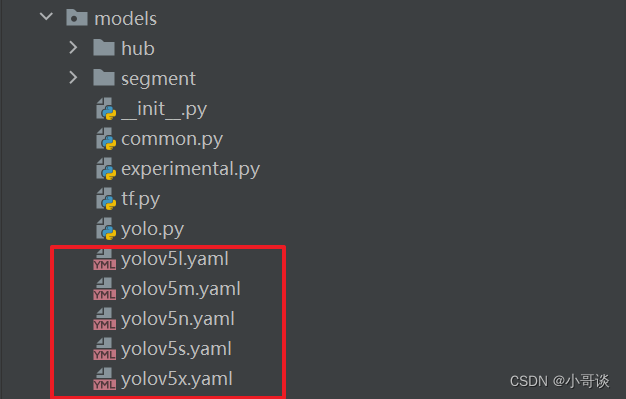
前言:Hello大家好,我是小哥谈。配置文件yolov5s.yaml在YOLOv5模型训练过程中发挥着至关重要的作用,属于初学者必知必会的文件!在YOLOv5-6.0版本源码中,配置了5种不同大小的网络模型,分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,其中YOLOv5n是网络深度和宽度最小但检测速度最快的模型,其他4种模型都是在YOLOv5n的基础上不断加深、加宽网络使得网络规模扩大,在增强模型检测性能的同时增加了计算资源和速度消耗。出于对检测精度、模型大小、检测速度的综合考量,本文选择普遍使用的YOLOv5s作为研究对象进行详细介绍,希望大家学完之后能够对配置文件yolov5s.yaml有一个清晰的理解!🌈
目录
🚀1.基本概念
💥💥1.1 什么是yaml?
💥💥1.2 什么是yolov5s.yaml?
🚀2.版本说明
🚀3.源码解析
🚀4.整体解析
🚀5.作者说明

🚀1.基本概念
💥💥1.1 什么是yaml?
YAML(YAML Ain't Markup Language)是一种轻量级的标记语言,用于表示数据的序列化格式。YAML 的设计目标是提供一种易读且容易写的数据格式,同时具有清晰的结构。它通常用于配置文件、数据交换、配置管理和其他需要人类可读性的应用场景。
💥💥1.2 什么是yolov5s.yaml?
yolov5s.yaml是YOLOv5目标检测算法的配置文件之一,它定义了模型的基本结构和参数。其中,nc表示分类数目,depth_multiple表示模型深度的倍数,width_multiple表示每层通道数的倍数。此外,yolov5s.yaml还包括了anchors、Backbone和Head等参数的定义。anchors定义了目标框的大小和比例,Backbone定义了模型的主干网络结构,Head定义了检测头的结构和参数。通过调整这些参数,可以对模型的性能和速度进行优化。
说明:♨️♨️♨️
本篇文章针对yolov5s.yaml配置文件的解析基于YOLOv5-6.0版本。
🚀2.版本说明
YOLOv5的网络模型结构由位于models文件夹下的yaml文件定义。以YOLOv5的6.0版本为例,其models文件夹下有多个yaml文件,它们分别是yolov5n.yaml、yolov5s.yaml、yolov5m.yaml、yolov5l.yaml、yolov5x.yaml,其区别仅为depth_multiple和width_multiple两个参数不同,其他都是相同的。虽然5个yaml文件中的backbone和head部分完全相同,但通过depth_multiple和width_multiple这两个参数即可实现不同复杂度的模型设计。
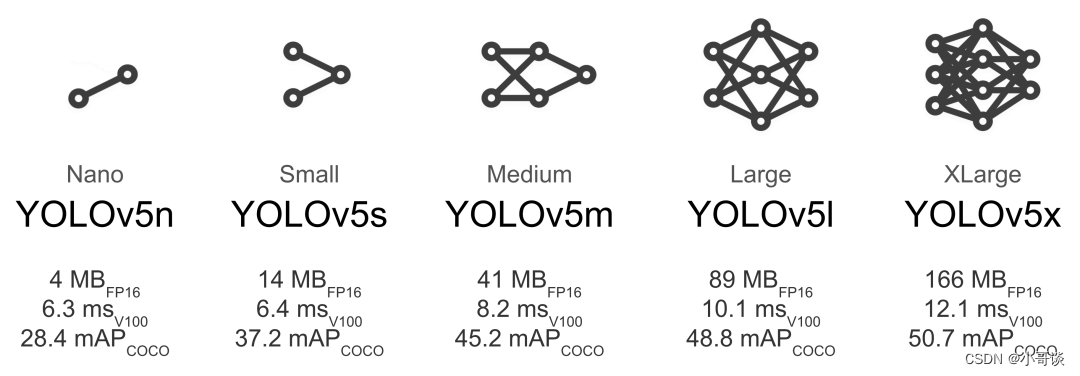
YOLOv5模型的深度和宽度是可以根据需求进行调整的。YOLOv5模型的深度由网络中卷积层的数量和每个卷积层中卷积核的数量决定,而宽度则由网络中每个卷积层的输入通道数和输出通道数决定。在训练过程中,可以通过调整深度和宽度来平衡模型的精度和速度。
具体来说,YOLOv5-6.0版本模型包含了n、s、m、l、x五个版本,分别对应不同的深度和宽度。其中,n版本是最轻量级的版本,适合在资源受限的设备上运行;而x版本则是最大的版本,可以获得最高的检测精度,但需要更多的计算资源。
| 版本/参数 | depth_multiple | width_multiple |
| yolov5n.yaml | 0.33 | 0.25 |
| yolov5s.yaml | 0.33 | 0.50 |
| yolov5m.yaml | 0.67 | 0.75 |
| yolov5l.yaml | 1.0 | 1.0 |
| yolov5x.yaml | 1.33 | 1.25 |
注意:♨️♨️♨️
YOLOv5-6.0的五个版本即n、s、m、l、x模型结构完全相同,区别仅在于模型的深度和宽度,即depth_multiple和width_multiple,并且按照顺序由小到大,模型深度和宽度不断增大。
关于这五个版本的模型复杂度和相关参数,详细对比如下所示:
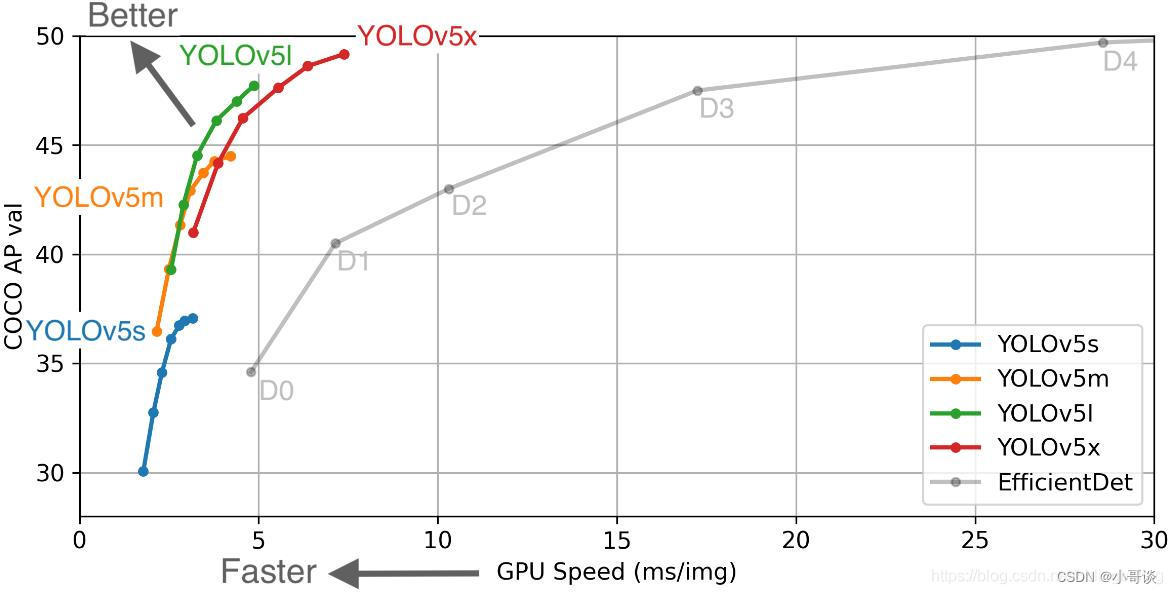

YOLOv5除了提供n、s、m、l、x版本之外,还提供了n6、s6、m6、l6、x6这五个版本,区别在于n、s、m、l、x版本的输入尺寸是640×640,最终会对图像进行32倍下采样,并输出3个预测特征层,而n6、s6、m6、l6、x6这五个版本的输入尺寸是1280×1280,最终会对输入图像进行64倍下采样,并且会输出4个预测特征层。
总结:♨️♨️♨️
n、s、m、l、x版本:输入尺寸640×640,32倍下采样,3个预测特征层。
n6、s6、m6、l6、x6版本:输入尺寸1280×1280,64倍下采样,4个预测特征层。
关于n6、s6、m6、l6、x6这五个版本对比如下所示:
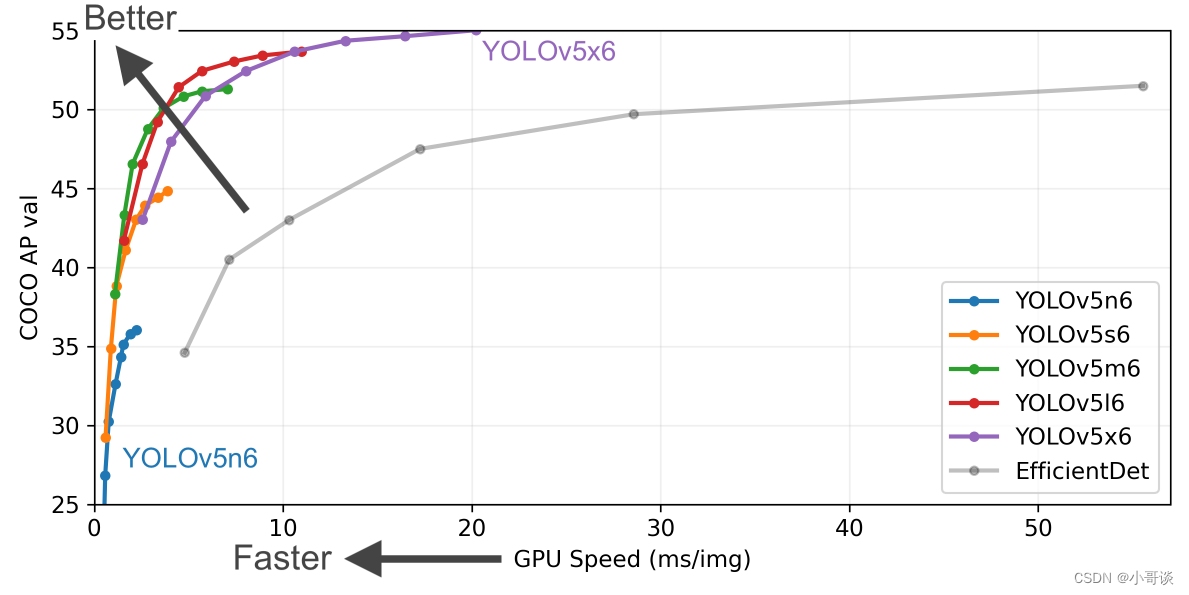
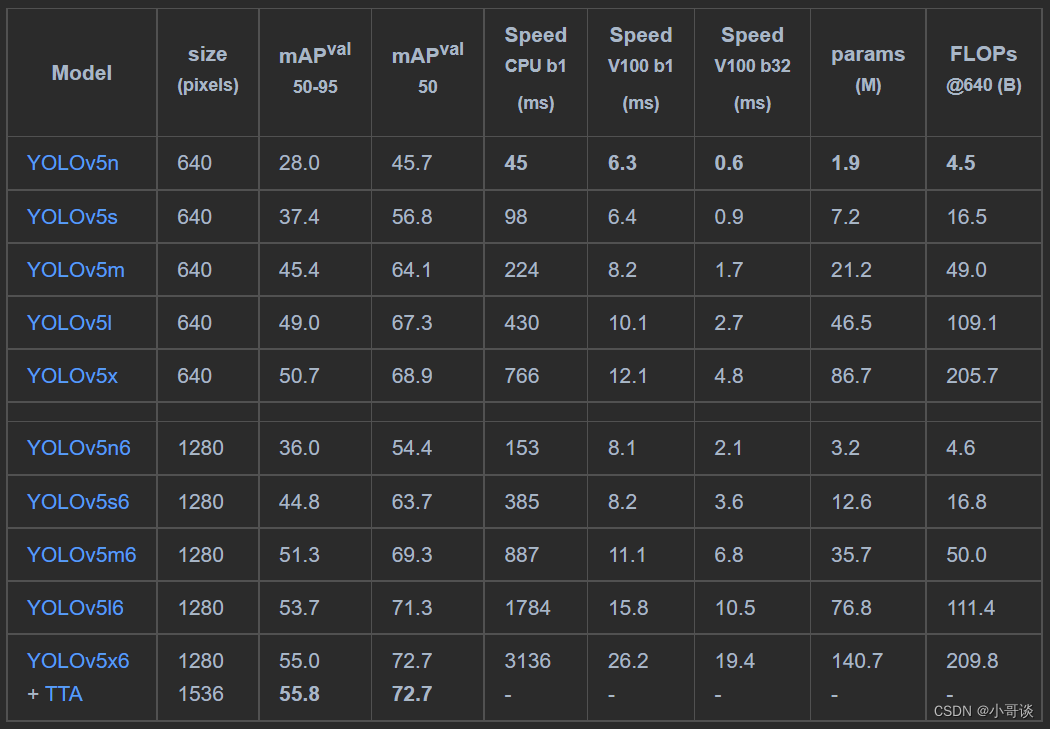
YOLOv5所提供的这些版本总的参数对比如下所示:
🚀3.源码解析
在解析之前,再次特别说明下,本次解析是基于YOLOv5-6.0版本的,该版本的yolov5.yaml文件代码如下所示: 👇
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8 该层特征图缩放为输入图像尺寸的1/8,
- [30,61, 62,45, 59,119] # P4/16 该层特征图缩放为输入图像尺寸的1/16,
- [116,90, 156,198, 373,326] # P5/32 该层特征图缩放为输入图像尺寸的1/32,
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# args:channel(输出通道数),kernel_size(卷积核大小),stride(步长),padding(填充)
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 输出通道64,实际上不是64,而是64*0.50=32
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]], # 输出通道128,实际上不是128,而是128*0.50=64
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
接下来,作者就根据上述代码进行逐行解析。
代码:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license解析:
YOLOv5是一种目标检测算法,由Ultralytics开发,采用GPL-3.0许可证。
Ultralytics公司官方网址:Ultralytics | Revolutionizing the World of Vision AI
代码:
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple解析:
Parameters:中文含义为“参数”。
nc:数据集中类别的个数,默认为80,这里指的是COCO数据集的类别数。这里采取默认即可,不改也不会报错,因为在训练的时候,我们在yaml文件中已经定义了类别数量和类别名称。训练的时候,我们所指定的yaml文件放置位置如下所示,位于train.py文件parse_opt函数中(参数设置第3行) ,即default中,下述代码中的helmet.yaml是我进行安全帽佩戴检测放置的,小伙伴们后期训练的时候自定义即可。
parser.add_argument('--data', type=str, default=ROOT / 'data/helmet.yaml', help='dataset.yaml path')关于 train.py文件parse_opt函数中各参数含义,请参考文章:
YOLOv5源码中的参数超详细解析(3)— 训练部分(train.py)| 模型训练调参
depth_multiple:控制网络深度的因子。通过调整depth_multiple的值,可以改变网络的深度,从而得到不同大小的模型。计算公式为:控制子模块数量= int(number*depth)。在yaml文件中,这是用来调整C3模块中的子模块Bottleneck重复次数的,在实际使用的时候,需要用这个深度因子乘上主干网络(backbone)C3模块的number系数,关于这里我们后面讲到主干网络的时候再详细讲述。
width_multiple:控制网络宽度的因子。在yaml文件中定义的网络结构中,每一层的通道数都会乘以width_multiple。例如,如果将width_multiple设置为0.5,则网络的通道数会减半,从而减小模型的大小和计算量,但可能会影响模型的性能。相反,如果将width_multiple设置为2,则网络的通道数会增加一倍,从而增加模型的大小和计算量,但可能会提高模型的性能。计算公式为:控制卷积核的数量= int(number*width)。
总结:♨️♨️♨️
depth_multiple和width_multiple可以用于控制模型大小和速度之间的平衡。较大的值会增加模型的大小和精度,但会增加计算量和推理时间。较小的值会减小模型的大小和精度,但会减少计算量和推理时间。
代码:
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32解析:
anchors:定义预设的锚框。anchors中包含的是k-means算法聚类得到的9个默认锚框。在yolov5s.yaml中,初始化了9个anchors,分为3组,在3个Detect层使用(3个feature map)。
分配规则:
尺度越大的 feature map 越靠前,相对原图的下采样率越小,感受野越小, 所以相对可以预测一些尺度比较小的物体(小目标),分配到的 anchors 越小。尺度越小的 feature map 越靠后,相对原图的下采样率越大,感受野越大, 所以可以预测一些尺度比较大的物体(大目标),所以分配到的 anchors 越大。即在小特征图(feature map)上检测大目标,中等大小的特征图上检测中等目标, 在大特征图上检测小目标。
所以,根据上述解释总结其作用分别是:
- [10,13, 16,30, 33,23] 作用:检测小目标
- [30,61, 62,45, 59,119] 作用:检测中目标
- [116,90, 156,198, 373,326] 作用:检测大目标
关于其对比,具体如下表所示:
| 感受野 | 大 | 中 | 小 |
| 先验框 | (116×90),(156×198),(373×326) | (30*61),(62*45),(59*119) | (10*13),(16*30),(33*23) |
另外,
- [10,13, 16,30, 33,23] # P3/8 后面的# P3/8表示该层特征图缩放为输入图像尺寸的1/8,是第3特征层。
- [30,61, 62,45, 59,119] # P4/16 后面的# P4/16表示该层特征图缩放为输入图像尺寸的1/16,是第4特征层。
- [116,90, 156,198, 373,326] # P5/32 后面的# P5/32表示该层特征图缩放为输入图像尺寸的1/32,是第5特征层。
这里的P3、P4和P5分别对应网络结构Detect的17层、20层和23层,具体代码如下所示:
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)术语定义:♨️♨️♨️
特征图:即feature map,是卷积神经网络中的一个概念,它是指在卷积层中,对输入数据进行卷积操作后得到的输出结果。每个卷积核都会产生一个feature map,而每个feature map都是一个二维矩阵,代表了输入数据中某种特定的特征。在卷积神经网络中,随着网络的加深,feature map的长宽尺寸会逐渐缩小,但是每个feature map提取的特征会越来越具有代表性。通过观察feature map的数值变化,可以了解网络的训练情况,一个训练成功的CNN网络,其feature map的值伴随网络深度的增加,会越来越稀疏,这可以理解为网络取精去燥。
感受野:感受野是指在卷积神经网络中,特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。在卷积层和池化层中,都会影响感受野,而激活函数层通常对于感受野没有影响,当前层的步长并不影响当前层的感受野,感受野和填补(padding)没有关系。公式求取的感受野通常很大,而实际的有效感受野(Effective Receptive Field)往往小于理论感受野,因为输入层中边缘点的使用次数明显比中间点要少,因此作出的贡献不同,所以经过多层的卷积堆叠后,输入层对于特征图点做出的贡献分布呈高斯分布形状。
先验框:即anchor,是目标检测算法中的一种技术,用于在图像中生成一组预定义的边界框,这些边界框具有不同的尺度和长宽比。目标检测算法会在这些先验框上进行分类和回归,以确定图像中是否存在目标物体,并且确定目标物体的位置和大小。先验框的作用是为了提高目标检测算法的准确性和效率,因为它可以减少目标检测算法对于不同尺度和长宽比的物体的检测难度。
代码:
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]解析:
backbone:即主干网络。
# [from, number, module, args]
from:表示当前模块的输入来自那一层的输出,-1表示来自上一层的输出,-2表示上两层,[-1, 4]表示取自上一层和第4层,依次类推。
备注:层数从0开始计算,比如第0层、第1层、第2层......🍉 🍓 🍑 🍈 🍌 🍐
number:表示该层模块堆叠的次数,对于C3、BottleneckCSP等模块,表示其子模块的堆叠,具体细节可以查看源代码,当然最终的次数还要乘上depth_multiple系数。
说明:♨️♨️♨️
depth_multiple即用来调整C3模块中的子模块BottleNeck重复次数的,在实际使用的时候,需要用深度因子乘上主干部分C3模块的number系数的,比如在主干网络中,第一个C3模块的
number系数是3,那么使用0.33×3向上取整就等于1了,这就代表第一个C3模块的BottleNeck只重复1次;第二个C3模块的number系数是6,那么使用0.33×6向上取整等于2,这就代表第二个C3模块的BottleNeck重复2次;同理,第三个C3模块的number系数是9,那么0.33×9向上取整就等于3了,代表第三个C3模块的BottleNeck重复3次。
module:表示该层模块的名称,这些模块写在common.py中,进行模块化的搭建网络。
args:模块搭建所需参数,指channel(输出通道数)、kernel_size(卷积核大小)、stride(步长)、padding(填充)、bias等,会在网络搭建过程中根据不同层进行改变。
注意:♨️♨️♨️
在yolov5.yaml文件中,是严格按照上述顺序来的,即channel(输出通道数)、kernel_size(卷积核大小)、stride(步长)、padding(填充)等。其实在最前面还有输入通道数,只不过本层的输入通道数即上一层的输出通道数,在yaml文件中省略了。
Conv:YOLOv5中的conv是指最基础的卷积模块,它由一个卷积层、一个批量归一化层和一个激活函数层组成。其中卷积层用于提取特征,批量归一化层用于规范化特征图,激活函数层用于增加非线性。在YOLOv5中,Conv模块还支持自动填充、分组卷积等功能,可以根据不同的需求进行灵活配置。此外,YOLOv5中的Conv模块还支持fuseforward方法,可以将卷积层和激活函数层融合在一起,提高模型的计算效率。
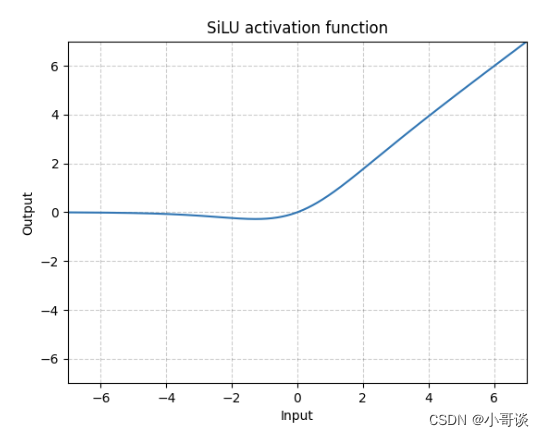
SiLU(Sigmoid Linear Unit)激活函数解析:
SiLU(Sigmoid Linear Unit)激活函数是近年来提出的一种新型激活函数,它将Sigmoid函数和ReLU函数结合起来,具有一定的优势。其公式为:
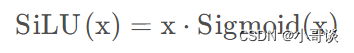
代码:
m = nn.SiLU()
input = torch.randn(2)
output = m(input)综上, Conv组成为:
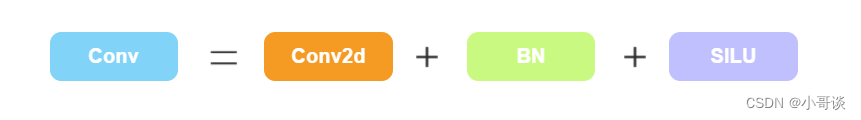
C3:其结构作用基本相同均为CSP架构,只是在修正单元的选择上有所不同,其包含了3个标准卷积层,数量由配置文件yaml的n和depth_multiple参数乘积决定。该模块是对残差特征进行学习的主要模块,其结构分为两支,一支使用了上述指定多个Bottleneck堆叠,另一支仅经过一个基本卷积模块,最后将两支进行concat操作。
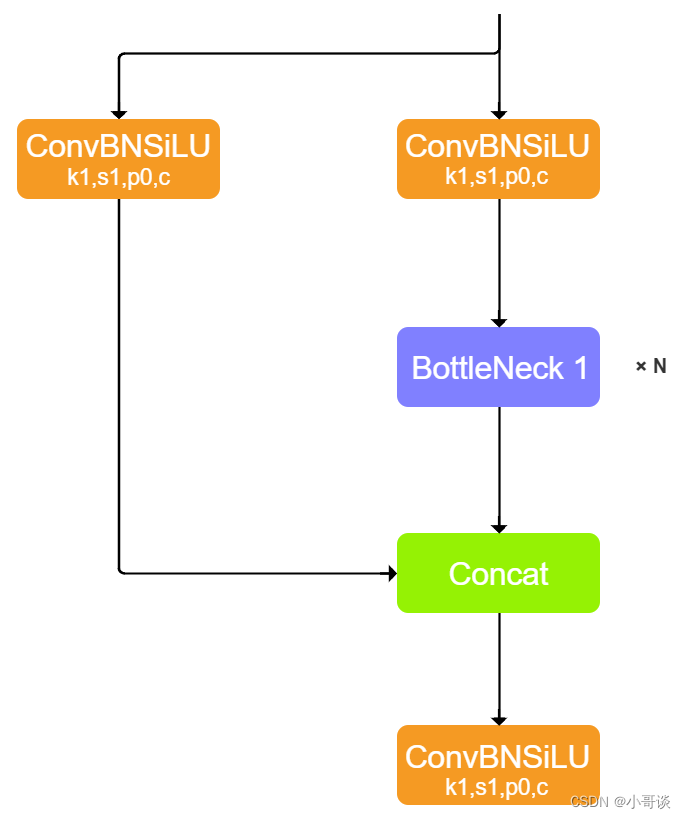
另外,C3模块中的Bottleneck借鉴了ResNet的残差结构,具体如下:
- 其中一路先进行1 ×1卷积将特征图的通道数减小一半,从而减少计算量,再通过3 ×3卷积提取特征,并且将通道数加倍,其输入与输出的通道数是不发生改变的。
- 另外一路通过shortcut进行残差连接,与第一路的输出特征图相加,从而实现特征融合。
在YOLOv5中,Backbone中的Bottleneck都默认使shortcut为True,而在Head中的Bottleneck都不使用shortcut。
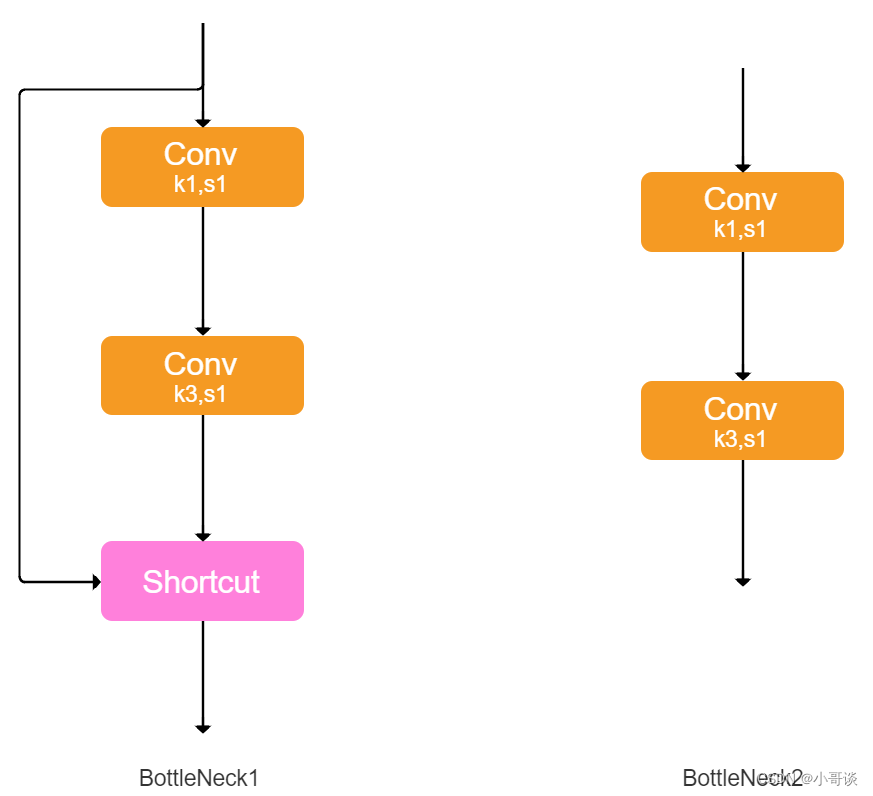
总结:♨️♨️♨️
在YOLOv5中,Backbone中的C3和Head中的C3是不相同的。Backbone中的C3的子模块为上图中Bottleneck1,为C3 True,而Head中的C3的子模块为上图中的Bottleneck2,为C3 False。
SPPF:SPPF由SPP改进而来,SPP先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的max pooling(对于不同的核大小,padding是自适应的)。对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。yolo的SPP借鉴了空间金字塔的思想,通过SPP模块实现了局部特征和全部特征。经过局部特征与全矩特征相融合后,丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,对yolo这种复杂的多目标检测的精度有很大的提升。
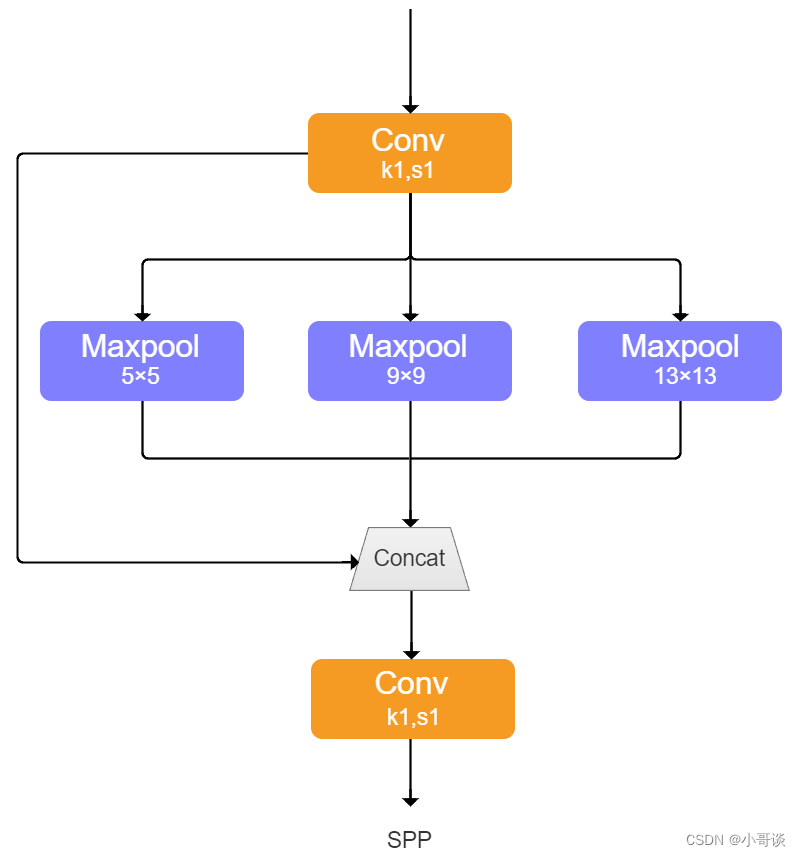
SPPF(Spatial Pyramid Pooling - Fast )使用3个5×5的最大池化,代替原来的5×5、9×9、13×13最大池化,多个小尺寸池化核级联代替SPP模块中单个大尺寸池化核,从而在保留原有功能,即融合不同感受野的特征图,丰富特征图的表达能力的情况下,进一步提高了运行速度。
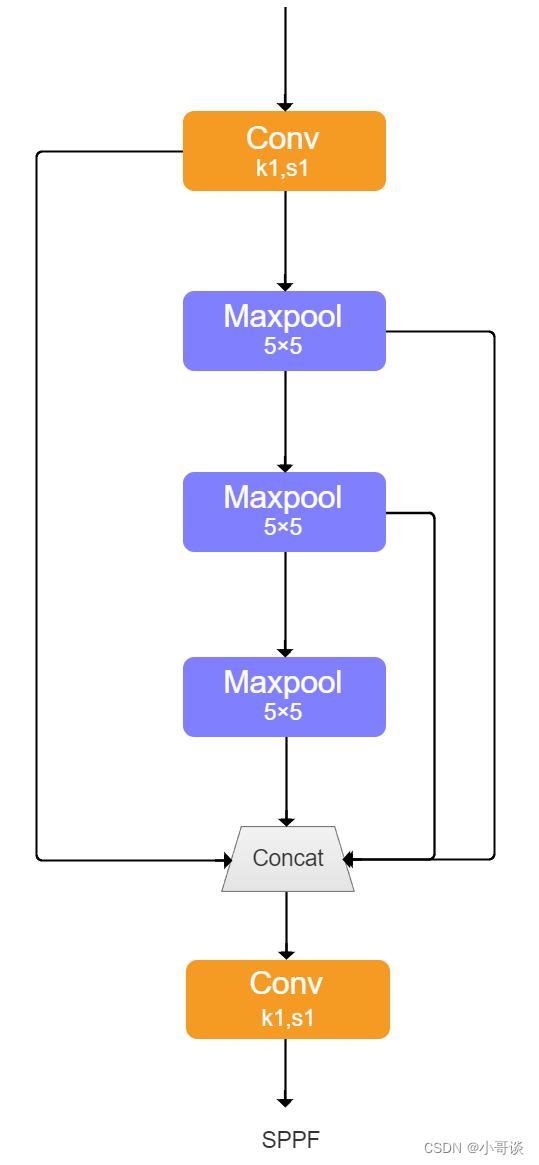
SPP和SPPF对比实验:
下面做个简单的小实验,对比下SPP和SPPF的计算结果以及速度,代码如下(注意这里将SPPF中最开始和结尾处的1x1卷积层给去掉了,只对比含有MaxPool的部分)。
代码:
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
结果:
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648
通过对比可以发现,两者的计算结果是一模一样的,但SPPF比SPP计算速度快了不止两倍。
实验参考文章:
作者:创不了浩;文章:YOLOv5 Focus C3 各模块详解及代码实现
关于上述代码各层解释如下所示:👇
- 第0层是一个卷积层,输出通道数为 64,卷积核大小为 6x6,步长为 2,填充为 2,输出特征图大小为输入的1/2。
- 第1层是一个卷积层,输出通道数为 128,卷积核大小为 3x3,步长为 2,输出特征图大小为输入的1/2。
- 第2层是一个 C3 模块,包含 3 个卷积层,每个卷积层的输出通道数为 128,卷积核大小分别为 1x1、3x3、1x1,不改变特征图大小。
- 第3层是一个卷积层,输出通道数为 256,卷积核大小为 3x3,步长为 2,输出特征图大小为输入的1/2。
- 第4层是一个 C3 模块,包含 6 个卷积层,每个卷积层的输出通道数为 256,卷积核大小分别为 1x1、3x3、1x1,不改变特征图大小。
- 第5层是一个卷积层,输出通道数为 512,卷积核大小为 3x3,步长为 2,输出特征图大小为输入的1/2。
- 第6层是一个 C3 模块,包含 9 个卷积层,每个卷积层的输出通道数为 512,卷积核大小分别为 1x1、3x3、1x1,不改变特征图大小。
- 第7层是一个卷积层,输出通道数为 1024,卷积核大小为 3x3,步长为 2,输出特征图大小为输入的1/2。
- 第8层是一个 C3 模块,包含 3 个卷积层,每个卷积层的输出通道数为 1024,卷积核大小分别为 1x1、3x3、1x1,不改变特征图大小。
- 第9层是一个 SPPF 层,具有金字塔式空间池化(Spatial Pyramid Pooling),输出通道数为 1024,使用大小为 5x5 的金字塔空间池化。
代码:
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]解析:
YOLOv5中的Head包括Neck和Detect两部分。Neck采用了FPN+PAN结构,Detect结构和YOLOV3中的Head一样。四个参数和上面 backbone 一样,这里就不再解释了。🌺
另外,Conv和C3上面已经解析,这里也不再赘述了。接下来,让我们看一下nn.Upsample、Concat。👇
注意:♨️♨️♨️
Backbone中的C3为C3 True,而Head中的C3为C3 False。在YOLOv5中,C3 True和C3 False是指不同的模块。C3 True是指使用了BottleneckCSP模块的C3模块,而C3 False是指使用了标准卷积模块的C3模块。相比于C3 False,C3 True在经历过残差输出后的Conv模块没有被去掉,同时concat后的标准卷积模块中的激活函数也由LeakyRelu变为了SiLU。这些改变使得C3 True模块在保持高精度的同时,也具有更快的训练速度和更小的模型体积。有点啰嗦了,不好意思~!
nn.Upsample:nn.Upsample是PyTorch中的一个上采样模块,用于将输入的特征图进行上采样操作,从而得到更高分辨率的特征图。它可以通过指定输出的尺寸大小或者输入尺寸的倍数来进行上采样操作,并且支持多种上采样算法,如最近邻插值、双线性插值等。需要注意的是,nn.Upsample只改变特征图的尺寸,而不改变通道数。在一些深度学习模型中,nn.Upsample被广泛应用。
注意:经过上采样后,通道数不变,而特征图加倍。
Concat:在yolov5.yaml中,Concat是指将多个特征图按照通道维度进行拼接的操作。在YOLOv5中,Concat主要用于将不同尺度的特征图进行融合,以提高检测的精度和召回率。具体来说,YOLOv5中使用了FPN(Feature Pyramid Network)结构,将不同层级的特征图进行融合,然后再进行检测。而在FPN中,就需要使用Concat将不同尺度的特征图进行拼接,以便进行下一步的处理。
Concat和Add的区分:♨️♨️♨️
Concat要求的是拼接的两个特征图的尺寸是一样的,通道可以不一样。Concat操作就是将两个特征图在通道维度上连接起来,得到一个新的特征图。如果合并前的两个feature map的通道数都是256,那么合并后的feature map的通道数就是512。而Add要求模型的通道和尺寸都相同,Add操作实际就是将两个特征图的相应像素相加,得到一个新的特征图。
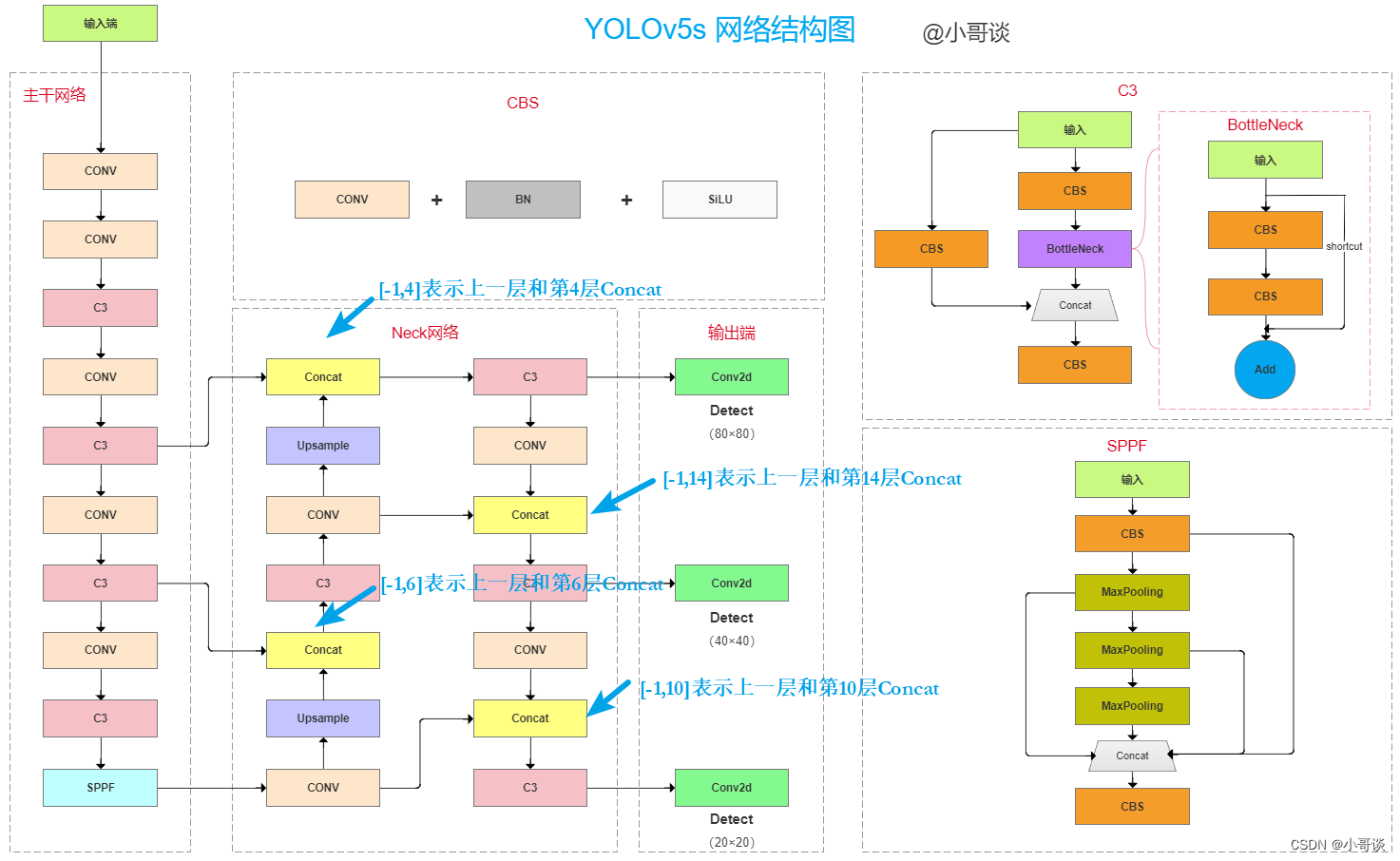
由代码可以看到,在yolov5.yaml中,具有4个Concat,最前面的“from”分别是[-1,6]、[-1,4]、[-1,14]、[-1,10],按照上面解析分别表示:
- [-1,6]: 上一层和第6层Concat
- [-1,4]: 上一层和第4层Concat
- [-1,14]:上一层和第14层Concat
- [-1,10]:上一层和第10层Concat
讲到这里,大家可能有点懵逼(哈哈~~~~😝),来,上图! 👋 👋 👋
最后,我们再分析下Detect部分。
代码:
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)解析:
这是Detect部分,由代码可知,yolov5s.yaml具有3个检测层,分别位于第17层、第20层和第23层,由上到下分别是80×80(检测小目标)、40×40(检测中目标)和20×20(检测大目标),讲到这里顺便提一下,如果想要再加一层来检测更小目标该如何做呢~?答案就是在最上面再加一层160×160(检测更小目标)呗~!!
Detect部分在图上展示如下所示:
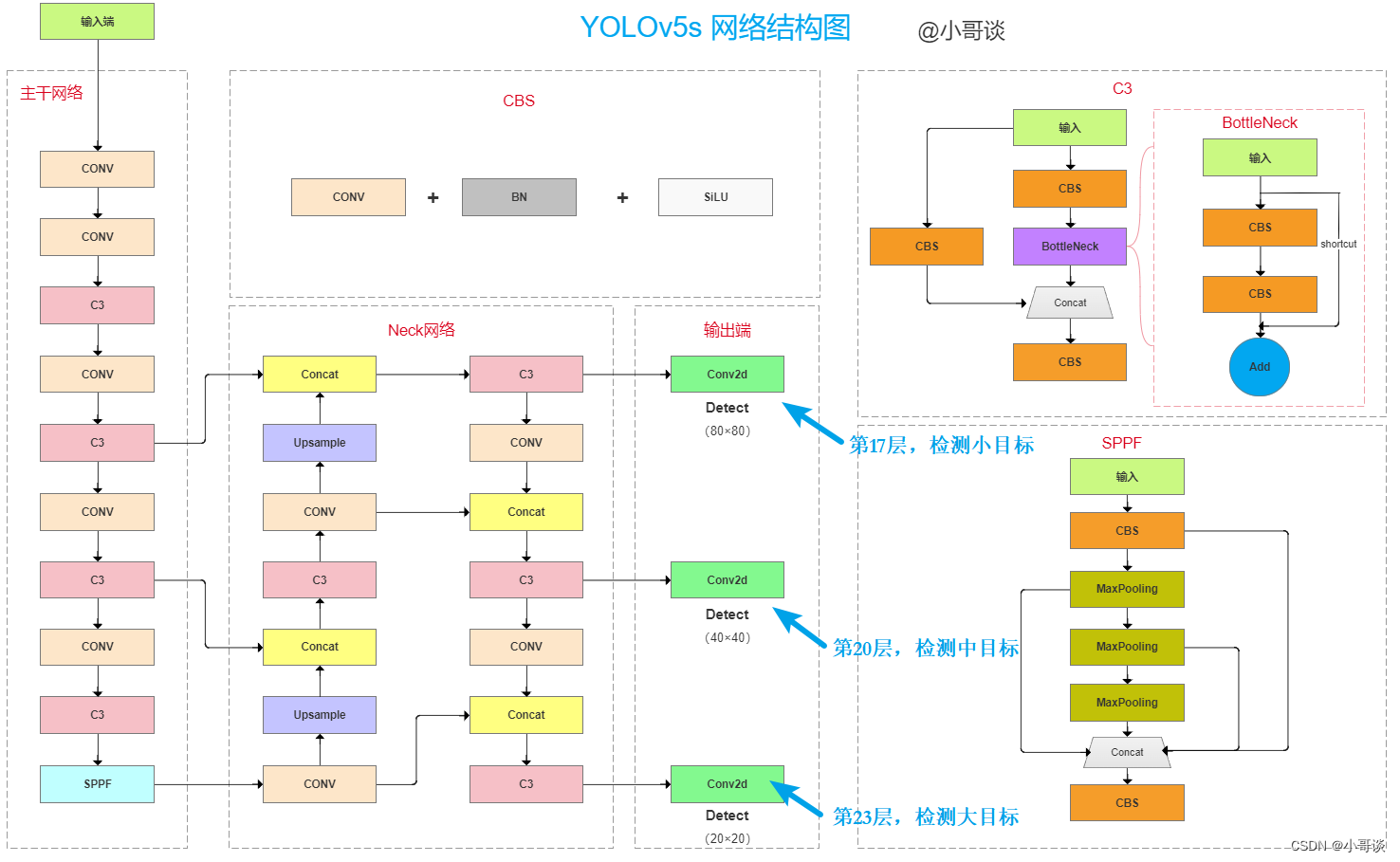
🚀4.整体解析
关于yolov5s.yaml配置文件所对应的网络结构图,可以参考下图。(本来想自己画的,但是感觉下图已经画的很完美了,我就不手绘了~!)在下图中,详细的列出了相关参数,包括模块、特征图大小变化、通道数变化等等,还是很完美的~!💞
该图也获得了作者的认可,并且评论道:very nice! Looks all correct.

具体如下所示:
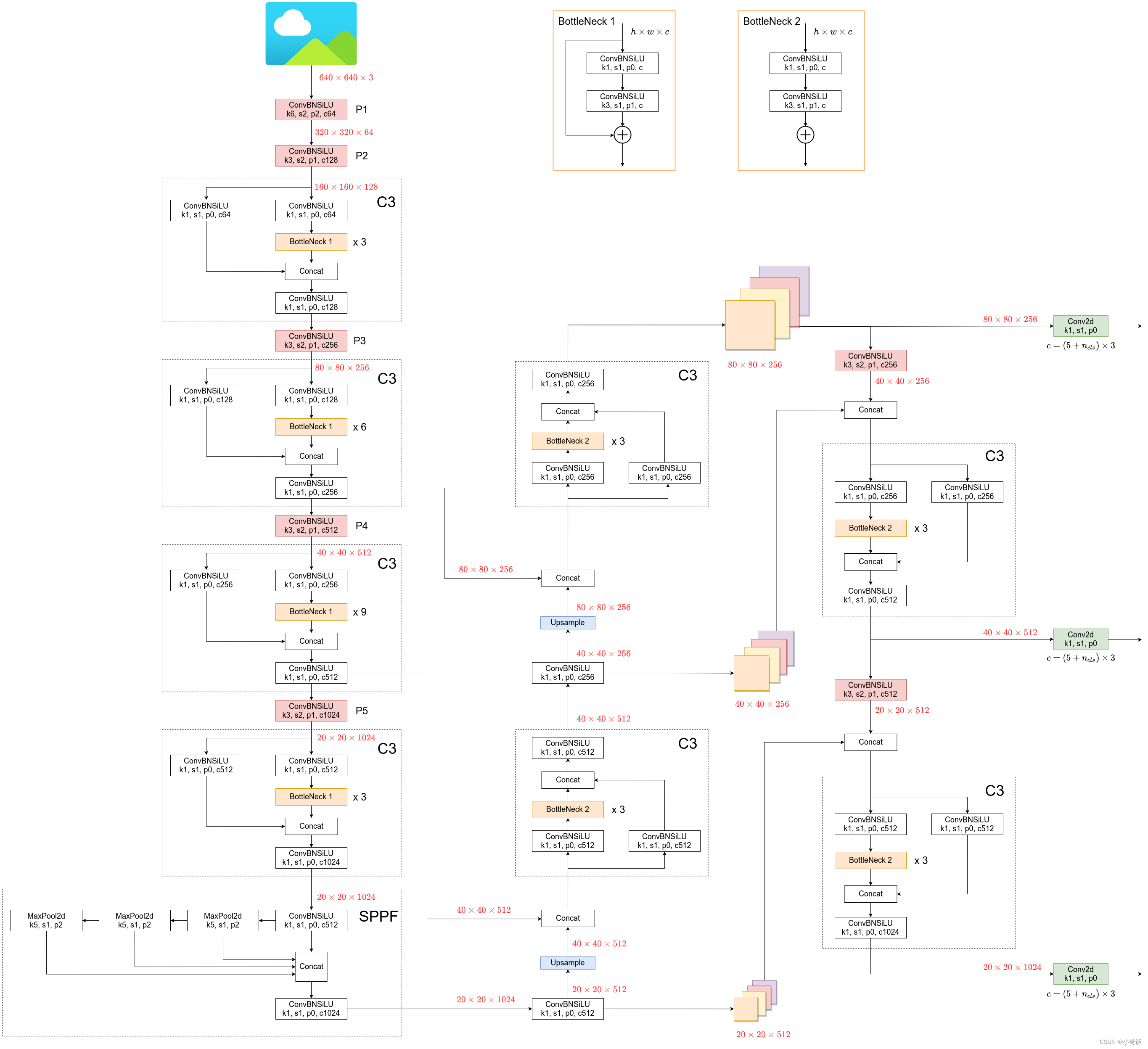
备注:♨️♨️♨️
图片来源地址:YOLOv5 6.0 Model Structure · Issue #6885 · ultralytics/yolov5 · GitHub
🚀5.作者说明
本文内容摘自专栏《YOLOv5:从入门到实战》文章:
YOLOv5源码中的参数超详细解析(2)— 配置文件yolov5s.yaml(包括源码+网络结构图)
关于YOLOv5算法之yolov5s.yaml配置文件的深度解析到这里就接近尾声了~!小伙伴们如果有任何疑问,可在评论区给出,小哥谈看到了会及时回复滴~!🍉 🍓 🍑 🍈 🍌 🍐
关于更多YOLOv5的知识,可参考专栏:YOLOv5:从入门到实战