distinct与group by 去重
- distinct 特点:
- group by 特点:
- 总结:
mysql中常用去重复数据的方法是使用 distinct 或者group by ,以上2种均能实现,但也有不同的地方。
distinct 特点:
1、distinct 只能放在查询字段的最前面,不能放在查询字段的中间或者后面。
备注:SELECT user_name,DISTINCT nick_name FROM sys_user_copy1 这种写法是错误的,distinct 只能写在所有查询字段的前面
2、distinct 对后面所有的字段均起作用,即 去重是查询的所有字段完全重复的数据,而不是只对 distinct 后面连接的单个字段重复的数据。
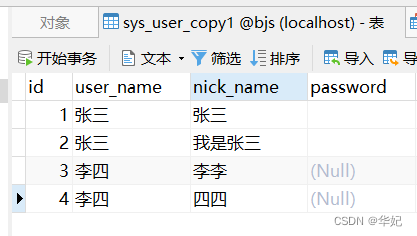
备注:也就是 distinct 关键字对 user_name, nick_name都起作用,去重姓名、昵称完全一样的用户,如果姓名相同、昵称不同是不会去重的。
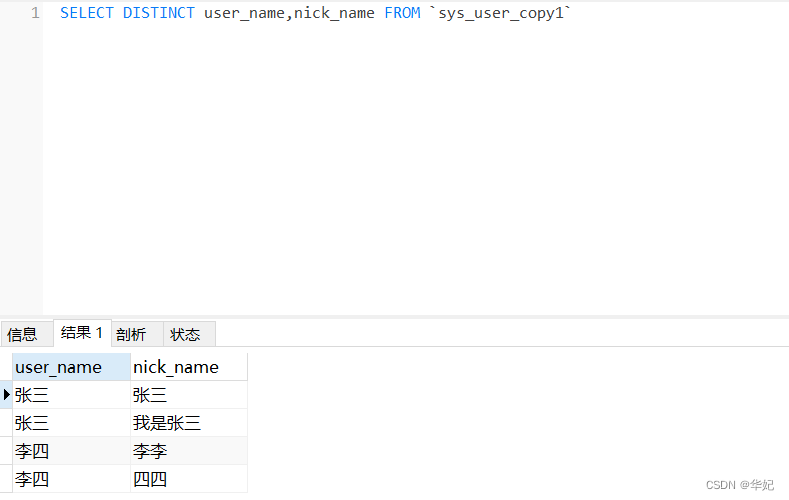
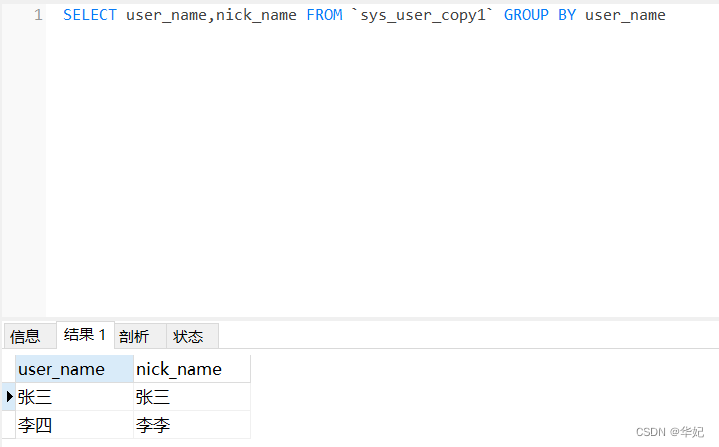
3、要查询多个字段,但只针对一个字段去重,使用distinct去重的话是无法实现的。
group by 特点:
1、一般与聚类函数使用(如count()/sum()等),也可单独使用。
2、group by 也对后面所有的字段均起作用,即 去重是查询的所有字段完全重复的数据,而不是只对 group by后面连接的单个字段重复的数据。

3、查询的字段与group by 后面分组的字段没有限制。
当对一个字段进行分组,可能会有多条数据时,会取第一条数据。
总结:
- distinct简单来说就是用来去重的,而group by的设计目的则是用来聚合统计。
- 单纯的去重操作使用distinct,速度是快于group by的。
- distinct 是针对要查询的全部字段去重,而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。
- 两者执行方式不同,distinct主要是对数据两两进行比较,需要遍历整个表。group by分组类似先建立索引再查索引,当数据量较大时,group by速度要优于distinct。