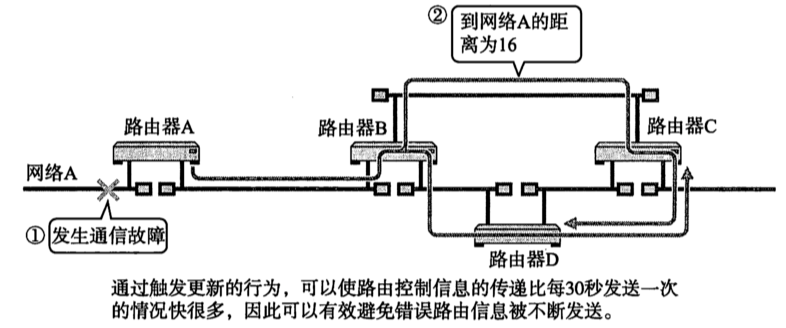
Kafka消息写入流程
0,写入消息简要流程图

1,从示例开始
在Kafka中,Producer实例是线程安全的,通常一个Producer的进程只需要生成一个Producer实例.
这样比一个进程中生成多个Producer实例的效率反而会更高.
在Producer的配置中,可以配置Producer的每个batch的内存缓冲区的大小默认16kb,或者多少ms提交一次,
这种设计参考了Tcp的Nagle算法,让网络传输尽可能的发送大的数据块.
非事务型示例
Kafka 3.0开始,是否启用冥等性的enable.idempotence 配置默认为true.
此配置只能保证单分区上的幂等性,即一个幂等性Producer能够保证某个主题的一个分区上不出现重复消息,它无法保证多个分区的幂等性.
//构建生成`KafkaProducer`的配置项.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("linger.ms", 200);props.put("batch.size", 16384);
//serializer建议使用byteArray/byteBuffer.
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//生成实例并向kafka发送消息.
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i),
Integer.toString(i)));
//所有操作结束,关闭producer.
producer.close();
事务型示例
- 设置事务型Producer有2个要求(后续在分析kafka中的事务实现):
- 和幂等性Producer一样,开启
enable.idempotence= true. - 设置Producer端参数
transactional.id. 此配置设置一个transactionId,当然最好能代表业务场景. - 在brokerServer的配置中,
min.insync.replicas配置的值必须大于1.
- 和幂等性Producer一样,开启
//构建生成事务型`KafkaProducer`的配置项.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
//serializer建议使用byteArray/byteBuffer.
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
//此时KafkaProducer的api并没有变化,只是通过producer直接开始事务即可.
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i),
Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
producer.abortTransaction();
}
producer.close();
2,KafkaProducer初始化
a,配置项
"bootstrap.servers" : brokerServer链接信息的配置,host:port,多个用","号分开.
"buffer.memory" : 默认值32mb,Producer端的内存缓冲区的大小.
"max.block.ms" : 默认值1分钟,当内存缓冲区被填满(生产速度大于了网络传输速度),producer的backOff时间.
"batch.size" : 默认值(16kb),内存缓冲区内每一个batch的大小,当producer写入达到一个batch后,此batch将会被提交.
"linger.ms" : 默认值(0),与"batch.size"配合使用,当batch未达到大小,batch的最大内存缓冲时间.
这个配置在根据node节点范围内有效,即对应node的partition中只要有一个超时,就会处理所有partition.
"request.timeout.ms" 默认(30秒),producer等待请求响应的超时时间,应该大于broker中的`replica.lag.time.max.ms`配置时间.
"delivery.timeout.ms" 默认(2分钟),send数据后(添加到内存缓冲区的时间),等待ack的超时时间,
这个值应该大于requestTimeout+lingerMs的和.
"retry.backoff.ms" 默认值(100ms),请求失败后的重试间隔时间.
"max.request.size" 默认值(1mb),单次网络请求的send数据的上限(建议是batchSize的倍数).
"enable.idempotence" 默认值(true),是否启用冥等性.
"transactional.id" 没有默认值,配置一个字符串值,用于记录此producer对应的事务ID.
跨多个producer的冥等性保证,但是broker节点最少需要三个.
"transaction.timeout.ms" 默认值(1分钟),用于配置transaction的超时时间.
"acks" 默认值(all/-1),可配置(all,0,1),producer响应ack的状态
0=>表示不管broker是否写入成功.
1=>表示只需要leader写入成功(这可能在副本切换时导致数据丢失)
all/-1 => 需要所有副本都写入成功,冥等性必须设置为此值.
"max.in.flight.requests.per.connection" 默认值(5),单个node可同时进行的请求的数量,
如果启用"enable.idempotence"时,这个值必须小于或等于5.
"metadata.max.age.ms" 默认值(5分钟),定时刷新metadata的时间周期.
"metadata.max.idle.ms" 默认值(5分钟),metadata的空闲时间,当超过这个时间metadata会被丢弃下次请求时重新获取.
"partitioner.class" 用于对record进行partition的区分, Partitioner接口的实现.
"partitioner.ignore.keys" 默认值(false),当设置为false,同时key不为null的情况下,使用hash分区,
如果指定了partitioner.class,这个配置无效.
"partitioner.adaptive.partitioning.enable" 默认值(true),是否让处理更快的partition分区更多的处理消息.
"partitioner.availability.timeout.ms" 默认值0,与上面的配置配合使用
如果Partition无法在指定的超时时间处理producer的消息,则认为parition不可用.
"compression.type" record压缩算法,可配置zstd,lz4,snappy, gzip
b,KafkaProducer实例初始化
Step=>1
根据是否配置enable.idempotence,默认值true,如果配置为true时,初始化TransactionManager实例.
this.transactionManager = configureTransactionState(config, logContext);
//初始化TransactionManager实例.
private TransactionManager configureTransactionState(ProducerConfig config,
LogContext logContext) {
TransactionManager transactionManager = null;
//只有`enable.idempotence`配置为`true`时,TransactionManager实例才会被初始化.
if (config.getBoolean(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG)) {
final String transactionalId = config.getString(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
final int transactionTimeoutMs = config.getInt(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG);
final long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
transactionManager = new TransactionManager(
logContext,transactionalId,
transactionTimeoutMs,retryBackoffMs,apiVersions
);
//根据是否配置`transactional.id`来判断是否开启事务.
if (transactionManager.isTransactional())
log.info("Instantiated a transactional producer.");
else
log.info("Instantiated an idempotent producer.");
} else {
// ignore unretrieved configurations related to producer transaction
config.ignore(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG);
}
return transactionManager;
}
Step=>2
生成用于producer使用的内存缓冲区RecordAccumulator,
所有对Producer的send操作都将向此accumulator的内存缓冲区内添加,由专门的Sender线程来负责发送并释放内存.
其内部的BufferPool即是accumulator使用的内存池,每一个batch都需要向此内存池申请内存.
在kafka中所有的消息写入都是以batch为基础,标准batch的大小由batch.size配置,默认为16kb.
boolean enableAdaptivePartitioning = partitioner == null &&
config.getBoolean(ProducerConfig.PARTITIONER_ADPATIVE_PARTITIONING_ENABLE_CONFIG);
RecordAccumulator.PartitionerConfig partitionerConfig = new RecordAccumulator.PartitionerConfig(
enableAdaptivePartitioning,
config.getLong(ProducerConfig.PARTITIONER_AVAILABILITY_TIMEOUT_MS_CONFIG)
);
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType, lingerMs(config),
retryBackoffMs, deliveryTimeoutMs,partitionerConfig,
metrics,PRODUCER_METRIC_GROUP_NAME,time,
apiVersions,transactionManager,
//环形内存缓冲区,其内部分为池化内存与非池化内存.
new BufferPool(this.totalMemorySize,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
metrics, time, PRODUCER_METRIC_GROUP_NAME
)
);
Step=>3
根据BOOTSTRAP_SERVERS_CONFIG配置,初始化ProducerMetadata实例,此实例用于维护metadata在producer端的cache信息.
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG));
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new ProducerMetadata(retryBackoffMs,
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
this.metadata.bootstrap(addresses);
}
Step=>4
生成producer向broker端发起请求的NetworkClient实例,并根据实例初始化并启动Sender线程.
此线程用于将RecordAccumulator中已经完成的batch发送到对应partition的leaderBroker端.
注意:此线程是一个守护线程(daemon).
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
//newSender生成网络处理线程的实现.
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
int maxInflightRequests = producerConfig.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION);
int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time, logContext);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
//生成用于向`broker`发起网络请求的NetworkClient实例.
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
metadata,
clientId,
maxInflightRequests,
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
//生成用于发送网络请求的线程.
short acks = Short.parseShort(producerConfig.getString(ProducerConfig.ACKS_CONFIG));
return new Sender(logContext,
client,
metadata,
this.accumulator,
maxInflightRequests == 1,
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),//单次请求的最大bytes.
acks,
producerConfig.getInt(ProducerConfig.RETRIES_CONFIG), //此配置通常保持默认值.
metricsRegistry.senderMetrics,
time,
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
}
c,更新Metadata
当Sender线程在不断轮询过程中,在调用执行到NetworkClient.poll函数或sendProducerData时,
会执行metadataUpdater(实现类DefaultMetadataUpdater)中的maybeUpdate函数,
此函数判断当前Producer中cache的metadata是否过期,过期时间由metadata.max.age.ms配置(默认5分钟).
(注意:如果是Producer初始化后的第一次轮询时,也表示超时.)
如果metadataCache过期后会发起MetadataRequest请求,来获取producer需要的metadata信息(topicInfo,brokers).
//这里会向随机的一个由"bootstrap.servers"配置的broker节点(或metadataCache中的节点)发起请求(如果超时).
//==>`metadataupdater`的实现在Producer端默认为`NetworkClient.DefaultMetadataUpdater`.
long metadataTimeout = metadataUpdater.maybeUpdate(now);
..........
void sendInternalMetadataRequest(MetadataRequest.Builder builder, String nodeConnectionId, long now) {
ClientRequest clientRequest = newClientRequest(nodeConnectionId, builder, now, true);
doSend(clientRequest, true, now);
}
//生成向broker请求的metadataRequest信息
protected MetadataRequest.Builder newMetadataRequestBuilder() {
return MetadataRequest.Builder.allTopics();
}
在Producer端,发起MetadataRequest请求时,会设置topics参数的值为null,表示获取集群中所有的topic信息.
如果ProducerMetadata实例中的newTopics容器不为空时,会只请求此部分的topics的metadata信息.
此请求在Broker端接收到后,会直接由KafkaApis中的handleTopicMetadataRequest进行处理.
而此请求的返回信息包含当前cluster中所有的topics信息与当前处于active状态的所有borker节点.
Producer发起的Metadata请求,在broker端成功响应后,
会交由NetworkClient中DefaultMetadataUpdater实例的handleSuccessfulResponse处理程序处理.
而在handleSuccessfulResponse处理程序中,其核心处理代码如下所示:
this.metadata.update(inProgress.requestVersion, response, inProgress.isPartialUpdate, now);
可以看到,当DefaultMetadataUpdater接收到broker的响应后,直接交给了ProducerMetadata实例进行处理.
而在Metadata.update的处理程序中,主要根据请求的响应重新生成MetadataCache实例,如下所示:
*=>1*, 更新metadata的刷新时间,此时间用于判断metadata是否过期.
//更新metadata的刷新时间.
this.lastRefreshMs = nowMs;
this.updateVersion += 1;
//判断是否是部分更新(newTopics容器不为空时,表示部分更新)
if (!isPartialUpdate) {
this.needFullUpdate = false;
this.lastSuccessfulRefreshMs = nowMs;
}
*=>2*, 根据Metadata请求的响应结果(clusterId,activeBrokers,topics,partitions)生成MetadataCache.
//根据请求的响应,生成MetadataCache.
this.cache = handleMetadataResponse(response, isPartialUpdate, nowMs);
//handleMetadataResponse中生成MetadataCache实例.
Map<Integer, Node> nodes = metadataResponse.brokersById();
//`isPartialUpdate == true`表示是增量更新(即partition的Leader发生切换后的增量metadata更新)
//==>或者producer要写入的record对应的topic在当前cache中不存在(新创建)
if (isPartialUpdate)
return this.cache.mergeWith(metadataResponse.clusterId(), nodes, partitions,
unauthorizedTopics, invalidTopics, internalTopics, metadataResponse.controller(), topicIds,
(topic, isInternal) -> !topics.contains(topic) && retainTopic(topic, isInternal, nowMs));
//全是更新,直接根据response生成metadataCache.
else
return new MetadataCache(metadataResponse.clusterId(), nodes, partitions,
unauthorizedTopics, invalidTopics, internalTopics, metadataResponse.controller(), topicIds);
d,InitProducerId(非事务)
client端发起请求
所谓的非事务场景即是Producer端配置有冥等性enable.idempotence == true,但事务idtransactional.id未配置的情况下,
此时Producer端会通过TransactionManager组件来初始化获取当前Producer的ProducerId.
即:当Sender线程启动后,runOne函数轮询过程时,
会在执行如下代码片段时判断ProducerId是否初始化,如果未初始化,发起InitProducerId请求:
if (transactionManager != null) {
try {
.....................
//非事务场景下,获取冥等性支持的ProducerId的值(如果还未获取).
//==>或broker响应`UNKNOWN_PRODUCER_ID`或`OUT_OF_ORDER_SEQUENCE_NUMBER`错误代码时.
//==>此时会把`InitProducerId`请求生成
transactionManager.bumpIdempotentEpochAndResetIdIfNeeded();
//处理TransactionManager组件相关的请求,如`InitProducerId`等,向broker端发起请求.
if (maybeSendAndPollTransactionalRequest()) {
return;
}
} catch (AuthenticationException e) {
log.trace("Authentication exception while processing transactional request", e);
transactionManager.authenticationFailed(e);
}
}
当ProducerId未初始化时,在执行bumpIdempotentEpochAndResetIdIfNeeded函数时会生成InitProducerId请求.
如下部分是函数实现的部分代码片段:
if (currentState != State.INITIALIZING && !hasProducerId()) {
transitionTo(State.INITIALIZING);
InitProducerIdRequestData requestData = new InitProducerIdRequestData()
.setTransactionalId(null)
.setTransactionTimeoutMs(Integer.MAX_VALUE);
InitProducerIdHandler handler = new InitProducerIdHandler(
new InitProducerIdRequest.Builder(requestData), false)
;
enqueueRequest(handler);
}
可以看到,针对InitProducerIdRequest请求的处理程序实现为InitProducerIdHandler.
在非事务的场景下,InitProducerIdHandler的coordinatorType为null.因此:
在maybeSendAndPollTransactionalRequest函数发送请求时,会从metadataCache中随机获取一个broker节点.
并通过此broker节点发起InitProducerId请求,如下代码片段:
//非事务场景下,直接调用NetworkClient中的leastLoadedNode来随机获取一个broker发起请求.
targetNode = coordinatorType != null ?
transactionManager.coordinator(coordinatorType) :
client.leastLoadedNode(time.milliseconds());
............
long currentTimeMs = time.milliseconds();
ClientRequest clientRequest = client.newClientRequest(
targetNode.idString(), requestBuilder, currentTimeMs,
true, requestTimeoutMs, nextRequestHandler);
log.debug("Sending transactional request {} to node {} with correlation ID {}"..);
client.send(clientRequest, currentTimeMs);
transactionManager.setInFlightCorrelationId(clientRequest.correlationId());
此请求在broker端将由TransactionCoordinator中的handleInitProducerId处理程序进行处理.
broker端处理请求
当broker端接收到InitProducerId请求后,会交由TransactionCoordinator组件来进行处理.
此组件在每个broker进程中都包含一个,在没有事务的场景下,此组件用于管理producer对应的produdcerId信息(随机到任意的broker节点),
而在有事务的场景下,每个broker实例中的transactionCoordinator负责一组分配到此broker的事务id.
TransactionCoordinator.handleInitProducerId(非事务场景)
//非事务场景下,Producer获取ProducerId的处理.
if (transactionalId == null) {
val producerId = producerIdManager.generateProducerId()
responseCallback(InitProducerIdResult(producerId, producerEpoch = 0, Errors.NONE))
}
从上面的代码片段中可以看到,在TransactionCoordinator组件中,在处理非事务场景下的producerId的申请时,
只是简单的直接通过调用ProducerIdManager中的generateProducerId函数来生成producerId,并响应给Producer端.
而在ProducerIdManager组件中,会首先向activeController发起一个AllocateProducerIds请求.
在controller端会由ProducerIdControlManager组件进行处理.
此AllocateProducerIds请求会给broker生成一个连续的producerId的数据块.
当ProducerIdManager中generateProducerId分配producerId达到连续数据块的90%时,会重新向controller请求一个新的数据块.
ProducerIdManager.generateProducerId函数
verride def generateProducerId(): Long = {
this synchronized {
//broker启动后首次生成producerId,先向controller请求一个producerid的数据块.
if (nextProducerId == -1L) {
maybeRequestNextBlock()
nextProducerId = 0L
} else {
//当前`currentProducerIdBlock`未完成分配,在上一个producerId的基础上加1.
nextProducerId += 1
//当producerId分配超过当前数据块的90%时,开始请求下一个数据块.
//==>新请求的数据块会放到`nextProducerIdBlock`阻塞队列中,此队列只有一个长度.
if (nextProducerId >= (
currentProducerIdBlock.firstProducerId +
currentProducerIdBlock.size * ProducerIdManager.PidPrefetchThreshold)
) {
maybeRequestNextBlock()
}
}
//当前`currentProducerIdBlock`分配完,从`nextProducerIdBlock`队列中获取一个新的数据块.
//如果是首次分配时`nextProducerId==0`,此时会等待第一次`AllocateProducerIds`的响应.
if (nextProducerId > currentProducerIdBlock.lastProducerId) {
val block = nextProducerIdBlock.poll(maxWaitMs, TimeUnit.MILLISECONDS)
if (block == null) {
throw Errors.REQUEST_TIMED_OUT.exception("Timed out waiting for next producer ID block")
} else {
block match {
case Success(nextBlock) =>
currentProducerIdBlock = nextBlock
nextProducerId = currentProducerIdBlock.firstProducerId
case Failure(t) => throw t
}
}
}
nextProducerId
}
}
ProducerIdManager.maybeRequestNextBlock函数 向activeController申请一个连续的produerId范围数据块(1000个)
//向activeController发起`AllocateProducerIds`请求,申请一批producerId.
private def maybeRequestNextBlock(): Unit = {
if (nextProducerIdBlock.isEmpty && requestInFlight.compareAndSet(false, true)) {
sendRequest()
}
}
private[transaction] def sendRequest(): Unit = {
val message = new AllocateProducerIdsRequestData()
.setBrokerEpoch(brokerEpochSupplier.apply())
.setBrokerId(brokerId)
val request = new AllocateProducerIdsRequest.Builder(message)
debug("Requesting next Producer ID block")
controllerChannel.sendRequest(request, new ControllerRequestCompletionHandler() {
override def onComplete(response: ClientResponse): Unit = {
val message = response.responseBody().asInstanceOf[AllocateProducerIdsResponse]
//controller响应的produerId数据块会被放到`nextProducerIdBlock`阻塞队列中.
handleAllocateProducerIdsResponse(message)
}
override def onTimeout(): Unit = handleTimeout()
})
}
controller端处理
AllocateProducerIds请求
当broker端无可以给Producer分配的producerId缓存时,会向activeController发起AllocateProducerIds请求.
此请求会由activeController中的ProducerIdControlManager组件来进行处理.
ProducerIdControlManager组件用于管理所有broker端用于分配给Producer的ProducerId的数据块信息.
在kafka中,每个producer初始化时都会向broker请求获取一个初始化的producerId,
而在broker端会向controller发起AllocateProducerIds请求每一次申请1000个producerId缓存到broker本地.
在每一次broker申请produerId的缓存数据块后,会生成一条ProducerIdsRecord消息并写入metadata中,
此消息在发生activeController切换或者重启后能方便找到上一次分配到的nextProducerId的起始位置.
generateNextProducerId函数 为请求producerId缓存的broker分配1000个连续的produerId数据块.
此函数操作会向quorumController的事件队列中注册了一个ControllerWriteEvent事件,
并在事件执行时调用此函数来处理,并产生一条ProducerIdsRecord消息.
在此函数中,根据上一次分配的block的id值+1000得到当前分配的block的起始范围.
如果是cluster的首次分配时,从0开始,而ProducerIdsRecord消息主要为记录下一次分配的起始值.
ControllerResult<ProducerIdsBlock> generateNextProducerId(int brokerId, long brokerEpoch) {
//检查请求的broker节点对应的epoch值是否与注册时broker对应的epoch值相同.
clusterControlManager.checkBrokerEpoch(brokerId, brokerEpoch);
long firstProducerIdInBlock = nextProducerBlock.get().firstProducerId();
//判断producerId的分配范围是否已经达到了long的最大值.
if (firstProducerIdInBlock > Long.MAX_VALUE - ProducerIdsBlock.PRODUCER_ID_BLOCK_SIZE) {
throw new UnknownServerException("Exhausted all producerIds as the next block's end..");
}
//根据当前记录的nextProducerBlock的第一个分配范围,连续分配1000个producerId给broker端.
//==>如果是cluster首次分配,这个值从0开始到999.
//==>如果非首次分配,这个值由上一次分配的block+1000得到(重启后由replay来回放NextProducerId的值)
ProducerIdsBlock block = new ProducerIdsBlock(
brokerId, firstProducerIdInBlock, ProducerIdsBlock.PRODUCER_ID_BLOCK_SIZE);
long newNextProducerId = block.nextBlockFirstId();
//生成`ProducerIdsRecord`消息,记录下一次分配id的起始范围.
ProducerIdsRecord record = new ProducerIdsRecord()
.setNextProducerId(newNextProducerId) //下一次分配时的起始值.
.setBrokerId(brokerId)
.setBrokerEpoch(brokerEpoch);
return ControllerResult.of(
Collections.singletonList(new ApiMessageAndVersion(record, (short) 0)), block);
}
replay(ProducerIdsRecord)
当controller启动时、或Controller在收到AllocateProducerIds请求后会生成ProducerIdsRecord消息,
此消息在向metadata写入并完成副本同步后会执行此replay操作.
作用于当下一次AllocateProducerIds请求所需要的开始producerId的值(起始范围).
void replay(ProducerIdsRecord record) {
long currentNextProducerId = nextProducerBlock.get().firstProducerId();
if (record.nextProducerId() <= currentNextProducerId) {
throw new RuntimeException("Next Producer ID from replayed record ...");
} else {
//根据监听到的最新的nextProducerId值,重置当前controller中nextProducerBlock的起始值.
nextProducerBlock.set(
new ProducerIdsBlock(record.brokerId(), record.nextProducerId(),
ProducerIdsBlock.PRODUCER_ID_BLOCK_SIZE));
brokerEpoch.set(record.brokerEpoch());
}
}
client端接收响应
当broker向Producer响应请求后,会交由Producer端的InitProducerIdHandler处理程序来解析response的信息并进行相应的处理.
InitProducerIdHandler处理InitProducerId的response结果:
当broker端成功分配producerId后,会向Producer响应两个参数值producerId与epoch.
其中epoch值在初始化分配producerId成功时,默认为0.
if (error == Errors.NONE) {
//根据broker端响应的producerId与epoch(默认为0),生成ProducerIdAndEpoch实例
ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(
initProducerIdResponse.data().producerId(),
initProducerIdResponse.data().producerEpoch());
//更新当前Producer对应的proudcerId与epoch的值,初始时epoch的值为0.
setProducerIdAndEpoch(producerIdAndEpoch);
//更新tranactionManager的状态为`READY`状态.
transitionTo(State.READY);
lastError = null;
if (this.isEpochBump) {
resetSequenceNumbers(); //非事务场景,这里不执行.
}
//完成future的等待.
result.done();
}
3,send(消息写入)
从示例代码中可以看到,在kafkaProducer端,所有的写入操作都是生成对应的record后,调用producer的send函数来完成.
send函数
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
KafkaProducer的send函数的定义: 其最终通过调用doSend函数来执行send操作.
从其函数定义可以看出,producer的send传入参数有两个,第一个是要写入的record(包含topic,key,value).
关于send的返回值
在kafka中大量利用future来实现了异步无锁等待,producer端也同样采用了future来为client端获取消息写入的结果信息.
在client端可以通过isDone来判断消息写入是否完成,通过try(future.get)catch(exception)来得到写入的结果.
doSend函数
主流程分析
doSend函数作用于具体处理消息向RecordAccumulator的producer内存缓冲区内写入消息.主要包含如下几个步骤
Step=>1
生成用于监听record的最终append完成的回调函数AppendCallbacks实例.
当Sender线程最终完成对recordBatch的提交后,会通过此callback来完成batch对应的future,实现send的异步回调.
//生成用于append完成后的callback实例.
AppendCallbacks<K, V> appendCallbacks = new AppendCallbacks<K, V>(callback, this.interceptors, record);
Step=>2
检查要写入的record对应的topic是否存在.
如果topic在matadataCache中不存在时,此时会发起增量Metadata请求来获取topic对应的metadata信息,
并等待metadata的请求响应(如果metadataCache中已经存在topic时无需发起Metadata请求).
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
//检查record对应的`topicPartition`在metadata中是否存在
//==>如果不存在等待metadata重新向broker端同步完成.
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
//记录此时获取topic对应的metadata的时间,此时间会算到send的总超时时间内.
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
Step=>3
根据Producer配置的key、value的序列化实例,对record的key、value进行序列化为byteArray.
//对要写入的消息序列化为bytes
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class ...", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class ...", cce);
}
Step=>4
获取record对应在topic中要写入的partition.
如果Producer有配置自定义的Partitioner实例时,使用自定义实例进行分区.
否则:
如果record对应的key存在,同时partitioner.ignore.keys配置为false(默认为false).
此时由BuiltInPartitioner利用murmurHash算法(v2版本实现),计算出key应该对应的partition并返回.
如果record的key不存在或者partitioner.ignore.keys配置为true时,此时针对此record返回的partition为UNKNOWN_PARTITION(-1),表示由RecordAccumulator决定要写入的partition.
//返回对应的partition或者UNKNOWN_PARTITION(-1).
//==>如果返回是(-1)表示由RecordAccumulator决定写入topic的partition(根据partition的工作负载来分配).
int partition = partition(record, serializedKey, serializedValue, cluster);
Step=>5
获取本次send的record的大小与timestamp信息(原始大小,不考虑压缩的情况).
注意record的大小不能超过max.request.size配置的值.
单条record的大小:61(byte,batchInfo)+21(recordInfo)+keyByteSize+valueByteSize+headerByteSize
请参考DefaultRecordBatch与DefaultRecord.
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
//获取当前record的写入大小,并判断是否超过单次请求的大小.
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
Step=>6
把消息追加到RecordAccumulator的内存缓冲区内,当缓冲区的batch写满或达到linger.ms配置的超时时间后后Sender线程发送给broker.
通过RecordAccumulator实例把record追加(append)到最后的batch中,
如果此时partition == UNKNOWN_PARTITION时,会通过builtInPartitioner为record分配partition.
并把分配的分区设置到appendCallbacks中. 此过程会向缓冲区的内存池中申请内存.
此时:如果batch不存在,会重新分配一个batch (关于RecordAccumulator的append在后面具体分析).
//`abortOnNewBatch == true` 表示自定义partitioner有配置,
//==>此时如果`RecordAccumulator`中如果没有正在进行中的batch时,会交由producer来生产新的batch.
boolean abortOnNewBatch = partitioner != null;
//向`RecordAccumulator`中未写满的batch中追加record.
//==>此过程会涉及到申请内存空间或线程阻塞(无内存可用时)
RecordAccumulator.RecordAppendResult result = accumulator.append(
record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks,
remainingWaitMs, abortOnNewBatch, nowMs, cluster);
assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION;
//`partitioner != null`:如果`RecordAccumulator`中没有正在进行中的batch.
//===>这里可以不用看,与上面的append没有本质上的区别.
if (result.abortForNewBatch) {
int prevPartition = partition;
//当前的`stickyPartition`对应的batch已经处理完成,或Producer的首次append操作.
//==>更新`stickyPartition`的值(前提条件是,使用了自定义的`partitioner`实例)
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic....;
}
//开启一个新的batch进行record的append操作.
result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
Step=>7
最后,在成功将record追加(append)到RecordAccumulator后,返回此条record对应的future,
在client端可用此future监听消息是否写入完成,并可在完成后获取到请求的响应信息.
同时,如果RecordAccumulator中当前进行中的batch已经写满或者开启了新的batch,
唤醒sender线程的等待,此时sender线程将通过sendProducerData函数处理recordBatch的提交.
// Add the partition to the transaction (if in progress) after it has been successfully
// appended to the accumulator. We cannot do it before because the partition may be
// unknown or the initially selected partition may be changed when the batch is closed
// (as indicated by `abortForNewBatch`). Note that the `Sender` will refuse to dequeue
// batches from the accumulator until they have been added to the transaction.
//==>只有开启事务的情况,这里才会处理,在分析事务时在分析.
if (transactionManager != null) {
transactionManager.maybeAddPartition(appendCallbacks.topicPartition());
}
//如果当前topicPartition正在进行中的batch已经写满,或者有新创建的batch(表示上一个未写满的batch无法写入更多消息)
//==>此时唤醒Sender线程,使其能够通过sendProducerData来处理消息的写入.
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch",
record.topic(),appendCallbacks.getPartition());
this.sender.wakeup();
}
return result.future; //client可通过此future来监听消息写入是否成功.
至此,对一条消息的send操作处理流程结束,其它网络请求的处理会交由Sender线程来处理.
append(RecordAccumulator)
在kafka中producer生产的消息都会先放到此累加器中,其内部的topicInfoMap容器为每个topic的partition维护了一个双端队列.
当producer生产消息调用send函数时,会调用其内部的append函数来将ProducerRecord附加到对应topicPartition的lastBatch中.
如果lastBatch不存在或已经写满,此时会向内存池重新申请一块新的内存空间,如果内存池没有可分配的内存时,producer线程会被阻塞.
函数的定义:
public RecordAppendResult append(
String topic,int partition,long timestamp,
byte[] key,byte[] value,Header[] headers,
AppendCallbacks callbacks,long maxTimeToBlock,
boolean abortOnNewBatch,/*true表示有自定义partitioner,分析时可以忽略掉*/
long nowMs,Cluster cluster) throws InterruptedException {
.........
}
append操作的处理流程:
Step=>1
从topicInfoMap容器中获取到reocrd对应的topicInfo信息(如果不存在,新创建一个).
在TopicInfo中维护有用于对record进行partition分区操作的builtInPartitioner实例,
以及正在进行中的ProducerBatch的双端队列(未完成send或者正在append中的batch).
//从`topicInfoMap`容器中获取到当前record对应的topicInfo信息.
//==>此topicInfo中维护有对应topic正在进行中的ProucerBatch的双端队列(按等写入的partition分区).
TopicInfo topicInfo = topicInfoMap.computeIfAbsent(topic, k -> new TopicInfo(logContext, k, batchSize));
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
//死循环,自旋,直到append到内存缓冲区后结束.
// Loop to retry in case we encounter partitioner's race conditions.
while (true) {
.......分配内存或向当前活动的内存缓冲区内添加record....
}
} finally {
//释放申请多于的内存buffer(如果已经分配这里不会释放).
//==>这通常发生在topicInfo的batchs队列已经写满,向内存池申请了新内存,
//==>但当前线程申请内存并对队列加锁后发现其它线程已经申请过内存并添加到队列中.
//====>这里内存空间的申请重复,此时把当前线程申请的内存空间释放.
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
接下来,开始自旋(while-true的死循环)直到append到内存缓冲区或超时结束.
Step=>2
根据是否分配partition,对record的partition进行分配,并将partition添加到callback中.
提示:如果partition是(UNKNOWN_PARTITION),表示partition的分配交给Producer来处理,那么此时:
会根据线程随机数取出一个partition或者根据partition的负载情况获取到最佳可用partition来处理record的写入(关于partition的负载见后续分析).
final BuiltInPartitioner.StickyPartitionInfo partitionInfo;
final int effectivePartition;
//如果未设自定义partitioner,同时key不存在或者忽略key的hash分配的场景.
//==>通过`builtInPartitioner`获取最佳写入的partition.
if (partition == RecordMetadata.UNKNOWN_PARTITION) {
partitionInfo = topicInfo.builtInPartitioner.peekCurrentPartitionInfo(cluster);
effectivePartition = partitionInfo.partition();
//按key进行了hash分配或自定义partitioner进行了partition分配.
//==>此时不做任何处理.
} else {
partitionInfo = null;
effectivePartition = partition;
}
//将partition设置到callback中(即可通过callback获取到对应的partition).
setPartition(callbacks, effectivePartition);
Step=>3
检查topicInfo对应record的partition是否有正在进行中的batch(未写满或未超时),
=>1,对StickyPartition的队列加锁后,
首先判断是否需要变更partition(自定义partitioner或keyHash的情况下这个步骤不会做任何变更).
==>这里的partitionChanged变更检查主要考虑加锁前其它线程有处理的情况.
=>2,向StickyPartition对应的缓冲区队列的lastBatch的内存缓冲区内append当前record,通过(tryAppend).
如果tryAppend返回的appendResult为null说明当前缓冲区已经写满或者无法再写入更多数据.
否则把record追击到其对应的MemoryReocrds中,并更新其lastAppendTime的时间.
=>3,如果成功把record添加到内存缓冲区内,
通过updatePartitionInfo判断是否需要变更粘性分区(StickyPartition).
=>4,如果当前StickyPartition的内存缓冲区已经不足以写入record,流程执行**Step4**.
此时StickyPartition中lastBatch的appendStream流会关闭,表示batch已经写满.
注意:在对**StickyPartition**的内存缓冲区进行appendRecord操作时,会对其双端队列加锁.
这个步骤在partition的首次append操作时不会执行,具体逻辑请看如下代码的注释说明.
//获取到对应partition中正在进行中的batchs的双端队列,并对队列加锁.
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(
effectivePartition, k -> new ArrayDeque<>());
synchronized (dq) {
//step1,加锁后,选判断针对`UNKNOWN_PARTITION`分配的partition是否需要变更.
//==>判断当前`StickyPartition`实例处理的producerSize的大小
//====>如果lastBatch已经写满或者lingerMs的超时多次send后的总大小达到batchSize,切换分区,重新迭代处理.
//====>在如下情况下会阻止partition的切换:
//====>1,如果batch未写满(如只写入10kb),但上一次send时达到了`lingerMs`的超时时间.
//====>此时producerSize的值小于一个batchSize的大小,阻止切换,
//====>2,在第二次写满或者`lingerMs`超时后又send(如10kb),此时总producerSize大小大于batchSize,切换分区.
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue; //分区发生切换,重新迭代处理.
//step2,尝试向partition对应的batchs队列的最后一个batch中追加record.
//=>同时,如果partition是否producer自动分配的情况下,判断是否需要更换`StickyPartition`实例
//==>如果`appendResult`返回为null,表示当前`StickyPartition`队列已经无法存储record,需要新开内存.
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
if (appendResult != null) {
//流程执行这里,表示lastBatch的内存空间足够存储当前record,否则appendResult会返回null.
// If queue has incomplete batches we disable switch (see comments in updatePartitionInfo).
boolean enableSwitch = allBatchesFull(dq); //判断队列是否写满
//如果当前partition是`StickyPartition`,
//==>检查当前partition的producerSize是否已经达到更换分区的大小,并更换分区.
//`updatePartitionInfo`在正常(不考虑`lingerMs`)的情况下,写满即会切换分区.
//在有`lingerMs`超时的情况下,上一次send的大小可能不到batchSize的大小,
//===>切换分区可能会在`lingerMs`超时send几次以后才会发生.
//===>但单个`StickyPartition`最大sned的ProducerSize的大小不会超过batchSize*2.
topicInfo.builtInPartitioner.updatePartitionInfo(
partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult; //成功把record追加到lastBatch,结束流程.
}
}
Step=>4
在partition首次写入或者partition的batchs队列内存空间不足以存储当前record时(或者已经写满),见Step3的逻辑,
此时需要向**内存池(BufferPool)**重新申请内存空间来处理record的append.
关于内存池的BufferPool.allocate分配内存部分见后续的分析.
注意:申请新的buffer,但buffer可能不会被使用,因为这个过程是未加锁的过程,有可能其它线程已经申请过.
//向内存池申请一块内存缓冲区,其大小默认为16kb.
//==>如果此时申请的buffer在后续流程中未被使用到,那么在流程结束时(见Step1中finally部分)会释放申请的内存.
if (buffer == null) {
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(
maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic...);
// This call may block if we exhausted buffer space.
//向内存池申请内存,如果内存池中没有足够可分配的内存时,这里会导致线程blcok.
buffer = free.allocate(size, maxTimeToBlock);
nowMs = time.milliseconds();
}
Step=>5
根据**Step4**中新申请的内存空间,再次处理record向内存缓冲区append操作.
注意: 在对**StickyPartition**的内存缓冲区进行appendRecord操作时,会对其对应的partition双端队列加锁.
在此步骤中通过执行appendNewBatch函数来将recordAppend到新申请的buffer中.
如果Step4新申请的内存空间(buffer)被使用,会把此buffer对应的ProducerBatch添加到incomplete队列中.
//对队列加锁后在执行append操作.
synchronized (dq) {
//Step1,重新对partition的buffer队列加锁后,判断`StickyPartition`是否需要变更.
//==>因为在当前线程未加锁前,可能会有其它线程对partition进行了append操作,
//==>此时,需要重新判断是否需要更换新的Partition进行recordAppend操作.
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
//Step2,执行`appendNewBatch`操作来处理recordAppend操作,此过程分两种情况:
//==>1,在当前线程申请内存缓冲区的buffer后,其它线程对partition进行了操作.
//====>>其它线程可以已经在partition对应的batchs队列中添加了正在进行中的buffer(lastBatch).
//====>>此时:
//直接在其它线程申请的lastBatch对应的buffer中append当前的record(`newBatchCreated == false`)
//==>2,正常情况(没有其它线程对partition的队列进行更新),此时:
//======>根据从内存池中新申请的buffer进行recordAppend操作,
//===========>并把此buffer对应的batch添加到partition的队列中.
//======>即:此时partition的lastBatch被重新分配了新的buffer(`newBatchCreated == true`).
RecordAppendResult appendResult = appendNewBatch(
topic, effectivePartition, dq, timestamp, key, value, headers, callbacks, buffer, nowMs
);
//`newBatchCreated == true`:表示新申请的内存缓冲区被使用,
//设置buffer为null,表示buffer不能被内存池回收.
if (appendResult.newBatchCreated)
buffer = null;
//step3, 写入成功后,根据当前lastBatch是否已经写满,同时:
//===>执行`updatePartitionInfo`操作尝试更换新的`StickyPartition`.
boolean enableSwitch = allBatchesFull(dq);
//检查粘性分区(当前写的partition)是否已经达到写入数据的上限,如果达到上限,重新换一个可用分区写入.
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo,
appendResult.appendedBytes, cluster, enableSwitch);
return appendResult; //结束append流程,整个send操作结束.
}
BufferPool(内存池)
内存池(BufferPool)负责给Producer端所有的topicPartition的record分配内存缓冲区.
其可用内存的总大于小buffer.memory配置,默认为32mb.
其内部维护着一个用于回收已经send完成的buffer的双端队列free(池化内存),即partition中内存缓冲区提交后的释放内存.
以及当前等待分配内存空间的线程等待队列waiters.
Allocate(申请内存)
在BufferPool中allocate用于给Producer端分配内存缓冲区,其传入参数:
size表示RecordAccumulator要申请的内存大小(通常应该是batch.size配置的大小),
maxTimeToBlockMs表示如果内存池空间已经被占满时最大等待时间(max.block.ms).
BufferPool中分配内存的处理流程:
Step=>1
在进行内存分配前,先对内存池进行加锁,防止多线程导致的线程安全问题.
//判断要申请的内存是否大于当前内存池内存总大小(肯定是不能超过的).
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
//要分配内存空间,先对内存池加锁,防止多线程导致的数据安全问题.
ByteBuffer buffer = null;
this.lock.lock();
if (this.closed) {
this.lock.unlock();
throw new KafkaException("Producer closed while allocating memory");
}
Step=>2
如果要申请的内存大小刚好是batchSize(池化空间)的大小,
同时free队列(池化内存)中有已经释放并回收到内存池中的buffer时,直接从队列中取出队顶元素,结束分配流程.
此时流程会释放锁资源(进入finally部分),并根据是否还有剩余内存空间来唤醒等待分配内存的线程.
// check if we have a free buffer of the right size pooled
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
Step=>3-1
判断非池化的内存空间加上内存池(free队列)中缓存的buffer大小是否能够满足分配需要.
如果能够满足分配需要,此时会尝试从(free队列)的尾部释放已经池化的空间,直到满足此次申请的内存.
提示:内存池(free队列)中池化的内存空间都是batchSize大小的固定空间,非标准空间会被释放.
int freeListSize = freeSize() * this.poolableSize;
if (this.nonPooledAvailableMemory + freeListSize >= size) {
// we have enough unallocated or pooled memory to immediately
// satisfy the request, but need to allocate the buffer
freeUp(size); //尝试从free队列尾部释放池化内存空间,直接非池化内存空间大小满足分配需要.
this.nonPooledAvailableMemory -= size;
}
如果此时非池化空间满足此时申请的size的大小时,流程进行尾部finally部分,并最终分配Buffer空间.
即:释放锁资源,并通过safeAllocateByteBuffer分配内存.
Step=>3-2
流程执行到这里,表示当前内存池的剩余空间不足(池化加非池化内存总和小于size),
此时线程进行await状态,直到其它线程释放内存空间后唤醒继续分配内存,或者线程等待超时后退出.
//内存池中内存空间不足,线程进行await状态,等待释放内存后唤醒重新分配或超时退出.
else {
// we are out of memory and will have to block
int accumulated = 0; //已经分配的内存空间大小.
//生成一个新的`Condition`实例.
Condition moreMemory = this.lock.newCondition();
try {
//超时时间,由`max.block.ms`配置,默认为1分钟.
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
//添加`Condition`实例到阻塞队列`waiters`中.
this.waiters.addLast(moreMemory);
//不间断的重复迭代,直到分配到足够的内存,或等待超出退出.
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
//让线程进入`timeWait`状态,其返回值`waitingTimeElapsed == true`表示等待超时.
//==>如果线程被中断,此时会抛出中断异常(InterruptedException).
try {
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
recordWaitTime(timeNs);
}
//Producer被关闭,throw KafkaException,在doSend部分处理此异常.
if (this.closed)
throw new KafkaException("Producer closed while allocating memory");
//线程等待超时,抛出ApiException.
if (waitingTimeElapsed) {
this.metrics.sensor("buffer-exhausted-records").record();
throw new BufferExhaustedException(
"Failed to allocate " + size + " bytes within the configured max blocking time "
+ maxTimeToBlockMs + " ms. Total memory: " + totalMemory()
+ " bytes. Available memory: " + availableMemory()
+ " bytes. Poolable size: " + poolableSize() + " bytes");
}
//未超时,被其它线程释放内存后唤醒,计算如果任然不满足分配时可用的等待时间.
remainingTimeToBlockNs -= timeNs;
//如果要申请的内存大小是标准池化内存大小(batchSize),同时池化空间(free队列)非空.
//==>直接取出free队列的队顶元素(队顶池化内存buffer),结束流程.
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// just grab a buffer from the free list
buffer = this.free.pollFirst();
accumulated = size;
//要申请的内存大小非标准池化内存大小,或者内存池(free队列)没有可用的池化空间.
//==>根据当前非池化空间大小进行内存分配,不够分配继续while迭代,否则表示成本申请到空间,结束迭代.
} else {
//从池化空间中释放内存,直到满足申请的空间或没有多于空间可分配.
freeUp(size - accumulated);
//得到本次迭代过程中分配到的内存空间大小,如果分配的内存已经满足需要,停止迭代,
//==>否则,继续整个while迭代,直到申请到足够的内存或超时.
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -= got;
accumulated += got;
}
}
//成功分配到内存后,把`accumulated`设置为0,
//==>这样做可以在分配过程中出现异常时在`finally`部分能够正常计算出应该还原的内存大小.
accumulated = 0;
} finally {
// When this loop was not able to successfully terminate don't loose available memory
this.nonPooledAvailableMemory += accumulated;
//结束分配,从等待队列`waiters`中移出当前`Condition`实例.
this.waiters.remove(moreMemory);
}
}
Step=>4
分配内存的流程结束(成功申请到内存空间或超时等异常情况),返回申请到的内存buffer.
此时释放锁资源,如果是正常流程结束(即成功申请到内存空间),此时会返回申请到的ByteBuffer空间.
finally {
try {
//如果当前内存池中还有可用的内存空间,唤醒一个等待队列中等待分配内存的线程.
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
//释放锁,不管成功还是失败.
// Another finally... otherwise find bugs complains
lock.unlock();
}
}
//成功申请到内存空间,此时可能会有两种情况:
//=>1,`buffer == null` : 池化空间(free队列)中没有空闲的内存可分配,
//====>根据申请的内存大小,生成一个ByteBuffer空间返回给`RecordAccumulator`.
//=>2,`buffer != null` : 表示申请的内存大小是标准的池化内存大小(batchSize),同时:
//====>当前内存池中池化空间有空间的内存可以分配(free队列有空间buffer)
if (buffer == null)
return safeAllocateByteBuffer(size);
else
return buffer;
deallocate(释放内存)
当RecordAccumulator缓冲区内的batch完成网络发送后,Sender线程中会释放掉对应batch所持有的内存空间.
此时会通常调用BufferPool中的此函数来进行内存的释放与回收.
此操作比较简单,根据释放的内存大小是否是标准池化内存大小来判断是否放入池化内存队列中.
同时唤醒一个等待分配内存的线程.
//完成对producer缓冲区内的batch的网络请求后,释放其持有的内存空间.
//size==>表示本次释放(回收)的内存大小
public void deallocate(ByteBuffer buffer, int size) {
//对内存池的操作,要加锁.
lock.lock();
try {
//step1,回收释放的内存空间,分为两种场景.
//case1,释放的内存空间大小是标准池化内存大小,直接cache到free队列中.
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
//case2,释放的内存空间非标准池化内存大小,直接释放buffer的空间(不加入池化队列free中)
} else {
this.nonPooledAvailableMemory += size;
}
//step2,此时,由于已经回收部分内存,唤醒一个等待分配的线程,让其开始处理内存申请.
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
partition负载计算
当producer端未配置自定义partitioner实现,针对未设置key或者partitioner.ignore.keys配置为true的record.
在执行RecordAccumulator的append操作附加record到内存缓冲区时,会根据partition的负载情况来随机分配record要写入的partition.
此时,partitioner的默认实现为BuiltInPartitioner.
在BuiltInPartitioner中,通过计算出每个partition对应的工作负载来选择合适的partition写入record.
partition负载计算
在Sender线程中执行sendProducerData函数时,
会首先通过RecordAccumulator.ready函数来查找已经准备好的batch对应的partitionLeader节点.
此时,会调用partition对应的topicInfo中对应的BuiltInPartitioner来更新各个partition的负载.
此操作最终由BuiltInPartitioner实例中的updatePartitionLoadStats函数来处理.
updatePartitionLoadStats函数定义: 函数的传入参数说明:
queueSizes => RecordAccumulator中对应topic的各个partition中当前的batchs队列大小.
partitionIds => 与queueSizes数组一一对应,表示什么partition对应当前batchs队列的大小.
public void updatePartitionLoadStats(int[] queueSizes, int[] partitionIds, int length) {
.....
}
函数更新负载的流程分析:
Step=>1
如果queueSizes的大小小于2或者为null,表示当前topic没有可用的partition或者topic只有一个partition,
此时无续计算partition的负载(只有一个partition就只能用其接收数据).
//无可用的partition,可能存在"partitioner.availability.timeout.ms"超时.
//==>或者当前RecordAccumulator的内存缓冲区内没有要写入的数据.
if (queueSizes == null) {
log.trace("No load stats for topic {}, not using adaptive", topic);
partitionLoadStats = null;
return;
}
assert queueSizes.length == partitionIds.length;
assert length <= queueSizes.length;
//只有一个Partition的情况下,不计算partition的负载.
if (length < 1 || queueSizes.length < 2) {
log.trace("The number of partitions is too small: available={}, all={},..");
partitionLoadStats = null;
return;
}
Step=>2
根据topic中每个partition对应的batch队列的大小,生成每个partition的负载信息,计算方法:
示例: 如果当前topic共有3个partition, 其队列(batch缓冲区队列)大小分别是 0 3 1.
=>1, 首先找到所有partition中最大的队列的size并加1, 示例中最大queueSize为3,加1 等于4.
=>2, 通过maxQueueSize+1的值(4)减去每个partition的队列大小来反转partition,此时值为: 4 1 3.
[0] = (4-0), [1] = (4-3), [2] = (4-1).
=>3, 最后,将其转换为队列运行总和(下一个值加上前一个值), 此时值为: 4 5 8.
[0] = 4(没有前一个值), [1] = (1+4=5), [2] = (5+3=8).
此时工作负载表的每个partition对应的queueSize的大小从小到大顺序排列(在使用时可以直接使用二分查找).
最后根据上述步骤生成出的partition负载,更新topic的PartitionLoadStats实例.
//计算所有partition中最大的队列的size,并加1.
int maxSizePlus1 = queueSizes[0];
boolean allEqual = true;
for (int i = 1; i < length; i++) {
if (queueSizes[i] != maxSizePlus1)
allEqual = false;
if (queueSizes[i] > maxSizePlus1)
maxSizePlus1 = queueSizes[i];
}
++maxSizePlus1; //对最大的队列的size加1.
if (allEqual && length == queueSizes.length) {
log.trace("All queue lengths are the same, not using adaptive for topic {}", topic);
partitionLoadStats = null;
return;
}
//对每个partition中的queueSize的值进行反转,并计算其运行总和(当前值加上前一个值.)
queueSizes[0] = maxSizePlus1 - queueSizes[0];
for (int i = 1; i < length; i++) {
queueSizes[i] = maxSizePlus1 - queueSizes[i] + queueSizes[i - 1];
}
log.trace("Partition load stats for topic {}: CFT={}, IDs={}, length={}",
topic, queueSizes, partitionIds, length);
//更新topic对应的负载信息.
partitionLoadStats = new PartitionLoadStats(queueSizes, partitionIds, length);
说明: 当此过程处理完成后, 当RecordAccumulator在append操作时对record进行partition分配时,
会从PartitionLoadStats对应的工作负载表中,随机生成一个0~maxLoadStats之间的值,如 3 .
那么针对示例的随机数3, 在分配partition时,从工作负载表中可以找到其在第0个数组下标所在的范围(小于第一个queueSize的负载).
因此其会取出partitionIds [0]所对应的partition来分配给record.
分配partition(append)
当Producer向RecordAccumulator追加record时,此时会调用其对应的append函数.
此时,如果record对应的partition为UNKNOWN_PARTITION,
会直接使用BuiltInPartitioner中stickyPartitionInfo 缓存起来的粘性分区来当着当前record的partition.
当每一个stickyPartitionInfo中append的record的记录总大小超过batchSize的值后(最大不超过2BatchSize),
会通过执行其nextPartition函数来重新选择一个可用partition.
如下代码片段所示:
//根据当前topic对应的partition工作负载表,生成一个随机的工作负载值.
int[] cumulativeFrequencyTable = partitionLoadStats.cumulativeFrequencyTable;
//生成的值的范围0~maxLoadStats.
int weightedRandom = random % cumulativeFrequencyTable[partitionLoadStats.length - 1];
//查找随机loadStats值(weightedRandom)对应在`cumulativeFrequencyTable`对应的下标.
int searchResult = Arrays.binarySearch(cumulativeFrequencyTable, 0, partitionLoadStats.length, weightedRandom);
//找到随机loadStats值(weightedRandom)对应的partition作为nextPartition的值.
int partitionIndex = Math.abs(searchResult + 1);
assert partitionIndex < partitionLoadStats.length;
partition = partitionLoadStats.partitionIds[partitionIndex];
Sender(线程)
sendProducerData
在Sender线程中sendProducerData函数用于判断当前RecordAccumulator的内存缓冲区内是否有已经准备好的partitions.
如果有已经准备好数据的partitions(有写满的batch或达到linger.ms的上限),根据partitions计算出对应的leader,
并排出缓冲区的batch,向对应的broker发起Producer请求.
sendProducerData函数的处理流程分析:
Step=>1
首先,执行RecordAccumulator中的ready函数来获取内存缓冲区中已经准备好的partitions对应的Leader节点集合与partition无Leader节点的topic集合.
所谓的已经准备好包含partition对应的Batch已经写满或已经达到lingerMs的超时时间.
同时在ready函数中,还会针对每个topic,更新其topicInfoMap中对应topicInfo的各个partition的负载.
如果ready函数的返回值result.unknownLeaderTopics不为空,
表示batch对应的partition的Leader未完成选举,此时会立即更新此topic对应的metadata信息,来获取到最新的topic信息.
此步骤具体逻辑见如下代码片段的注释.
Cluster cluster = metadata.fetch();
//Step1,获取到已经准备好发送数据的topicPartitions对应的的Leader节点集合.
//==>此函数会执行如下几个场景的处理:
//=>1,迭代内存缓冲区中所有已经写满的partitionBatch(写满或linger超时),
//====>并找到partition对应的Leader节点,
//====>如果Leader节点不存在添加`topic`到`result.unknownLeaderTopics`中.
//====>如果Leader节点存在,同时batch已经准备好(写满或者linger超时)将Leader添加到`result.readyNodes`中.
//=>2,执行`updatePartitionLoadStats`函数,根据topic的每个partition的batchs队列大小,更新partition的负载.
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//Step2,如果内存缓冲区内有partition无Leader节点信息时,立即更新partition对应的topic的metadata.
//==>此时,内存缓冲区内这部分无leader节点信息的batch将不会被提交.
if (!result.unknownLeaderTopics.isEmpty()) {
//添加topic到`newTopics`容器中
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
//设置metadataCache过期,即:表示立即执行metadata的更新操作.
//==>当sender线程下一次轮询时,会发起metadata请求来更新topic信息.
this.metadata.requestUpdate();
}
Step=>2
当partitioner.availability.timeout.ms配置是大于0的值时,维护Step1中得到的result.readyNodes的lastReadyTime的时间.
此信息由RecordAccumulator中nodeStats容器维护,每个Node节点都包含一个NodeLatencyStats实例.
默认情况下partitioner.availability.timeout.ms配置值为0,表示不启用nodeStats的判断.
//nodeStats的结构定义
NodeLatencyStats(long nowMs) {
readyTimeMs = nowMs; //最后一次准备send的时间
drainTimeMs = nowMs; //最后一次有batch可send的时间.
//readyTime - drainTime > availabilityTimeout时,此partition会被移出
}
此步骤的实现代码如下所示:(只有在partitionAvailabilityTimeoutMs大于0的配置下有效).
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
//当前Producer与`node`节点的链接不可用,此时只更新node节点的`readyTimeMs`.
//=>1,与node链接的链接未创建,或者node节点还有处理中的请求.
//=>2,Producer端metadata过期,需要重新请求获取metadata的情况.
if (!this.client.ready(node, now)) {
//此时,与node节点的链接暂时不可用,只更新node节点的`readyTimeMs`.
//如果`readyTimeMs`减去`drainTimeMs`大于`partitionAvailabilityTimeoutMs`超时时间,
//==>表示对应partition不可用,此node对应的partition会从partitionLoadStats中移出.
this.accumulator.updateNodeLatencyStats(node.id(), now, false);
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
//当前Producer与`node`节点的链接可用,此时更新node对应的`readyTimeMs`与`drainTimeMs`.
} else {
//节点链接已经准备好(成功链接,并且同时进行中的请求数小于指定的配置值)
this.accumulator.updateNodeLatencyStats(node.id(), now, true);
}
}
Step=>3
根据max.request.size配置的单次网络请求可传输的大小,
从**Step1**中已经准备就绪的nodes对应的partitons中取出需要发送的batch(batchDrain),为网络请求做准备.此过程中:
迭代每一个node,轮询所有partitions,每次取出一个batch,达到maxRequestSize或者迭代完一轮partitions结束.
注意:此时不在区分linger 是否超时,轮询所有partition,从队顶开始取出batch.
在执行drain操作时,针对一个broker节点的所有partitions,每一次发送数据,单个partition最多发送一个batch
此执行RecordAccumulator中drain函数排出对应的batch时,会同时设置对应batch的epoch与sequenceNumber的值.
解释一下sequenceNumber的值:
针对每一个topicPartition,在transactionManager的txnPartitionMap容器中都维护着此一个nextSequence的值,初始为0.
比如:针对某一个topicPartition,连续写入两个batch,其中:第一个batch有3条记录,第二个batch有5条记录.那么:
第一个batch的sequenceNumber的值为0, 此时nextSequence的值为 0+3=3
第二个batch的sequenceNumber的值就为3, 此时nextSequence的值变为3+5=8.
为什么sequenceNumber不是每个batch只加1呢??
因为:batch有可能在broker端处理的时候响应消息太大的errorCode,此时需要对batch进行拆分成多个batch,
而这些新的batch的sequenceNumber值,必须是比当前的缓冲区内的值更靠前,数据的写入才不会乱序.
//从已经准备就绪的nodes对应的partitions中取出`maxRequestSize`的batch,做为需要发送的数据.
//==>每个node中所有partitions都会轮询取出batch,示例:
//==> node-0中有5个partition,当取到3partition时,batchs大小已经达到最大请求大小时.
//====>此时,会记录3这个下标,下一次网络请求时会从3这个位置开始继续轮询.
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(
cluster, result.readyNodes, this.maxRequestSize, now);
//把topicPartition对应的batches添加到`inFlightBatches`容器中,表示正在进行中的batches数量.
addToInflightBatches(batches); //用于判断处理是否超时.
//只有在"max.in.flight.requests.per.connection"配置为1时,这里才会执行.
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
Step=>4
从inFlightBatches与RecordAccumulator的topicInfoMap中取出已经超时(由delivery.timeout.ms配置)的batches,
释放其占用的内存空间,并进行异常的callback回调(send消息失败,callback通知client端处理).
//对已经超时的batch进行callback回调,抛出TimeoutException,同时释放其对应的内存缓冲区.
accumulator.resetNextBatchExpiryTime();
//获取到已经超过最大延时时间的batchs,执行`failBatch`的回调,此时client的future.get会throw exception.
List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
//有已经超过最大延时时间的batch,failBatch完成future的等待并throw exception给client端(如果client端在监听future).
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for "
+ expiredBatch.topicPartition
+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
//failBatch,清理已经超时的batch,并释放内存空间.
failBatch(expiredBatch, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
transactionManager.markSequenceUnresolved(expiredBatch);
}
}
Step=>5
最后,根据已经drain得到的每个node对应topicPartition的batchs信息,生成ProduceRequest请求,
向对应leaderBroker节点发送数据,当请求响应时,将由handleProduceResponse处理程序进行处理.
生成ProduceRequest请求并发起网络通信的任务由sendProduceRequests函数来完成.
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
pollTimeout = 0;
}
//向准备好接收数据的broker节点发送对应的topicPartitions的生产数据.
sendProduceRequests(batches, now);
return pollTimeout;
流程执行到这里,整个Producer端的消息发送过程结束,等待LeaderBroker接收并处理请求后响应并完成整个写入过程.
completeBatch
当leaderBroker对Producer请求进行处理后,响应给Producer的response会交由Sender线程中的handleProduceResponse函数来进行处理.
当ack==-1时,Producer的响应必须等待partition的follower节点副本满足副本最小复制因子时才会响应(默认最小副本数为1).
leaderBroker可能 的响应错误代码: 可参见ProduceResponse类的描述
不可重试error Producer版本与broker不匹配,此时会直接failBatch释放内存.
可重试error 与broker的网络链接断开,可重试,按batch对应的sequenceNumber重新插入到队顶正确的位置.
InvalidMetadataException(可重试)topicPartition的metadata信息不正确,需要更新metadata.
MESSAGE_TOO_LARGE 消息超过配置的阀值,对batch进行split操作.
DUPLICATE_SEQUENCE_NUMBER 重复提交,直接用上一次提交的信息完成batch.
正确写入,并得到ack的响应 完成写入的batch,释放内存.
completeBatch处理流程分析(主入口)
Case=>1
如果leaderBorker的响应结果提示MESSAGE_TOO_LARGE,超出了限制,那么此时对batch进行split,按batch.size重新分batch.
同时移出过大的batch,并重新添加新split出来的batches到队列中,此时client端对future的监听保持不变(监听实例会变更为最新的实例).
//如果提交的batch太大,此时通过调用原ProducerBatch的split函数来切分成若干个小的batch后重新放入队列正确认位置.
if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 && !batch.isDone() &&
(batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) {
// If the batch is too large, we split the batch and send the split batches again. We do not decrement
// the retry attempts in this case.
log.warn(
"Got error produce response..., splitting and retrying ({} attempts left). Error: {}",
correlationId,batch.topicPartition,
this.retries - batch.attempts(),formatErrMsg(response));
//移出正在进行的batch,并对batch进行split操作.
if (transactionManager != null)
transactionManager.removeInFlightBatch(batch);
//对当前的batch进行split,并根据sequence把batch放到队列正确认位置上.
this.accumulator.splitAndReenqueue(batch);
//移出太大的batch并释放内存.
maybeRemoveAndDeallocateBatch(batch);
this.sensors.recordBatchSplit();
}
Case=>2
其他错误代码的处理,在此分支流程中,需要进行如下动作的尝试:
第一歩: 先判断响应的错误是否可重试.
=>1, 当前响应的error是否可重试,同时batch未达到最大延时时间,如果满足要求,重新把batch入队到正确的位置.
=>2, 响应DUPLICATE_SEQUENCE_NUMBER的错误代码,此时表示producer重复提交,忽视当前batch(使用上次成功提交的信息响应给client)
=>3, 其它错误(如超过最大延时时间、重试次数超过指定的值或其它不可重试的异常), 直接failBatch.
第二歩: 判断响应的异常是否是InvalidMetadataException,如果是说明需要更新metadataCache.
else if (error != Errors.NONE) {
//Step1,根据响应的errorCode进行对应的处理.
//case-1,判断当前异常是否可以重试,如果可以重试,按batch.sequenceNumber重新把batch添加到队列对应的位置(队列头部)
//==>满足以下几个条件时,可以进行重试:
//=>1,batch的等待时间未超过最大延时响应的配置时间.
//=>2,重试次数未达到最大重试次数的配置.
//=>3,RetriableException异常.
if (canRetry(batch, response, now)) {
log.warn(
"Got error produce response with correlation id ,,,,, retrying ({} attempts left). Error: {}",
correlationId,batch.topicPartition,
this.retries - batch.attempts() - 1,
formatErrMsg(response));
reenqueueBatch(batch, now); //把batch根据sequenceNumber重新添加到队列头部指定的位置.
//case-2,目前没有发现这个error从什么地方生成,但已知重复插入的情况下:
//==>broker会响应已经提交的batch对应的offset与timestamp相关信息,因此这个batch也会正常完成.
} else if (error == Errors.DUPLICATE_SEQUENCE_NUMBER) {
completeBatch(batch, response);
//case-3,其它异常情况,如超时或者无法重试的异常情况,此时将error直接抛出给client端(在监听future的情况会收到异常)
} else {
failBatch(batch, response, batch.attempts() < this.retries);
}
//Step2,如果broker端响应的异常是`InvalidMetadataException`,此时需要发起metadata的更新请求.
if (error.exception() instanceof InvalidMetadataException) {
if (error.exception() instanceof UnknownTopicOrPartitionException) {
log.warn("Received unknown topic or partition error in produce request on partition {}. The " +
"topic-partition may not exist or the user may not have Describe access to it",
batch.topicPartition);
} else {
log.warn("Received invalid metadata error in produce request on partition {} due to {}. Going " +
"to request metadata update now", batch.topicPartition,
error.exception(response.errorMessage).toString());
}
metadata.requestUpdate();
}
}
Case=>3
broker正常响应请求,成功添加消息,此时返回对应batch的baseOffset与timestamp的值,调用completeBatch结束写等待并释放内存.
//broker端正常响应,即batch被成功添加.
else {
completeBatch(batch, response);
}
// Unmute the completed partition.
//单个节点只允许一个并行网络请求的场景,完成响应后对mutePartition释放.
if (guaranteeMessageOrder)
this.accumulator.unmutePartition(batch.topicPartition);
completeBatch处理流程分析(完成batch并释放内存)
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response) {
//更新transactionManager中`txnPartitionMap`中对应topicPartition的信息:
//=>1,从`inflightBatchesBySequence`中移出此batch.
//=>2,更新lastAckSequence的值为当前batch的sequenceNumber.
//=>3,更新lastAckOffset的值为当前batch的lastOffset的值.
if (transactionManager != null) {
transactionManager.handleCompletedBatch(batch, response);
}
//设置batch的状态为完成状态,并完成对应此batch所有PrducerRecord的future的等待.
if (batch.complete(response.baseOffset, response.logAppendTime)) {
//从`inFlightBatches`中移出batch(表示完成),并释放内存
maybeRemoveAndDeallocateBatch(batch);
}
}
4,Broker处理(Leader)
当Producer生产消息后,会向partition对应的LeaderBroker节点发起Producer请求,此请求将有KafkaApis中的handleProduceRequest 处理.
handleProduceRequest(KafkaApis)
当kafkaApis接收到producer生产的消息后,会先在此处对请求进行解析,并做必要的校验.
val produceRequest = request.body[ProduceRequest]
val requestSize = request.sizeInBytes
...........写入权限校验(不分析)..........
//校验topicPartition是否是否在`metadataCache`中存在,并校验producer的请求版本.
produceRequest.data.topicData.forEach(topic => topic.partitionData.forEach { partition =>
val topicPartition = new TopicPartition(topic.name, partition.index)
// This caller assumes the type is MemoryRecords and that is true on current serialization
// We cast the type to avoid causing big change to code base.
// https://issues.apache.org/jira/browse/KAFKA-10698
val memoryRecords = partition.records.asInstanceOf[MemoryRecords]
if (!authorizedTopics.contains(topicPartition.topic))
unauthorizedTopicResponses += topicPartition -> new PartitionResponse(Errors.TOPIC_AUTHORIZATION_FAILED)
//==>检查topicPartition是否存在(有可能被删除掉,或新创建还未同步过来)
//==>如果topicPartition不存在时,对应此topicPartition的所有batch都将响应`UNKNOWN_TOPIC_OR_PARTITION`异常.
else if (!metadataCache.contains(topicPartition))
nonExistingTopicResponses += topicPartition -> new PartitionResponse(Errors.UNKNOWN_TOPIC_OR_PARTITION)
else
try {
//==>检查producer的api版本,当前版本的apiVersion为9,这里默认会全部通过.
ProduceRequest.validateRecords(request.header.apiVersion, memoryRecords)
authorizedRequestInfo += (topicPartition -> memoryRecords)
} catch {
case e: ApiException =>
invalidRequestResponses += topicPartition -> new PartitionResponse(Errors.forException(e))
}
})
根据producer传入的数据集通过副本管理器replicaManager中的appendRecords写入到topicPartition对应的数据文件中.
并在写入完成后通过sendResponseCallback进行回调来向producer响应处理结果.
if (authorizedRequestInfo.isEmpty)
//没有可写入的消息(表示本次写入校验不通过),直接向producer相应相关的异常信息.
//==>如果`ack==0`时,将向producer响应一个空response.
sendResponseCallback(Map.empty)
else {
//是否是adminClient的调用,只有adminClient的调用可以对内置进行操作.
//==>producer默认的`client.id`配置为一个空字符串.
val internalTopicsAllowed = request.header.clientId == AdminUtils.AdminClientId
//调用副本管理器`replicaManager`中的`appendRecords`将校验通过的batchs写入到segment中.
//==>完成后会通过`sendResponseCallback`来进行回调向producer响应结果.
replicaManager.appendRecords(
timeout = produceRequest.timeout.toLong,
requiredAcks = produceRequest.acks,
internalTopicsAllowed = internalTopicsAllowed,
origin = AppendOrigin.Client,
entriesPerPartition = authorizedRequestInfo,
requestLocal = requestLocal,
responseCallback = sendResponseCallback,
recordConversionStatsCallback = processingStatsCallback)
//清空请求信息,方便GC回收.
produceRequest.clearPartitionRecords()
}
ReplicaManager
appendRecords
在KafkaApis中接收到producer的写数据请求后,对records进行校验后,会调用此函数来完成当前节点副本的append操作.
Step=>1
调用ReplicaManager中的appendToLocalLog函数来完成消息在当前节点的副本写入.
并根据函数的返回值按topicPartition生成对应的ProducePartitionStatus状态信息,
在ProducePartitionStatus内部维护有用于响应给producer的PartitionResponse.
val sTime = time.milliseconds
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
origin, entriesPerPartition, requiredAcks, requestLocal)
debug("Produce to local log in %d ms".format(time.milliseconds - sTime))
//根据每个partition写入消息后得到的`LogAppendInfo`信息,生成对应的`PartitionResponse`.
val produceStatus = localProduceResults.map { case (topicPartition, result) =>
topicPartition -> ProducePartitionStatus(
result.info.lastOffset + 1, // required offset
new PartitionResponse(
result.error,
result.info.firstOffset.map(_.messageOffset).getOrElse(-1),
result.info.logAppendTime,
result.info.logStartOffset,
result.info.recordErrors.asJava,
result.info.errorMessage
)
) // response status
}
Step=>2
当前节点的本地副本写入完成,判断是否需要立即向producer端响应response的写入结果.
以下三种场景全部满足的情况下,需要等待follower节点完成副本同步后才能响应response给producer.
ack == -1即:必须等待所有follower节点完成副本同步.当前节点有写入本地的数据即:本次请求有要写入的数据.只少有一个partition的请求数据被写入成功即:在当前Producer的请求中包含有多个topicPartition数据,同时最少有一个partition被成功写入.
否则,不需要等待follower节点同步副本,可直接向producer进行响应.
//ack==-1,同时本次请求的数据不为空,同时最少有一个partition已经被成功写入到本地.
//==>此时,请求需要延时响应,等待follower节点同步副本.
if (delayedProduceRequestRequired(requiredAcks, entriesPerPartition, localProduceResults)) {
// create delayed produce operation
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
// create a list of (topic, partition) pairs to use as keys for this delayed produce operation
val producerRequestKeys = entriesPerPartition.keys.map(TopicPartitionOperationKey(_)).toSeq
// try to complete the request immediately, otherwise put it into the purgatory
// this is because while the delayed produce operation is being created, new
// requests may arrive and hence make this operation completable.
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
//不需要等待follower节点完成副本的同步,直接将处理结果响应给producer.
} else {
// we can respond immediately
val produceResponseStatus = produceStatus.map { case (k, status) => k -> status.responseStatus }
responseCallback(produceResponseStatus)
}
Step=>3
根据**Step1**中appendToLocalLog函数的返回值,生成一个action,添加到actionQueue队列中,
此时,在KafkaApis的handle(finally部分)中会触发ReplicaManager中的tryCompleteActions来执行其action,
如果follower还未完成对副本的同步,同时follower节点目前处于延时等待中,此时会唤醒follower节点继续执行fetch操作来完成副本的同步.
actionQueue.add {
() =>
localProduceResults.foreach {
case (topicPartition, result) =>
val requestKey = TopicPartitionOperationKey(topicPartition)
result.info.leaderHwChange match {
//这种情况表示本地副本添加完成后,follower节点也已经完成同步,高水位线已经更新.
//==>此时:同步唤醒follower的fetch副本同步与producer的延时响应等待.
case LeaderHwChange.Increased =>
// some delayed operations may be unblocked after HW changed
delayedProducePurgatory.checkAndComplete(requestKey)
delayedFetchPurgatory.checkAndComplete(requestKey)
delayedDeleteRecordsPurgatory.checkAndComplete(requestKey)
//=>leader节点的`endOffset`发生变化,唤醒`follower`节点对fetch操作等待,继续同步副本.
case LeaderHwChange.Same =>
// probably unblock some follower fetch requests since log end offset has been updated
delayedFetchPurgatory.checkAndComplete(requestKey)
case LeaderHwChange.None =>
// nothing
}
}
}
appendToLocalLog
从如下代码中可以看到,其通过迭代要写入数据的topicPartition找到对应的Partition实例后,
直接调用其appendRecordsToLeader来进行append操作,并把函数的处理结果返回给appendRecords函数.
//迭代请求的每个partition对应的batch数据.并向对应的partition写入.
entriesPerPartition.map { case (topicPartition, records) =>
........
if (Topic.isInternal(topicPartition.topic) && !internalTopicsAllowed) {
(topicPartition, LogAppendResult(
LogAppendInfo.UnknownLogAppendInfo,
Some(new InvalidTopicException(s"Cannot append to internal topic ${topicPartition.topic}"))))
} else {
try {
//获取到topicPartition对应的`Partition`实例,这里可能会出现如下异常:
//=>1, `KAFKA_STORAGE_ERROR` : partition在当前节点处于下线状态.
//=>2, `NOT_LEADER_OR_FOLLOWER` :topicPartition存在,但是当前broker已经不在是partition的副本节点.
//=>3, `UNKNOWN_TOPIC_OR_PARTITION` : topicPartition不存在,
val partition = getPartitionOrException(topicPartition)
//通过topicPartition对应的`Partition`实例,判断节点是否是leader,并写入消息到本地副本.
val info = partition.appendRecordsToLeader(records, origin, requiredAcks, requestLocal)
val numAppendedMessages = info.numMessages
...........
(topicPartition, LogAppendResult(info))
} catch {
......
}
}
}
appendRecordsToLeader(Partition)
当leaderBroker接收到对应topicPartition的Producer请求后,会获取到topicPartition对应的Partition实例,
并通过调用其内部的appendRecordsToLeader来把消息写入本地数据文件中.
这里引入一个配置项最小副本数min.insync.replicas,默认值1,如果producer的ack配置为-1(all)时,副本同步必须满足最小副本数才算写完.
LogAppendInfo返回的关键参数说明:
firstOffset => 本次写入的第一个batch的baseOffset的值,None表示没有写入任何消息.
lastOffset => 本次写入的最后一条消息的offset的值,-1表示没有写入任务消息.
lastLeaderEpoch => 本次写入的partitionLeaderEpoch的值,默认值-1,
maxTimestamp => 本次写入消息中最大的timestamp的值.
offsetOfMaxTimestamp => 与maxTimestamp对应,最大的timestamp对应的batch的lastOffset的值.
logAppendtime => 消息被添加到leader副本的时间.
logStartOffset => partition日志的起始offset.
lastOffsetOfFirstBatch => 本次写入消息中第一个batch对应的lastOffset的值.
fyi
可能引发的异常:
NotEnoughReplicasException: 当ack配置为-1(all)时,如果当前partition对应的isr列表小于最小副本数时,抛出此异常.
NotLeaderOrFollowerException: 当前broker节点不是partition的Leader节点时,抛出此异常.
流程分析:
首先: 函数会先判断当前broker是否是partition的leader节点,如果不是,直接throw NotLeaderOrFollowerException.
否则: 获取当前partition对应的UnifiedLog实例,如果ack == -1时判断isr是否小于最小副本数,不满足直接throw NotEnoughReplicasException.
最后: 通过UnifiedLog实例中的appendAsLeader函数把消息写入到本地数据文件中,并检查高水位线是否发生变化.
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
leaderLogIfLocal match {
case Some(leaderLog) =>
//Step2=>获取到当前partition本地副本的`UnifiedLog`实例(Leader节点)
val minIsr = leaderLog.config.minInSyncReplicas
val inSyncSize = partitionState.isr.size
//Step2-1,如果producer配置的ack是-1时,检查isr列表是否小于最小副本复制因子.
//==>如果isr小于最小副本数,抛出没有足够的副本的异常.
if (inSyncSize < minIsr && requiredAcks == -1) {
throw new NotEnoughReplicasException(s"The size of the current ISR ${partitionState.isr} " +
s"is insufficient to satisfy the min.isr requirement of $minIsr for partition $topicPartition")
}
//Step2-2,当前isr列表中同步的副本个数满足要求,通过`UnifiedLog`将消息集写入到本地副本中.
val info = leaderLog.appendAsLeader(records, leaderEpoch = this.leaderEpoch, origin,
interBrokerProtocolVersion, requestLocal)
//Step2-3,检查partition的高水位线是否发生变化,
//==>根据当前节点的endOffset判断副本是否已经同步到最新的offset位置,得到true/false.
(info, maybeIncrementLeaderHW(leaderLog))
case None =>
//Step1=>当前节点不是partition的Leader节点,抛出非leader的异常.
throw new NotLeaderOrFollowerException("Leader not local for partition %s on broker %d"
.format(topicPartition, localBrokerId))
}
}
//Step3=>根据follower是否同步到最新的endOffset位置,来生成`LeaderHwChange`.
//==>在ReplicaManager中,会根据此`LeaderHwChange`来唤醒prducer与fetch的等待.
info.copy(leaderHwChange = if (leaderHWIncremented) LeaderHwChange.Increased else LeaderHwChange.Same)
}
appendAsLeader(UnifiedLog)
此函数在Leader节点的Partition接收到要写入的消息后,会获取到partition对应的UnifiedLog实例来进行本地消息的写入.
向partition的Leader副本写入消息即由此函数来完成. 其最终会调用append函数来完成写入,并返回LogAppendInfo.
def appendAsLeader(records: MemoryRecords,
leaderEpoch: Int,
origin: AppendOrigin = AppendOrigin.Client,
interBrokerProtocolVersion: MetadataVersion = MetadataVersion.latest,
requestLocal: RequestLocal = RequestLocal.NoCaching): LogAppendInfo = {
//此时值为true,表示offset需要分配(只有metadata的offset不需要分配).
val validateAndAssignOffsets = origin != AppendOrigin.RaftLeader
//执行append操作,把消息写入到数据文件中.
//==>`leaderEpoch`初始时值为0,在每次leader变更时,epoch值为+1.
append(records, origin, interBrokerProtocolVersion, validateAndAssignOffsets,
leaderEpoch, Some(requestLocal), ignoreRecordSize = false)
}
UnifiedLog.append函数: 处理消息在本地副本中的写入.
函数的参数定义
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: MetadataVersion,
validateAndAssignOffsets: Boolean, //producer时,此值为true.
leaderEpoch: Int, //partition的LeaderEpoch的值.
requestLocal: Option[RequestLocal],
//ignoreRecordSize传入值默认为false.
ignoreRecordSize: Boolean): LogAppendInfo = {
........
}
append函数写入消息的处理流程分析:
Step=>1
检查用于记录partition对应的topicId的partition.metadata文件是否已经落盘,如果没有对文件落盘.
如果此时出现无法写入的情况(需要更新的情况下),会抛出KafkaStorageException异常.
maybeFlushMetadataFile() //对文件的写入操作时会加锁.
Step=>2
对topicPartition要写入的消息进行校验,得得到消息集对应的LogAppendInfo实例.
此过程可能抛出如下异常:
InvalidRecordException producer传入的batch对应的baseOffset不是0(producer写入消息不能带有offset信息).
RecordTooLargeException records的batch的大小超过了单个message的配置大小(max.message.bytes,默认1mb).
CorruptRecordException records的batch对应的crc校验不通过(消息内容损坏).
如果校验后,发现要写入的消息数量(batch计数)shallowCount值为0,直接返回得到的LogAppendInfo实例.否则执行**Step3**的处理.
//检查要写入的消息集对应的baseOffset是否为0,同时进行crc校验.
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize, leaderEpoch)
// return if we have no valid messages or if this is a duplicate of the last appended entry
if (appendInfo.shallowCount == 0) appendInfo //如果batch计数器的值为0,直接结束append的写入流程(没有要写入的消息).
Step=>3
本次producer请求针对此partition有需要写入的消息,对要写入的消息进行阶段(如果有校验不通过的batch时会丢弃后续所有的batch)
并对UnifiedLog实例加锁,开始执行消息的写入操作。
// trim any invalid bytes or partial messages before appending it to the on-disk log
var validRecords = trimInvalidBytes(records, appendInfo) //这里原则上会得到所有要写入的消息.
//对`UnifiedLog`实例加锁,开始处理消息写入操作.
lock synchronized {
......
}
Step=>4
对本次producer传入的消息进行offset的分配,起始值从当前partition对应log的endOffset开始.
在对records进行offset与timestamp的处理时,根据log.message.timestamp.type配置(默认为CreateTime),
来判断timestamp使用消息创建时的时间还是使用日志写入时间,可配置为CreateTime或LogAppendTime.
在此步骤完成后,得到的validateAndOffsetAssignResult数据集其对应的offset,timestamp,partitionLeaderEpoch已经完成分配.
// assign offsets to the message set
val offset = new LongRef(localLog.logEndOffset)
//更新`LogAppendInfo`中firstOffset的值,为当前logEndOffset的值.
appendInfo.firstOffset = Some(LogOffsetMetadata(offset.value))
val now = time.milliseconds
//默认未启动压缩的情况下,这里会调用`LogValidator`中的`assignOffsetsNonCompressed`函数来进行offset的分配.
//==>完成此步骤后,batch对应的offset,timestamp,partitionLeaderEpoch的值都变更为正确的值.
//==>其中,partitionLeaderEpoch的值就是当前partition的leaderEpoch的值
val validateAndOffsetAssignResult = try {
LogValidator.validateMessagesAndAssignOffsets(validRecords,
topicPartition, offset, time, now,
appendInfo.sourceCodec, appendInfo.targetCodec,
config.compact, config.recordVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
//`leaderEpoch`此时当前partition的leaderEpoch值.
leaderEpoch, origin,
interBrokerProtocolVersion,
brokerTopicStats,
requestLocal.getOrElse(throw new IllegalArgumentException(
"requestLocal should be defined if assignOffsets is true")))
} catch {
case e: IOException =>
throw new KafkaException(s"Error validating messages while appending to log $name", e)
}
Step=>5
根据**Step4**中完成对records分配的timestamp与offset信息,对LogAppendInfo的信息进行更新.
此处还会根据是否压缩来重新校验消息大小,并判断offset的写入是否顺序写入,以及firstOffset是否小于当前partition的logStartOffset.
!appendInfo.offsetsMonotonic: 这个判断在producer写入leader节点的副本时,意义不大,单个partition一次只传入一个batch的消息.
validRecords = validateAndOffsetAssignResult.validatedRecords
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
appendInfo.lastOffset = offset.value - 1
appendInfo.recordConversionStats = validateAndOffsetAssignResult.recordConversionStats
if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME)
appendInfo.logAppendTime = now
...移出掉一些校验代码...
Step=>6
根据**Step4**中完成分配的partitionLeaderEpoch与baseOffset的值,更新leader-epoch-checkpoint缓存文件.
此文件中记录每个新写入batch的最新epcoh与对应的startOffset.
// update the epoch cache with the epoch stamped onto the message by the leader
validRecords.batches.forEach { batch =>
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) {
maybeAssignEpochStartOffset(batch.partitionLeaderEpoch, batch.baseOffset)
} else {
// In partial upgrade scenarios, we may get a temporary regression to the message format. In
// order to ensure the safety of leader election, we clear the epoch cache so that we revert
// to truncation by high watermark after the next leader election.
leaderEpochCache.filter(_.nonEmpty).foreach { cache =>
warn(s"Clearing leader epoch cache after unexpected append with message format v${batch.magic}")
cache.clearAndFlush()
}
}
}
Step=>7
获取到当前UnifiedLog中的activeSegment日志段文件,准备向segment中追加消息.
检查当前的activeSegment是否需要滚动,如果需要滚动:此时会重新创建一个segment作为activeSegment,否则返回当前activeSegment.
如下几种场景下,当前的activeSegment需要滚动并生成新的activeSegment:
- segment的第一条消息写入时间已经达到segment滚动的条件.
滚动时间配置log.roll.hours,默认168小时,
segment滚动的抖动时间 log.roll.jitter.hours , 默认值0, 抖动时间为 0 ~ jitterHours(转换为毫秒)之间的随机数.
**即:(currentTime - segment.firstBatchTime) > (rollMs - jitterMs) **
- 当前
activeSegment的存储大小已经不足以存储最新要写入的消息. - 当前
activeSegment文件的offsetIndex或timeIndex文件已经写满. - 当前要写入的
batch的maxOffset减去activeSegment.baseOffset的值超过了Int.maxValue的值.
即:segment中的相对offset值太大,一个segment文件中存储的最大相对offset不能超过Int.maxValue.
如果以上几个条件中的任意一个条件满足,那么当前segment会完成写操作(滚动),并重新创建一个segment设置为activeSegment.
关于segment的滚动,见后续的分析.
// check messages set size may be exceed config.segmentSize
if (validRecords.sizeInBytes > config.segmentSize) {
throw new RecordBatchTooLargeException(s"Message batch size is ${validRecords.sizeInBytes} bytes in append " +
s"to partition $topicPartition, which exceeds the maximum configured segment size of ${config.segmentSize}.")
}
//判断activeSegment是否需要滚动,并返回滚动后最新的activeSegment.
// maybe roll the log if this segment is full
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
Step=>8
根据本次要写入的消息的firstOffset与activeSegment中的baseOffset以及当前activeSegment的文件大小生成LogOffsetMetadata.
同时从通过producerStateManager组件检查当前producerId写入的batch是否重复提交.
在producerStateManager组件中,记录有每一个producerId最近提交的5个batch的BatchMetadata信息.
**BatchMetadata信息:(lastSeq: Int, lastOffset: Long, offsetDelta: Int, timestamp: Long) **
判断重复的方法:
从本次要写入的batch中找到其对应的producerId,并找到其存储的batchMetadatas队列,
检查队列中是否存在与当前要写入batch的firstSeq,lastSeq相同的记录,如果有表示重复提交.
否则:表示producerStateManager组件中不存在当前要写入的batch,生成BatchMetadata,并记录到producerId的队列中.
//根据当前activeSegment与本次写入的firstOffset信息生成`LogOffsetMetadata`,
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
//通过`producerStateManager`组件检查`producerId`下本次提交的`batch`是否是重复提交的batch.
//==>如果本次要写入的`batch`在`producerStateManager`中不存在,记录当前producerId本次写入batch的BatchMetadata信息.
val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState(
logOffsetMetadata, validRecords, origin)
判断是否重复提交的代码片段
//producerStateManager中,找到producerId对应的batchMetadata队列,
//根据判断其sequence的值是否在队列中有记录来判断是否重复提交.
val duplicate = batchMetadata.filter { metadata =>
firstSeq == metadata.firstSeq && lastSeq == metadata.lastSeq
}
batch在producerId中不存在时,记录到batchMetadata队列的代码片段
//非事务场景下,`maybeCompletedTxn`的返回值为`None`.
val maybeCompletedTxn = updateProducers(producerStateManager, batch, updatedProducers, firstOffsetMetadata, origin)
//==>updateProducers
private def updateProducers(producerStateManager: ProducerStateManager,
batch: RecordBatch,
producers: mutable.Map[Long, ProducerAppendInfo],
firstOffsetMetadata: Option[LogOffsetMetadata],
origin: AppendOrigin): Option[CompletedTxn] = {
val producerId = batch.producerId
//如果`producerId`不存在时,先存储一个用于存储`producerId`的batchMetadata的队列.
val appendInfo = producers.getOrElseUpdate(producerId, producerStateManager.prepareUpdate(producerId, origin))
appendInfo.append(batch, firstOffsetMetadata)
}
//==>向batchMetadata队列中记录当前插入的batch的信息
//==>appendInfo.append=>appendDataBatch=>ProducerStateEntry.addBatch=>addBatchMetadata
//=====>`ProducerStateEntry.NumBatchesToRetain`是一个固定值,存在最近5条记录.
private def addBatchMetadata(batch: BatchMetadata): Unit = {
if (batchMetadata.size == ProducerStateEntry.NumBatchesToRetain)
batchMetadata.dequeue()
batchMetadata.enqueue(batch)
}
Step=>9=>Case1
如果**Step8**中发现本次提交的batch是重复提交的batch时,根据LogAppendInfo的返回信息,
跳过本次写入,并直接结束appendAsLeader函数的处理,
此时整个leaderBroker处理本次Producer的写消息请求将返回上一次提交的记录信息.
maybeDuplicate match {
case Some(duplicate) =>
appendInfo.firstOffset = Some(LogOffsetMetadata(duplicate.firstOffset))
appendInfo.lastOffset = duplicate.lastOffset
appendInfo.logAppendTime = duplicate.timestamp
appendInfo.logStartOffset = logStartOffset
Step=>9=>Case2
本次提交的batch不是重复提交的数据,开始向本地数据文件中进行写入操作.即:Step8中得到的maybeDuplicate返回值为None
maybeDuplicate match {
case Some(duplicate) =>
...重复提交的场景...
case None =>
//开始处理这部分的流程.
....非重复提交,向本地文件中写入....
}
写入消息到本地副本的处理流程:
更新用于返回给调用方的LogAppendInfo的firstOffset的信息,此时在offset的基础上,再追加其对应的segment与当前segment的大小.
//更新用于返回给调用方的`LogAppendInfo`的firstOffset的信息.
//==>此时会记录firstOffset对应的segment与当前segment的大小.
appendInfo.firstOffset = appendInfo.firstOffset.map { offsetMetadata =>
offsetMetadata.copy(segmentBaseOffset = segment.baseOffset, relativePositionInSegment = segment.size)
}
通过LocalLog实例,向topicPartition的activeSegment文件中写入消息. 此时:
1=>,如果当前activeSegment的大小是0时(新segment文件),更新rollingBasedTimestamp为当前写入batch的maxTimestamp的值.
缓存起来,在判断segment是否需要滚动时,可减少io操作.
2=>,向segment对应的FileChannel通道中写入本次的消息集records.
3=>,更新segment中缓存的maxTimestampAndOffsetSoFar的值为TimestampOffset(largestTimestamp, shallowOffsetOfMaxTimestamp)
即:记录timeIndex的最后一条索引信息的缓存(timestamp,offset).
4=>,判读从上一次写入索引记录后,当前写入消息的大小是否达到写入新索引记录的条件,如果达到,向offsetIndex与timeIndex中写入索引.
在segment中,跳跃多少数据写一次索引由index.interval.bytes配置项解决,默认为4kb.
即表示:每写入4kb的数据到segment后向offsetIndex与timeIndex中写入一条索引信息.
索引文件的大小由log.index.size.max.bytes配置项决定,默认为10mb.
OffsetIndex索引文件的结构:
offsetIndex中,每条索引记录占8byte的空间,记录存储格式:
4byte(offset)=>offset的高32位的值(offset-baseOffset), 4byte(position)=>当前offset对应segment文件的起始位置
在offsetIndex中记录的offset值是当前写入的batch的lastOffset的值.
也就是说,在查找时,通过offset对应的position位置开始读取的一个batch的结束offset即是offsetIndex中记录到的offset.
同时,一个segment按默认1gb的存储空间来算,10mb的索引最大可记录134217728条索引信息.
TimeIndex索引文件的结构:
timeIndex中,每条索引记录占12byte的空间,记录存储格式:
8byte(timestamp), 4byte(offset)=>offset的高32位的值(offset-baseOffset)
在timeIndex中记录的timestamp值是当前写入的records中的最大的timestamp,以及这个timestamp对应的offset记录.
同时,一个segment按默认1gb的存储空间来算,10mb的索引最大可记录89478485条索引信息.
5=>,最后,根据写入records的lastOffset,更新本地副本的endOffset的信息nextOffsetMetadata.
localLog.append(appendInfo.lastOffset, appendInfo.maxTimestamp, appendInfo.offsetOfMaxTimestamp, validRecords)
//LocalLog.append函数:
private[log] def append(lastOffset: Long, largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long, records: MemoryRecords): Unit = {
//向activeSegment中追加本次要写入的消息集,
//==>`shallowOffsetOfMaxTimestamp`表示`maxTimestamp`对应的记录的offset值.
segments.activeSegment.append(largestOffset = lastOffset, largestTimestamp = largestTimestamp,
shallowOffsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp, records = records)
//更新当前节点副本的endOffset的值(`nextOffsetMetadata`).
//==>包含endOffset,当前activeSegment的baseOffset与大小.
updateLogEndOffset(lastOffset + 1)
}
检查当前节点的高水位线highWatermark是否大于等于当前节点的endOffset的值,如果超过更新高水位线为endOffset.
主要在以下两个场景下,可能会涉及到更新高水位线:
=>1,当前log文件发生了truncation操作,高水位线的值超过了当前endOffset.
=>2,当前activeSegment滚动到了新的segment文件,此时需要更新highWatermarkMetadata来让其指向到最新的segment.
updateHighWatermarkWithLogEndOffset()
//updateHighWatermarkWithLogEndOffset函数的实现代码
private def updateHighWatermarkWithLogEndOffset(): Unit = {
// Update the high watermark in case it has gotten ahead of the log end offset following a truncation
// or if a new segment has been rolled and the offset metadata needs to be updated.
if (highWatermark >= localLog.logEndOffset) {
updateHighWatermarkMetadata(localLog.logEndOffsetMetadata)
}
}
将本次写入的batchMatadata写入的producerStateManager组件中,用于后续新的写入请求时判断是否重复提交.
根据**Setp8**中生成的batchMetadata信息,存储在updatedProducers变量中(记录当前producerId本次写入的batchMetadata),
// update the producer state
updatedProducers.values.foreach(producerAppendInfo => producerStateManager.update(producerAppendInfo))
更新producerStateManager中记录的lastMapOffset的值为当前本地副本的endOffset.
// always update the last producer id map offset so that the snapshot reflects the current offset
// even if there isn't any idempotent data being written
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
最后: 根据flush.messages配置的消息条数flush的间隔,判断是否需要对消息的写入进行落盘,
这个配置默认未启用,不建议配置此值,可通过副本复制来解决数据丢失的问题,把flush的操作交给操作系统来完成.
if (localLog.unflushedMessages >= config.flushInterval) flush(false)
当这个步骤处理完成后,整个写消息的流程结束,此时会返回消息写入时生成的LogAppendInfo实例给调用方.
并等待follower节点发起fetch操作来同步副本后更新高水位线来让producer的写等待响应.
roll(LogSegment)
主流程分析
在UnifiedLog的append函数中(见appendAsLeader(UnifiedLog)分析中的Step7部分),
在向当前activeSegment写入消息前,会先检查当前的activeSegment是否达到了滚动的条件,如果达到条件,会滚动一个新的activeSegment.
此函数即是在达到滚动条件后处理activeSegment滚动的处理流程部分(由UnifiedLog中的maybeRoll函数触发).
roll函数的触发部分代码:
//rollOffset的记录原则上是当前logEndOffset的值(即当前要写入消息的firstOffset),
//`getOrElse(maxOffsetInMessages - Integer.MAX_VALUE)` (只存在于早期版本V2以前)
//==>如果firstOffset不存在时,会通过本次要写入的`lastOffset`减去Int.maxValue来得到一个启发值.
//====>此时,这个值可能不是一个真实的offset,但一定是小于或等于真实offset的值.
val rollOffset = appendInfo
.firstOffset
.map(_.messageOffset)
.getOrElse(maxOffsetInMessages - Integer.MAX_VALUE)
//发起`activeSegment`的滚动,此函数返回一个新的`activeSegment`实例.
roll(Some(rollOffset))
roll函数的实现代码
=>1,调用LocalLog.roll函数来对当前activeSegment执行Inactive动作,并根据endOffset生成新的activeSegment文件.
=>2,根据当前新生成的activeSegment的baseOffset更新producerStateManager组件的lastMapOffset值
=>3,根据最新的segment对应的baseOffset的值,生成producers的snapshot文件(offset(20字符).snapshot).
=>4,由于最新的logEndOffset更新,检查如果高水位线值与logEndOffset相同时,更新高水位线metadata(highWatermarkMetadata).
=>5,通过flushUptoOffsetExclusive对新segment前的所有segment文件强制flush,
并更新recoveryPoint的值为新segment的baseOffset与lastFlushedTime的最新的flush时间.
def roll(expectedNextOffset: Option[Long] = None): LogSegment = lock synchronized {
val newSegment = localLog.roll(expectedNextOffset)
// Take a snapshot of the producer state to facilitate recovery. It is useful to have the snapshot
// offset align with the new segment offset since this ensures we can recover the segment by beginning
// with the corresponding snapshot file and scanning the segment data. Because the segment base offset
// may actually be ahead of the current producer state end offset (which corresponds to the log end offset),
// we manually override the state offset here prior to taking the snapshot.
producerStateManager.updateMapEndOffset(newSegment.baseOffset)
producerStateManager.takeSnapshot()
updateHighWatermarkWithLogEndOffset()
// Schedule an asynchronous flush of the old segment
scheduler.schedule("flush-log", () => flushUptoOffsetExclusive(newSegment.baseOffset))
newSegment
}
roll(LocalLog)
对当前log的activeSegment进行滚动,并生成一个新的activeSegment. 此函数实现activeSegment滚动的处理流程:
Step=>1
根据函数传入的expectedNextOffset(通常等于logEndOffset),与logEndOffset取最大值来生成新的segment文件.
segment文件名称: offset(20个字符长度).log
val newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset)
val logFile = LocalLog.logFile(dir, newOffset)
val activeSegment = segments.activeSegment
Step=>2=>Case1
如果当前newOffset对应的segment文件已经存在时,判断segment文件是否是空文件,否则抛出KafkaException异常.
如果已经存在的文件是空文件并且文件已经加载到LogSegments数据结构中(跳表),删除此segment并重新创建一个.
//如果要生成的目标`segment`文件存在,判断文件是否是空文件,如果是空文件,删除原来的文件重新创建.
if (segments.contains(newOffset)) {
// segment with the same base offset already exists and loaded
if (activeSegment.baseOffset == newOffset && activeSegment.size == 0) {
// We have seen this happen (see KAFKA-6388) after shouldRoll() returns true for an
// active segment of size zero because of one of the indexes is "full" (due to _maxEntries == 0).
warn(s"Trying to roll a new log segment with start offset $newOffset ....")
//删除当前的`activeSegment`,并重新创建一个新的`segment`文件.
//==>此时,新创建的`segment`自动变为`activeSegment`.
val newSegment = createAndDeleteSegment(newOffset, activeSegment, asyncDelete = true, LogRoll(this))
updateLogEndOffset(nextOffsetMetadata.messageOffset)
info(s"Rolled new log segment at offset $newOffset in ${time.hiResClockMs() - start} ms.")
return newSegment
} else {
//当前`activeSegment`已经创建,并且已经在进行数据的写入,直接抛出异常.
throw new KafkaException(s"Trying to roll a new log segment for topic partition...." +")
}
}
Step=>2=>Case2
当前准备新创建的activeSegment的baseOffset小于当前activeSegment的baseOffset,直接抛出KafkaException异常.
else if (!segments.isEmpty && newOffset < activeSegment.baseOffset) {
throw new KafkaException(
s"Trying to roll a new log segment for topic partition $topicPartition with ...t")
}
Step=>2=>Case3
正常逻辑,准备新创建的activeSegment文件不存在,先清理掉准备创建的segment文件对应的索引文件相关文件(如果存在)
同时,对当前的activeSegment文件执行Inactive动作,即(onBecomeInactiveSegment):
=>1,将当前segment中最后一条已经写入的maxTimestamp与maxTimestamp对应的offset写入到timeIndex索引文件中.
=>2,根据当前索引文件的存储记录数,对offsetIndex与timeIndex文件进行截断.
=>3,如果segment是预先创建好指定存储空间大小的文件时,按当前存储的实际大小对文件进行截断.
else {
val offsetIdxFile = offsetIndexFile(dir, newOffset)
val timeIdxFile = timeIndexFile(dir, newOffset)
val txnIdxFile = transactionIndexFile(dir, newOffset)
//如果准备创建的`segment`对应的三个索引文件存在,先清理掉这些索引文件.
for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {
warn(s"Newly rolled segment file ${file.getAbsolutePath} already exists; deleting it first")
Files.delete(file.toPath)
}
segments.lastSegment.foreach(_.onBecomeInactiveSegment())
}
Step=>3
创建一个新的segment文件作为当前log的activeSegment文件,其baseOffset的值就是函数传入的newOffset.
//代码没什么好解释的.
val newSegment = LogSegment.open(dir,
baseOffset = newOffset,
config,
time = time,
initFileSize = config.initFileSize,
preallocate = config.preallocate)
segments.add(newSegment) //添加到`LogSegments`的跳表数据结构中,方便快速定位
// We need to update the segment base offset and append position data of the metadata when log rolls.
// The next offset should not change.
updateLogEndOffset(nextOffsetMetadata.messageOffset)
info(s"Rolled new log segment at offset $newOffset in ${time.hiResClockMs() - start} ms.")
newSegment
DelayedProduce
DelayedProduce作用于延时响应Producer请求的response,当Producer配置的ack为-1时,需要等待follower完成副本同步后才能给请求方响应成功失败.
个人感觉,这部分采用future来实现会让整个delayed部分代码更容易理解
在replicaManager中执行appendRecords写入消息时,此时会生成一个延时响应的DelayedProduce实例.
此实例会根据本次producer写入的topicPartitions生成对应的watcherKey并将DelayedProduce加入到其Watchers的等待队列中.
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
//生成用于延时响应`Producer`请求的实例,超时或者follower完成副本同步后响应`Producer`的请求.
//==>当DelayedProduce完成时,通过执行`responseCallback`来向请求方响应response.
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
// create a list of (topic, partition) pairs to use as keys for this delayed produce operation
val producerRequestKeys = entriesPerPartition.keys.map(TopicPartitionOperationKey(_)).toSeq
//根据topicPartition生成的watcherKey,找到其`Watchers`实例,将`delayedProduce`添加到观察者的等待队列中.
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
在每个Partition实例初始化时,会将replicaManager中的三个delayedPurgatory存入到Partition实例中(如下所示:).
val delayedOperations = new DelayedOperations(
topicPartition,
replicaManager.delayedProducePurgatory,
replicaManager.delayedFetchPurgatory,
replicaManager.delayedDeleteRecordsPurgatory)
当Follower节点在发起Fetch请求同步partition的副本时,在Partition的fetchRecords中获取到最新消息后,会同时处理replica的副本同步状态.
//Partition.fetchRecords函数中处理follower同步副本的场景.
if (fetchParams.isFromFollower) {
// Check that the request is from a valid replica before doing the read
val (replica, logReadInfo) = inReadLock(leaderIsrUpdateLock) {
//先检查当前节点是否是partition的Leader节点,如果是,获取到本地副本的log实例.
val localLog = localLogWithEpochOrThrow(
fetchPartitionData.currentLeaderEpoch,
fetchParams.fetchOnlyLeader
)
//检查follower节点是否存在,从`remoteReplicasMap`中获取到`Replica`实例.
val replica = followerReplicaOrThrow(
fetchParams.replicaId,
fetchPartitionData
)
//读取最新的消息数据.
val logReadInfo = readFromLocalLog(localLog)
(replica, logReadInfo)
}
//非delayFetch的场景下(当前的fetch能够获取到数据时fetch不会阻塞等待)
//==>同时fetch传入的epoch与offset在当前leader的正常数据范围内.
//==>此时,通过调用updateFollowerFetchState函数来更新当前请求的follower节点的fetch状态.
if (updateFetchState && logReadInfo.divergingEpoch.isEmpty) {
updateFollowerFetchState(
replica,
followerFetchOffsetMetadata = logReadInfo.fetchedData.fetchOffsetMetadata,
followerStartOffset = fetchPartitionData.logStartOffset,
followerFetchTimeMs = fetchTimeMs,
leaderEndOffset = logReadInfo.logEndOffset
)
}
logReadInfo
}
在updateFollowerFetchState函数中,对replica的副本状态进行更新后,会判断副本的logEndOffset是否发生变化.
follower节点上一次请求时的logEndOffset小于本次请求时传入的logEndOffset
如果follower的logEndOffset发生变化时,此时会通过delayedOperations的checkAndCompleteAll函数来尝试完成producer的响应等待.
// some delayed operations may be unblocked after HW or LW changed
if (leaderLWIncremented || leaderHWIncremented)
tryCompleteDelayedRequests()
private def tryCompleteDelayedRequests(): Unit = delayedOperations.checkAndCompleteAll()
//delayedOperations最终会调用`DelayedOperationPurgatory`的`checkAndComplete`函数来尝试完成`producer`的延时响应的等待.
def checkAndCompleteAll(): Unit = {
val requestKey = TopicPartitionOperationKey(topicPartition)
fetch.checkAndComplete(requestKey)
produce.checkAndComplete(requestKey) //这个部分,尝试完成producer的等待.
deleteRecords.checkAndComplete(requestKey)
}
接下来看看DelayedOperationPurgatory中的checkAndComplete函数实现代码
def checkAndComplete(key: Any): Int = {
val wl = watcherList(key)
//获取到watcherKey(topicPartition)对应的Watchers队列,
//==>通过执行其`tryCompleteWatched`函数来尝试完成等待队列中的`DelayedProducer`
val watchers = inLock(wl.watchersLock) { wl.watchersByKey.get(key) }
val numCompleted = if (watchers == null)
0
else
watchers.tryCompleteWatched()
if (numCompleted > 0) {
debug(s"Request key $key unblocked $numCompleted $purgatoryName operations")
}
numCompleted
}
由上面的代码能看出,其直接根据topicPartition对应的watcherKey获取到对应的Watchers队列,并执行其tryCompleteWatched.
因此,这里还需要分析Watchers中的tryCompleteWatched函数的实现:
def tryCompleteWatched(): Int = {
var completed = 0 //本次执行完成`DelayedProducer`的队列数量.
//获取到所有延时`producer`队列的迭代器,并迭代进行处理.
val iter = operations.iterator()
while (iter.hasNext) {
val curr = iter.next()
//如果其它线程已经完成了此`DelayedProducer`(如超时或另一次写入),从队列中移出此等待.
if (curr.isCompleted) {
iter.remove()
//尝试执行`DelayedProducer`的`safeTryComplete`来检查是否可完成此等待.
//==>此函数对`DelayedProducer`加锁后直接调用`tryComplete`来处理.
//==>`safeTrycomplte`函数返回`true`表示对应的`producer`的等待已经被唤醒.
} else if (curr.safeTryComplete()) {
iter.remove()
completed += 1
}
}
//如果当前`watchers`的等待队列为空,直接移出此观察者对应的key.
if (operations.isEmpty)
removeKeyIfEmpty(key, this)
completed
}
最后:
在DelayedProducer中通过其tryComplete函数来判断本次写入(此Delayed对应的producer)的所有topicPartition的副本同步是否达到了最新的offset.
所谓最新的offset:表示在这一次producer提交后leader当时的endOffset的值,只有follower同步到此offset时,才算完成写操作
==>1,迭代Producer写入的所有topicPartition,判断这个partition的高水位线是否已经达到Producer写入时leader的endOffset的值.
同时需要判断ISR列表是否满足最小副本复制因子.
==>2,如果Producer本次写入的所有topicPartitions对应的acksPending的值都已经是false表示全部完成处理.
此时,取消对本次写等待的超时timer的定时器的执行,并向Producer响应response.
响应response时,会调用KafkaApis中handlerpoduceRequest内部的sendResponseCallback来进行响应.
override def tryComplete(): Boolean = {
// check for each partition if it still has pending acks
produceMetadata.produceStatus.forKeyValue { (topicPartition, status) =>
trace(s"Checking produce satisfaction for $topicPartition, current status $status")
//检查当前`producer`对应的`ackPending`是否还处于等待中(初始时未完成写操作的partition对应此值为true)
if (status.acksPending) {
val (hasEnough, error) = replicaManager.getPartitionOrError(topicPartition) match {
case Left(err) =>
// Case A
(false, err)
//判断当前partition的高水位线(`highWatermark`)是否达到了`requiredOffset`的值,
//==>如果高水位线的值达到了`requiredOffset`(producer写入时leader的logEndOffset),
//=====>此时判断isr列表中同步的副本个数是否小于最少同步因子的数量,如果满足条件:
//=====>本次`producer`的写操作在对应的partition中完成.
case Right(partition) =>
partition.checkEnoughReplicasReachOffset(status.requiredOffset)
}
// Case B || C.1 || C.2
//如果操作出现异常,或者此时写等待的副本成功完成同步,设置`acksPending`为false,表示完成(成功或失败)
if (error != Errors.NONE || hasEnough) {
status.acksPending = false
status.responseStatus.error = error
}
}
}
//本次`producer`的写消息请求所有的topicPartition的处理完成(副本同步达到最新的高水位线)
//==>清理timeout的定时器,同时执行`KafkaApis`中的`sendResponseCallback`的回调.
if (!produceMetadata.produceStatus.values.exists(_.acksPending))
forceComplete()
else
false
}
Partition.checkEnoughReplicasReachOffset检查follower的副本同步是否满足requiredOffset的条件
即:判断follower节点副本的同步是否已经满足最小副本数量,高水位线达到了producer写入时leader的endOffset的值(requiredOffset)
def checkEnoughReplicasReachOffset(requiredOffset: Long): (Boolean, Errors) = {
leaderLogIfLocal match {
case Some(leaderLog) =>
//获取到当前ISR的列表,
val curMaximalIsr = partitionState.maximalIsr
if (isTraceEnabled) {
........
}
val minIsr = leaderLog.config.minInSyncReplicas
//判断当前partition的高水位线是否达到requiredOffset,如果达到,
//==>同时ISR列表数量不小于最小副本复制因子,表示本次`producer`写成功.
if (leaderLog.highWatermark >= requiredOffset) {
if (minIsr <= curMaximalIsr.size)
(true, Errors.NONE)
else
(true, Errors.NOT_ENOUGH_REPLICAS_AFTER_APPEND)
} else
(false, Errors.NONE)
case None =>
(false, Errors.NOT_LEADER_OR_FOLLOWER)
}
}
sendResponseCallback(KafkaApis)
当replicaManager完成对请求消息的写入后(Follower节点完成副本同步),会通过调用此函数来向producer进行响应.
此函数是handleProducerRequest函数内部定义的一个函数.
def sendResponseCallback(responseStatus: Map[TopicPartition, PartitionResponse]): Unit = {
//先合并所有的`PartitionResponse`的信息.
val mergedResponseStatus = responseStatus ++ unauthorizedTopicResponses ++
nonExistingTopicResponses ++ invalidRequestResponses
var errorInResponse = false
mergedResponseStatus.forKeyValue { (topicPartition, status) =>
if (status.error != Errors.NONE) {
errorInResponse = true
debug("Produce request with correlation id %d from client %s on partition %s failed due to %s".format(
request.header.correlationId,
request.header.clientId,
topicPartition,
status.error.exceptionName))
}
}
//限流的处理,不用管.
val timeMs = time.milliseconds()
val bandwidthThrottleTimeMs = quotas.produce.maybeRecordAndGetThrottleTimeMs(request, requestSize, timeMs)
val requestThrottleTimeMs =
if (produceRequest.acks == 0) 0
else quotas.request.maybeRecordAndGetThrottleTimeMs(request, timeMs)
val maxThrottleTimeMs = Math.max(bandwidthThrottleTimeMs, requestThrottleTimeMs)
if (maxThrottleTimeMs > 0) {
request.apiThrottleTimeMs = maxThrottleTimeMs
if (bandwidthThrottleTimeMs > requestThrottleTimeMs) {
requestHelper.throttle(quotas.produce, request, bandwidthThrottleTimeMs)
} else {
requestHelper.throttle(quotas.request, request, requestThrottleTimeMs)
}
}
//向`Producer`响应本次写入的`reponse`
if (produceRequest.acks == 0) {
//如果`Producer`写入的`ack`是0时,表示client不需要broker的响应,此时只响应一个空的response.
//==>但是,即使是`ack == 0`的情况下,如果本次请求处理出错,会关闭与client端的链接来通知client端重新更新metadata.
if (errorInResponse) {
val exceptionsSummary = mergedResponseStatus.map { case (topicPartition, status) =>
topicPartition -> status.error.exceptionName
}.mkString(", ")
info(
s"Closing connection due to error during produce request with correlation id ${request.header.correlationId} " +
s"from client id ${request.header.clientId} with ack=0\n" +
s"Topic and partition to exceptions: $exceptionsSummary"
)
requestChannel.closeConnection(request, new ProduceResponse(mergedResponseStatus.asJava).errorCounts)
} else {
//向`producer`响应一个NoOpResponse.
requestHelper.sendNoOpResponseExemptThrottle(request)
}
} else {
//`ack != 0`的情况下,向`Producer`响应本次请求的处理结果.
requestChannel.sendResponse(request, new ProduceResponse(mergedResponseStatus.asJava, maxThrottleTimeMs), None)
}
}




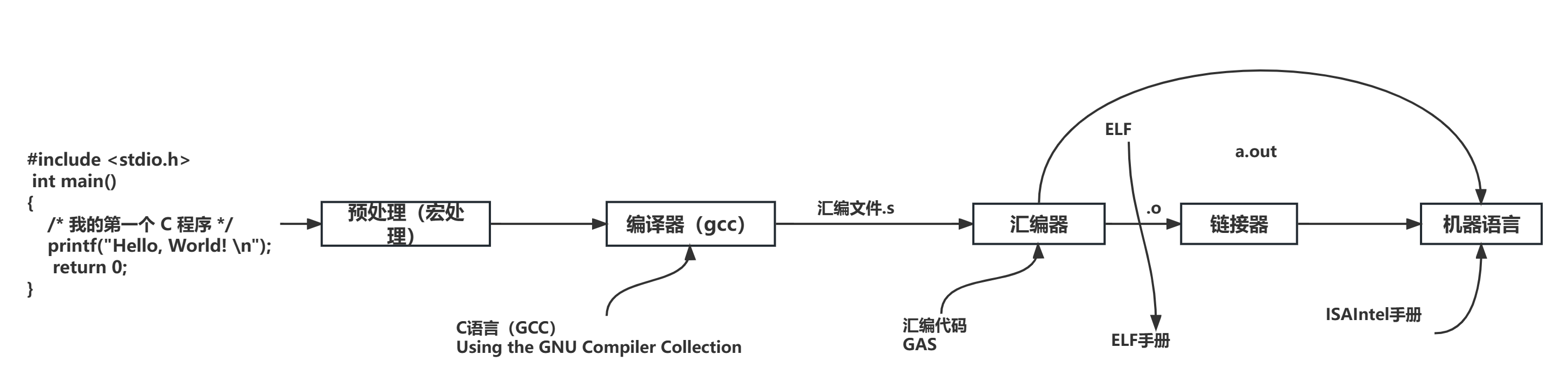







![(五)汇编语言——[bx]和loop指令](https://img-blog.csdnimg.cn/f8a59e6a6c204752a14754c8c351255a.png)