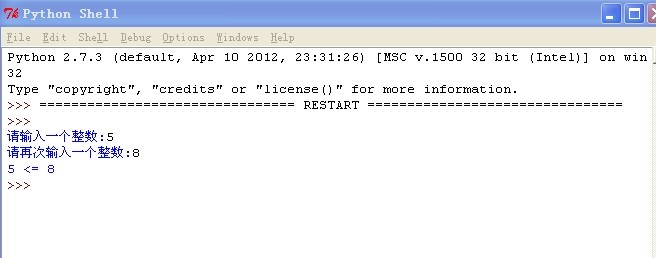
Attetion is all you need
参考:沐神(
沐神_论文精讲_Attention is all you need)
1、Abstract
主流的序列转录模型(给一个序列生成另一个序列,比如机器翻译,给一句英文,生成一句中文)都是基于复杂的循环或卷积神经网络,一般是基于encoder and decoder的架构。在这些好的模型中,一般会在encoder和decoder之间使用注意力机制。
而本文提出了一个新的简单的架构,Transformer,仅基于注意力机制,免除了循环或卷积。在俩个机器翻译任务上证明这个模型的有效性,并行度更好,训练时间少。并且Transformer模型还可以泛化到其他的任务当中。
Our model achieves 28.4 BLEU on the WMT 2014 English to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature.
2、Conclusion
Transformer是第一篇做序列转录的模型,仅使用了注意力机制,将循环层替换为multi-headed self-attetion.它在机器翻译任务重表现的很好。
这种纯注意力机制的模型还可以泛化到其他领域当中。
3、Introduction
循环神经网络(RNN),长短期记忆(LSTM)和门控循环(gated recurrent)神经网络,已经成为序列建模和转导问题(如语言建模和机器翻译)的最先进方法。主要有language models 和 encoder-decoder architectures.
RNN处理序列时通常会根据序列的输入输出顺序从左到右一步步前进,计算位置t时,会输出一个隐藏状态ht,该输出由之前的隐藏状态ht-1和当前位置t共同决定的。这导致使用RNN计算序列模型无法并行,它需要等到先前状态ht-1计算完成之后才能计算ht。而且由于内存的限制,会对序列长短有着限制,若序列过长会导致历史信息的丢失或者内存开销过多。虽然近期的工作对RNN有着很多的改进,比如使用分解的方法提升并行度,但是最根本的问题依旧存在着。
在各种任务中,注意机制已经成为序列建模和转换模型的必要组成部分,允许模型不考虑输入或输出序列中的距离的情况。但大多情况下,注意力机制都会与RNN结合使用。
在本文中,Transformer,不在使用循环神经网络,而是纯注意力机制。从而其可以并行运算,从而使得能够在更短的时间做到比之前更好的结果。
4、Background
可以使用卷积神经网络替换循环神经网络,使得减少时序的计算。但如果使用卷积神经网络对于较长的序列难以建模,因为卷积神经网络计算时使用的是3x3/5x5等大小的卷积核,如果要寻找间隔较长的俩个像素之间的关系,需要卷积多次才能够将这俩个像素融合起来,但是如果使用Transformer的注意力机制,可以一次可以看到所有像素。但是卷积神经网络可以卷积出多个输出通道,每个输出通道可以认为是它去识别不一样的模式,为了达到这一效果,Transformer提出了一个Multi-Head Attention来实现这一影响。
自注意力机制,将单个序列不同位置联系起来的注意力机制,以便于计算序列内部之间的联系,且应用非常广泛。
端到端的记忆网络基于循环注意力机制,替换了序列对齐循环,已被证明在简单的语言问题的回答和语言建模任务重表现良好。
Transformer是第一个基于自注意力机制来计算输入输出的transuduction model,没有使用序列对齐的RNN模型或卷积。
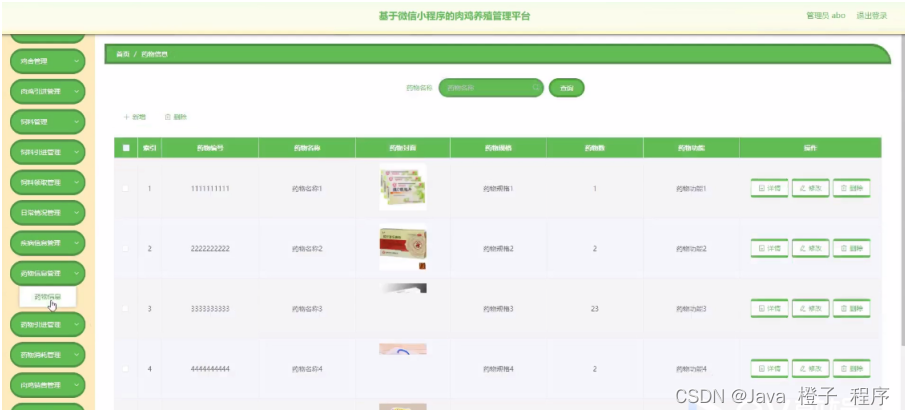
5、模型架构
大多序列转导(sequence transduction)模型都使用了encoder-decoder架构。首先encoder是将一个序列(x1,…,xn)编码对应为(z1,…,zn),随后给decoder输入Z生成输出序列(y1,…,ym),其中n,m可以不相等,而且解码器是使用了自回归模型,也就是说之前的输出作为下一时刻额外的输入(解码器的输出是一个个输出,比如已知y1-y3,下一时刻生成y4)。
首先Transformer结构是

5.1 Encoder and Decoder Stacks
Encoder: N=6,重复6次,每个layer 有俩个sub-layers,第一个为multi-head自注意力机制,第二个是position-wise fully connected feed-forward network,效果也就是相当于一个MLP。对于每个子层都用了一个参差连接,子层的输出为:LayerNorm(x + Sublayer(x)),为了简单,激情每一个层的输出维度dmodel=512.(不同于MLP将维度减少,也不同为CNN将空间维度减少,channel维度上拉)
**Decoder:**N=6,每个layer 除了有之前的俩个sub-layers之外,新加了第三个子层,一个多头注意力机制,与encoder一样,使用了参差结构,并在之后使用了LN,并使用了自回归,当前时刻的输入是上面一些时刻的输出。但因为在预测阶段,网络不能看到t时候之后的输出,只能看到t时刻之前的输出,但在注意力机制当中,每次都可以看到完整的输入(为什么训练的时候注意力机制可以看到完整的输入呢?因为训练时输入了GT,而且注意力机制不像卷积小窗口,而是可以看到所有输入,所以可以看到完整的输入),所以为了统一训练和预测阶段,我们使用了Masked Multi-Head,使得网络在t时刻只能看到t时刻之前的输出。
5.2 Attention
注意力函数是一个query,和一些key-value键值对映射成一个输出的一个函数,其中query,keys,values和output都是向量。输出是values的加权和,所以输出的维度和value的维度是一样的。其中,权重是由values对应的key和query的相似度(compatibility function)计算的来的。
(形象一点的理解:key相当于名字,value是分数,query表示我想看谁的分数,所以通过query去查key对应的value,获得最终的结果,不同的注意力机制,计算相似度的方法不一样。)
5.2.1 Scaled Dot-Product Attention
queries和keys的维度都为dk,values的维度为dv,具体计算时将query和keys做内积,内积越大,相似度越高,内积为0,代表垂直没有相似度。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
常见的俩种计算注意力机制的方法,一种加型注意力机制,可以处理query和keys不等长,另一种是点积注意力机制,与作者提出的基本相同,但Transfomer的除以了 d k \sqrt{d_{k}} dk。点乘更简单,高校。
当dk较大/小时,点乘的值会比较大/小,会导致softmax之后的结果更加靠近0/1,更向俩端靠拢,会导致梯度比较小(因为此时该靠近1的已经趋于1,该趋于0的也都趋于0了,所以网络自认为已经收敛了)。所以/ d k \sqrt{d_{k}} dk。

5.2.2 Multi-Head Attention
与其使用单个维度为dmodel(keys, values, queries)的注意力函数,不如将queries,key,values投影到一个低维,投影h次,再做h次的注意力函数,得到的h个输出在使用concat并在一起。然后再通过线性投影得到最终的输出。(这里的投影相当于做了一个MLP)(为了得到更多的学习参数)

MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O where headi = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} \operatorname{MultiHead}(Q, K, V) & =\operatorname{Concat}\left(\operatorname{head}_{1}, \ldots, \operatorname{head}_{\mathrm{h}}\right) W^{O} \\ \text { where headi } & =\operatorname{Attention}\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) \end{aligned} MultiHead(Q,K,V) where headi =Concat(head1,…,headh)WO=Attention(QWiQ,KWiK,VWiV)
h=8,因为有参差连接存在,所以输入和输出维度相等,所以投影时,投影的事输出的维度/h,之前输出的维度是512,所以512/8=64,所以就是每个head投影到一个64维。
5.2.3 Application of Attention in our model

三种使用方法:
- 在"encoder-decoder attention" layers,quries来自之前的decoder,key和values来自encoder。这是的decoder中的每个位置可以覆盖输入序列的所有位置,这模拟了序列到序列模型中典型的编码器和解码器模型。
- encoder中的自注意力层,在自注意力层中的所有keys、values、queries都来自同一个地方,也就是来自编码器前一层的输出。编码器的每个位置都可以处理编码器前一层中的所有位置。
- 类似的,解码器的自注意力层允许解码器中的每个位置关注到所有的输入,我们要防止信息信息在decoder中向左流动,以保持自回归特性。并通过为softmax的输出设置掩码(setting -无穷)来实现scaled dot-product attention。
The Transformer uses multi-head attention in three different ways:
• In “encoder-decoder attention” layers, the queries come from the previous decoder layer,and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [38, 2, 9].
• The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
• Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flflow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections. See Figure 2.
5.3 Position-wise Feed-Forward Networks
除了注意力子层,编码器和解码器的每一层都包含了一个fully connected feed-forward网络,这个网络分别且相同的对每一个位置(一个序列中的某一个词)都作用了一遍。包含了俩个线性转换和ReLU激活函数。
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2
x为固定维度512,W1会512投影为dff=2048,因为有参差连接,所以W2将2048->512
5.4 Embeddings and Softmax
Embeddings就是对一个序列中的任一一个词都学习一个长为dmodel的向量来表示它。dmodel=512,encoder、decoder输入,softmax之后也要一个embedding,这三个embedding权重相同。注意要将学习到的权重 multiply d m o d e l \sqrt{d_{model}} dmodel。学习embeddings是会将每个向量的l2 norm学的比较小,eg=1,不管维度多大,其l2 norm都等于1,所以维度一大,其权重值就会变小。所以乘 d m o d e l \sqrt{d_{model}} dmodel变大一些。
(1. L2 Norm会将向量的所有值归一化2. 维度越大的向量归一化后其单个值就越小3. 而时序信息是递增的整数(往后看会讲)4. 为了让它们的规模相匹配,故而乘了一个根号d给前面)
(权重经l2正则化以后都比较小,维度越大权重会越小,为了让它能跟位置编码一个维度,乘了根号512)
5.4 Positional Encoding
因为attention没有时序信息,输出是对value的一个加权和,权重是query和key之间的距离,和序列信息无关,所以一个序列顺序变了但经过attetion之后还是一样的,所以需要加入时序信息。
RNN是将上一时刻的输出作为下一时刻的输入来传递历史信息。Attention需要在输入中加入时序信息,eg:将每个单词的位置i加到输入中。
位置信息是通过一系列公式加入的,该位置信息长为512,然后结果加到输入信息中,则输入中就加入了时序信息。
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d m o d e l ) \begin{aligned} P E_{(p o s, 2 i)} & =\sin \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right) \\ P E_{(p o s, 2 i+1)} & =\cos \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right) \end{aligned} PE(pos,2i)PE(pos,2i+1)=sin(pos/100002i/dmodel)=cos(pos/100002i/dmodel)
4 Why Self-Attetion
比较了自注意力与循环层、卷积层进行比较。
Layer Type Complexity per Layer Sequential Operations Maximum Path Length Self-Attention O ( n 2 ⋅ d ) O ( 1 ) O ( 1 ) Recurrent O ( n ⋅ d 2 ) O ( n ) O ( n ) Convolutional O ( k ⋅ n ⋅ d 2 ) O ( 1 ) O ( log k ( n ) ) Self-Attention (restricted) O ( r ⋅ n ⋅ d ) O ( 1 ) O ( n / r ) \begin{array}{lccc} \hline \text { Layer Type } & \text { Complexity per Layer } & \begin{array}{c} \text { Sequential } \\ \text { Operations } \end{array} & \text { Maximum Path Length } \\ \hline \text { Self-Attention } & O\left(n^{2} \cdot d\right) & O(1) & O(1) \\ \text { Recurrent } & O\left(n \cdot d^{2}\right) & O(n) & O(n) \\ \text { Convolutional } & O\left(k \cdot n \cdot d^{2}\right) & O(1) & O\left(\log _{k}(n)\right) \\ \text { Self-Attention (restricted) } & O(r \cdot n \cdot d) & O(1) & O(n / r) \\ \hline \end{array} Layer Type Self-Attention Recurrent Convolutional Self-Attention (restricted) Complexity per Layer O(n2⋅d)O(n⋅d2)O(k⋅n⋅d2)O(r⋅n⋅d) Sequential Operations O(1)O(n)O(1)O(1) Maximum Path Length O(1)O(n)O(logk(n))O(n/r)