requests不是python的内置库,需要手动安装:
pip install requests一. 一个类型和六个属性
1.1 类型
requests访问url后返回的对象类型为requests.models.Response类型。

1.2 属性
下面是requests.models.Response类型对象的方法。
- text:以字符串的形式返回网站源码
- encoding:访问或定制编码方式
- url:获取请求的url
- content:响应字节类型,返回二进制的网站内容。
- status_code:响应的状态码
- headers:响应的头信息

二. get请求
使用requests.get(url, params, kwargs)方法:
url:请求资源路径
params:参数
kwargs:字典。
对比urllib,当有参数时,我们需要先进行请求对象的定制,在进行访问。而requests不需要进行请求对象的定制,可以将参数直接传入,并且requests的参数不需要urlencode进行编码,请求资源路径中参数前的'?'可以加,也可以不加。

三. post请求
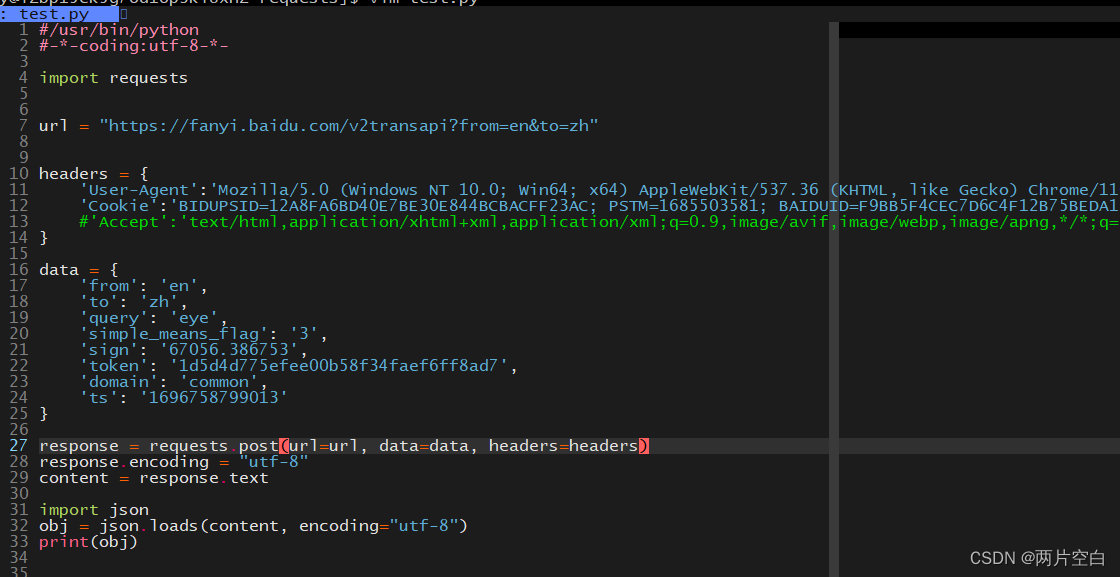
使用requests.post(url, data, json, args)方法:
url:请求资源路径
data:参数
args:字典。
四.代理
由于get和post的第三个参数是一个字典。我们可以创建代理变量,然后将代理变量传入使用。

五.cookie登录古诗文网

查看登录时的请求参数,有三个参数(__VIEWSTATE,__VIEWSTATEGENERATOR和code)是未知的,需要获取。

- 获取__VIEWSTATE和__VIEWSTATEGENERATOR
__VIEWSTATE和__VIEWSTATEGENERATOR存在于网页源代码中,我们需要先获取源代码。解析出这两个参数。使用bs5库的BeautifulSoup来进行解析

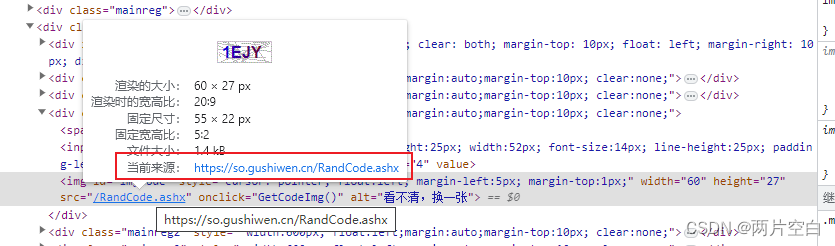
- 获取code验证码
code验证码在下图链接中,我们需要访问该链接并获取资源。我们会得到一张包含验证码的图片。在通过input函数来获取验证码。
注意点:
在下载资源时,我们不能使用urllib.request的urlretrieve函数来访问。原因是当访问获取到验证码之后,再去访问登录连接时,访问了两次,导致验证码刷新,获取的验证码失效了。这里我们就需要使用requests.session。
requests.session介绍:
s = requests.session() 会实例化会话一个会话对象。
作用:
- 会话对象让你能跨请求保持这些参数。他也会在同一个Session实例发出的所有请求之间保持cookie
- 会话对象具有主要的requests API的所有方法。你可以当成Request去使用。
遇到的问题:
当我使用session来请求网站时,一直报验证码错误。后面通过查出来,原因是:session在访问后会保存cookie,在header中不需要加cookie了。
#/usr/bin/python
#-*-coding:utf-8-*-
import requests
session = requests.Session()
url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
#'Accept-Encoding':'gzip, deflate, br',
#'Cookie':'BIDUPSID=12A8FA6BD40E7BE30E844BCBACFF23AC; PSTM=1685503581; BAIDUID=F9BB5F4CEC7D6C4F12B75BEDA133E123:FG=1; BD_UPN=12314753; MCITY=-289%3A; BDUSS=2VDak14ZWdGQVpaMzJKTFhkcnV6Um1IeW51QmwyaUdwc0o2b3lHekFGb2d-dk5rSVFBQUFBJCQAAAAAAAAAAAEAAADqHDzIdGltZcG9xqy~1bDXAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACBxzGQgccxkT; BDUSS_BFESS=2VDak14ZWdGQVpaMzJKTFhkcnV6Um1IeW51QmwyaUdwc0o2b3lHekFGb2d-dk5rSVFBQUFBJCQAAAAAAAAAAAEAAADqHDzIdGltZcG9xqy~1bDXAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACBxzGQgccxkT; H_WISE_SIDS=234020_110085_259301_265864_266759_266777_268592_268634_259642_269390_269552_203519_269831_269904_270184_270532_270662_270969_271037_271171_271178_269730_267659_271319_271470_269610_270102_270875_269777_271673_268416_256151_8000073_8000118_8000129_8000139_8000162_8000174_8000179_8000186_8000189_8000191_8000196_8000204; H_WISE_SIDS_BFESS=234020_110085_259301_265864_266759_266777_268592_268634_259642_269390_269552_203519_269831_269904_270184_270532_270662_270969_271037_271171_271178_269730_267659_271319_271470_269610_270102_270875_269777_271673_268416_256151_8000073_8000118_8000129_8000139_8000162_8000174_8000179_8000186_8000189_8000191_8000196_8000204; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=exAOJeC62i1lporfpFYR2QBJEtn-wpTTH6aojIHQ7Y89EBl12yeKEG0PIx8g0KuMn57JogKK0eOTHk_F_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=JnIqVCt5tKt3hD_RKb5o2bcH-UIsJnvlB2Q-5KL-2CjSqb74bl3DqtrX0t5Z0R3XH6vj-UbdJJjojlTS0jJZe5FkLxkDJJc-W2TxoUJYMInJhhvGXtIhjUIebPRiJPQ9QgbWMhQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0M5DK0hC-le5-MjjoMMhoWK6kOHD7yWCvVahvcOR5Jj6KBqtcWQljhQPDLtRrI5qcN34P-SPTP3MA--t4ODf-O-tciKej7BIJGWx3Bsq0x0h3te-bQyPQaaPogJIOMahkM5l7xObv3QlPK5JkgMx6MqpQJQeQ-5KQN3KJmfbL9bT3tjjT3jH-Otj08JR3fL-08atn0qn7I5bJHK4QH-UIsybLjB2Q-5KL-0-cRqJQ4bR3AefvX0t5Z0x3r0G633MbdJJjoSPcsMR5JyRFrQqtthxrUK2TxoUJ85DnJhhvDXqopWfPebPRiJPQ9QgbWMhQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0M5DK0MKt4j6Aaej5MKUbHJK6e2I600Tr2a-t3qRQoXU6qLT5X04-ehxtq5jRtQft-LloksJcg0J5b3h0njxQy0bQTLnbK5bcFMDbGsbosMUonDh8s2a7MJUntBRrT0l5O5hvvhb5O3M7OBUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQ2a_EtTLqfR4foKtQtC_5q-ov2bu_-P6Mbq7CWMT-0bFHBCjs-n7Ke4JDWqKK0fDpQqOXeRbjQNn7_JjO2qT1VD3Xe5rpL47LDlr-BMQxtNRAXInjtpvh8JuGjU6obUPUDMo9LUvWX2cdot5yBbc8eIna5h'
}
#获取网页源代码,来获取参数
req = session.get(url=url, headers=header)
print("first get cookie", session.cookies)
req.encoding = "utf-8"
content = req.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'lxml')
#获取__VIEWSTATE,放回是一个列表
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
#获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
code_addrs = soup.select('#imgCode')[0].attrs.get('src')
#print(code_addrs)
code_url = 'https://so.gushiwen.cn' + code_addrs
#print(code_url)
#获取验证码
#使用urllib下载资源
#这里会有一个问题,这里urllib请求了一次得到验证码,下面使用requests又请求了一次,验证码刷新了
#需要使用requests的session来实现
#import urllib.request
#urllib.request.urlretrieve(code_url, 'code.jpg')
code_req = session.get(url = code_url, headers=header)
print("first get cookie", session.cookies)
#注意要使用二进制数据,因为我们要使用的图片的下载
code_content = code_req.content
#wb是将二进制数据写入文件
with open("code.jpg", 'wb') as codefp:
codefp.write(code_content)
code = input("请输入验证码:")
print(code)
denglu_url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR':viewstategenerator,
'from':'https://so.gushiwen.cn/user/collect.aspx',
'email': '账号',
'pwd': '密码',
'code': code,
'denglu': '登录',
}
#denglu_req = requests.post(url=url, data=data, headers=header)
denglu_req = session.post(url=denglu_url, data=data, headers=header)
print("first get cookie", session.cookies)
print("first get cookie", denglu_req.cookies)
#denglu_req.encoding = 'utf-8'
denglu_content = denglu_req.text
#print(denglu_req.text)
fp = open("gushi.html", 'w', encoding='UTF-8')
fp.write(denglu_content)
fp.close()