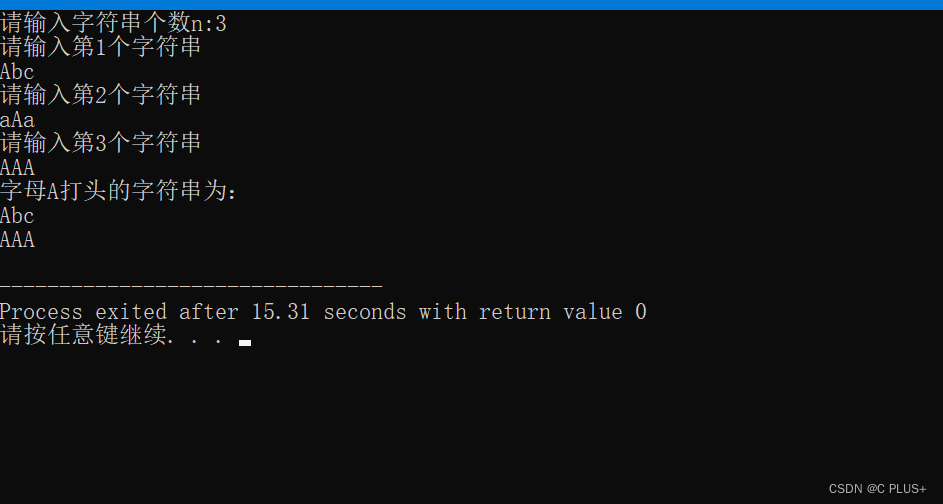
前两篇中我们讨论了节点层级的特征表示、边层级的特征表示:
- CS224W2.1——传统基于特征的方法(节点层级特征)
- CS224W2.2——传统基于特征的方法(边层级特征)
在这篇中,我们将重点从整个图中提取特征。换句话说,我们想要描述整个图结构的特征。具体来说,我们感兴趣的是测量两个图之间相似性的图核方法。我们将描述提取这种图核的不同方法,包括Graphlet特性和WL核。
文章目录
- 1. 目标
- 2. Kernel Methods
- 2.1 Graph Kernel的作用
- 2.2 Graph Kernel的核心思想
- 2.3 Graphlets Kernel
- 2.4 Weisfeiler-Lehman Kernel
- 3. 总结
1. 目标
目标是:我们想要一个特征来描述整个图的结构。

2. Kernel Methods

这种核方法广泛应用于传统的图层级预测上。
这种方法的思想是:设计核(kernels)代替特征向量。
核矩阵 K = ( K ( G , G ′ ) ) K=(K(G,G')) K=(K(G,G′))必须有正的特征值,可以表示为两个向量的乘积。
2.1 Graph Kernel的作用

Graph Kernels可以去计算两个图的相似程度。
这里应该要讲两种:
- Graphlet Kernel
- Weisfeiler-Lehman Kernel
2.2 Graph Kernel的核心思想

内核目标的关键思想是定义一个特征向量 ϕ ( G ) \phi(G) ϕ(G)
我们将这个特征向量 ϕ ( G ) \phi(G) ϕ(G)作为图的词袋(bag-of-words)类型表示。
其中词袋(bag-of-words)是:当我们有文本文档时,我们表示文本文档的一种方式,就是简单地将其表示为一袋单词。基本上我们会说,对于每个单词,我们记录该单词在文档中出现的频率。我们可以考虑,比如,按字母顺序排序的单词,然后,你知道,在这个词袋表示的位置i,我们会得到单词i在文档中出现的频率,出现的次数。
同样地,把这个想法简单地推广到图中就是把节点看作词。
问题是:由于图的结构可能非常不同,但节点数量相同,我们会得到相同的特征向量,或者两个不同图的相同表示。

2.3 Graphlets Kernel




一些问题:

2.4 Weisfeiler-Lehman Kernel









WL Kernel的方法时间复杂度与边数成线性关系,说明他效率比较高。
3. 总结