笔者在上篇博客书写了一个名为:链式存储之:链表的引出及其简介原文链接为:https://blog.csdn.net/weixin_64308540/article/details/128374876?spm=1001.2014.3001.5501
对于此篇博客,在一写出来,便引起了巨大反响!!那么后续来了!!今日,笔者来带领大家走进:无头单向非循环链表的实现(面试笔试经常用到)
我们来看一下实现的主要代码:
总体的方法:
//头插法
public void addFirst(int data) {
}
//尾插法
public void addLast(int data){
}
//任意位置插入,(第一个数据节点为0下标)
public void addIndex(int index ,int data) {
}
//查找是否包含关键字key在链表当中
public boolean contains(int key) {
return false;
}
//删除第一次出现关键字为key的节点
public void remove(int key){
}
//删除所有值为key的节点
public void removeAllkey(int key){
}
//得到单链表的长度
public int size(){
return -1;
}
//清空
public void clear(){
}
//打印
public void display(){
}对于上述的各种方法,可能就会有不少的老铁感到犯浑了,一脸懵逼,那么接下来我们就主要来实现他们一下!!
准备性的工作:
public class MySingleList {
static class ListNode{ //静态内部类
public int val; //存储数据
public ListNode next; //存储下一个节点的地址
//构建方法!没有next,
// 主要还是在于刚new对象的时候,不知道下一个节点的地址!!
public ListNode(int val) {
this.val = val;
}
public ListNode head; //代表当前链表的头节点的引用
//不带头的非循环的单链表,最大的问题就是怎么知道头节点在哪儿??
//手动创建节点
public void creatLink(){
ListNode listNode1 = new ListNode(12);
ListNode listNode2 = new ListNode(23);
ListNode listNode3 = new ListNode(34);
ListNode listNode4 = new ListNode(45);
listNode1.next=listNode2;
listNode2.next=listNode3;
listNode3.next=listNode4;
//listNode4所对应的next默认为空null
//确定头节点
head=listNode1;
}
}
}
对于上述的代码,我们来进行小小的解析一下吧!!
首先,我们创建了一个内部类,而且还是一个静态内部类哟!!原因在于:我们写成内部类是把节点看成链表的一部分,当然,我们单独写成一个类也可以!!在我们这个写的情况下:脱离了链表,内部类ListNode没有任何意义,因为链表是由一个一个的节点组成的!!其次,我们使用了static(静态),主要是想将ListNode这个内部类,不需要依靠MySingleList这个外部类都可以单独实现!!

经过上述代码的实现,我们可以进行后续的真正压轴的环节了!!
进入正题
遍历链表
对于遍历链表,虽然很简单,但是,经过思考,有着一下几个小小的疑问:
head怎么往后走??head=head.next; 当我们打印完以后,head将会指向最后一个节点!这不是我们想要的!!
循环结束的条件是什么??(1)head != null ?? (2)还是head.next !=null ??
//遍历数组
public void display(){
//重新定义一个头节点,使其等于head节点!
ListNode cur = head;
while (cur != null){
System.out.print(cur.val+" ");
cur=cur.next;
}
//换行
System.out.println();
}对于:head != null ?? 我们可以看出来:打印全部的链表!head.next !=null 则是:链表的最后一个不能打印 !!
因此,我们有着一下的总结:
如果说,把整个链表遍历完成,就需要head==null;
如果说,遍历到链表的尾巴(最后一个),则head.next == null;
对于ListNode cur = head;这个部分,我们可以理解为:滴滴代跑!!确定头节点不会随着链表的遍历而发生改变!!
从指定位置开始遍历数组
经过上述的遍历数组的过程,我们是不是可以想一下:从指定位置开始遍历数组呀??那么请看笔者的代码吧!!其实大致上的代码还是一样的!!
//从指定位置开始遍历数组
public void display(ListNode newHead){
ListNode cur = newHead;
while (cur != null){
System.out.print(cur.val+" ");
cur=cur.next;
}
//换行
System.out.println();
}仅仅经过代码的改写一下就可以了!没有技术含量,笔者在此就不再进行讲解啦哈!!
查找链表当中是否包含关键字key??
在这个过程中,我们仍然需要遍历一遍链表才可以,若是key在链表当中,当遍历到哪儿的时候直接return true 就可以了,若是没有,则返回false!
下面就进行一下代码的书写吧!
//查找链表当中是否包含关键字key
public boolean contains(int key){
ListNode cur = head;
while (cur != null){
if (cur.val == key){
return true;
}
cur=cur.next;
}
return false;
}那么,我们来进行简单的讲解一下吧!
当cur == null的时候,所有的节点都已经判断完了
当代码的循环条件写为cur.next == null的时候,则链表的最后一个节点不能进行比较!!
在循环中,if语句中,cur.val == key,用了“==“来进行比较,主要还是在刚定义的时候,val,key都为int类型!!否则,就使用equals来进行比较了(返回值类型为boolean)
上述的代码讲解完毕了,我们开始进行下面的:
得到单链表的长度
不管怎么样进行得到单链表的长度,我们都必须进行遍历一遍链表!所以时间复杂度为O(N)
在遍历链表的时候,我们可以用一个计算器count来进行统计链表的长度!!
请看代码:
//得到单链表的长度
public int size(){
int count=0;
ListNode cur =head;
while (cur != null){
count++;
cur=cur.next;
}
return count;
}对于该段代码没有什么好解释的哈!
头插法
对于头插法,顾名思义就是:给你一个新的节点,你将这个节点插入在该链表的头部!!那么,我们需要想一想;更改些什么数据才能插入想要的数据呢??
因此:有着下面的简单代码:
//头插法 时间复杂度为O(1)
public void addFirst (int data){
ListNode listNode = new ListNode(data);
listNode.next = head;
head=listNode;
}那么,对于上述的头插法的简单代码,笔者便来简单解释一下吧!!
得有一个想要节点!!不用管里面存储的数据是多少!!
因此,我们通过代码:来创建了一个节点:新创建的节点next的值为null 原因在于:只是实列化了一个节点,我们并不知道下一个节点是谁!!
ListNode listNode = new ListNode(data);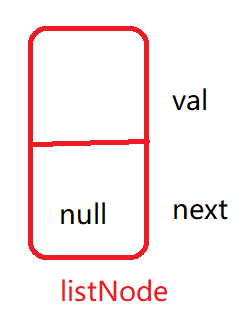
因此,我们只需要将上述的节点,与原来的链表的头节点进行简单的更改数据即可!!
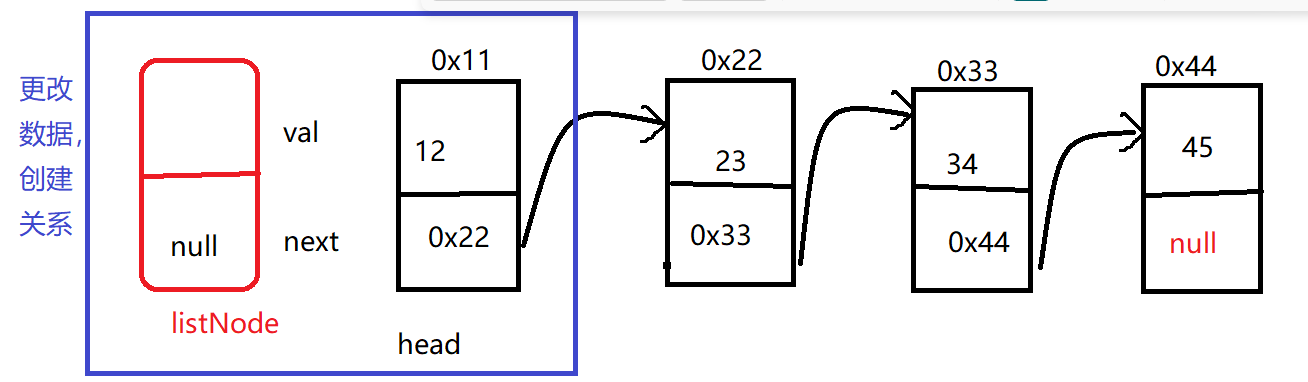
在上述的分析过程中,既然有了想法,那么我们便可以通过……
listNode.next = head;
head=listNode;将链表进行头节点的插入!

在这个过程中,我们需要注意的是:在链表里面的插入,一定要先绑后面!!
尾插法
在上个案列中,我们讲述了头插法,但是对于尾插法!不知道屏幕前的各位老铁有何指教呢??
其实对于尾插法!也是很简单!主要还是在于:找到该链表的尾巴!!但是,需要判断原来链表是否为null,就连链表的空间都不用判断!!相对于顺序表,显得简单多了!!
因此,我们有着下列的简单代码:
//尾插法 时间复杂度为O(N) 找到链表的尾巴!
//把一个节点插入到一个链表的最后
public void addLast(int data){
ListNode listNode = new ListNode(data);
if (head == null){
head = listNode;
return;
}
ListNode cur = head;
while (cur.next != null){
cur=cur.next;
}
cur.next = listNode;//插入时候所需的代码!
}在上述代码中;如果链表中一个节点都没有??此时if(head == null)成立 ,我们就不用进行插入了!!毕竟没啥用了也!!直接将要插入的节点当作头节点进行返回就行了!!但是,这儿的return 是一定要写的!!如果不写,就会继续往下走!!写上return是指:直接结束!!
定义一个新的节点cur !相当于滴滴代跑!使得头节点保存不变!在while循环中,进行找链表的尾巴节点!!当找到后,进行插入所需要的代码就先了!!
总结一下:链表的插入!仅仅是修改了部分数据的指向!!
任意位置插入?
前提:第一个数据节点当作0号下标(数组的下标)
我们在上述的两个案列当中,讲述了:头插法,尾插法,那么,现在让我们来深入进行一下:在任意位置进行插入节点!
对于该案列,我们要有着一下简单的思考:
是否需要检查想要插入的位置是否合法??(范围)
//检查想要插入的位置是否合法??
private void checkIndex(int index)throws ListIndexOutOfExpection{
if ( index < 0 || index > size()){
throw new ListIndexOutOfExpection("index位置不合法");
}
}头插法??(当想要插入的位置为0时)
//头插法??
if (index == 0){
addFirst(data);
return;
}尾插法??(当想要插入的位置等于原链表的长度的时候)
//尾插法??
if (index == size()){
addLast(data);
return;
}我们是要找到想要插入的位置的节点??还是要找到想要插入位置的前一个节点呢??
//找到index-1位置的节点的地址
private ListNode findIndexSubOne(int index){
ListNode cur =head;
int count =0;
while (count != index-1){
cur = cur.next;
count++;
}
return cur;
}对于该案列,笔者仅仅有着上述的4点猜想,当然,有这4种猜想也够了!!
对于实现该案列的总体代码为:
//在任意位置插入(第一个数据节点为0号下标)
public void addIndex(int index , int data )
throws ListIndexOutOfExpection{
//检查想要插入的位置是否合法??
checkIndex(index);
//头插法??
if (index == 0){
addFirst(data);
return;
}
//尾插法??
if (index == size()){
addLast(data);
return;
}
//找到想要插入位置的前一个节点!
ListNode cur = findIndexSubOne(index);
ListNode listNode = new ListNode(data);
//先捆绑后面
listNode.next=cur.next;
cur.next=listNode;
}
//检查想要插入的位置是否合法??
private void checkIndex(int index)throws ListIndexOutOfExpection{
if ( index < 0 || index > size()){
throw new ListIndexOutOfExpection("index位置不合法");
}
}
//找到index-1位置的节点的地址
private ListNode findIndexSubOne(int index){
//走index-1步,然后返回所对应的节点的地址
ListNode cur =head;
int count =0;
while (count != index-1){
cur = cur.next;
count++;
}
return cur;
}
当然,笔者还创建了一个名为:ListIndexOutOfExpection.java 的类!!主要是用来抛出警告!!
public class ListIndexOutOfExpection extends RuntimeException{
public ListIndexOutOfExpection() {
}
public ListIndexOutOfExpection(String message) {
super(message);
}
}对于上述代码的总体思路为:

删除第一次出现关键字为key的节点?
对于这个案列,我们有着一下的想法:
原链表当作是否一个节点都没有??即head==null是否成立?
判断头节点是否为对应的key??
找到关键字key的前一个节点!!
下面请看笔者的代码吧!
//删除第一次出现关键字为key的节点 时间复杂度为O(N)
public void remove(int key){
if (head == null){
return;
//此时,一个节点都没有!
}
//判断头节点是否为对应的key
if (head.val == key){
head =head.next;
return;
}
//searchPrev找到关键字key的前一个节点
ListNode cur = searchPrev(key);
if (cur == null){
return;
}
//dele为要删除的节点
ListNode dele = cur.next;
cur.next=dele.next;
}
//找到关键字key的前一个节点!
private ListNode searchPrev(int key){
ListNode cur =head; //这样操作的前提为head不为null
while (cur.next != null){
if (cur.next.val == key){
return cur; //此时cur时key的前一个节点
}
cur =cur.next;
}
return null;
//此时,没有要删除的节点!
}对应该案列代码的总体过程为:
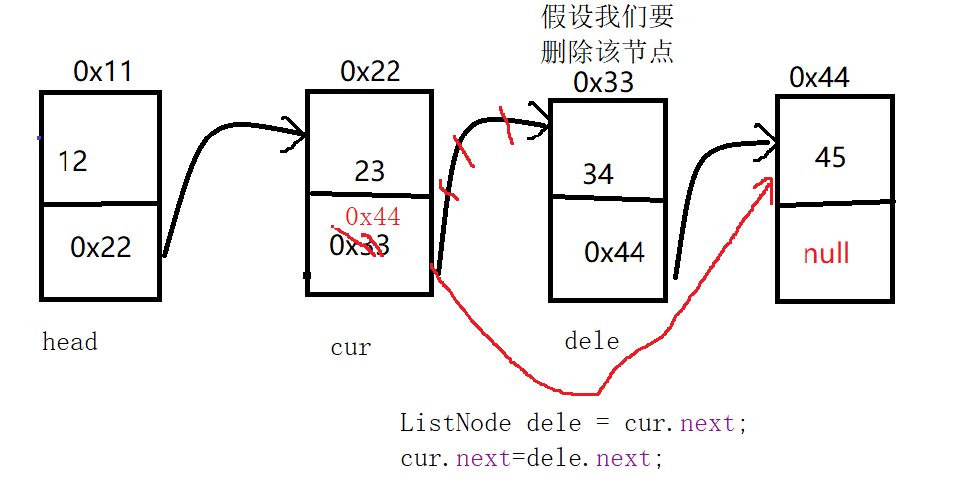
删除所有值为key的节点??
要求:遍历一遍就能全部都删除掉!!
经过上述几个案列的分析,能够坚持阅读下去的你!是否已经收获满满呢??自信满满呢??那么,这次便来个压轴的吧!!
下面请看笔者的代码:
//删除所有值为key的节点
//要求:遍历一遍就都删除了!
public void removeAllKey(int key){
if (head == null ){
return;
}
ListNode prev =head;
ListNode cur =head.next;
while (cur != null){
if (cur.val == key){
prev.next=cur.next;
cur=cur.next;
}else {
prev=cur;
cur=cur.next;
}
}
if (head.val ==key){
head=head.next;
}
}对于该段代码,由于文本+笔者发热头疼的原因,打算偷懒会!!嘘嘘,千万不要往外说!
对于该段代码看不懂的读者,请私聊笔者哟!!当作个悬念吧!!
回收链表
要求:保证所有的节点都被回收!!
其实一开始,感觉还是是挺蛮烦的!但是细细想来!每个节点都是由一个存储当前的数据,及其下一个节点的地址组成的!!如果将第一个节点给置为null,那么不就找不到第二个节点在哪儿了吗??同样也就被回收了!!
经过上述的分析,因此,有着下列的代码:
//链表回收
public void clear(){
head=null;
}当头节点被回收了(置为null),后续的阶段的就没有引用的了,从而也会都被回收的!!