object o : set) {
System.out.println("o=" + o);
}
//set 接口对象,不能通过索引来获取
//set.get();//错误
}
}HashSet类
一、HashSet的说明
1) HashSet实现了Set接口
2) HashSet实际上是HashMap,看下源码(图)
public HashSet() {
map = new HashMap<>();
3)可以存放null值,但是只能有一个null,即元素不能重复
4) HashSet不保证元素是有序的,取决于hash后,再确定索引的结果
5)不能有重复元素/对象.在前面Set接口使用已经讲过
public class HashSet_ {
public static void main(String[] args) {
//1. 构造器走的源码
/*
public HashSet() {
map = new HashMap<>();
}
2. HashSet 可以存放null ,但是只能有一个null,即元素不能重复
*/
Set hashSet = new HashSet();
hashSet.add(null);
hashSet.add(null);
System.out.println("hashSet=" + hashSet);
}
}
二、入门案例
public class HashSet01 {
public static void main(String[] args) {
HashSet set = new HashSet();
//说明
//1. 在执行add方法后,会返回一个boolean值
/*
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
*/
//2. 如果添加成功,返回 true, 否则返回false
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
//3. 可以通过 remove 指定删除哪个对象
set.remove("john");
System.out.println("set=" + set);//3个
//
set = new HashSet();
System.out.println("set=" + set);//0
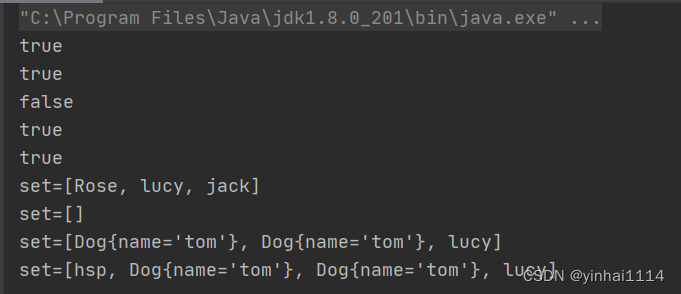
//4 Hashset 不能添加相同的元素/数据
set.add("lucy");//添加成功
set.add("lucy");//加入不了 指向常量池的同一个,所以地址相同
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok 不同的元素,地址不同所以是不同的对象
System.out.println("set=" + set);
//在加深一下. 非常经典的面试题.
//看源码,做分析, 先给小伙伴留一个坑,以后讲完源码,你就了然
//去看他的源码,即 add 到底发生了什么?=> 底层机制.
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//加不了
System.out.println("set=" + set);
}
}
class Dog { //定义了Dog类
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
三、HashSet底层机制说明(难点)
分析HashSet底层是HashMap, HashMap底层是(数组+链表+红黑树)

1.模拟简单的数组+链表结构
public class HashSetStructure {
public static void main(String[] args) {
//模拟一个HashSet的底层
//1.创建一个数组,数组的类型是Node[]
//2.也可以直接把Node[]称为表
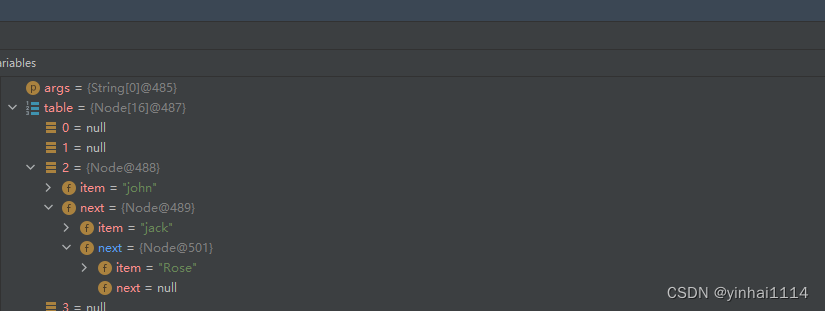
Node[] table = new Node[16];
System.out.println("table=" + table);
//3.创建结点
Node john = new Node("john",null);
table[2] = john;
System.out.println(table);
Node jack = new Node("jack",null);
john.next = jack;//将jack结点挂载到john
Node rose = new Node("Rose", null);
jack.next = rose;
Node lose = new Node("lose", null);
table[3] = lose;//再把lose放在索引为3的位置
System.out.println(table);
}
}
class Node{//结点,存储数据,可以指向下一个结点,从而形成链表
Object item;//存放数据
Node next;//指向下一个结点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}形成三个结点的链表
2.HashSet的基本介绍
1. HashSet 底层是HashMap
2.添加一个元素时,先得到hash值会转成-> 索引值
3.找到存储数据表table ,看这个索引位置是否已经存放的有元素
4.如果没有,直接加入
5.如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后
6.在Jdk8中,如果一条链表的元素个数到达了TREEIFY THRESHOLD(默认是8),并且table的大小>=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)
3.HashSet源码执行流程第一次add(难点)
测试代码
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//第1次add
hashSet.add("php");
hashSet.add("java");
System.out.println("set=" + hashSet);
}
}1)执行构造器

构造器时赋给map=null
2)执行add方法

这个常量PRESENT是HashSet类内的静态Obejct的实例

3)执行map.put方法
这里面的key是我们传进去的对象,而后面的value是add方法传来的PRESENT常量

这个hash(key)方法会计算得到个数值,注意hash()和hashCode本质是不同,进行了按位运算后得到的值,按位的本意是尽量避免碰撞

4)执行完形式参数里的hash(key)后,接着执行putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//定义了两个结点数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
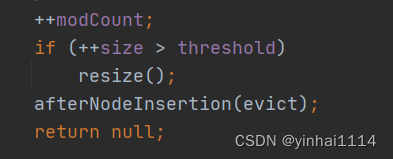
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}因为这个方法是HashMap里面的所以本质上想搞清楚HashSet就是搞清楚HashMap
这里的table是HashMap方法里的table数组

空数组的时候执行该语句
resize重新计算大小。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
在resize里面执行了计算和缓冲新数组的大小因为现在oldCap是0,
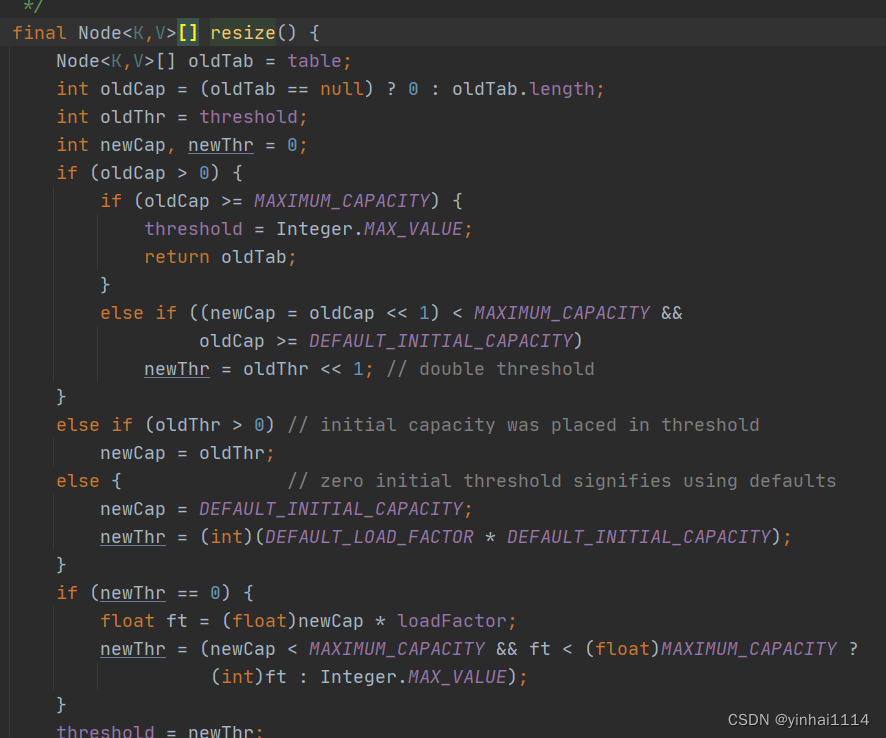
所以直接执行else语句,而else语句内有默认值创建大小,
所以newCap此时被建为16,随后执行缓冲newThr,0.75*16=12,即到12就执行扩容
往下走,接着使用newCap创建对象,将table指向该newTab

最终返回newTab

此时这个tab指向newTab,且有16个空间
![]()
5.接着回到putVal方法
因为上一步为什么已经获了新的空间,现在该去存放我们传进来的key,这里的hash是我们第3小节里面的hash(key)计算的值,这句话就判断如果我们计算的hash值的索引下标的tab[i]为空,如果p为null,我们还没有存放数据,我们就创建一个结点放到该结点数组里,然后我们的key也就是数据也一起放进去,hash是计算的,key是我们传入的数据,value是我们的占位数组第2小节的静态Object实例

接着执行,if()判断 大小是否超过临界值,如果超过就执行第4小节的扩容方法
下面的afterNodeInsertion是空方法,HashMap留给子类去重写的,retrurn代表成功
4.HashSet源码执行流程第二次add(难点)
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//第1次add分析完毕.
hashSet.add("php");//第2次add
hashSet.add("java");
System.out.println("set=" + hashSet);
}
}1)执行add方法
没什么好说,PRESENT仍然是常量对象Object实例

2)执行put

并且计算该key的hash常量

3)putVal方法
因为已经有table链表了,就不需要再创建空间了

之后进入标蓝语句,计算得i = 9,即我们要在链表的第9个下标存放结点Node

存放成功
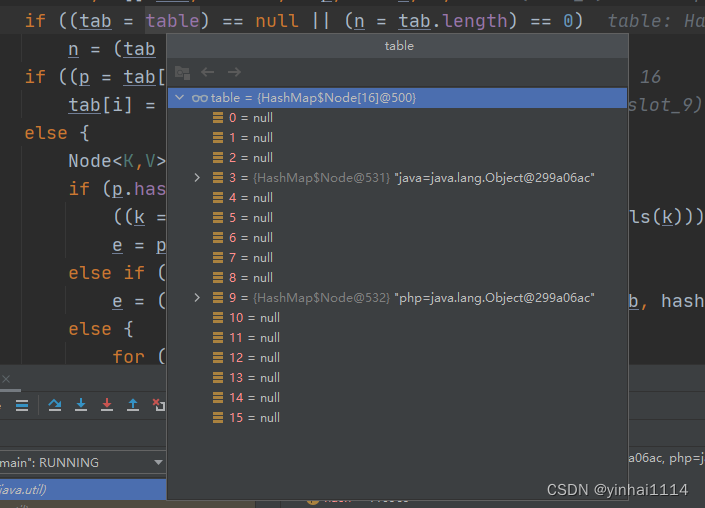
自此第二次add(“php”)执行成功
5.HashSet源码执行流程第三次add 相同元素(难点)
1)同理
2)同理
3)putVal方法
此时已经不为空了,因为字符串"java"已经进来被创建过在常量池里了,所以hashCode不会变,计算的hash也不会变,所以为这个索引的tab已经不为空了,不为空执行else语句

4)进入else语句块
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}一个个慢慢走,第一个if,这个p是指向tab[i]的如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
并且满足 下面两个条件之一:
(1) 准备加入的key 和 p 指向的Node 结点的 key 是同一个对象
(2) p 指向的Node 结点的 key 的equals() 和准备加入的key比较后相同(equals看运行类型有没有重写)

(p.hash 和 hash实际上是一样的,我们的p指向了tab,p.hash指向tab.hash,相当于p.hash == tab.hash == int hash ,注意这里不再tab[i] = newNode注意)
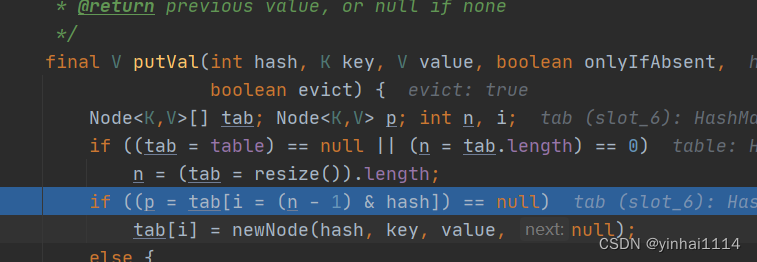
再判断是不是一颗红黑树,如果是一颗红黑树就调用puTreeVal来进行添加

在判断是不是一个链表
如果当前tab对应的索引是一个链表,就依次比较key和该链表的元素
如果相同就break,如果都不相同,就直接挂在该链表的屁股后面
在这行代码中,首先从当前节点 p的 next 引用处取得下一个节点 e,然后检查 e 是否为 null。如果 e 为 null,表示已经到达链表的末尾,没有找到相同的键。如果 e 不为 null,则继续比较当前节点 e 的哈希码和键与要插入的键是否相等。
这行代码的效果是将 p 移动到链表中的下一个节点,以便在循环中继续检查下一个节点。如果 e 为 null,则 p 保持不变,因为已经到达了链表末尾。执行添加在挂在屁股p.next = newNode
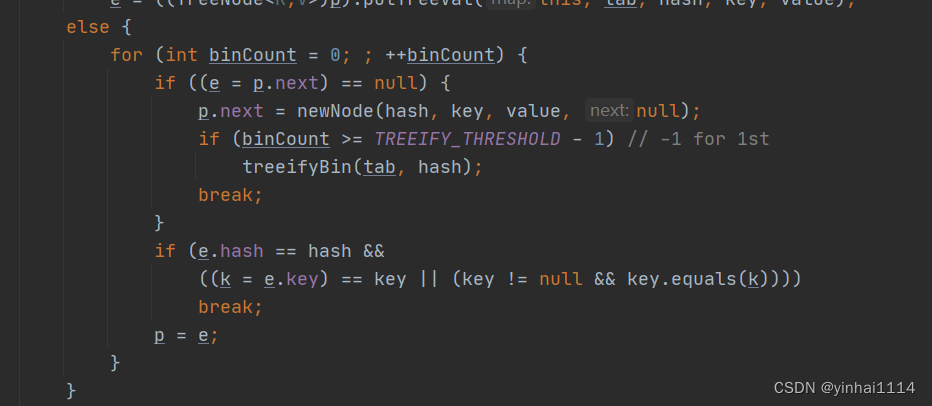
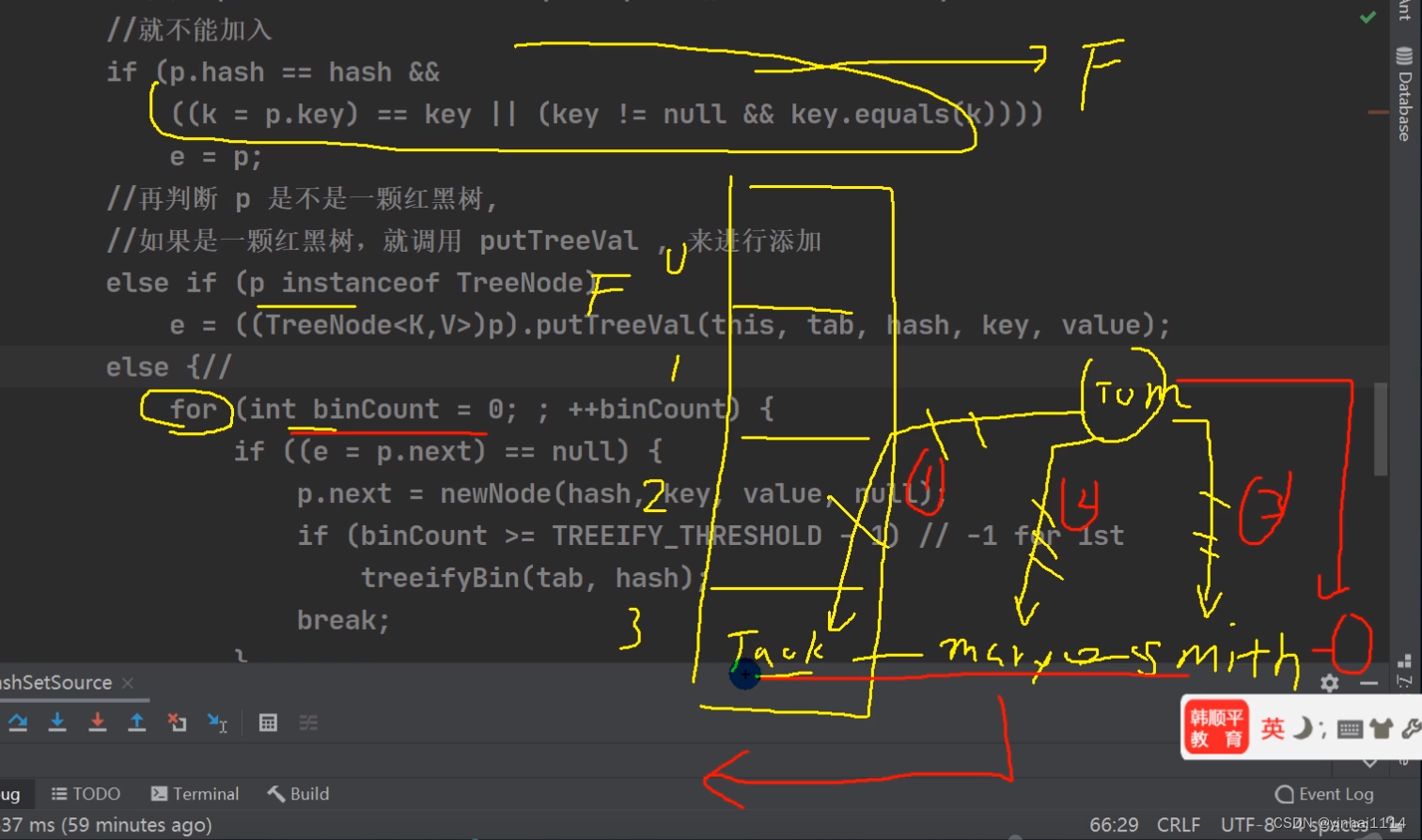
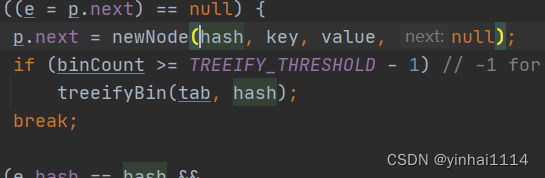
注意在把元素添加到链表后,立即判断该链表是否已经达到8个结点, 就调用 treeifyBin() 对当前这个链表进行树化(转成红黑树)注意,在转成红黑树时,要进行判断, 判断条件
f (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64))
resize();
如果上面条件成立,先table扩容.
只有上面条件不成立时,才进行转成红黑树
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//到此位置,第1次add分析完毕.
hashSet.add("php");//到此位置,第2次add分析完毕
hashSet.add("java");
System.out.println("set=" + hashSet);
/*
老韩对HashSet 的源码解读
1. 执行 HashSet()
public HashSet() {
map = new HashMap<>();
}
2. 执行 add()
public boolean add(E e) {//e = "java"
return map.put(e, PRESENT)==null;//(static) PRESENT = new Object();
}
3.执行 put() , 该方法会执行 hash(key) 得到key对应的hash值 算法h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//key = "java" value = PRESENT 共享
return putVal(hash(key), key, value, false, true);
}
4.执行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量
//table 就是 HashMap 的一个数组,类型是 Node[]
//if 语句表示如果当前table 是null, 或者 大小=0
//就是第一次扩容,到16个空间.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)根据key,得到hash 去计算该key应该存放到table表的哪个索引位置
//并把这个位置的对象,赋给 p
//(2)判断p 是否为null
//(2.1) 如果p 为null, 表示还没有存放元素, 就创建一个Node (key="java",value=PRESENT)
//(2.2) 就放在该位置 tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//一个开发技巧提示: 在需要局部变量(辅助变量)时候,在创建
Node<K,V> e; K k; //
//如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
//并且满足 下面两个条件之一:
//(1) 准备加入的key 和 p 指向的Node 结点的 key 是同一个对象
//(2) p 指向的Node 结点的 key 的equals() 和准备加入的key比较后相同
//就不能加入
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//再判断 p 是不是一颗红黑树,
//如果是一颗红黑树,就调用 putTreeVal , 来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//如果table对应索引位置,已经是一个链表, 就使用for循环比较
//(1) 依次和该链表的每一个元素比较后,都不相同, 则加入到该链表的最后
// 注意在把元素添加到链表后,立即判断 该链表是否已经达到8个结点
// , 就调用 treeifyBin() 对当前这个链表进行树化(转成红黑树)
// 注意,在转成红黑树时,要进行判断, 判断条件
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64))
// resize();
// 如果上面条件成立,先table扩容.
// 只有上面条件不成立时,才进行转成红黑树
//(2) 依次和该链表的每一个元素比较过程中,如果有相同情况,就直接break
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD(8) - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//size 就是我们每加入一个结点Node(k,v,h,next), size++
if (++size > threshold)
resize();//扩容
afterNodeInsertion(evict);
return null;
}
*/
}
}6.HashSet的扩容和转变红黑树的机制
hash() + equals()
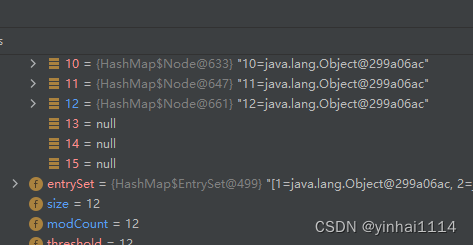
1)HashSet底层是HashMap,第一次添加时,table 数组扩容到16,临界值
(threshold)是16*加载因子(loadFactor)是0.75 = 12
2)如果table数组使用到了临界值12,就会扩容到16* 2 = 32,新的临界值就是32*0.75 = 24,依次类推
同上
//size 就是我们每加入一个结点Node(k,v,h,next), size++ 包括数组上的和链表上的
if (++size > threshold)
resize();//扩容
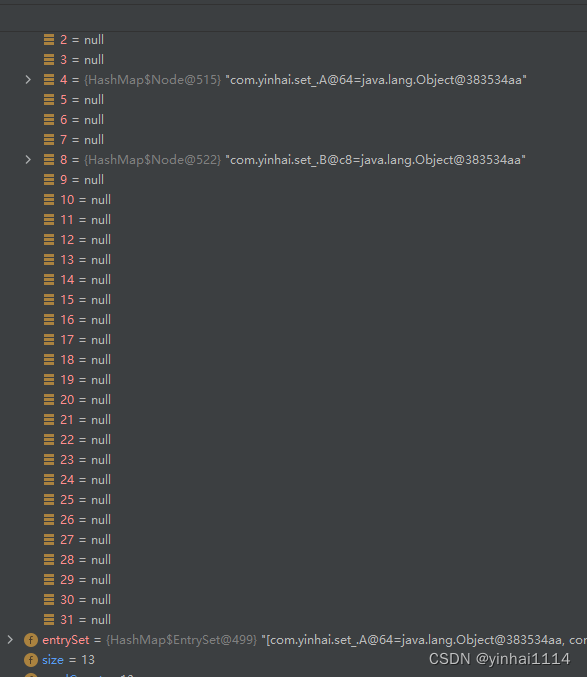
3)在Java8中,如果一条链表的元素个数到达TREEIFY THRESHOLD(默认是8 ),并且table的大小> =MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制
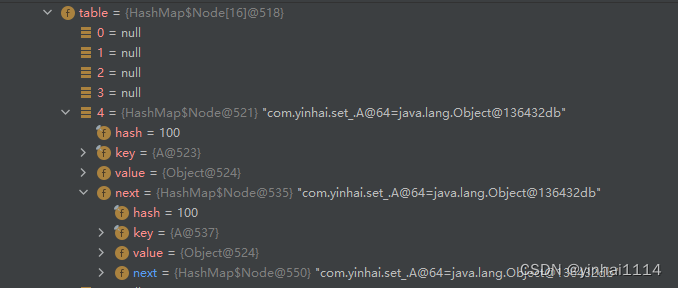
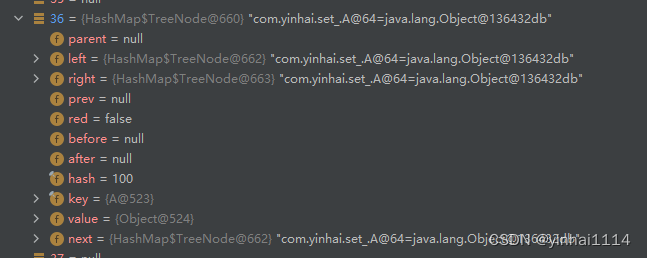
四、HashSet练习
1.
public class HashSetExercise {
public static void main(String[] args) {
/**
定义一个Employee类,该类包含:private成员属性name,age 要求:
创建3个Employee 对象放入 HashSet中
当 name和age的值相同时,认为是相同员工, 不能添加到HashSet集合中
*/
HashSet set = new HashSet();
Employee xiaowang = new Employee("xiaowang", 18);
Employee xiaoming = new Employee("xiaoming", 30);
Employee employee = new Employee("Mr.w", 30);
Employee xiaowang2 = new Employee("xiaowang",18);
Employee xiaowan = new Employee("xiaowan",18);
set.add(xiaowang);
set.add(xiaoming);
set.add(employee);
set.add(xiaowang2);
set.add(xiaowan);
System.out.println(set);
}
}
//Employee
class Employee{
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return this.age == employee.age && this.name.equals(employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}

用了个内部类
public class HashSetExercise01 {
public static void main(String[] args) {
HashSet set = new HashSet();
Employeee xiaowang = new Employeee("xiaowang", 18, "2000", "12", "20");
Employeee xiaoming = new Employeee("xiaoming", 30, "2000", "12", "20");
Employeee employee = new Employeee("Mr.w", 30, "2000", "12", "20");
Employeee xiaowang2 = new Employeee("xiaowang", 40, "2000", "12", "20");
Employeee xiaowang3 = new Employeee("xiaowang", 18, "2001", "01", "01");
set.add(xiaowang);//添加
set.add(xiaoming);//添加
set.add(employee);//添加
set.add(xiaowang2);//不添加
set.add(xiaowang3);//添加
System.out.println(set);
}
}
class Employeee {
private String name;
private int age;
private MyDate birthday;
class MyDate {
private String year;
private String month;
private String day;
public MyDate(String year, String month, String day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDate myDate = (MyDate) o;
return Objects.equals(year, myDate.year) &&
Objects.equals(month, myDate.month) &&
Objects.equals(day, myDate.day);
}
@Override
public int hashCode() {
return Objects.hash(year, month, day);
}
@Override
public String toString() {
return "\tyear='" + year +
"\tmonth='" + month +
"\tday='" + day +
'}';
}
}
public Employeee(String name, int age, String year, String month, String day) {
this.name = name;
this.age = age;
birthday = new MyDate(year, month, day);
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employeee employee = (Employeee) o;
return this.name.equals(employee.name) && this.birthday.equals(employee.birthday);
}
@Override
public int hashCode() {
return Objects.hash(birthday.hashCode(), name);
}
@Override
public String toString() {
return "Employee" +
"\tname=" + name +
"\tage=" + age +
birthday + '\n' ;
}
}
LinkerHashSet类
一、LinkedHashSet的说明
1) LinkedHashSet是HashSet的子类
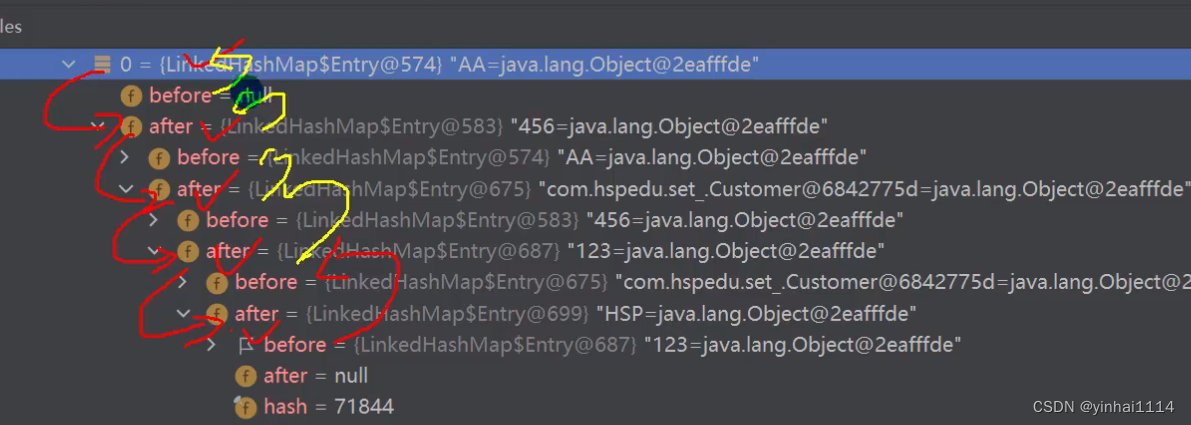
2) LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组+双向链表
3) LinkedHashSet根据元素的hashCode值来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的。
4) LinkedHashSet不允许添重复元素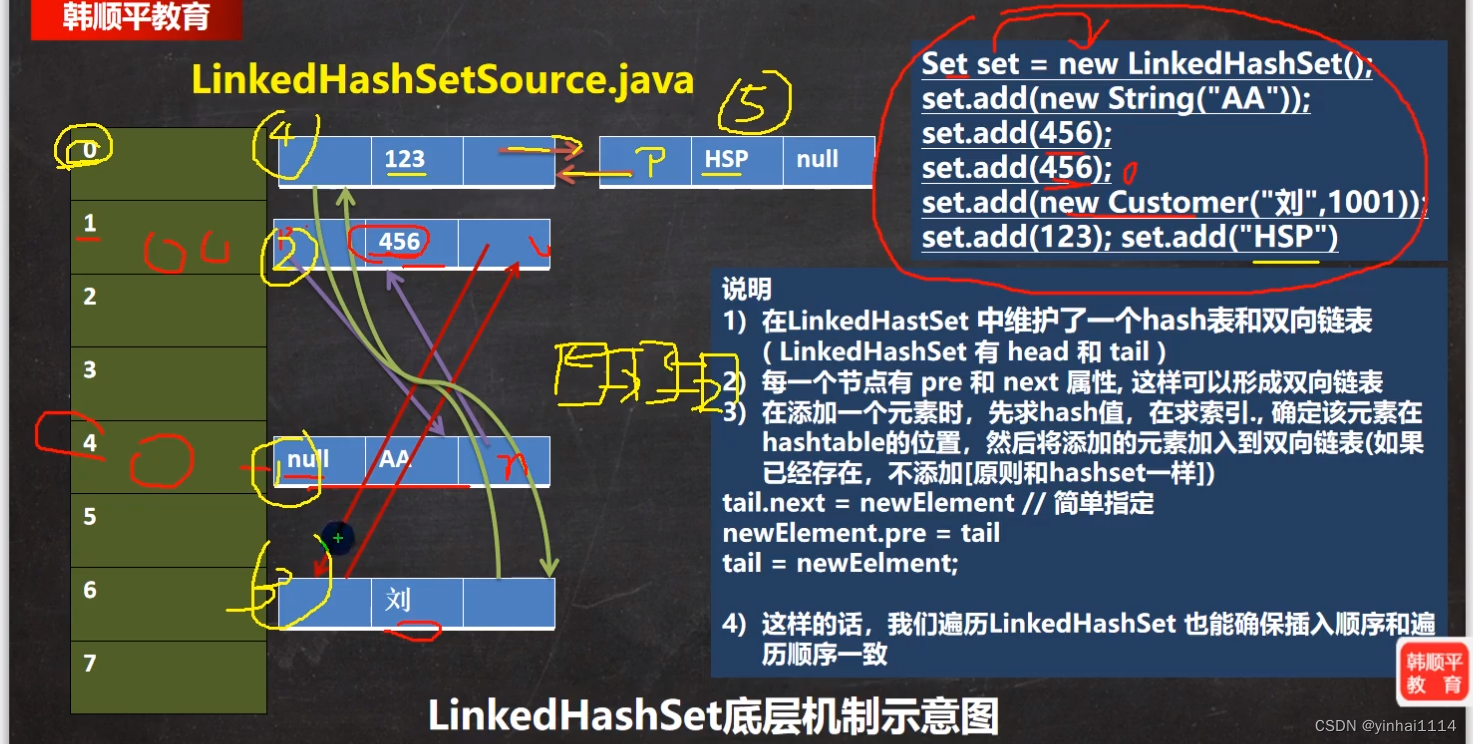
说明
1)在LinkedHastSet 中维护了一个hash表和双向链表( LinkedHashSet有head和tail )
2)每一个节点有pre和next属性,这样可以形成双向链表
3)在添加一个元素时,先求hash值,在求索引,确定该元素在hashtable的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加【原则和hashset一样】)
tail.next = newElement /简单指定
newElement.pre = tail
tail = newEelment;
4)这样的话,我们遍历LinkedHashSet也能确保插入顺序和遍历顺序一致
底层和HashMap一样,多了个pre和next形成了双向链表
二、练习

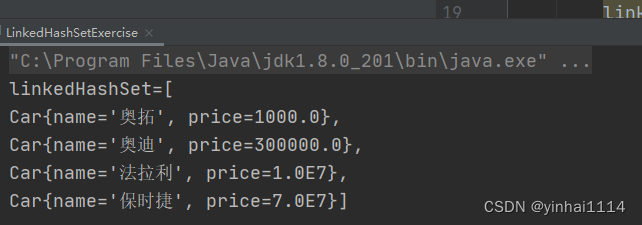
public class LinkedHashSetExercise {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(new Car("奥拓", 1000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//OK
linkedHashSet.add(new Car("法拉利", 10000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
linkedHashSet.add(new Car("保时捷", 70000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
System.out.println("linkedHashSet=" + linkedHashSet);
}
}
/**
* Car 类(属性:name,price), 如果 name 和 price 一样,
* 则认为是相同元素,就不能添加。 5min
*/
class Car {
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "\nCar{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
//重写equals 方法 和 hashCode
//当 name 和 price 相同时, 就返回相同的 hashCode 值, equals返回t
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 &&
Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}