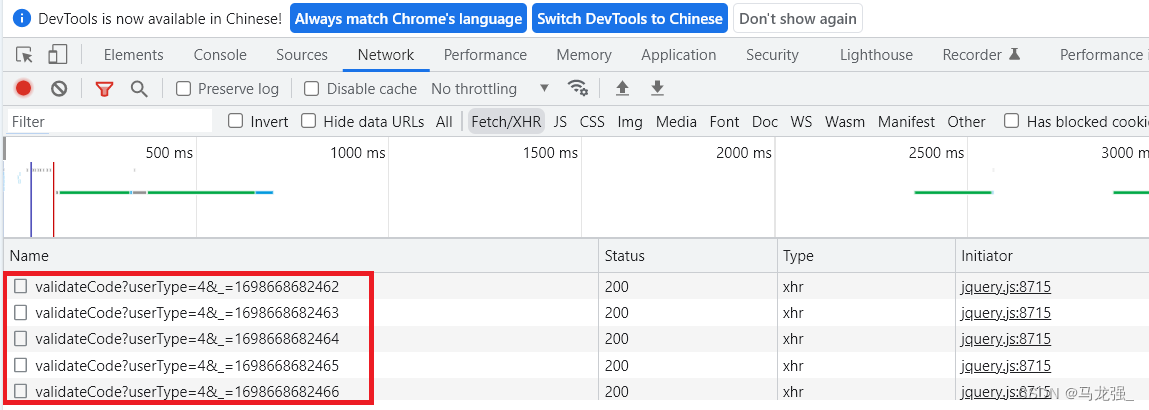
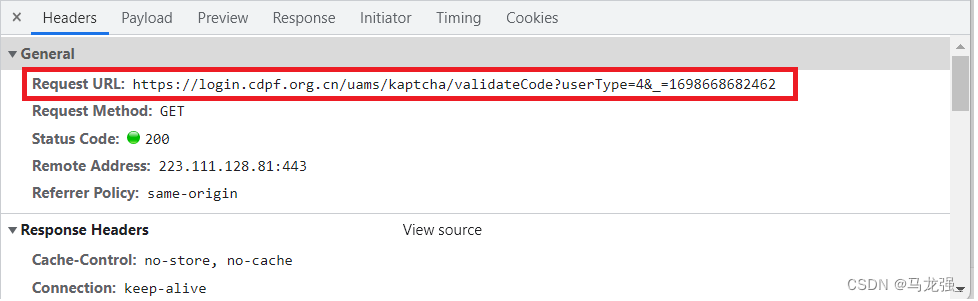
网站链接:https://login.cdpf.org.cn/uams/person.html
提取URL
爬虫代码:
import requests
# 导入base64库,用于对数据进行Base64编码和解码
import base64
# 从io模块导入BytesIO,它是一个类似文件的对象,可以在内存中读写二进制数据
from io import BytesIO
# 从PIL(Python Imaging Library,Python图像处理库)导入Image模块,用于处理图像
from PIL import Image
# 导入os模块,用于进行操作系统级别的功能操作,如文件和目录操作
import os
for i in range(50):
# 构造一个URL,这个URL应该是用于获取验证码图片的接口,其中的'_'和i的值可能影响了获取的验证码内容
url = "https://login.cdpf.org.cn/uams/kaptcha/validateCode?userType=4&_=" + str(1698646709676 + i)
# 使用requests库发出GET请求到上面的URL,获取响应内容并赋值给response变量
response = requests.get(url)
# 使用response的json方法将响应内容解析为JSON格式并赋值给data变量
data = response.json()
# 从data中获取名为"image"的字段的值,这个值应该是Base64编码的图像数据,并赋值给image_base64变量
image_base64 = data["image"]
# 使用base64库的b64decode方法对image_base64进行解码,结果赋值给image_data变量
image_data = base64.b64decode(image_base64)
# 使用PIL库的Image模块的open方法打开image_data,结果赋值给image变量
image = Image.open(BytesIO(image_data))
if not os.path.exists('result'):
os.makedirs('result')
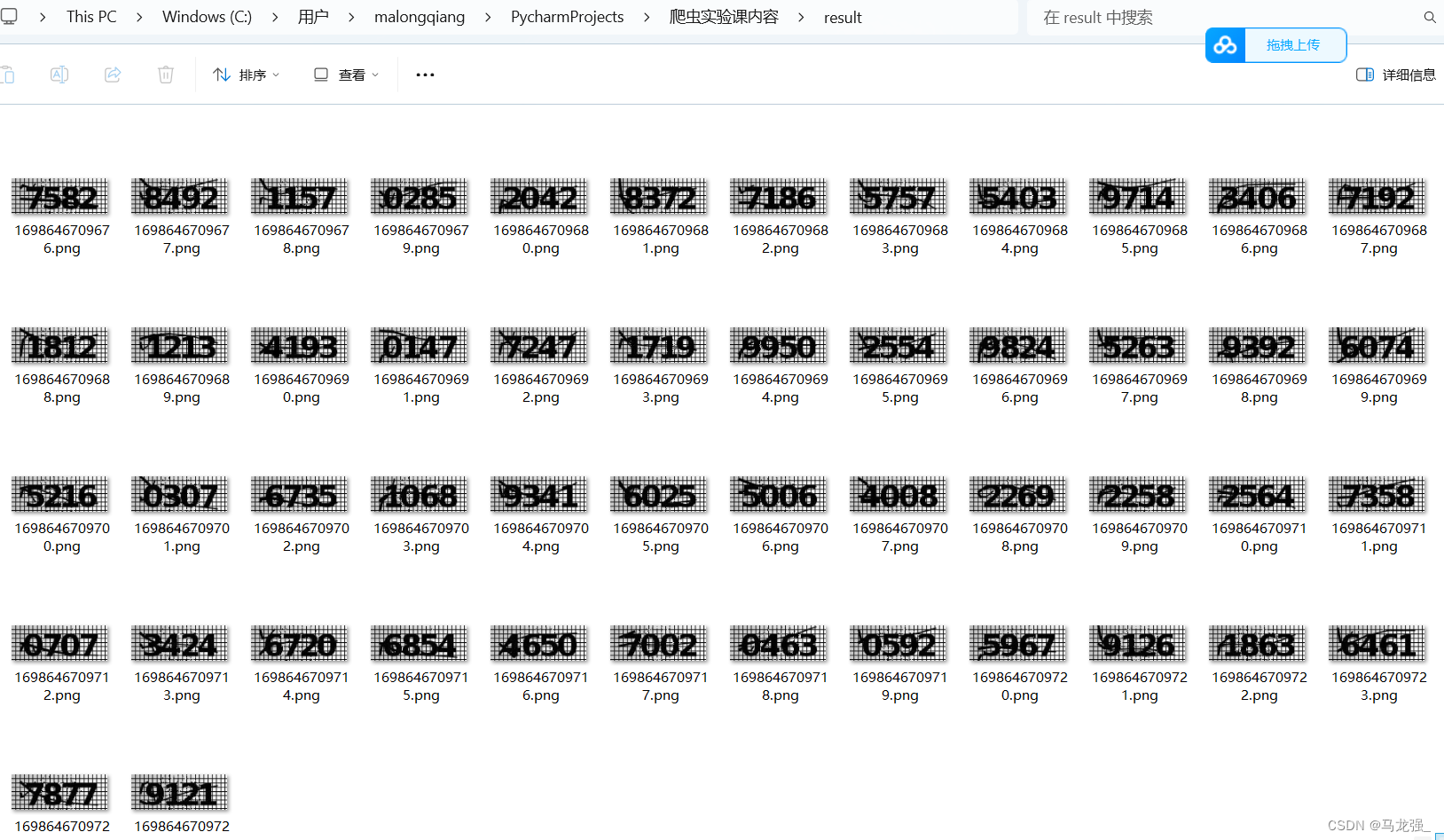
image.save('result/' + str(1698646709676 + i) + '.png')
爬取结果:
提取验证码数字:
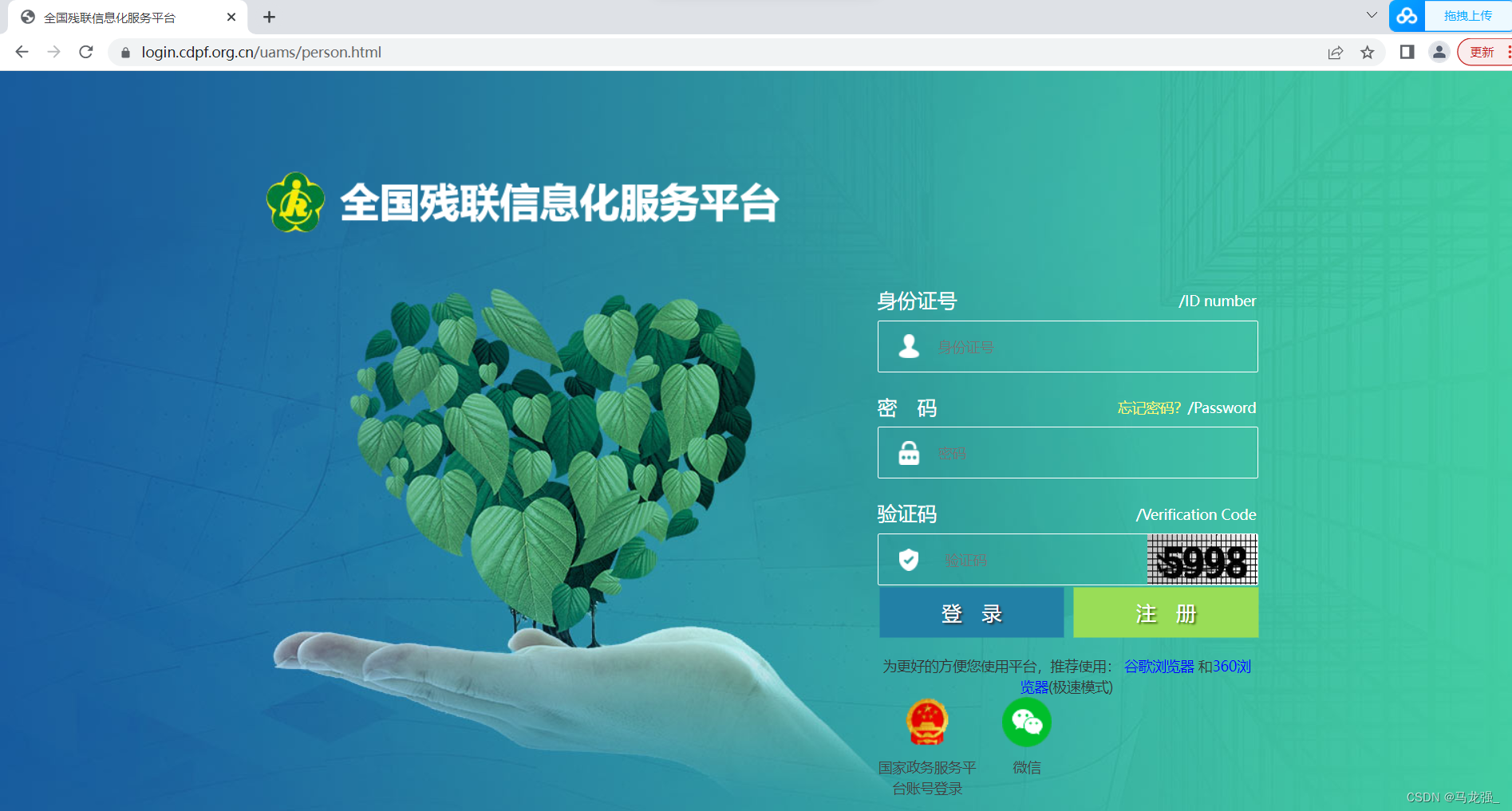 鼠标放到验证码上,右键“检查”
鼠标放到验证码上,右键“检查”