不管你设计的系统架构是怎么样,最后都是你的组织内的沟通结构胜出。这个观点一直在组织内不断地被证明,但也不断地被忽略。
前后端分离的利与弊
近几年,随着微服务架构风格的引入、前后端生态的快速发展、多端产品化的出现,前后端分离已经成为行业的普遍实践,也是大型企业级分布式架构的缺省选择。
前后端分离也给软件技术人员的职业发展和协作方式带来了新的变化,分别出现了前端工程师、后端工程师、前端开发团队以及后端开发团队。
前后端分离使得前端关注信息架构,处理用户体验相关问题;而后端则关注构建业务能力、数据处理、持久化等问题,并向前端提供API接口(API as product),由前端进行消费。前端工程师不需要关注后端的具体实现和技术框架,后端工程师也不需要关注前端的具体实现和技术框架。
这带来了如下的好处:
- 前后端用户体验和业务逻辑解耦。不同端以及不同用户体验的变化不再影响后端API接口。后端API聚焦在表达业务能力,可同时服务于多端产品,而无需更改。
- 后端无需考虑业务逻辑或能力升级对前端的影响,只要保证接口不变即可。
- 响应变快。对前端尤其是多端服务出现后,前后端分代码和打包部署等技术分离、可以更快地响应不同的用户体验需求,而不必等待后端。
- 前后端工程师能力聚焦,可以专注各自领域的技术学习,聚焦提升自己的专项技能和经验。
- 前后端团队边界明显,认知负荷降低,单点开发效率高,只需关注本端的开发任务和技术即可。
分离带来的好处渐渐体现出来,尤其是在一些大型的互联网项目尤为明显。然而也有很多前后端分离的交付团队中出现了如下的问题:
- 团队开发业务的大小和复杂度随着项目的进行发生变更,引起前后端团队人员比例失调,比如出现前端开发团队进度快,需要等后端团队联调,或者反过来,后端团队等前端的情况,开发进度不畅,沟通协作成本高。
- 这样的临时任务变动,不管新增还是调换人员的动态调整成本高,体验差。
- 业务开发节奏快,没有足够时间量留给后端预先设计API,前端团队只能靠自己的猜测和仅有的共识进行开发,联调时双方分头再改一遍,返工高,沟通协作成本高。
- API的设计也受前端消费者和开发节奏的影响,面向前端的用户体验设计。
- 多个相同组件模块间出现多种不同的做法。
那么,前后端团队不分行不行。当然行,前后端人员不分的协作模式可以灵活匹配开发任务、全栈能力提升、同时团队还可以了解端到端的业务;但同时也使得团队整体的认知负荷高,架构越复杂成本越高,还会影响整体的开发效率。
那到底分不分呢?是什么在影响我们的架构?
组织的沟通结构决定软件构架
康威定律:设计系统的组织由于受到约束,这些设计往往是组织内部沟通结构的副本。
分不分答案其实很简单,就如文章开头所言,不管架构怎么设计,不管作为技术从业者的我们多少次向更好地架构和技术发起努力,但还是会看到“为什么得不到想要的设计,为什么明明是一个架构却各不相同”。因为,在这场对抗中,最后一定是组织的沟通结构胜出。实际上也确实是这样。从上述坏味道以及这些“前后端分离团队”的代码中也可以看出:
- /stock-schema/customer-detail
- /stocks/createAndNext
- /stocks/query-list?
后面就差写上page了
前后端分离看似简单,然而它实际上是技术的分离而非团队的分离。如果要真正实现前后端团队分离的协作模式,或者反过来要想实现前后端技术分离的分布式架构,都要首先考虑组织的沟通结构设计,让它去服务于你想要的及架构。
尤其是当我们在构建和运行大规模软件系统的时候,更需要刻意设计我们的团队沟通结构,以促成“低摩擦”的软件交付,避免“跨部门的职能竖井”、严重依赖外包资源、大量工作件流动受阻、无法提供快速交付或者难以满足现有业务服务的组织反馈机制”。
设计团队的沟通结构
那么,回到最初的问题,如果作为架构师的我们,想要实现前后端技术分离的分布式架构,如何设计团队的沟通结构?
我参考《高效能团队协作模式》中作者给出的四种拓扑类型、三种协作模式,以及设计原则试着给出如下两种答案:
1.方案A - 前后端分离的特性交付团队
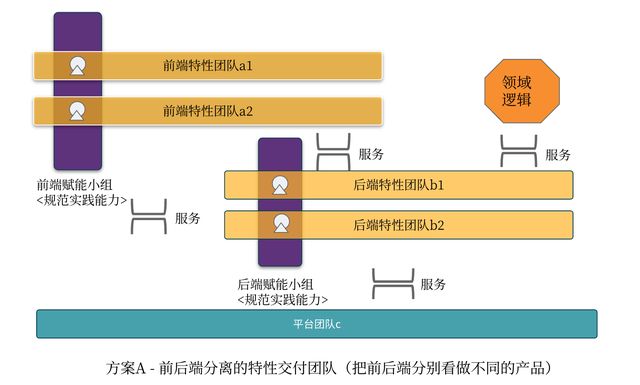
图1.1 方案A的端到端交付团队协作模式
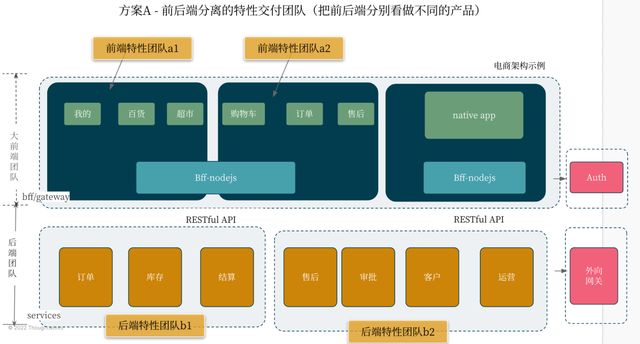
图1.2 方案A的端到端交付团队服务的架构图
图1.1和1.2分别展示了方案A中前后端团队如何围绕架构进行协作。方案A的假设在于前后端分别是不同的服务/产品,向不同的服务对象提供某种服务。
每个团队都是端到端的交付团队,好处是团队高度重视用户价值和服务的可用性,可以快速的响应各自的变化,团队的认知边界也很清晰,协作成本低,效率高。它的挑战则在于服务的边界是否定义良好、能否被正确实现,服务提供方可以实施服务管理实践时,这种模式才能正常运作。一旦边界或API不合理,效率会降低。这种方案对团队的服务/产品设计和管理能力要求较高。
方案A中赋能团队、以及可能的领域子系统团队是必不可少的。尤其在团队和业务规模增长的情况下,这两个团队的存在是为了补齐端到端特性团队的能力短板,降低认知负荷,提供特定领域的支持和赋能,同时避免了因组织沟通壁垒导致的规范、实践、重复造轮子、能力缺少等共性问题,尤其促进了跨组织的低摩擦软件交付和特性团队的交付效能。
2 方案B-端到端交付团队
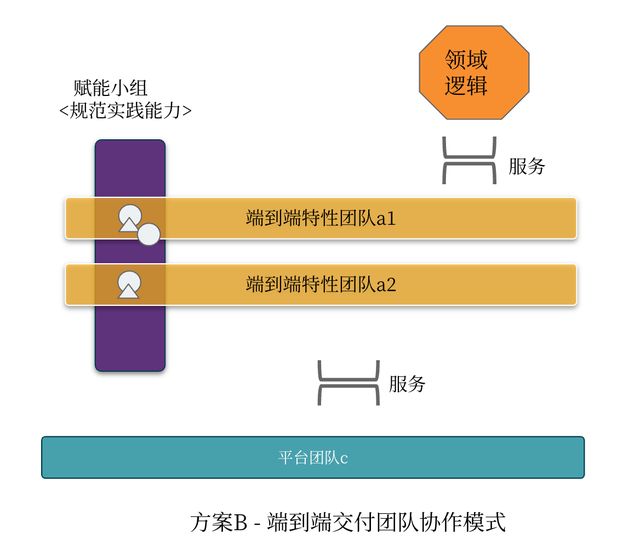
图2.1 方案B的端到端交付团队协作模式
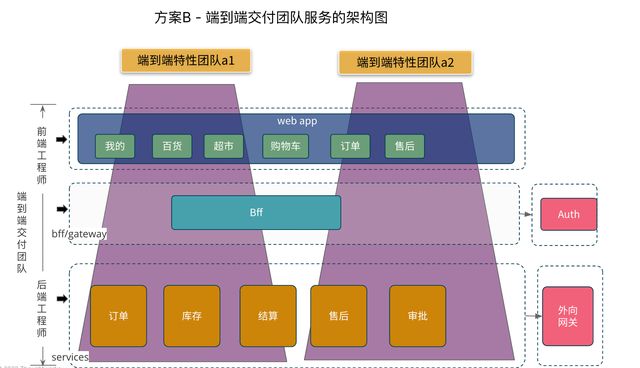
图2.2 方案B的端到端团队协作的架构图
图2.1和2.2分别展示了方案B中前后端团队如何围绕架构进行写作。方案B同样以端到端的特性团队为主,它将整个架构所服务的Web系统看做是一个服务或产品。因此,采取纵向切片的方式划分端到端的特性交付团队。在这样的团队协作中,前后端技术分离但不分家,前后端工程师分别以组件开发的方式进行协作和内部集成。
它的好处在于,能够完成端到端的交付,不需要依赖其它团队,团队自己有能力进行快速的业务创新和探索,也可以与领域子系统进行协作达成目的。
其缺点则在于:
- 前后端开发集成需要较多的协作和沟通成本
- 需要迭代计划的配合
- 这些开发细节和沟通等待会产生较高的认知负荷,对整体效率产生影响
- 对团队能力挑战大
同样,方案B中赋能团队、以及可能的领域子系统团队是必不可少的,这两个团队的存在避免了因组织沟通壁垒导致的规范、实践、重复造轮子、能力缺少等共性问题,尤其促进了跨组织特性团队的低摩擦交付和效能。
然,方案B的另一个问题在于,通常端到端交付的节奏都比较快,要预先留给后端进行设计的时间并不多,所以也会很容易出现在文章开头的问题(又回到原点):
- 前后端并行开发,在集成时返工
- 后端API为前端而设计,耦合度高
- 前后端人员比例与业务的节奏和复杂度不能灵活匹配,出现前端等后端,或者后端等前端联调的情况,造成浪费。
这些问题如何解决?
- 根据业务变化,动态的调整前后端工程师的比例。人员协调成本高,团队人员体验差,成长不利。
- Web开发前后端能力全栈,Story前后端一起做,灵活匹配开发任务、团队能力提升、还可以同时了解端到端的业务和实现;但同时也使得团队整体的认知负荷高,前后端技术和架构越复杂成本越高,还会影响整体的开发效率;也还需要同时考虑人员的成长与发展。
- 适当增加全栈的比例,前端和后端分开做,由全栈同学做“自由人”切换前后端开发任务。自由人越多,团队整体的适应力就越强,对自由人的挑战和依赖较大。
在我的访谈中,1、2、3均有很多团队尝试过或正在采纳。大多数团队前后端的比例在1:2 ~ 1:4之间调整。访谈的同学都提到了两个决策因素:
- 既要尊重现在的前后端技术发展趋势和生态不同,各自有不同的关注点和特点
- 又要为达成业务目标而努力。
那么,还有其它的解法吗?从《高效团队协作模式》一书中我找到了另一种答案:
在考虑这个问题的时候,切入点依然是康威定律的指引。我们会发现,一个项目的架构也并不是一成不变的,它会随着业务的变化而变化,在产品的早期、成熟期、规模期,架构是不同的形态,我们为什么不可以用动态的眼光去设计我们团队的沟通结构呢?答案是显然的。
所以就有如下的解法:
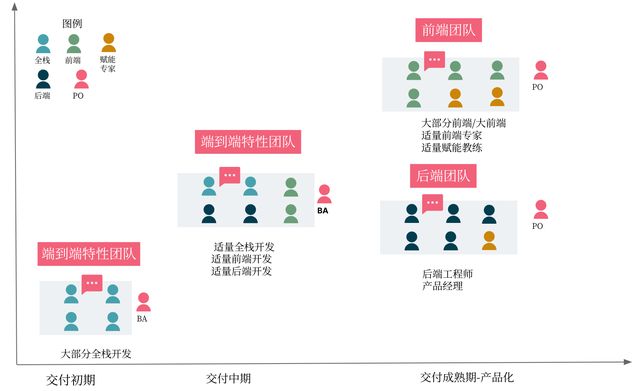
假设业务及技术的复杂度和规模随着时间而增加。那么:
- 在交付初期,业务和技术的复杂度相对较低,要求业务快速上线完成价值转化。
- 前端后端更多的是在构建基础的页面和模型。与此同时,团队刚刚形成,需要端到端的去了解业务的价值,面向Web开发的全栈更容易促成团队的组建、规范和达成业务目标。
- 交付中期,业务开始增长,有复杂的业务流程引入,以及用户体验要求上升。
- 前后端的技术复杂度也随之而来,比如页面的渲染,交互操作,微前端的引入、数据的一致性,业务的可用性都开始有了较高的要求。
同时,代码量也到了一定的量级,在耦合性、内聚性也都出现了不同程度的质量要求。
这个时候,可以适当的开始引入前后端专家,以赋能角色促进的方式与全栈团队进行协作,解决技术难度,整洁代码治理,赋能规范和对应的前后端工程实践等以提高整体的工程效能。 - 交付的成熟期,随着业务规模发展,系统架构也开始变的复杂起来,用户多了起来,除了功能特性,也会在页面加载性能、数据安全等方面提出新的要求。
- 与此同时,也会出现多端产品服务,开发者生态的形成也会促进后端形成平台化的能力。
这些变化都会促成前后端团队的逐渐分离。
这个时候前后端团队也会适当增加转向架构和特定领域的技术专家,可能增加特定领域团队,而大前端的工程师则会补充前端+Bff的开发能力诉求。
总结
前后端分离本质上是技术的分离,而不是人员的分离。团队要不要分取决于你如何设计你的架构,也取决于你的业务模式,所服务的产品形态、团队能力、工程实践的成熟度。
前后端团队分离的成本是极高的,对团队的能力要求也是极高的。它并不适合业务不明确,交付优先级经常变动,需要快速交付,且需要不断创新和探索的业务。
从个人成长来看,前后端分不分并不重要,而是于自己的发展目标与项目机会是否匹配,团队不应该成为我们成长的阻碍,而应该化为促进我们成长的平台。
本文的讨论并不涉及Mobile app的开发。如果你的架构既有Web端,又有Native app, 小程序,你的团队结构是怎么设计的呢?







![[AUTOSAR][诊断管理][ECU][$22] 读取相关的数据](https://img-blog.csdnimg.cn/bd06d5c875f94ccc964f1cba50b6eda3.png)