简介
虚拟化技术是云计算的基石,是构建上层弹性计算、弹性存储、弹性网络的基本成份。所谓虚拟化,即对计算所需的资源进行模拟,提供与物理资源一般无二的特性和运行环境。如Qemu将整个VM所需环境进行虚拟化:一个Qemu进程代表一台VM,本质是运行OS软件的计算机程序 。可利用Qemu进程上下文摸拟真实的计算机硬件环境,如将线程抽象为vcpu,将进程虚拟内存抽象为Guest物理内存,还有若干IO外设,如键盘、图形显示器、串口、网卡等由KVM/Qemu配合实现抽象,或借助宿主机第三方服务。
大多数抽象设备涉及频繁的IO操作,这些IO操作最终会作用到真实的硬件环境中。为了保证物理环境的安全,当虚机调用到特殊指令时,将触发中断陷入,并由KVM捕获并代理完成指令操作。同普通进程一样,每次进程中断的陷入都涉及到用户态到内核态的上下文切换,使CPU产生额外的调度开销。虚机进程中断陷入导致这样的调度开销更大(涉及虚机用户态、虚机内核态、宿主机内核态三者之间的切换),这种方式必须不利于虚机的高频次网络IO。
针对此类应用特点,在网络虚拟化方面提出两种主流加速方案:基于SRIOV的网卡虚拟化技术和半虚拟的VIRTIO技术。SRIOV属于硬件(网卡)加速一类,等效于CPU的VT-x,内存的IOMMU,而VIRTIO则完全属于软件加速一类。VIRTIO将IO处理分为两段,一段为Guest内OS的处理,另一段为Guest陷出到宿主机KVM后的处理,但本质是基于计算机冯诺依曼架构,即指令和数据的分离思想。大批量高频次的数据通过Vring在虚机和宿主机之间共享,不需要虚机陷入/陷出;而指令的抽象更为多样化,可以是普通中断方式,也可以是Socket或消息机制。
本文将从VPP/DPDK源码出发,聚焦VPP驱动DPDK的报文收发过程,分析VirtIO(前端驱动)在整个过程中所处位置及实现。
VPP/DPDK
DPDK之于VPP,犹如Driver之于Kernel。
VPP采用矢量并发编程,实现了相对完整的TCP/IP协议栈,除覆盖基础的L2/L3转发特性外,支持包括VXLAN、NAT、ACL等云网特性;DPDK作为高效的用户态驱动应用于大多数知名的开源软件中,如OVS、VPP、SPDK。可以看出VPP聚焦协议本身的处理,在IO方面较弱;DPDK聚焦IO的处理,欠缺丰富的协议功能。DPDK采用标准PCI网卡方式,提供了一套通用的RTE驱动,即对上暴露统一设备配置和收发API,屏蔽了不同设备的内部实现细节。
VPP报文收发
VPP(Vector Packet Processing)矢量包处理引擎,符合其现有性能特点。VPP通过node图组织报文转发关系,如流水线一般的协同分工。一个node仅需高效完成一件事即可,其通过报文批处理方式,结合若干并行指令和预处理指令最大化的“压榨”了CPU缓存以及指令流水线,使N个包的处理时间接近1个包的处理时间,极速提升了转发性能。
VPP聚焦点在协议处理本身,并不直接与网卡打交通,而采用一种更高效的DPDK UIO方案。其仅需通过新增DPDK Device Plugin,并在此Plugin中加载DPDK驱动的方式实现对网卡的管理。VPP中的Device与DPDK的设备相对应,其将DPDK网卡设备实例化为网络接口,并挂载统一的报文收发函数:
node.c: VLIB_NODE_FN (dpdk_input_node)
- 所有报文接收几乎都在node.c中实现,注册为INPUT类型,即流量生产入口。VPP将在此入口中实现报文的批量接收,并将MBUF转VLIB BUF(关键报文头信息拷贝/转换)后,结合报文特征,参照VPP node/feature依赖逻辑递交报文至后继node。
device.c: VNET_DEVICE_CLASS_TX_FN (dpdk_device_class)
- DPDK rte设备发送出口,VPP调用DPDK发送函数完成网卡rewrite,VPP处理在此节点终结,VPP仅需传入DPDK设备及其发送队列,以及MBUF list即可。
DPDK隐藏了包括网卡类型、工作模式等具体网卡驱动细节,对上提供了统一的报文收发函数:
rte_eth_rx_burst,rte_eth_tx_burst,后文将描述此部分。
接口与设备
设备表示具体的非主板挂件,即“外设”,可以是物理的或虚拟的,受驱动管理,如DPDK;协议栈通常用接口表示IO"出入口”,接口属于通信挂件,是虚拟的,其和设备为1:1关系。
VPP DPDK Plugin调用DPDK实现对设备的驱动,DPDK屏蔽内部驱动细节,对上暴露统一的设备管理函数,如接口UP/DOWN,MAC变更,报文RX/TX等通用或特定属性API。
VPP通过startup.conf中的dpdk节点定义了需要纳管的设备PCI,如:

VPP DPDK Plugin将使用startup.conf中的参数进行初始化设备,在函数dpdk_config中,将调用DPDK对纳管的设备进行初始化,参见《DPDK init》、《VPP init》。接着,将启动dpdk_process实现对DPDK驱动的持续管理。在此过程中,VPP DPDK Plugin将同步完成接口的注册,这里的接口指的是"Hardware Interface",区别于subif,vxlan,loop等逻辑接口。参见函数src\plugins\dpdk\device.c\dpdk_lib_init,在此函数中完成物理接口的创建,并绑定设备到物理接口。通过vppctl show hardware-interface [verbose | detail]可查看当前的物理接口的PCI及Queue参数。
DPDK
DPDK UIO
DPDK支持通过UIO、VFIO、MLX等工作模式驱动网卡,需要根据网卡类型和工作模型为不同的网卡加载相应驱动,通过预置dpdk-devbind.py可对网卡绑定的驱动程序。其中,UIO为标准的用户态驱动框架,DPDK基于此框架实现了igb_uio.ko的用户态PMD驱动,通过此驱动来绕过内核,将网卡(寄存器)映射到用户态。
DPDK通过PCI地址的方式绑定网卡,并由dpdk-devbind脚本为网卡绑定驱动,在目录/sys/bus/pci/drivers/生成了igb_uio软链接,从中可获得绑定后的信息。
igb_uio将网卡映射到用户态后(实则将网卡从内核解绑,完成网卡必要的初始化,获取网卡属性并生成系列文件供用户态程序使用),后续DPDK将通过内部注册的网卡驱动完成对网卡的再次纳管。纳管时通过Vendor和Device区配设备和驱动程序 ,如VIRTIO驱动注册支持的{PCI Vendor,Device}如下:
/* VirtIO PCI vendor/device ID. */
#define VIRTIO_PCI_VENDORID 0x1AF4
#define VIRTIO_PCI_LEGACY_DEVICEID_NET 0x1000
#define VIRTIO_PCI_MODERN_DEVICEID_NET 0x1041
仅网卡和驱动的{PCI Vendor,Device}完全匹配时才能成功绑定。执行命令lscpu -n可查看网卡PCI地址的Vendor和Device信息:

参考PCI官网PCI IDS定义:

可见1AF4厂商为Red Hat,且主要支持Virtio类设备(包括网卡、串口、显卡等),其中,网卡设备号为1000和1041。
在网卡成功绑定驱后,参见《接口与设备》章节,VPP会根据vpp startup.conf配置,生成供自己管理的DPDK 设备和接口,完成了与DPDK的对接。
PCI基础
组成计算机系统的主要成为包括CPU、内存、主板+外设。在早期计算机系统中,外设接入CPU存在诸多限制,如受限于CPU总线架构、寻址方式、工作频率等,这些限制导致了外设的读写速率过低、计算机可扩展性差、甚至系统蓝屏现象。这些问题, 直到Peripheral Component Interconnect(直译为外设内联标准,用于CPU对外围设备的连接和控制的标准方式,由Intel提出并制定的标准南桥接入方案)的提出得以解决。
支持PCI的设备在系统开机时,会向系统注册其配置空间,不同的外设将注册到不同的配置空间。配置空间中,配置了包括Device和Vendor信息,以及PCI BAR(基地址)和若干扩展信息。其中,Device和Vendor将指示OS为外设加载合适驱动,参见上文。PCI BAR为系统指示了访问外设的基地址,通过“基地址+寄存器”即可实现对外设的操作。PCI BAR主要包括内存BAR、IO BAR、中断BAR。
通常,系统通过内存映射方式访问外设。基于类UNIX的OS支持虚拟内存Page,进程通过虚拟Page方式共享系统内存;仅在实际发生读写时,将虚拟内存映射到实际的物理内存,并根据映射对象的类型调用对应的驱动指令来实现真实访问;整个过程对进程透明,由OS内存管理负责内存调度。这种虚拟内存Page技术,同时支持将外设内存BAR映射到虚拟地址空间,进程通过访问虚拟地址空间,即可同步访问外设。
VIRTIO 驱动和设备
虚拟化软件,如KVM,为虚机提供了和物理机等同的运行环境,OS不需要关心自己处于虚拟化环境中还是真实的物理环境中,所有外设皆由KVM/Qemu为虚机OS抽象,包括网卡。这些虚拟外设通常以VIRTIO类型提供给虚机,参考如下虚机配置文件:
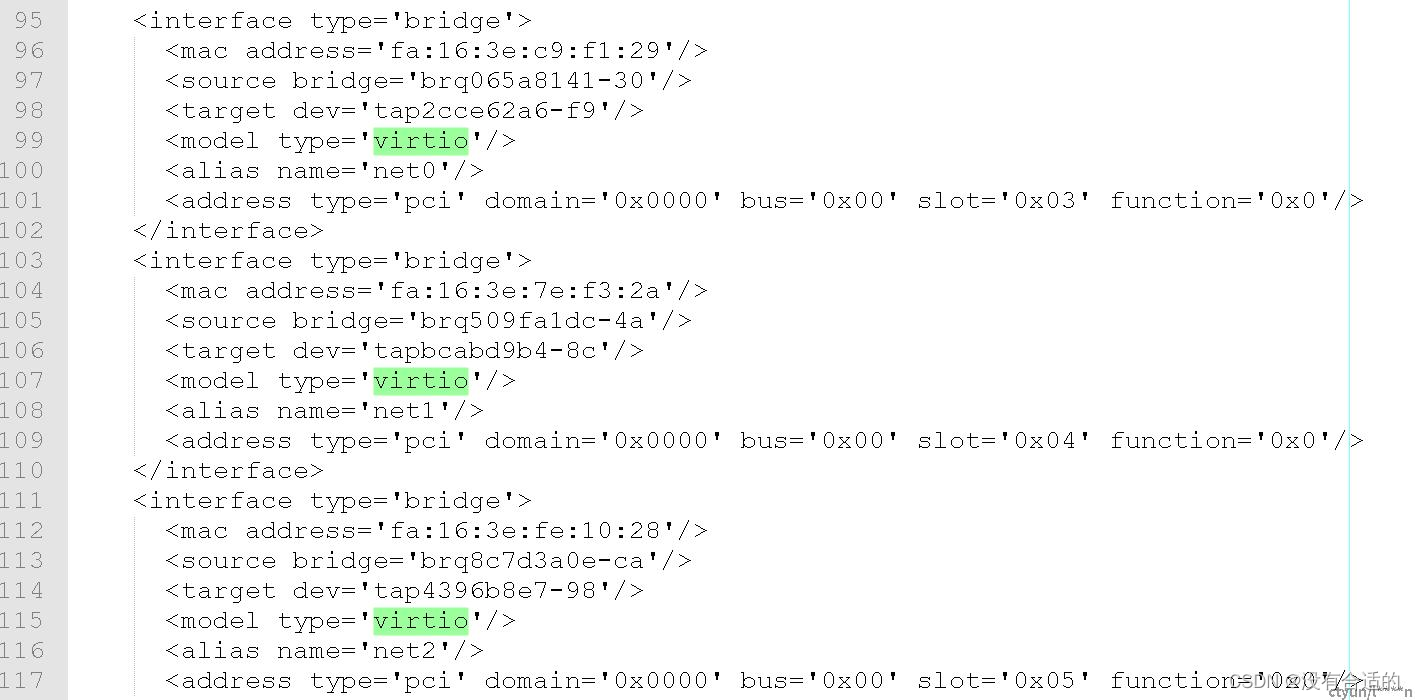
Qemu在拉起虚机OS时,已根据上述配置注入到虚机配置空间,虚机OS启动后,识别PCI设置时,根据Vendor和Device信息加载相应VIRTIO类型驱动来操作虚拟外设。虚拟VIRTIO类型的网卡,可由内核态的virtio-pci驱动管理,或可由用户态的igb_uio驱动管理,具体可以虚机内执行lspci -vvv查看:

上文提到,igb_uio不做实际的网卡收发操作,而交由DPDK完成,一些操作必须在内核完成的,由igb_uio代理,如中断处理。DPDK通过igb_uio对网卡的映射,在用户态空间即可实现对网卡的操作。
VIRTIO Probe
在OS识别到网卡后,实则已用igb_uio驱动完成网卡的加载工作,后续用户态DPDK可基于igb_uio映射的地址信息直接管理网卡,从Probe的字面意思也可见一斑。用户态DPDK中针对不同的厂商和网卡类型实现对应的网卡驱动,搜索"rte_pci_driver"可查看注册的PCI类型的驱动(部分):

驱动通过调用RTE_INIT向DPDK框架注册,注册时,携带了rte_pci_driver指标的参数信息,id表和probe/remove操作函数,其中id表中,含有上文提到的Vendor和Device信息。VIRTIO亦是如此,其向DPDK注册支持{0x1AF4,0x1000}、{0x1AF4,0x1041}两种类型的网卡(参见上文),VIRTIO rte_pci_driver如下:

RTE_INIT宏由RTE_INIT_PRIO展开为:
static void __attribute__((constructor(RTE_PRIO(prio)), used)) func(void)
使rte_eal_iopl_init、rte_pci_register先于main函数执行,这两个函数,主要实现VIRTIO驱动的注册(而非加载),即向rte_pci_bus.driver_list链中挂载驱动识别信息。
PCI Probe
DPDK的总线类型比较丰富,搜索'RTE_REGISTER_BUS'可查看(或直接查看driver/bus/pci目录):

PCI为现代服务器支持的主流扩展总线,DPDK中定义rte_pci_bus来注册PCI总线管理函数:

备注:不同类型的PCI应注册不同的PCI bus,如显卡、磁盘等与网卡不同的设备。
DPDK init
在上述Probe就绪后,DPDK将在main阶段调用rte_eal_init->rte_bus_scan->rte_pci_scan来扫描总线上所有的PCI设备并加载对应驱动(与内核行为一致)。
在《DPDK UIO》提到,DPDK将扫描PCI目录(Linux):/sys/bus/pci/devices,并从调用pci_scan_one逐一识别PCI:

扫描出来的PCI信息将会与rte_pci_bus.device_list中注册的驱动比对(比对Vendor和Device),仅和DPDK注册驱动相匹配的PCI才能被加载。
接着,同scan相同的套路,rte_eal_init->rte_bus_probe->pci_probe加载PCI总线驱动,实现PCI设备化,VIRTIO类型的网卡将调用VIRTIO Probe函数:eth_virtio_pci_probe。
eth_virtio_pci_probe调用rte_eth_dev_pci_generic_probe生成标准的ETH网卡设备(rte_eth_dev eth_dev),并同时调用eth_virtio_dev_init注册设备配置函数,包括设备启停、MTU配置、MAC设置、VIRTIO队列配置等(参见virtio_eth_dev_ops)。
VIRTIO报文收发函数在设备启动函数中配置,即由virtio_dev_start->set_rxtx_funcs设置(回调):
eth_dev->rx_pkt_burst = virtio_recv_pkts
eth_dev->tx_pkt_burst = virtio_xmit_pkts
最终将PCI设备生成了标准的ETH设备,挂载了ETH相关的操作函数,主要的为报文接收和发送函数(参见下文分解)。
VPP init
在《VPP接口与设备》章节提到了VPP将调用dpdk_lib_init初始化DPDK设备为接口(物理接口),实现设备到协议栈的抽象。此函数中,将查询所有DPDK的设备,并同时检查本地startup.conf中配置由DPDK纳管的网卡,并通过调用(dpdk function):
dpdk_device_setup
dpdk_device_startrte_eth_dev_start
rte_eth_dev_configure
rte_eth_tx_queue_setup
rte_eth_rx_queue_setup
rte_eth_dev_set_mtu
正式配置ETH设备,ETH设备到此才正式从OS中脱离并被VPP/DPDK纳管。
备注:参见rte_eth_dev_xxx实现,此类函数中,将调用相应设备注册的配置函数,VIRTIO类型的设备的配置参见virtio_eth_dev_ops。
报文发送
在VPP完成协议处理后,如涉及报文发送,将调用DPDK驱动函数rte_eth_tx_burst,并传入设备ID参数、设备队列ID和待发送的MBUF。其中,VPP发送基于接口而非设备,根据接口和设备的1:1映射关系,即可找到设备ID;设备通常配置为多队列,一般一个队列映射到一个转发Worker上,不同的转发Worker选择不同的设备队列发送数据。
DPDK将根据设备ID找到ETH设备实例,ETH实例中注册了eth_dev->tx_pkt_burst发送回调函数,不同的实例发送函数实现方式不同,但大多基于Queue工作机制,即向网卡发送队列中塞入待发数据,由网卡DMA数据并发送到物理线路。
VIRTIO类型的虚拟网卡基于前后端分离的驱动模式,前端驱动工作于虚机OS内部,后端驱动工作于宿主机。基于VPP/DPDK架构的数据面中,由DPDK作为VIRTIO前端将待发数据写入发送Queue,由于Queu共享于宿主机和虚拟机之间,后端驱动可通过Kernel或OVS或DPDK OVS从发送Queue中直接读出数据,并代为调用网卡发送到物理线路。
报文接收
基于高性能数据转发平面的VPP通常采用Polling轮询调度方案接收数据。DPDK可配置网卡为轮询模式,在网卡接收数据后将DMA塞入数据到接收Queue后,由VPP异步检视接收Queue有的数据,如有,将调用rte_eth_rx_burst尽可能多的批量读取数据。
同报文发送,DPDK将调用ETH实例注册的eth_dev->rx_pkt_burst实现数据接收。VIRTIO使用软队列实现前后端数据交互,前端DPDK中,将数据从接收Queue出队即可。
VIRTIO队列配置
Queue仅仅是packet desc queue,即报文描述符队列,或叫指针队列。与普通网卡操作方式一样,它并不直接存放报文,而是存放报文的指针(即存放DMA转换后可供网卡使用的地址)。它工作在虚机和宿主机之间,Queue由虚机分配(参见virtio_init_queue),并配置到Qemu进程空间进而被宿主机应用感知。
关于如何与外设交互,或读写外设配置,在PCI probe时已配置了相关操作接口,参见:

函数eth_virtio_pci_init->vtpci_init中,将设置VIRTIO_OPS(hw) = &legacy_ops, 后续与外界的交互将通过此类接口进行,包括告知外界发送Queue或接收Queue的地址。
在函数virtio_init_queue中,将根据Qemu xml中的配置(参见 《VIRTIO驱动和设备》)的队列参数来创建queue。期间,将调用VIRTIO_OPS(hw)->setup_queue(hw, vq)将队列共享给后端驱动:

见上述函数,共享队列vq通过rte_pci_ioport_write写入网卡pci配置空间。