❤️ 个人主页:水滴技术
🚀 支持水滴:点赞👍 + 收藏⭐ + 留言💬
🌸 订阅专栏:大数据核心技术从入门到精通
文章目录
- 一、Elasticsearch 版本的选择
- 二、下载 **Elasticsearch**
- 三、安装 Elasticsearch
- 四、配置 Elasticsearch
- 1. 集群名称
- 2. 节点名称
- 3. 数据存储路径
- 4. 日志存储路径
- 5. 网络主机
- 6. HTTP 端口
- 7. 节点间通信端口
- 8. 集群与发现
- 9. JVM 堆大小
- 五、运行 Elasticsearch
- 热门专栏
大家好,我是水滴~~
从现在开始,我们一起学习 Elasticsearch 的核心技术。
一、Elasticsearch 版本的选择
Elasticsearch 的版本更新很快,目前已经更新到了 8.5 版。选择版本时也不能一味地求新,还要看其他框架或组件的支持情况,比如:IK 分词器、Spring Boot 等。

目前 Spring Boot 3.0 是能够支持 Elasticsearch 8.5 版本的,但由于 Spring Boot 3.0 是基于 Java 17,而绝大部分企业还是基于 Java 8 的,所以我们选择 Elasticsearch 3.17 版。
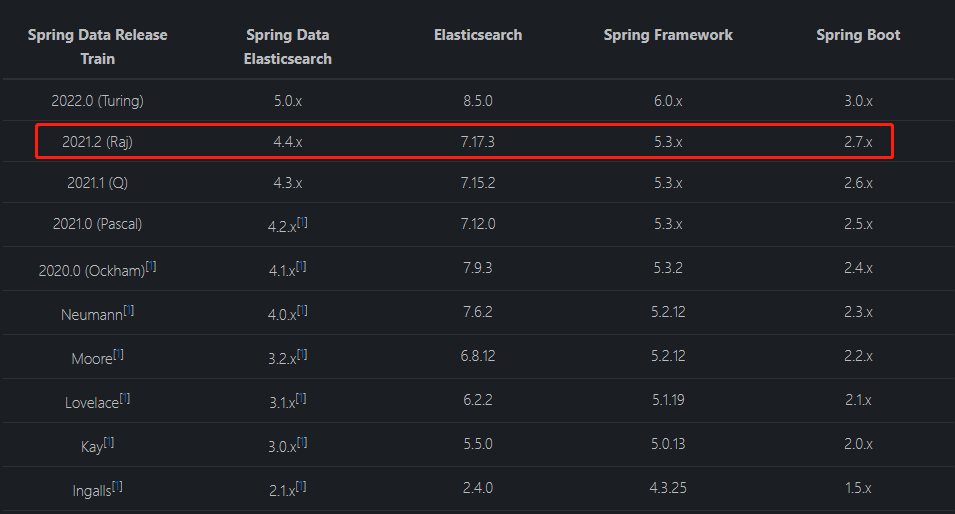
这里要统一一下版本,后面介绍与 Spring Boot 集成的时候,使用 Spring Boot 2.7.3,它的默认版本是 Elasticsearch 7.17.7,我们就使用该版本进行安装吧。
二、下载 Elasticsearch
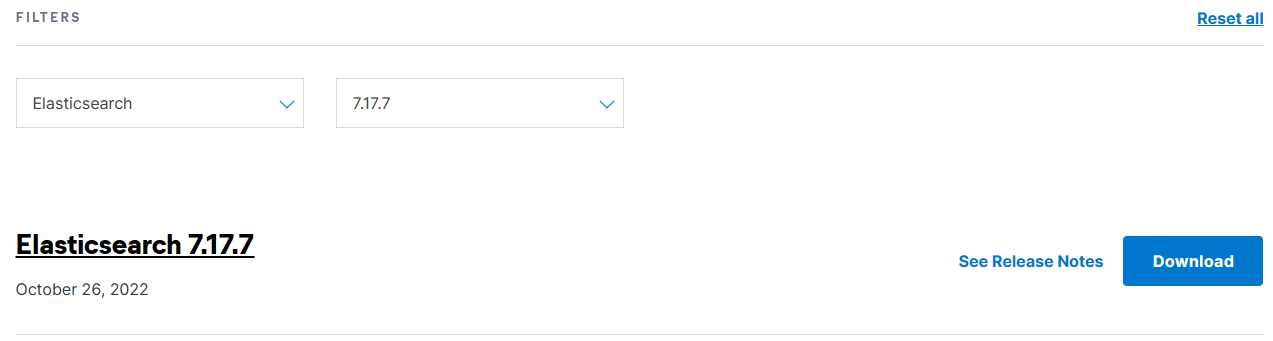
打开 Elasticsearch 的历史版本下载页,选择 Elasticsearch 的版本为 7.17.7,然后点击右侧的【Download】按钮进入下载页。
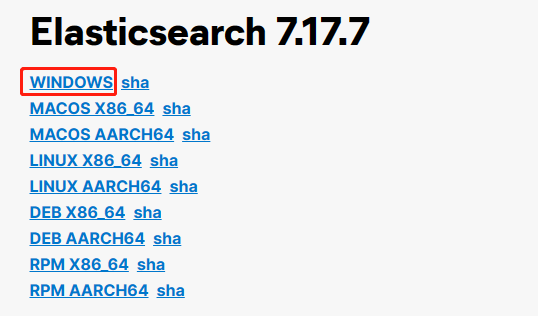
在 Elasticsearch 7.17.7 下载页中,根据自己的操作系统进行选择下载,这里我们选择【WINDOWS】进行下载。
开始下载…
下载完后就是一个 ZIP 压缩包:elasticsearch-7.17.7-windows-x86_64.zip
三、安装 Elasticsearch
Elasticsearch 的安装比较简单,直接解压即可,我的解压目录是:D:\elastic\elasticsearch-7.17.7,目录结构如下:
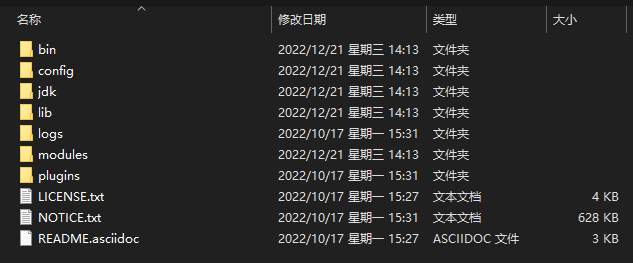
bin:存入一些二进制脚本,包括启动 ES、安装插件命令等都在这里。config:存放 ES 的配置文件,主要是elasticsearch.yml。jdk:ES 自带的 Java 环境,所以我们无需自己安装 Java 环境。lib:存放 ES 相关组件的jar包。logs:日志文件存放位置。plugins:插件文件存放位置,每个插件都包含在一个子目录中。data:运行后会自动生成该目录,用于存放该节点上分配的索引/分片的数据文件。
四、配置 Elasticsearch
Elasticsearch 提供了良好的默认值,只需要修改少量的配置即可使用(如果你只是在自己电脑上使用 Elasticsearch 做一些测试,完全不用修改任何配置,直接运行即可)。
Elasticsearch 有三个配置文件:
elasticsearch.yml用于配置 Elasticsearchjvm.options用于配置 Elasticsearch JVM 设置log4j2.properties用于配置 Elasticsearch 日志记录
elasticsearch.yml 配置是我们重点要讲的,一些重要的配置如下:
1. 集群名称
如果搭建的是集群环境,需要在每个节点上配置相同的集群名称,默认集群名称:elasticsearch
cluster.name: my-application
2. 节点名称
在群集环境中,用于配置当前节点的名称,每个节点应该配置不同的名称
node.name: node-1
3. 数据存储路径
可以配置 Elasticsearch 数据文件的存储路径,默认:主目录下的data 目录。
path.data: D:\elastic\elasticsearch-7.17.7\data
4. 日志存储路径
可以配置 Elasticsearch 日志文件的存储路径,默认:主目录下的logs目录。
path.logs: D:\elastic\elasticsearch-7.17.7\logs
5. 网络主机
默认情况下,Elasticsearch 只能在本地主机上访问,这里可以设置一个主机地址,用于在局域网中访问。
network.host: 192.168.0.1
6. HTTP 端口
修改配置 Elasticsearch 监听的端口,默认:9200
http.port: 9200
7. 节点间通信端口
在多节点集群环境中,每个节点间的通信会有一个专门的端口,可以修改这个监听的端口,默认:9300
transport.port: 9300
8. 集群与发现
在多节点集群环境中,需要节点之间可以互相发现并选择主节点,有两个配置可以设置:
(1)配置集群环境中所有节点的通信地址,节点使用此配置发现集群中其他节点(如果不配置,默认扫描当前服务器的 9300~9305端口,生产环境还是要配置的)。
- 可配置主机 + 端口,端口就是上一小节的“节点间通信端口”
- 端口也可以不填写,默认使用:9300
- 也可以是域名或IPv6地址,IPv6地址必须在中括号内。
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
- [0:0:0:0:0:ffff:c0a8:10c]:9301
(2)配置符合条件的主节点,他们会参与主节点的选举,配置项可以使用上面小节中的“节点名称”(未配置将从所有节点中进行选举主节点,生产上建议明确列出符合主节点条件的节点)。
cluster.initial_master_nodes:
- node-1
- node-2
- node-3
9. JVM 堆大小
默认情况下,Elasticsearch 会根据当前节点的总内存自动设置 JVM 堆大小。如果是生产环境,建议对默认大小进行调整。
该配置在 jvm.options 文件中进行配置:
-Xms2g
-Xmx2g
五、运行 Elasticsearch
在 Elasticsearch 安装目录下,双击 bin\elasticsearch.bat 即可运行。

输出如下内容表示启动成功。
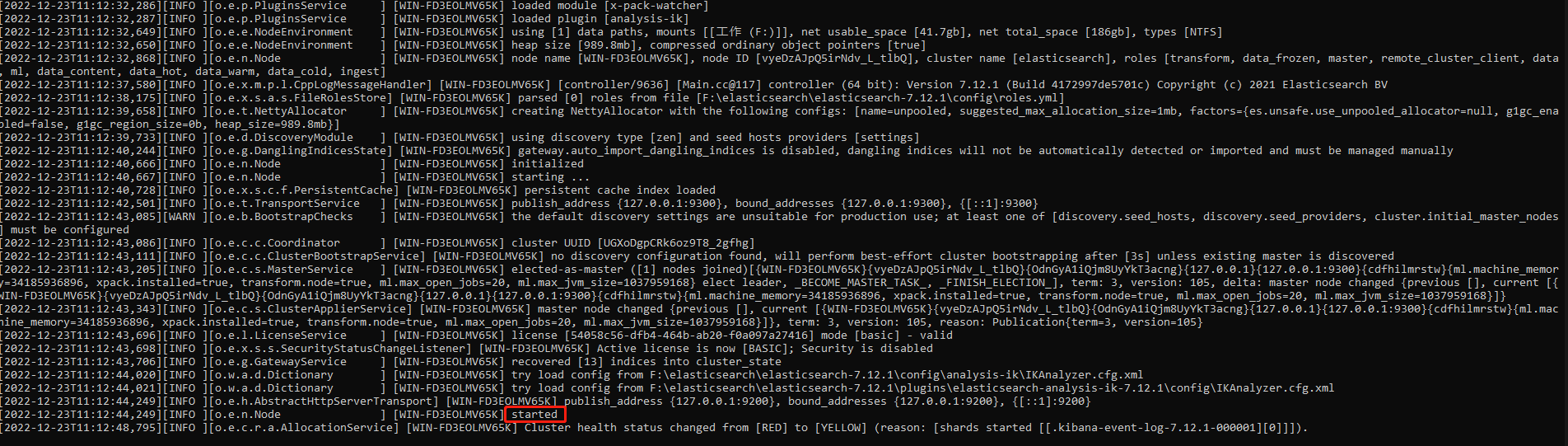
此时在浏览器中输入 http://localhost:9200,会输出如下内容,表示 Elasticsearch 启动成功
{
"name" : "WIN-AS4BRM3L8AU",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "MHVG4nBpTeGXhf0Fz5Chxg",
"version" : {
"number" : "7.17.7",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "78dcaaa8cee33438b91eca7f5c7f56a70fec9e80",
"build_date" : "2022-10-17T15:29:54.167373105Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
热门专栏
👍 《Python入门核心技术》
👍 《IDEA 教程:从入门到精通》
👍 《Java 教程:从入门到精通》
👍 《MySQL 教程:从入门到精通》
👍 《大数据核心技术从入门到精通》