- 创建feaderSpider项目:feapder create -p feapderSpider,已创建可忽略
- 进入feapderSpider目录:cd .\ feapderSpider\spiders
- 创建爬虫:feapder create -s airSpiderDouban,选择AirSpider爬虫模板,可跳过1、2直接创建爬虫文件
- 配置邮件报警:报警配置163邮箱,https://feapder.com/#/source_code/%E6%8A%A5%E8%AD%A6%E5%8F%8A%E7%9B%91%E6%8E%A7
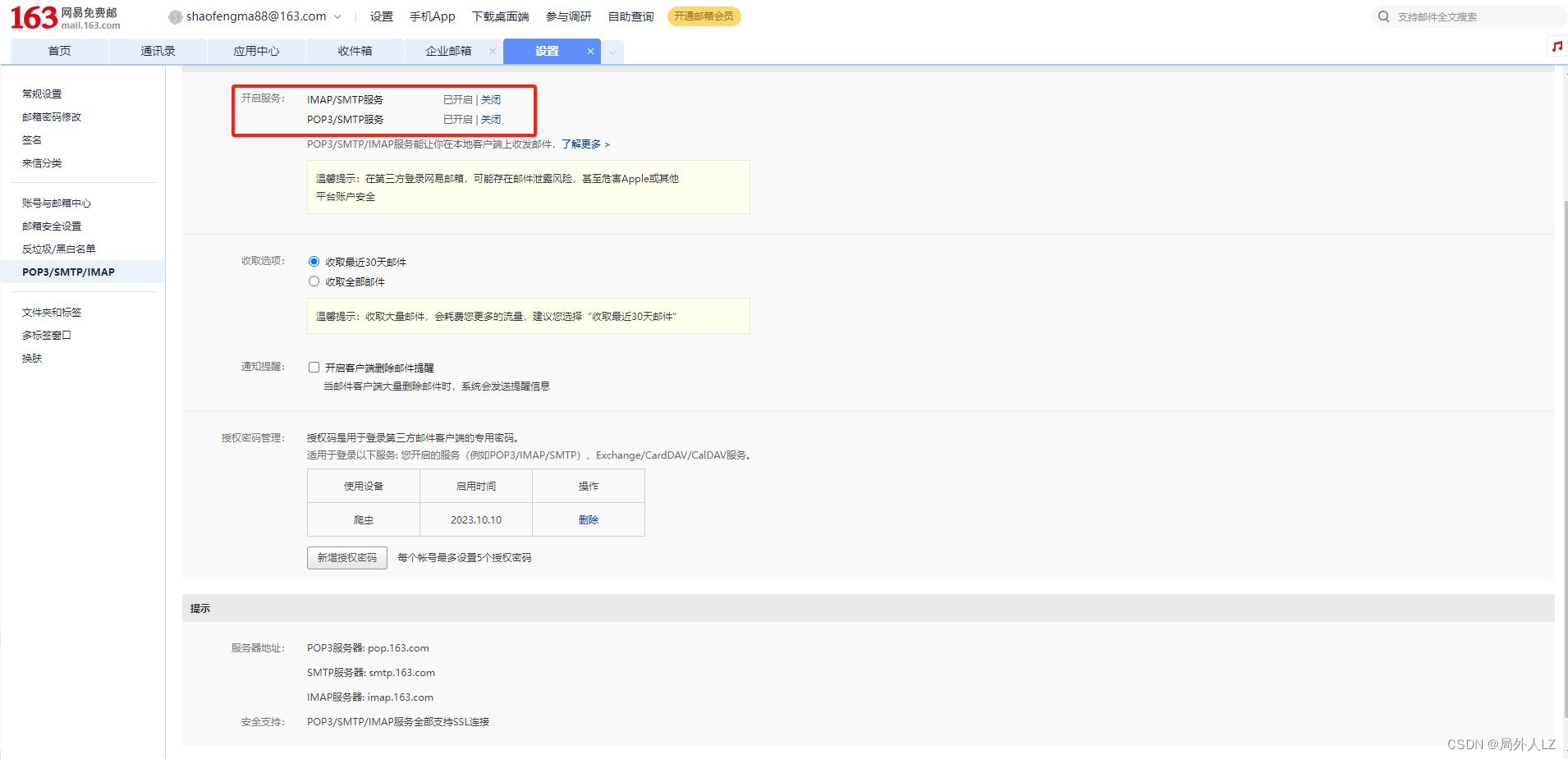
- setting.py打开mysql配置,无setting.py文件,运行命令feapder create --setting
# # MYSQL MYSQL_IP = "localhost" MYSQL_PORT = 3306 MYSQL_DB = "video" MYSQL_USER_NAME = "root" MYSQL_USER_PASS = "root" # # REDIS # # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"] REDISDB_IP_PORTS = "localhost:6379" REDISDB_USER_PASS = "" REDISDB_DB = 0 # 连接redis时携带的其他参数,如ssl=True REDISDB_KWARGS = dict() # 适用于redis哨兵模式 REDISDB_SERVICE_NAME = "" # # 去重 ITEM_FILTER_ENABLE = True # item 去重 ITEM_FILTER_SETTING = dict( filter_type=1, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4 name="douban" ) # # 邮件报警 EMAIL_SENDER = "123123123@163.com" # 发件人 EMAIL_PASSWORD = "EYNXMBWJKMLZFTKQ" # 授权码 EMAIL_RECEIVER = ["123123123@163.com"] # 收件人 支持列表,可指定多个 EMAIL_SMTPSERVER = "smtp.163.com" # 邮件服务器 默认为163邮箱 - 创建item:feapder create -i douban,选择item,需要现在数据库创建表
CREATE TABLE IF NOT EXISTS douban( id INT AUTO_INCREMENT, title VARCHAR(255), rating FLOAT, quote VARCHAR(255), intro TEXT, PRIMARY KEY(id) ) - 修改douban_item.py文件
# -*- coding: utf-8 -*- """ Created on 2023-10-08 16:17:51 --------- @summary: --------- @author: Administrator """ from feapder import Item class DoubanItem(Item): """ This class was generated by feapder command: feapder create -i douban """ __table_name__ = "douban" __unique_key__ = ["title","quote","rating","title"] # 指定去重的key为 title、quote,最后的指纹为title与quote值联合计算的md5 def __init__(self, *args, **kwargs): super().__init__(**kwargs) # self.id = None self.intro = None self.quote = None self.rating = None self.title = None - 爬虫文件:air_spider_douban.py
# -*- coding: utf-8 -*- """ Created on 2023-10-06 15:36:09 --------- @summary: --------- @author: Administrator """ import feapder from items.douban_item import DoubanItem from feapder.network.user_agent import get as get_ua from requests.exceptions import ConnectTimeout,ProxyError from feapder.utils.email_sender import EmailSender import feapder.setting as setting class AirSpiderDouban(feapder.AirSpider): def __init__(self, thread_count=None): super().__init__(thread_count) self.request_url = 'https://movie.douban.com/top250' def start_requests(self): yield feapder.Request(self.request_url) def download_midware(self, request): request.headers = { 'User-Agent': get_ua() } return request def parse(self, request, response): video_list = response.xpath('//ol[@class="grid_view"]/li') for li in video_list: item = DoubanItem() item['title'] = li.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first() item['rating'] = li.xpath('.//div[@class="bd"]//span[@class="rating_num"]/text()').extract_first() item['quote'] = li.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first() detail_url = li.xpath('.//div[@class="hd"]/a/@href').extract_first() if detail_url: yield feapder.Request(detail_url, callback=self.get_detail_info, item=item) # 获取下一页数据 next_page_url = response.xpath('//div[@class="paginator"]//link[@rel="next"]/@href').extract_first() if next_page_url: yield feapder.Request(next_page_url,callback=self.parse) def get_detail_info(self, request, response): item = request.item detail = response.xpath('//span[@class="all hidden"]/text()').extract_first() or '' if not detail: detail = response.xpath('//div[@id="link-report-intra"]/span[1]/text()').extract_first() or '' item['intro'] = detail.strip() yield item def exception_request(self, request, response, e): prox_err = [ConnectTimeout,ProxyError] if type(e) in prox_err: request.del_proxy() def end_callback(self): with EmailSender(setting.EMAIL_SENDER,setting.EMAIL_PASSWORD) as email_sender: email_sender.send(setting.EMAIL_RECEIVER, title='python',content="爬虫结束") if __name__ == "__main__": AirSpiderDouban(thread_count=5).start() - feapder create -p feapderSpider根据该命令创建的项目下会有main文件,除了单独运行爬虫文件,可以在main文件中运行,一般用于运行多个爬虫
from feapder import ArgumentParser from spiders import * def crawl_air_spider_douban(): """ AirSpider爬虫 """ spider = air_spider_douban.AirSpiderDouban() spider.start() if __name__ == "__main__": parser = ArgumentParser(description="爬虫练习") parser.add_argument( "--crawl_air_spider_douban", action="store_true", help="豆瓣AirSpide", function=crawl_air_spider_douban ) parser.run("crawl_air_spider_douban")
python爬虫之feapder.AirSpider轻量爬虫案例:豆瓣
news2026/2/12 8:44:09
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1145693.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
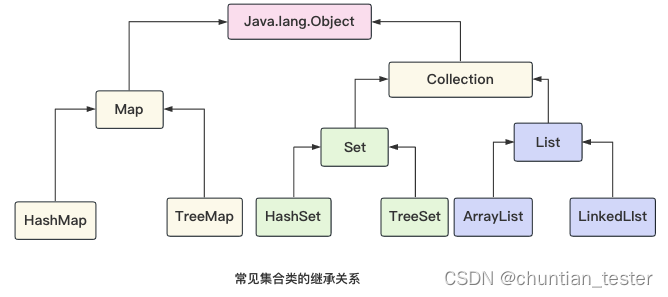
Java集合类--List集合,Set集合,Map集合
集合可以看作一个容器,Java中提供了不同的集合类,这些类具有不同的存储对象的方式,同时提供了相应的方法,以便用户对集合进行遍历、添加、删除、查找指定的对象。
1.集合类概述: 集合类类似于数组,与数组不…
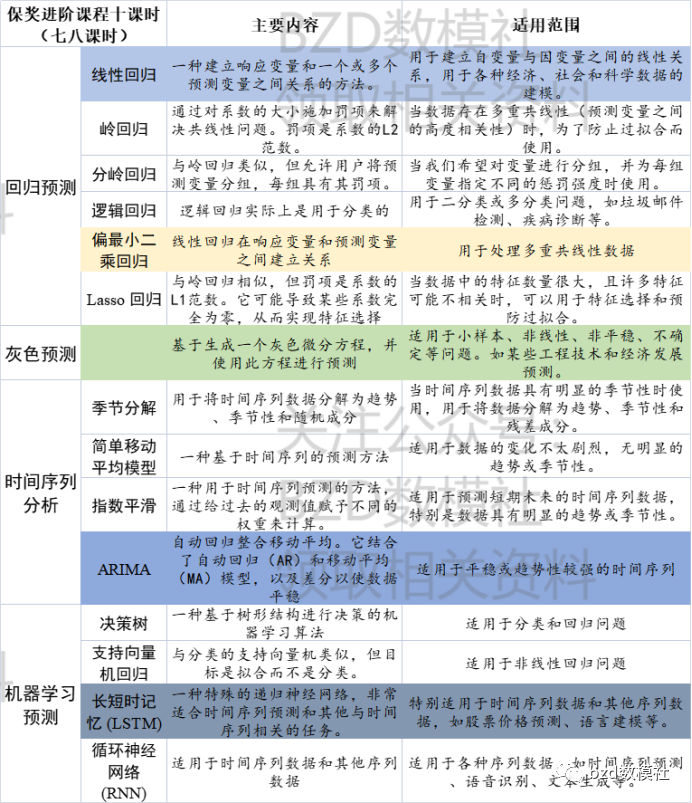
2023年第四届MathorCup高校数学建模挑战赛——大数据竞赛B题解题思路
比赛时长为期7天的妈杯大数据挑战赛如期开赛,为了帮助对B题有更深的理解,这里为大家带来B题的初步解题思路。
赛道B:电商零售商家需求预测及库存优化问题
由于妈杯竞赛分为初赛复赛,因此,对于B题大家仅仅看到了预测相…
nodejs+vue+elementui社区居民信息管理及数据分析与可视化系统设计
其中用户登录中,通过HTML访问该社区居民信息管理及数据分析与可视化系统,选择登录界面,进行登录。登录成功进入到系统,登录失败,提示用户不存在, 流入人口管理中,启动社区居民信息管理及数据分…
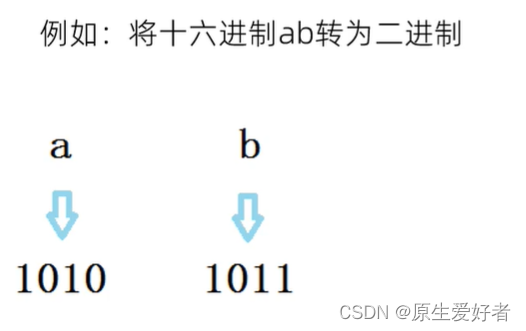
C语言二、八、十六进制转换
二进制转八进制、十六进制
二进制转八进制: 三合一法: 从低位到高位,每 3 给二进制组成 1 位八进制数据,高位不够三位用 0 填补,将二进制转为对应的八进制数即可 二进制转十六进制: 四合一法:…
基于nodejs+vue食力派网上订餐系统
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…
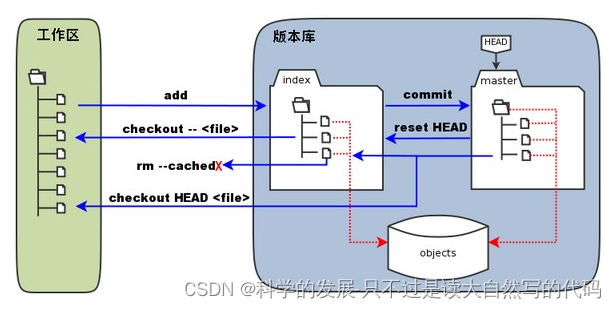
git学习笔记-发现问题如何恢复
1.概要 git总出各种问题,不清楚原因。所以准备了解的跟深入些。本来的理解是这样的:
下载我就pull
修改完就
commit然后push
怎么会有问题的,结果还总有。
既然问题无法避免,那就提高解决问题和恢复问题的能力。如果问题能够恢复就没有什…

lesson2(补充)取地址及const取地址操作符重载
个人主页:Lei宝啊
愿所有美好如期而遇 以下两个默认成员函数一般不用重新定义 ,编译器默认会生成。 #include <iostream>
using namespace std;class Date
{public:Date():_year(2023),_month(10),_day(28){}Date* operator&(){return this…
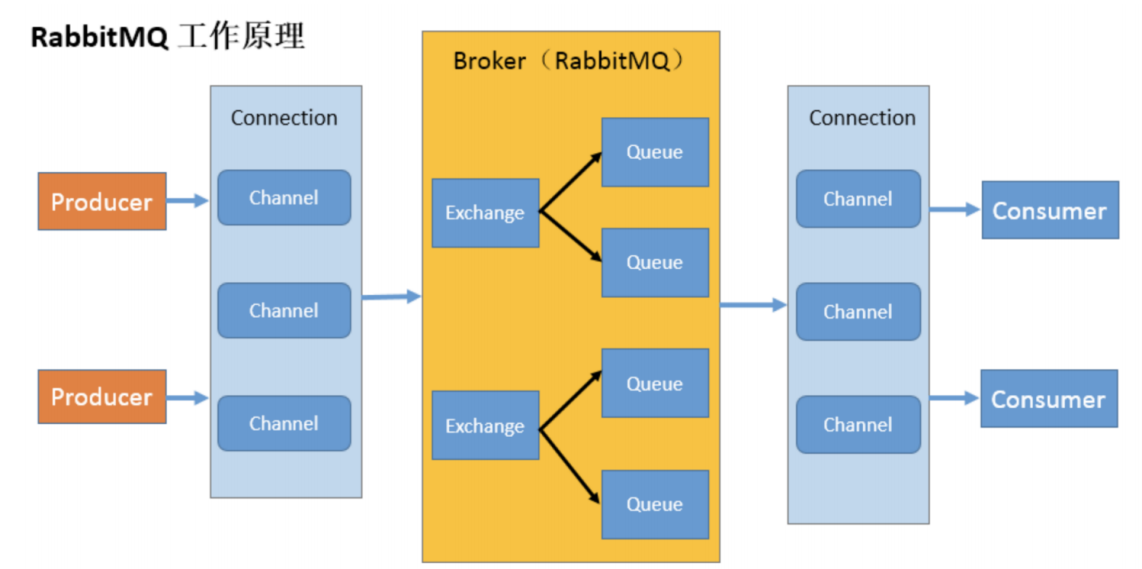
RabbitMQ学习01
四大核心概念
生产者
产生数据发送消息的程序是生产者
交换机
交换机是 RabbitMQ 非常重要的一个部件,一方面它接收来自生产者的消息,另一方面它将消息推送到队列中。交换机必须确切知道如何处理它接收到的消息,是将这些消息推送到特定队…

内网穿透工具之NATAPP(一)
使用工具前,有必要了解一下什么是内网穿透吧! 内网穿透简单来说就是将内网外网通过natapp隧道打通,让内网的数据让外网可以获取。比如常用的办公室软件等,一般在办公室或家里,通过拨号上网,这样办公软件只有在本地的局…

MySQL 字符集与乱码与collation设置的问题?
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友…
《HelloGitHub》第 91 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、…
![NSS [UUCTF 2022 新生赛]websign](https://img-blog.csdnimg.cn/img_convert/3341430f22b50164d2e002ef001886ba.png)
NSS [UUCTF 2022 新生赛]websign
NSS [UUCTF 2022 新生赛]websign
开题就给了提示 ban了F12,鼠标右键,CtrlU
可以用view-source: 别人的思路:ctrls下载页面,notepad打开
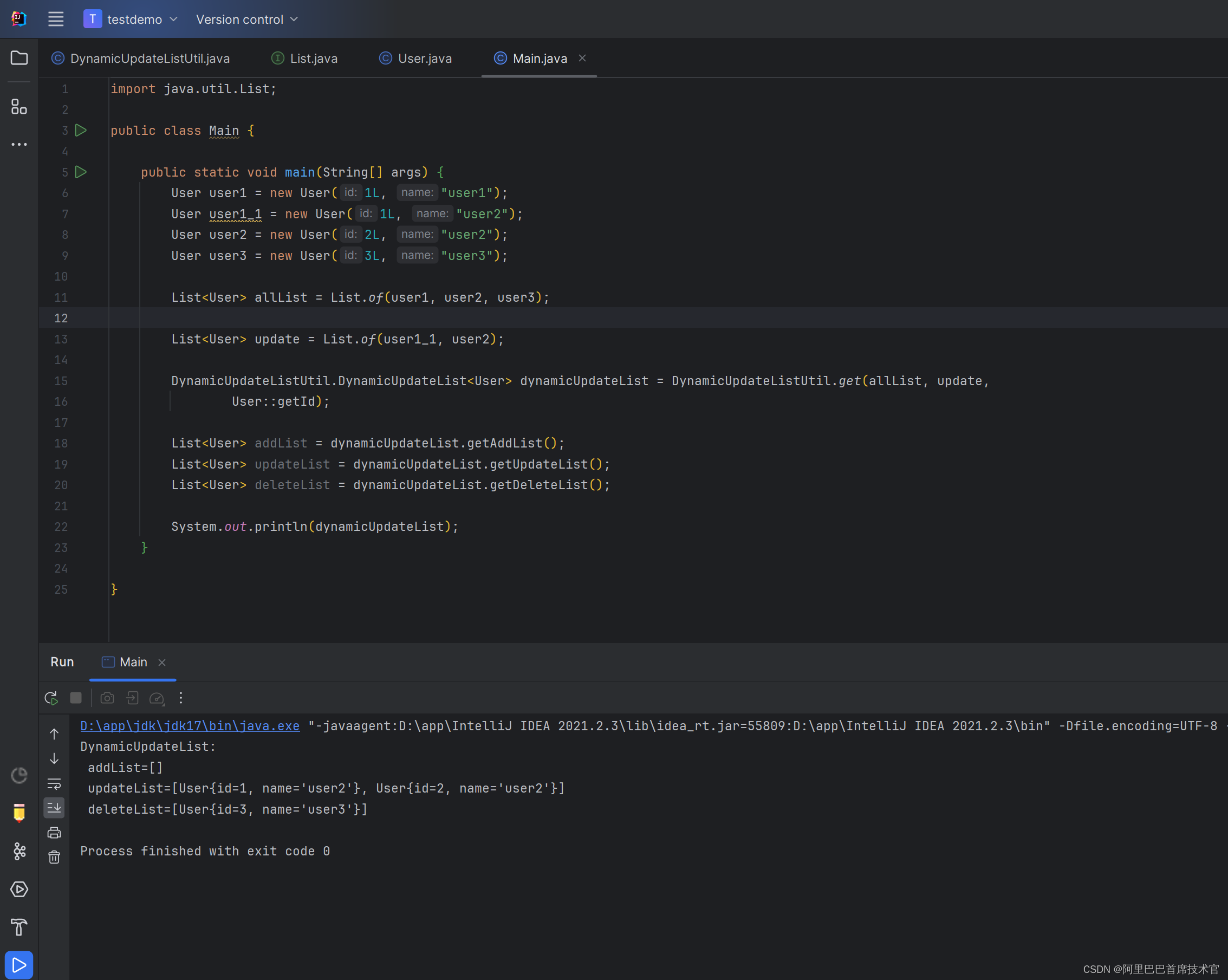
Java 工具类 列表动态维护
原本需求:一个二级 list 更新功能。
常规实现:先删除原来的全部数据,再重新插入,这样就很耗时了,所以这里写一个工具类出来。
1. 如果有新增的数据:仅对这些数据新增
2. 如果有删除的数据:仅…

【C++】STL容器——探究List与Vector在使用sort函数排序的区别(14)
前言 大家好吖,欢迎来到 YY 滴C系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! 目录 一、Sort函数介绍1.Sort函数接口2.Sort…
![[动态规划] (一) LeetCode 1137.第N个泰波那契数](https://img-blog.csdnimg.cn/img_convert/5a82e2bb09145e8ed83c3ae14771c6fa.png)
[动态规划] (一) LeetCode 1137.第N个泰波那契数
[动态规划] (一) LeetCode 1137.第N个泰波那契数 文章目录 [动态规划] (一) LeetCode 1137.第N个泰波那契数题目解析解题思路状态表示状态转移方程初始化和填表顺序返回值 代码实现总结空间优化代码实现 总结 1137. 第 N 个泰波那契数 题目解析 解题思路
状态表示
(1) 题目要…
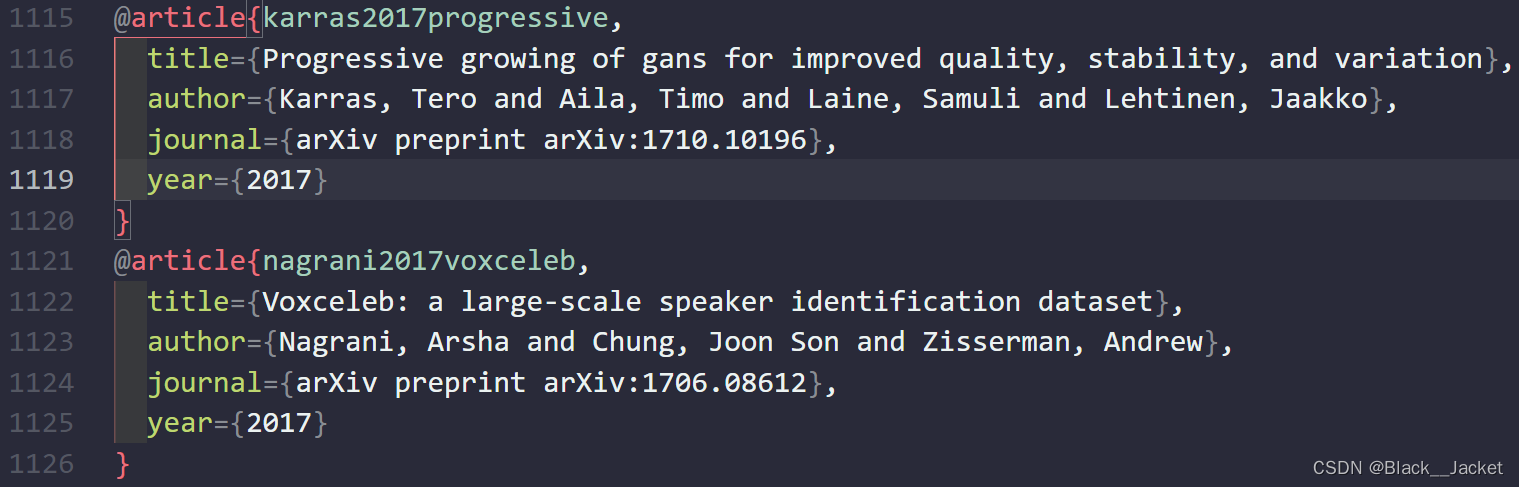
【菜菜研科研小BUG记录】【Latex写作方面1】不定期更新
Latex写作方面:
项目相关背景:
(1)VscodeTexlive环境,bib文件出现报错 (2)bib报错出现引文重复现象,这个要通过二分法查找重复的引文位置,比较麻烦,比较难找…

linux常用基本命令大全的使用(三)
🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页石马农青衿 🌄每日一句:努力一点,优秀一点 📑前言
本文主要是linux常用基本命令面试篇文章,如果有什么…

【vue3】样式穿透、完整新特性、动态css、css-module
一、样式穿透
vue2里面使用 /deep/ vue3里面使用 :deep() :deep(.el-input__inner){background-color: red;
}二、完整新特性
:slotted() //parent.vue
<template><div><p>这是父级</p><span></span><A><p class"red"…