版本兼容
| JDK | 1.8.0_211 |
|---|---|
| ZooKeeper | 3.4.14 |
| Hadoop | 3.2.1 |
| Hive | 3.1.2 |
| HBase | 2.2.1 |
| Scala | 2.13.1 |
| Spark | 2.4.4 |
| MySQL | 5.7.28 |
基本配置
修改ip和主机名
| 主机名 | IP地址 | Java | Zookeeper | Hadoop | Hive | HBase | Spark | MySQL |
|---|---|---|---|---|---|---|---|---|
| hadoop | 192.168.137.201 | √ | √ | √ | √ | √ | √ | |
| slave1 | 192.168.137.202 | √ | √ | √ | √ | √ | √ | |
| slave2 | 192.168.137.203 | √ | √ | √ | √ | √ | √ |
修改主机名
hostnamectl set-hostname hadoop
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
修改静态IP
/etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static
ONBOOT=yes
NETMASK=255.255.255.0
DNS1=192.168.137.1
GATEWAY=192.168.137.1
hadoop IPADDR=192.168.137.201
slave1 IPADDR=192.168.137.202
slave2 IPADDR=192.168.137.203
修改域名/etc/hosts
192.168.137.201 hadoop
192.168.137.202 slave1
192.168.137.203 slave2
测试三台
ping hadoop -c 2;ping slave1 -c 2; ping slave2 -c 2
集群互信
在hadoop上
ssh-keygen 生成密钥
实现互信三台同时执行
ssh-copy-id hadoop
ssh-copy-id slave1
ssh-copy-id slave2
拷贝到节点
scp id_rsa.pub slave1:/root/.ssh/authorized_keys
scp id_rsa.pub slave2:/root/.ssh/authorized_keys
测试
ssh hadoop
ssh slave1
ssh slave2
同步时间
安装工具
yum -y install ntp ntpdate
修改时区
timedatectl set-timezone Asia/Shanghai
同步时间
ntpdate ntp1.aliyun.com
查看时间
timedatectl
定时同步
每天0点执行同步,并写入硬件(防止重启时间改变)
0 0 * * * ntpdate ntp1.aliyun.com;hwclock -w
安装Java
解压
tar zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local
链接
ln -s /usr/local/jdk1.8.0_211 /usr/local/jdk
配置环境变量
/etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH=.:
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:PATH
source /etc/profile
测试
java -version
javac -version
Zookeeper集群
下载
http://mirror.bit.edu.cn/apache/zookeeper/
安装
tar zxvf zookeeper-3.4.14 -C /usr/local
ln -s /usr/local/zookeeper-3.4.14 /usr/local/zookeeper
配置环境变量
/etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=.:
Z
O
O
K
E
E
P
E
R
H
O
M
E
/
b
i
n
:
ZOOKEEPER_HOME/bin:
ZOOKEEPERHOME/bin:PATH
source /etc/profile
创建数据、日志目录
cd /usr/local/zookeeper
mkdir -p data
mkdir -p logs
配置文件
cp conf/zoo_sample.cfg conf/zoo.cfg
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
server.1=hadoop:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
注 server.A=B:C:D
A服务器编号,与每个myid里的数字保持一致
B服务器域名或IP地址
C Leader选举的端口
D Zookeeper之间通信端口
分发
scp -r zookeeper/ slave1:/usr/local/
scp -r zookeeper/ slave2:/usr/local/
编辑myid
hadoop echo 1 > data/myid
slave1 echo 2 > data/myid
slave2 echo 3 > data/myid
启动三台服务器
关闭防火墙
systemctl stop firewalld
sudo iptables -F
启动服务
zkServer.sh start
查看状态
zkServer.sh status
出现下面信息表示正常
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/…/conf/zoo.cfg
Mode: leader
验证 jps
QuorumPeerMain
Hadoop HA集群
| 主机名 | IP地址 | namenode | datanode | journalnode | resourcemanager |
|---|---|---|---|---|---|
| hadoop | 192.168.137.201 | √ | √ | √ | |
| slave1 | 192.168.137.202 | √ | √ | √ | √ |
| slave2 | 192.168.137.203 | √ | √ | √ |
在架构中每个namenode是一台独立的服务器,在任何时刻,只有一个namenode处于active状态,另一个处于standby状态,active态的namenode负责所有客户端的操作和请求,standby态的namenode处于从属,维护数据状态,随时准备切换。两个namenode为了同步数据,会通过一组journalnodes的进程进行通信,当active态的namenode有修改时,会告知大部分的journalnodes进程,standby态的namenode能读取journalnodes中的变更信息,并监控edit log的变化,同步信息。journalnodes能保证同一时刻集群中只有一个处于active态的namenode,2.x中只能配置两个namenode,3.x中可以配置多个。
下载
https://hadoop.apache.org/releases.html
安装
tar zxvf hadoop-3.2.1.tar.gz -C /usr/local
ln -s /usr/local/hadoop-3.2.1 /usr/local/hadoop
配置环境变量
/etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPHOME/bin:PATH
source /etc/profile
配置
/usr/local/hadoop/etc/hadoop见附件
启动
journalnode服务三台都启动
sbin/hadoop-daemon.sh start journalnode
验证 jps
JournalNode
格式化namenode,在namenode上(重新格式化需要删除原来journaldata里的数据,主节点NameNode产生新的clusterID、namespaceID,于是导致主节点的clusterID、namespaceID与各个子节点DataNode不一致)
hdfs namenode -format
tmp 目录下会出现dfs目录
启动namenode,在hadoop上
hadoop-daemon.sh start namenode
验证 jps
NameNode
namenode同步元数据信息,在slave1上
hdfs namenode -bootstrapStandby
复制hadoop上tmp 目录下dfs目录
再启动namenode
hadoop-daemon.sh start namenode
验证 jps
NameNode
启动datanode,在三台上(重启需要删除原来tmp下临时文件)
hadoop-daemon.sh start datanode
验证 jps
DataNode
浏览器查看
Namenode1 http://192.168.137.201:9870
Namenode2 http://192.168.137.202:9870 两台都处于standby状态
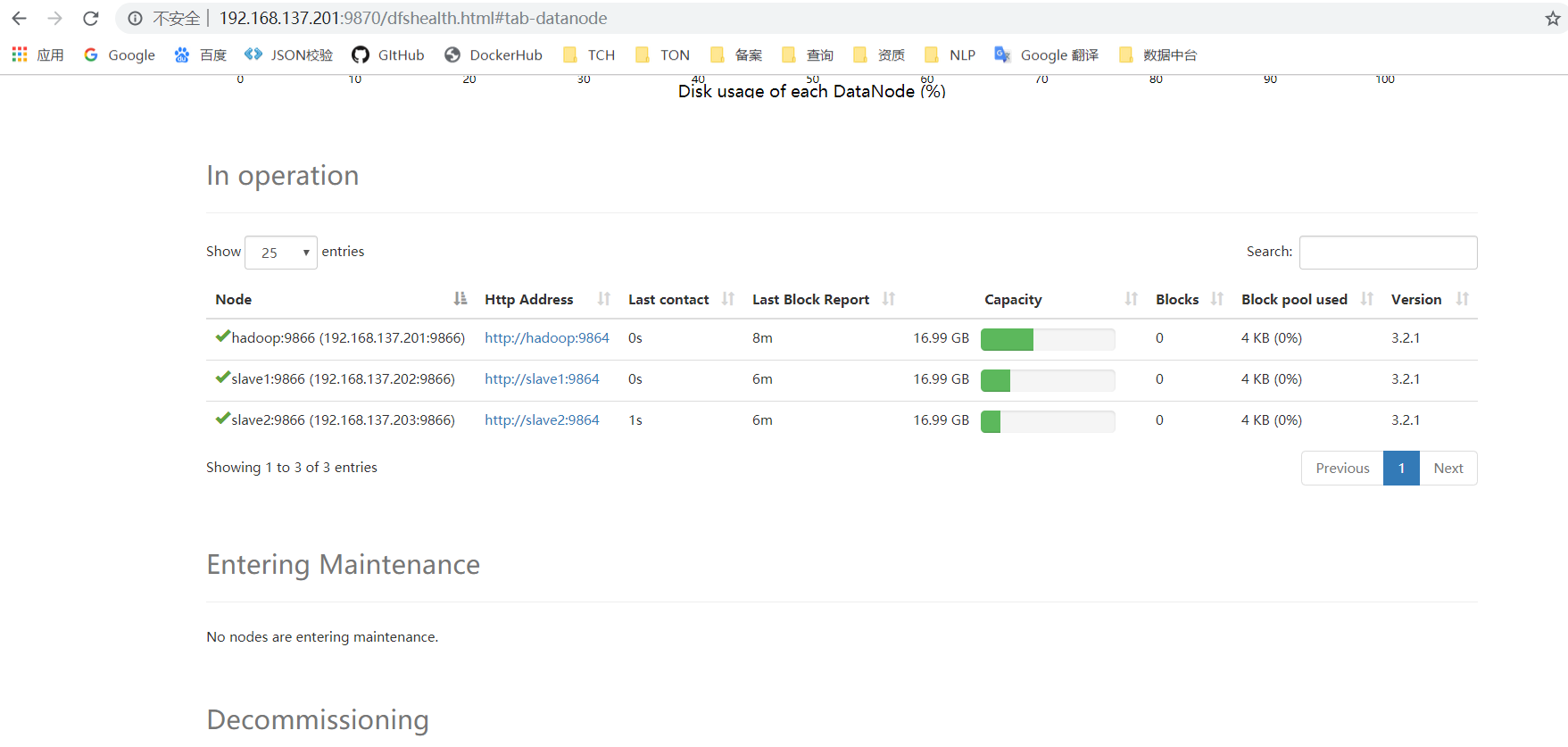
启动dfs
hadoop上执行 sbin/start-dfs.sh
http://192.168.137.201:9870 变为active态
启动yarn
hadoop上执行 sbin/start-yarn.sh
http://192.168.137.202:8088/cluster 查看
测试
创建目录
hadoop fs -mkdir /input-test
上传文件
hadoop fs -put /root/test /input-test
下载文件
hadoop fs -get /input-test/test
测试程序
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input-test /output-test
执行完后可以在web端看结果
MySQL安装
检查旧版本
rpm -qa | grep mariadb
rpm -qa | grep mysql
卸载
rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
下载
https://dev.mysql.com/downloads/mysql/
选择
系统 Red Hat Enterprise Linux 7 / Oracle Linux 7 (x86, 64-bit)
版本 mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
安装
tar xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm --force --nodeps
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm–force --nodeps
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm --force --nodeps
初始化
mysqld --initialize --user=mysql
查看密码cat /var/log/mysqld.log
[Note] A temporary password is generated for root@localhost: +zip+r:yM8Ci
修改密码
mysql -u root -p
ALTER USER ‘root’@‘%’ IDENTIFIED BY ‘123456’;
flush privileges;
设置开机自启
systemctl enable mysqld
Hive搭建(采用远程元存储)
| 主机名 | IP地址 | MySQL | Hive服务端 | Hive客户端 |
|---|---|---|---|---|
| hadoop | 192.168.137.201 | √ | ||
| slave1 | 192.168.137.202 | √ | ||
| slave2 | 192.168.137.203 | √ |
下载(3.x运行在hadoop3.x上)
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
安装
tar zxvf apache-hive-2.3.6-bin.tar.gz -C /usr/local
ln -s /usr/local/apache-hive-2.3.6-bin /usr/local/hive
配置环境变量
/etc/profile
export HIVE_HOME=/usr/local/hive
export PATH=.:
H
I
V
E
H
O
M
E
/
b
i
n
:
HIVE_HOME/bin:
HIVEHOME/bin:PATH
source /etc/profile
配置
hive/conf
cp hive-env.sh.template hive-env.sh
hive-env.sh修改
HADOOP_HOME=/usr/local/hadoop
HIVE_CONF_DIR=/usr/local/hive/conf
cp hive-log4j2.properties.template hive-log4j2.properties
hive-log4j2.properties 修改
property.hive.log.dir=/usr/local/hive/logs
mysql添加hive用户
CREATE DATABASE hive;
USE hive;
CREATE USER ‘hive’@‘localhost’ IDENTIFIED BY ‘123456’;
GRANT ALL ON hive.* TO ‘hive’@‘localhost’ IDENTIFIED BY ‘123456’;
GRANT ALL ON hive.* TO ‘hive’@‘%’ IDENTIFIED BY ‘123456’;
FLUSH PRIVILEGES;
连接器
下载
http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.48/
配置
拷贝MySQL连接器
cp mysql-connector-java-5.1.48.jar /usr/local/hive/lib/
检查hadoop安装目录下share/hadoop/common/lib 和 hive安装目录下lib的guava.jar版本,如果不一致删除低版本,拷贝高版本。
否则会报错 Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
初始化(slave1上)
schematool -dbType mysql -initSchema hive 123456
启动metastore服务
hive --service metastore
查看端口验证
netstat -nptl | grep 9083
启动客户端(在slave2上)
hive
测试
创建文件hive-test
1,李晨,女,22,IS
2,李国华,女,21,IS
3,王笑笑,女,22,IS
4,张山,男,21,CS
5,胡佳,女,18,CS
6,周来,男,23,IS
7,刘莉,女,21,IS
创建数据库
create database hivetest;
use hivetest;
创建表
create table userprofile(id int, name string, sex string, age int, department string) row format delimited fields terminated by “,”;
加载数据
load data local inpath “/root/hive-test” into table userprofile;
查询
select * from userprofile;
HBase集群搭建
| 主机名 | IP地址 | HRegionServer | HMaster |
|---|---|---|---|
| hadoop | 192.168.137.201 | √ | √ |
| slave1 | 192.168.137.202 | √ | √ |
| slave2 | 192.168.137.203 | √ |
下载
https://www.apache.org/dyn/closer.lua/hbase/2.2.1/hbase-2.2.1-bin.tar.gz
安装
tar zxvf hbase-2.2.1-bin.tar.gz -C /usr/local
ln -s /usr/local/hbase-2.2.1 hbase
配置环境变量
/etc/profile
export HBASE_HOME=/usr/local/hive
export PATH=.:
H
B
A
S
E
H
O
M
E
/
b
i
n
:
HBASE_HOME/bin:
HBASEHOME/bin:PATH
source /etc/profile
配置文件见附件
链接Hadoop hdfs配置
ln -s /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/
分发到节点
scp -r /usr/local/hbase slave1:/usr/local
scp -r /usr/local/hbase slave2:/usr/local
启动
start-hbase.sh
验证jps
HMaster hadoop slave1
HRegionServer hadoop slave1 slave2
访问页面
Master http://hadoop:16010/master-status
Backup Master http://slave1:16010/master-status
Spark集群搭建
下载
http://spark.apache.org/downloads.html
安装
tar zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local
ln -s /usr/local/spark-2.4.4-bin-hadoop2.7 spark
配置环境变量
/etc/profile
export SPARK_HOME=/usr/local/hive
export PATH=.:
S
P
A
R
K
H
O
M
E
/
b
i
n
:
SPARK_HOME/bin:
SPARKHOME/bin:PATH
source /etc/profile
配置见附件
分发到节点
scp -r /usr/local/spark slave1:/usr/local
scp -r /usr/local/spark slave2:/usr/local
修改 slave1上SPARK_MASTER_IP=slave1
启动
启动master节点:sbin/start-master.sh
启动worker节点:sbin/start-slaves.sh
Sqoop安装
下载
https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/
安装
tar zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/
ln -s /usr/local/sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
配置
cp sqoop-env-template.sh sqoop-env.sh
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export ZOOCFGDIR=/usr/local/zookeeper/conf
配置环境变量
/etc/profile
export SQOOP_HOME=/usr/local/hive
export PATH=.:
S
Q
O
O
P
H
O
M
E
/
b
i
n
:
SQOOP_HOME/bin:
SQOOPHOME/bin:PATH
source /etc/profile
拷贝mysql链接器
cp mysql-connector-java-5.1.47.jar /usr/local/sqoop/lib/
如果报错Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils 下载http://mirrors.tuna.tsinghua.edu.cn/apache//commons/lang/binaries/commons-lang-2.6-bin.zip 解压后拷贝到/usr/local/sqoop/lib
测试连接
sqoop list-databases --connect jdbc:mysql://hadoop:3306 --username root -P
Hadoop配置说明
sbin/
hadoop-env.sh 添加JDK安装路径
export JAVA_HOME=/usr/local/jdk/
添加用户
start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
etc/hadoop
core-site.xml
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地,这里使用集群地址-->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!--指定 hadoop 存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<!--在读写文件时使用的缓存大小-->
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<!-- 指定ZKFC故障自动切换转移 -->
<name>ha.zookeeper.quorum</name>
<value>hadoop:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<!--指定DataNode存储block的副本数量,不大于DataNode的个数就行,默认为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 完全分布式集群名称, 对应core-site中fs.defaultFS-->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- mycluster下面有两个NameNode,分别是node1, node2 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>node1,node2</value>
</property>
<!-- namenode RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.node1</name>
<value>hadoop:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.node2</name>
<value>slave1:8020</value>
</property>
<!-- namenode http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.node1</name>
<value>hadoop:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.node2</name>
<value>slave1:9870</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<!-- 运行在yarn上 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<!--MapReduce JobHistory Server地址-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<property>
<!--MapReduce JobHistory Server Web界面地址-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>15000</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>slave1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave2:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
workers 配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动
hadoop
slave2
slave3
Hbase配置说明
hbase-site.xml
<configuration>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/data</value>
</property>
</configuration>
hbase-env.sh
export JAVA_HOME=/usr/local/jdk
export HBASE_MANAGES_ZK=false
regionservers
hadoop
slave1
slave2
新建backup-masters
slave1
Hive配置说明
服务端
<configuration>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
<!--hdfs上hive元数据存放位置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/local/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
</property>
<!--连接数据库地址,名称 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop:3306/hive</value>
</property>
<!--连接数据库驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--连接数据库用户名称 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!--连接数据库用户密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--客户端显示当前查询表的头信息 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--客户端显示当前数据库名称信息 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
spark配置说明
spark-env.sh
#指定默认master的ip或主机名
export SPARK_MASTER_HOST=hadoop
#指定maaster提交任务的默认端口为7077
export SPARK_MASTER_PORT=7077
#指定masster节点的webui端口
export SPARK_MASTER_WEBUI_PORT=8080
#每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=1g
#允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心)
export SPARK_WORKER_CORES=1
#每个worker从节点的实例(可选配置)
export SPARK_WORKER_INSTANCES=1
#指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#指定整个集群状态是通过zookeeper来维护的,包括集群恢复
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark"
slaves
hadoop
slave1
slave2