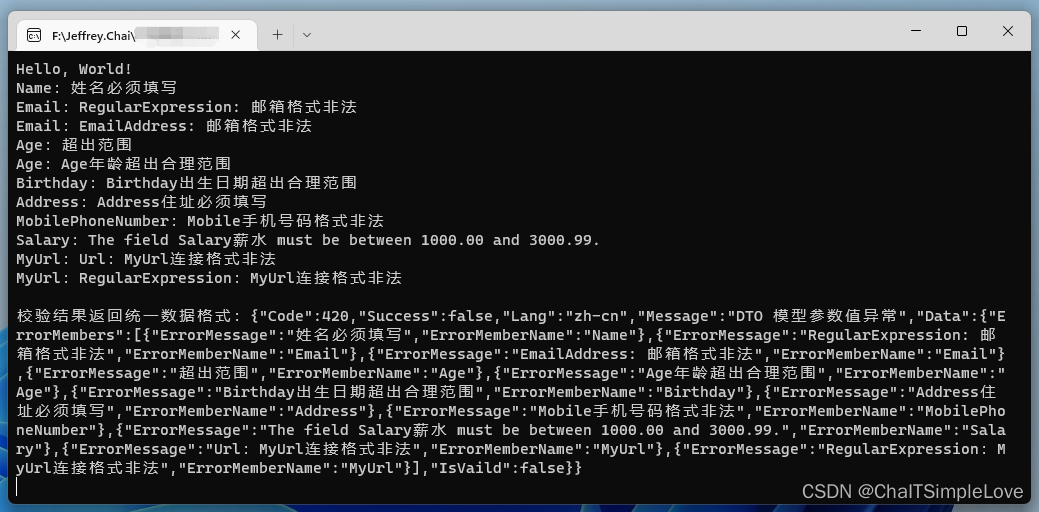
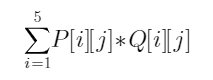Pandas数据结构简介 - Series
来源:Pandas官网:https://pandas.pydata.org/docs/getting_started/intro_tutorials/index.html
笔记托管:https://gitee.com/DingJiaxiong/machine-learning-study

下面将从对 pandas 中的基本数据结构进行快速、非全面的概述开始以入门。
有关数据类型、索引、轴标记和对齐方式的基本行为适用于所有对象。
文章目录
- Pandas数据结构简介 - Series
- 导包
- 【Series类似ndarray】
- 【Series是字典般的】
- 【矢量化操作和标签对齐与系列】
- 【名称属性】
导包
import numpy as np
import pandas as pd
从根本上说,数据对齐是固有的。除非您明确这样做,否则标签和数据之间的链接不会断开。
【Series】
Series 是一个一维标记数组,能够保存任何数据类型(整数、字符串、浮点数、Python 对象等)。轴标签统称为索引。
创建Series的基本方法是调用:
s = pd.Series(data, index=index)
在这里,data可以是许多不同的东西:
-
一个python 字典
-
一个 NDARRAY
-
标量值(如 5)
传递的索引是轴标签的列表。因此,根据数据的不同,这分为几种情况:
① 从ndarray
如果数据是 ndarray,则索引的长度必须与data相同。如果没有传递索引,将创建一个值为 [0, …, len(data) - 1] 的索引.
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s
a 0.314088
b 0.104008
c -0.720088
d 2.083319
e 1.012002
dtype: float64
s.index
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
pd.Series(np.random.randn(5))
0 -0.472511
1 1.090733
2 -1.834285
3 0.140736
4 0.039101
dtype: float64
【注意】pandas 支持非唯一索引值。如果尝试不支持重复索引值的操作,届时将引发异常。
② 从字典
Series可以从字典实例化:
d = {"b": 1, "a": 0, "c": 2}
d
{'b': 1, 'a': 0, 'c': 2}
pd.Series(d)
b 1
a 0
c 2
dtype: int64
如果传递了索引,则会拉出索引中标签对应的数据值。
d = {"a": 0.0, "b": 1.0, "c": 2.0}
d
{'a': 0.0, 'b': 1.0, 'c': 2.0}
pd.Series(d)
a 0.0
b 1.0
c 2.0
dtype: float64
pd.Series(d, index=["b", "c", "d", "a"])
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
【注意】NaN(不是数字)是pandas 中使用的标准缺失数据标记。
③ 从标量值
如果data是标量值,则必须提供索引。该值将重复以匹配索引的长度.
pd.Series(5.0, index=["a", "b", "c", "d", "e"])
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
【Series类似ndarray】
Series的作用与 ndarray 非常相似,是大多数 NumPy 函数的有效参数。但是,切片等操作也会对索引进行切片。
s
a 0.314088
b 0.104008
c -0.720088
d 2.083319
e 1.012002
dtype: float64
s[0]
0.3140880811481063
s[:3]
a 0.314088
b 0.104008
c -0.720088
dtype: float64
s[s > s.median()]
d 2.083319
e 1.012002
dtype: float64
s[[4, 3, 1]]
e 1.012002
d 2.083319
b 0.104008
dtype: float64
np.exp(s)
a 1.369010
b 1.109609
c 0.486709
d 8.031077
e 2.751102
dtype: float64
【注意】我们会在索引部分中解决基于数组的索引,如 s[[4, 3, 1]].
像 NumPy 数组一样,pandas Series只有一个 dtype.
s.dtype
dtype('float64')
这通常是一个 NumPy dtype。但是,pandas 和第三方库在一些地方扩展了 NumPy 的类型系统,在这种情况下,dtype 将是 ExtensionDtype。pandas 中的一些示例是分类数据和可为空的整数数据类型。
如果我们需要支持Series的实际数组,可以使用 Series.array.
s.array
<PandasArray>
[ 0.3140880811481063, 0.10400776543204251, -0.7200878768948227,
2.0833185892885258, 1.0120015026753872]
Length: 5, dtype: float64
当需要在没有索引的情况下执行某些操作(例如,禁用自动对齐)时,访问数组可能很有用。
Series.array 将始终是一个 ExtensionArray。简而言之,ExtensionArray 是围绕一个或多个具体数组(如 numpy.ndarray)的薄包装器。pandas 知道如何获取 ExtensionArray 并将其存储在 DataFrame 的Series或列中。
虽然 Series 是类似 ndarray 的,但如果我们需要实际的 ndarray,可以使用 Series.to_numpy().
s.to_numpy()
array([ 0.31408808, 0.10400777, -0.72008788, 2.08331859, 1.0120015 ])
即使Series由 ExtensionArray 支持,Series.to_numpy() 也会返回一个 NumPy ndarray。
【Series是字典般的】
Series也类似于固定大小的字典,因为我们可以通过索引标签获取和设置值:
s
a 0.314088
b 0.104008
c -0.720088
d 2.083319
e 1.012002
dtype: float64
s["a"]
0.3140880811481063
s["e"] = 12.0
s
a 0.314088
b 0.104008
c -0.720088
d 2.083319
e 12.000000
dtype: float64
"e" in s
True
"f" in s
False
如果索引中不包含标签,则会引发异常:
s["f"]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\core\indexes\base.py:3803, in Index.get_loc(self, key, method, tolerance)
3802 try:
-> 3803 return self._engine.get_loc(casted_key)
3804 except KeyError as err:
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\_libs\index.pyx:138, in pandas._libs.index.IndexEngine.get_loc()
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\_libs\index.pyx:165, in pandas._libs.index.IndexEngine.get_loc()
File pandas\_libs\hashtable_class_helper.pxi:5745, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas\_libs\hashtable_class_helper.pxi:5753, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'f'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Cell In[26], line 1
----> 1 s["f"]
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\core\series.py:981, in Series.__getitem__(self, key)
978 return self._values[key]
980 elif key_is_scalar:
--> 981 return self._get_value(key)
983 if is_hashable(key):
984 # Otherwise index.get_value will raise InvalidIndexError
985 try:
986 # For labels that don't resolve as scalars like tuples and frozensets
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\core\series.py:1089, in Series._get_value(self, label, takeable)
1086 return self._values[label]
1088 # Similar to Index.get_value, but we do not fall back to positional
-> 1089 loc = self.index.get_loc(label)
1090 return self.index._get_values_for_loc(self, loc, label)
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\core\indexes\base.py:3805, in Index.get_loc(self, key, method, tolerance)
3803 return self._engine.get_loc(casted_key)
3804 except KeyError as err:
-> 3805 raise KeyError(key) from err
3806 except TypeError:
3807 # If we have a listlike key, _check_indexing_error will raise
3808 # InvalidIndexError. Otherwise we fall through and re-raise
3809 # the TypeError.
3810 self._check_indexing_error(key)
KeyError: 'f'
使用 Series.get() 方法,缺少的标签将返回 None 或指定的默认值:
print(s.get("f"))
None
s.get("f", np.nan)
nan
也可以按属性访问这些标签.
【矢量化操作和标签对齐与系列】
使用原始 NumPy 数组时,通常不需要逐个值循环。
在pandas 中使用Series时也是如此。Series也可以传递到大多数 NumPy 方法中,期望一个 ndarray。
s
a 0.314088
b 0.104008
c -0.720088
d 2.083319
e 12.000000
dtype: float64
s + s
a 0.628176
b 0.208016
c -1.440176
d 4.166637
e 24.000000
dtype: float64
s * 2
a 0.628176
b 0.208016
c -1.440176
d 4.166637
e 24.000000
dtype: float64
np.exp(s)
a 1.369010
b 1.109609
c 0.486709
d 8.031077
e 162754.791419
dtype: float64
Series和 ndarray 之间的主要区别在于,Series之间的操作会根据标签自动对齐数据。
因此,我们可以编写计算,而无需考虑所涉及的Series是否具有相同的标签。
s[1:] + s[:-1]
a NaN
b 0.208016
c -1.440176
d 4.166637
e NaN
dtype: float64
未对齐Series之间的操作结果将具有所涉及的索引的并集。
如果在某个系列或另一个Series中找不到标签,则结果将被标记为缺少 NaN。能够在不进行任何显式数据对齐的情况下编写代码,为交互式数据分析和研究提供了巨大的自由度和灵活性。pandas 数据结构的集成数据对齐功能使 pandas 与大多数用于处理标记数据的相关工具区分开来。
【注意】
通常,我们选择使不同索引对象之间的操作的默认结果产生索引的联合,以避免信息丢失。尽管缺少数据,但具有索引标签通常是计算中的重要信息。当然,您可以选择通过dropna功能删除缺少数据的标签。
【名称属性】
Series还具有name属性:
s = pd.Series(np.random.randn(5), name="something")
s
0 0.302426
1 0.924330
2 0.393936
3 0.377490
4 -0.446103
Name: something, dtype: float64
s.name
'something'
在许多情况下,可以自动分配Series名称,特别是从DataFrame中选择单个列时,将为name分配列标签。
我们可以使用pandas 重命名Seriespandas.Series.rename() 方法。
s2 = s.rename("different")
s2.name
'different'
注意,s 和 s2 指的是不同的对象。