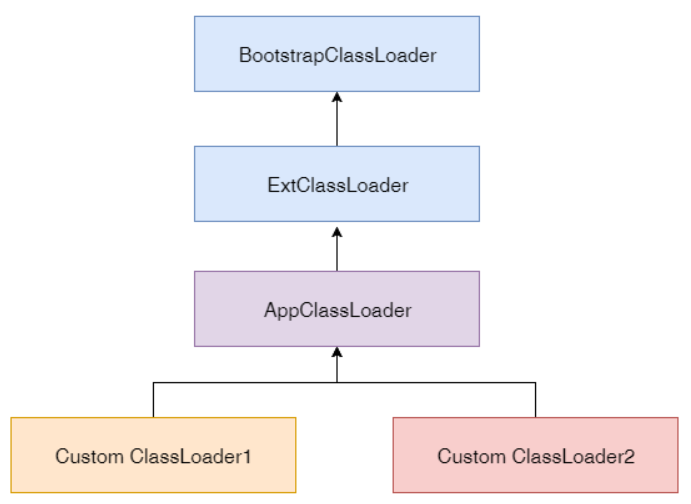
一、训练流程
1. 特征提取
提取N个输入图像的深层特征用作深度匹配
与传统三维重建方法类似,第一步是提取图像特征(SIFT等特征子),不同点在于本文使用8层的卷积网络从图像当中提取更深层的图像特征表示,网络结构如下图所示:
输入:N张3通道的图像,宽高为W,H
输出:N组32通道图,每通道尺度为H/4,W/4
虽然特征提取后图像帧缩小,但每个剩余像素的原始相邻信息已经被编码到32通道像素描述符中,防止了密集匹配丢失有用的上下文信息。
【就是尺寸变小但是通道数增加,不同的通道可以保存更多有用的信息】
在计算机视觉中,图片的比例取W/4和H/4是因为在一些特定的任务和网络架构中,使用降低的尺寸可以提高计算效率,并且有助于提取更高级的特征。
通常,处理全尺寸图像可能会导致计算负荷过大和内存占用过高的问题。通过将图像尺寸缩小为原尺寸的1/4,可以显著减少计算和内存需求,加速模型的训练和推理过程。
此外,采用缩小尺寸的图片还有助于网络模型更好地感知和捕捉图像中的重要细节和特征。尺寸缩小会导致图像信息丢失,但同时也可以通过允许更大的**感受野( receptive field)**来提取更宽广的上下文信息,从而帮助网络学习到更具有区分性的特征。
2. 构建特征体(Feature Volume)
将提取的特征图和输入图建立一个3D成本体积(之前方法使用的体积或者点云重建,本文使用深度图重建)
2.1 单应性变换
实现端到端训练
单应性变换(Homography Transform)是指在平面几何中,将一个平面上的点集映射到另一个平面上的点集的线性变换。它是一种二维投影变换。
单应性变换简单来说,对于3D空间的点X,我们通过相机1拍照,得到照片1上的对应二维像素点P(x,y);在另一个位置用相机2拍照,得到照片2上的对应二维像素点P’(x’,y’)——通过一个正确的单应矩阵H(包含相机1,2的位置转换参数R,T、相机1到点X的距离d),可以实现P’ = HP(点到点的映射)。即在已经提前获取相机的内外参数前提下,因此只需要一个深度值变量,就可以找到参考图像上点P对应在源图像上点P’的位置。

若我们已知两个位姿的相机参数(相机1,2的位置转换参数),现在设置一个深度区间[d1,d2],并设置分辨率为Δd,由此得到D=(d2-d1)/Δd个平面,那么每个d都对应了一个单应变换矩阵h。
如果对一张图片上每个像素点,使用di对应的矩阵hi进行变换可以得到一张变换后的图片,意义为假设各个像素点真实深度都为d时,在另一位姿下各像素点的应有的对应特征值。
而我们假设了D个深度,也即将得到D幅变换后的图像,各图代表了其像素点真实深度为当前深度时变换对应的特征值,即可理解为上图中各层蓝色由深变浅的图层。
为什么是“锥形视锥”,因为当单应矩阵对应的真实深度不同时,由近大远小原理可知能被当前位置的相机看到的特征点数量随着深度减小而减小,因而出现锥形。(在下一步构建特征体时使用了双线性插值来保证所有深度的特征图尺寸一致)
2.2 特征体构建

在本文当中,我们通过特征提取得到的是N个特征图(1个参考图(估计图)、N-1个原图(辅助图)),每个特征图有32通道。
每个特征图可以理解为一本书,有32页,每页尺寸是HxW
那么,一本书(一个特征体)通过2.1中的单应变换就变成了一摞书,等于将原来第一页通过深度为[d1,d2]的矩阵[h1,h2]变换成n个深度下的第一页,将原来第二页变成n个深度下的第二页……
此时,一本书 = 某深度d
书的某页 = 某深度下某特征通道
书的某页上某字 = 某深度下某特征通道某点的特征
将src(参考图)坐标系下的特征图投影到ref(估计图)坐标系,分别构建cost volume
需要注意的是,对于Ref的特征图则是直接在每个深度下复制,因为多个Src都是要变换到这个参考图下的
待估计的图像称为reference_image(ref),其余视角下的辅助图像称为source_image(src)
**Ref特征图(Ref Feature Map)**是一种用于图像超分辨率重建的中间表示。在图像超分辨率重建任务中,Ref特征图是通过神经网络从低分辨率输入图像中提取的一组特征图。
Ref特征图通常由多个通道组成,每个通道包含不同的特征信息。这些特征信息可以包括低级的边缘、纹理信息,以及更高级的语义信息。通过对这些特征进行处理和合成,可以提取出有关图像结构和内容的高级表示。
在图像超分辨率重建中,Ref特征图扮演着关键的角色。它被用来模拟低分辨率输入图像的高分辨率版本,并指导神经网络生成相应的重建图像。Ref特征图能够捕捉低分辨率图像中的细节、边缘和纹理信息,以及其与高分辨率图像之间的对应关系,从而帮助提升重建图像的质量和细节保持程度。
通过结合Ref特征图和其他网络模块,如超分辨率网络或生成对抗网络,可以实现图像超分辨率重建任务。Ref特征图的准确性和有效性对于最终的重建结果具有重要影响。因此,设计和提取有意义的Ref特征图是图像超分辨率重建算法中的关键挑战之一。
3. 生成代价体(Cost Volume)

经过上一步后我们得到了不同视角下的cost volume。由于我们不想固定src图像的数量(能够接受任意N个输入的原因),为了提高模型的泛化性,作者采用了基于方差的特征融合方法。
适应任意数量的输入视图(选择了“方差”运算,因为“均值”运算本身没有提供关于特征差异的信息)
通过第2步我们得到了N摞书,现在竖着看每摞书的第一本,代表了假设深度为d1时,各特征图上各像素经过变换后的特征值——若某个像素真实深度接近d1的话,那变换后该列该处的特征值应该是近似的。
基于这样的想法,对每一列书的每一页上的每个像素计算方差,代表了假设深度为di时,各图像特征图的各通道各特征点的差异情况,方差越小,越相似,该特征点真实深度就越可能是di。
该步得到了一摞书,每本书 = 一个深度
每页 = 某深度下特征图一个通道
页上的点 = 该深度下特征图某通道上点的相似程度,方差越小越相似
这里就是论文所说能够接受任意N个输入的原因,因为是取方差所以输入几个都一样。
代价体(Cost Function)也被称为损失函数(Loss Function)或目标函数(Objective Function)。它是用于衡量模型预测结果与真实值之间差异的一种函数。 在本节中指的就是对特征图的同一通道上的个点求的方差
4.代价体正则化(Cost Volume Regularization)
正则化步骤旨在细化上述成本体积C,以生成用于深度推断的概率体积P
受物体表面材质、物体遮挡等影响,上述融合后的cost volume可能包含噪声或在部分遮挡地区存在匹配错误的情况。作者利用了一个类似于3D-Unet的网络对cost volume在channel上进行归一化操作。这样,原先像素上每个depth上对应一个向量,经过归一化后对应了一个数。这个数的含义可以理解为:像素对应的深度为depth的概率。
在第3步中得到了代价体,但论文说 “The raw cost volume computed from image features could be noise-contaminated” ,即这个代价体由于非朗伯面、遮挡等原因是包含噪声的,要通过正则化来得到一个概率体P(probability volume),具体采用了一个类似UNet的网络结构,对原代价体进行编码和解码,并最终将各通道数压缩为1,即将一摞书变成了一本书

此时书 = 概率体
每页 = 某深度
页上的点 = 该点在该深度的概率
如对(H,W)平面上的一点(x,y),若在深度d处值最大,该点深度为d
Softmax函数是一种常用的激活函数,常用于多类别分类任务中。它的基本原理是将输入的实数向量转换为一个概率分布向量,使得每个元素都表示对应类别的概率。
Softmax函数的计算公式如下:
softmax(x_i) = exp(x_i) / sum(exp(x_j))其中,x_i是输入向量的第i个元素,exp表示自然指数函数,sum(exp(x_j))是计算所有输入元素的指数的和。
Softmax函数的基本思想是通过对每个元素进行指数转换,使得每个元素的值变得非负。然后,将这些转换后的值除以所有元素的和,以确保概率分布的归一化。
Softmax函数的作用是使得输入向量的每个元素的取值范围在0到1之间,并且所有元素的和等于1。这样可以表示每个元素对应类别的概率,用于多类别分类问题中的决策和预测。
把多个通道特征压缩成一个通道,直观想法是保留其中方差最小(最可能属于当前深度)的那个通道的特征,然后方差越小说明这个像素点的深度越可能是当前层深度;但文章说是出于噪声目的试用网络来正则化获得最终的概率体,不太理解为什么要用这个UNet网络。
我感觉实际上就是通过softmax回归来保留概率最大的那个通道的特征
CostRegNet网络:
class CostRegNet(nn.Module):
def __init__(self):
super(CostRegNet, self).__init__()
self.conv0 = ConvBnReLU3D(32, 8)
# 为了进一步减少计算量,在第一个3D卷积层之后,我们将32通道的开销体积减少到8通道,并将每个尺度内的卷积从3层改为2层
self.conv1 = ConvBnReLU3D(8, 16, stride=2)
self.conv2 = ConvBnReLU3D(16, 16)
self.conv3 = ConvBnReLU3D(16, 32, stride=2)
self.conv4 = ConvBnReLU3D(32, 32)
self.conv5 = ConvBnReLU3D(32, 64, stride=2)
self.conv6 = ConvBnReLU3D(64, 64)
self.conv7 = nn.Sequential(
nn.ConvTranspose3d(64, 32, kernel_size=3, padding=1, output_padding=1, stride=2, bias=False),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True))
self.conv9 = nn.Sequential(
nn.ConvTranspose3d(32, 16, kernel_size=3, padding=1, output_padding=1, stride=2, bias=False),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True))
self.conv11 = nn.Sequential(
nn.ConvTranspose3d(16, 8, kernel_size=3, padding=1, output_padding=1, stride=2, bias=False),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True))
# 最后一个卷积层输出1通道体积
# in_channels=8,out_channels,kernel_size=3,stride=1,padding=1
self.prob = nn.Conv3d(8, 1, 3, stride=1, padding=1)
def forward(self, x):
conv0 = self.conv0(x)
conv2 = self.conv2(self.conv1(conv0))
conv4 = self.conv4(self.conv3(conv2))
x = self.conv6(self.conv5(conv4))
x = conv4 + self.conv7(x)
x = conv2 + self.conv9(x)
x = conv0 + self.conv11(x)
x = self.prob(x)
return x
5. 深度图初始估计(Depth Map Initial Estimation)

利用第4步的概率体, 将深度估计的质量定义为地面实况深度在估计附近的小范围内的概率。 沿深度d方向(就是上一步中softmax概率最大的深度)求期望,就得到对应像素点的初始深度值;
对每个像素点求期望,即将概率体变成了一张概率图。
6. 深度图优化(Depth Map Refinement)

应用了深度残差学习网络 (ResNet) 就是将输入直接连到后面的层,使得后面的层可以直接学习残差。
初始深度图和调整大小的参考图像(将其缩小1/4)被连接为4通道输入,然后通过三个32通道2D卷积层,然后通过一个1通道卷积层来学习深度残差。然后将初始深度图添加回以生成细化的深度图。最后一层不包含BN层和ReLU单元,以便学习负残差。此外,为了防止在某个深度尺度上产生偏差,我们将初始深度幅度预先缩放到[0,1]范围,并在细化后将其转换回 。
?为什么融合以后就成4通道了
参考图-》src
感受野(Receptive Field)是指在神经网络模型中,一个特定层的输出值受输入图像区域的影响范围。它代表了一个特定位置的输出值对输入图像上不同位置的感受程度。
在卷积神经网络(Convolutional Neural Network, CNN)中,每一层都由多个卷积核或滤波器组成,这些滤波器对输入数据进行卷积操作,以提取特征。每个滤波器对应一个感受野。
感受野的大小取决于网络的结构和每一层的设计。通常,感受野的大小由卷积核的大小和网络层数决定。在较低层,感受野相对较小,只能捕捉到少量的局部特征。随着网络的深层化,感受野逐渐增大,可以捕捉到更大范围的特征和上下文信息。
感受野的概念有助于理解和解释神经网络的输出是如何受到输入图像的局部和全局信息影响的。通过增加网络的深度和扩大感受野的范围,网络可以更好地理解和解析输入图像中的语义信息,提取更高级的特征。
在一些任务中,特别是目标检测和图像分割等任务中,感受野大小的合理选择对于捕捉目标的上下文信息和边界特征至关重要。较小的感受野可能导致模型在处理大物体或全局上下文时失去一些细节和全局信息,而较大的感受野可能对于捕捉局部细节和小目标不够敏感。因此,在网络设计中需要根据任务和数据的特点合理选择感受野的大小。
7. 损失计算
使用地面实况深度图和估计深度图之间的平均绝对差作为我们的训练损失
只考虑那些具有有效地面实况标签的像素

loss1:

二、后处理
论文在摘要中提到*“With simple post-processing”*之后模型效果很好,这个post-processing主要包括深度图滤波和深度图融合两部分-》 即在将结果转换为密集点云之前,有必要过滤掉这些背景和遮挡区域的异常值
1. 深度图滤波(Depth Map Filter)

1.1 光度约束
光度一致性衡量匹配质量
光度约束,其实是在通过概率体得到初始深度图的同时计算了一个概率图

各像素点的深度越集中在某个深度附近,则该点深度判断的准确概率越高,最后过滤掉概率小于0.8的点。
1.2 几何约束
几何约束度量多个视图之间的深度一致性
首先几何约束比较简单,就是说将参考点p1通过其估计深度d1投影至源视角pi点,再将pi点通过其深度估计di重投影至参考视角preproj点,这个重投影后的preproj点深度估计为dreproj,若满足
∣ p r e p r e j − p 1 ∣ < 1 ∣ d r e p r o j − d 1 ∣ d 1 < 0.01 | p _ { r e p r e j } - p _ { 1 } | < 1 \quad\frac { | d _ { r e p r o j } - d _ { 1 } | } { d _ { 1 } } < 0 . 0 1 ∣preprej−p1∣<1d1∣dreproj−d1∣<0.01
则说是满足几何约束的( 我们说p1的深度估计d1是两视图一致的 ),论文里保证三视图满足该几何约束一致性。
2. 深度图融合(Depth Map Fusion)

即在多个视角下推测深度图,并采取特定融合算法融合;其中每个深度图的像素深度选择是使用了几何约束时计算的重投影的均值作为最终深度估计。
三、总结