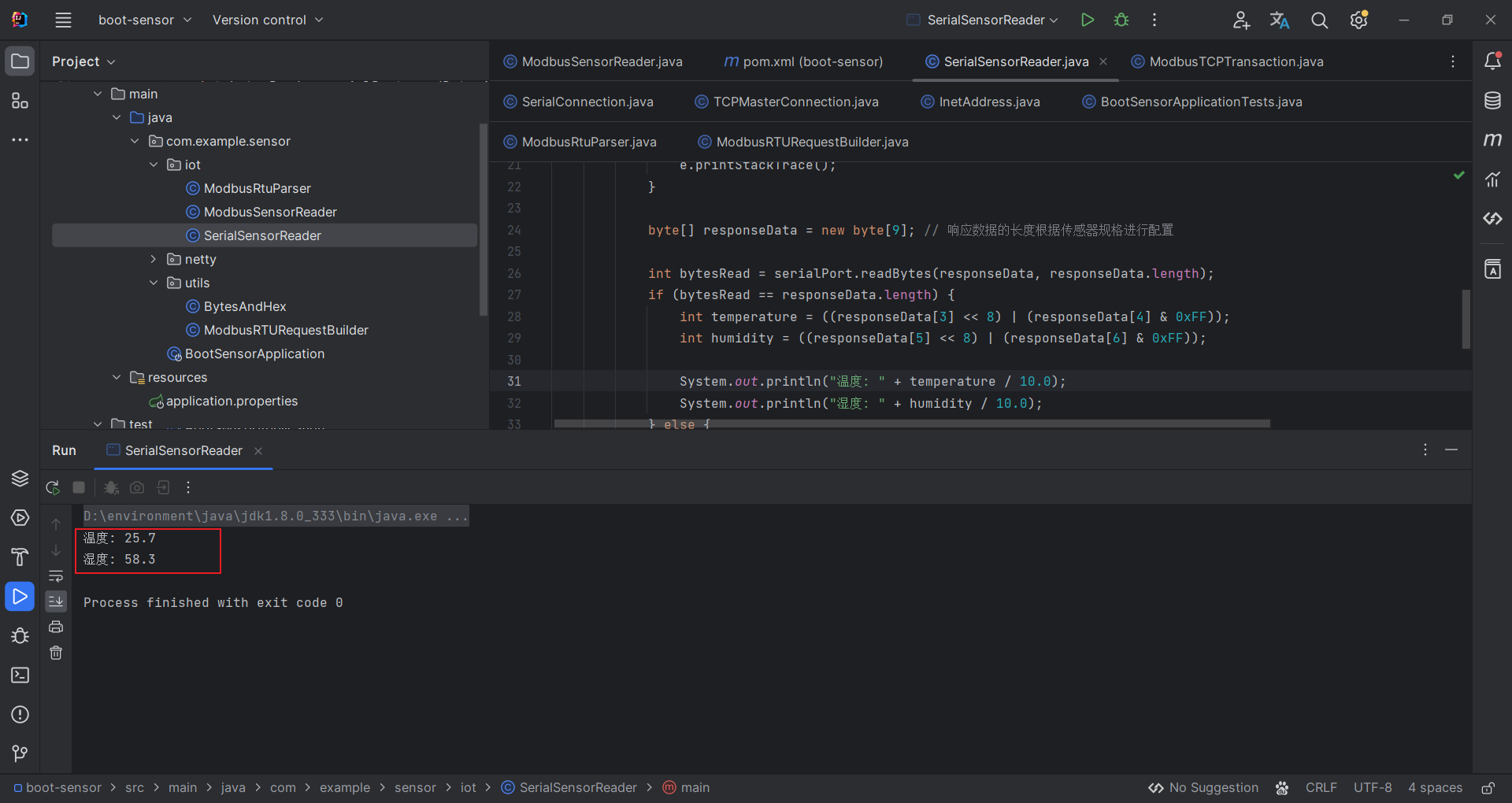
BeautifulSoup库用于从HTML或XML文件中提取数据。它可以自动将复杂的HTML文档转换为树形结构,并提供简单的方法来搜索文档中的节点,使得我们可以轻松地遍历和修改HTML文档的内容。广泛用于Web爬虫和数据抽取应用程序中。
读者如果需要使用这个库,同样需要执行pip命令用以安装:
- 安装PIP包:pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
21.8.1 属性定位链接
通过HTML属性我们可以轻松的实现对特定页面特定元素的提取,如下代码我们首先封装两个函数,其中get_page_attrs函数用于一次性解析需求,函数search_page则用于多次对页面进行解析,这两个函数如果传入attribute属性则用于提取属性内的参数,而传入text则用于提取属性自身文本。
import requests
from bs4 import BeautifulSoup
header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98"}
# 参数1: 解析页面URL
# 参数2: 需要解析的页面定位
# 参数3: 提取标签属性
# 参数4:设置超时时间
# 参数5:设置返回类型(attribute 返回属性字段,text 返回文本字段)
def get_page_attrs(url,regx,attrs,timeout,type):
respon_page = []
try:
respon = requests.get(url=url, headers=header, timeout=timeout)
if respon.status_code == 200:
if respon != None:
soup = BeautifulSoup(respon.text, "html.parser")
ret = soup.select(regx)
for item in ret:
if type == "attribute":
respon_page.append( str(item.attrs[attrs] ))
if type == "text":
respon_page.append(str(item.get_text()))
return respon_page
else:
return None
except Exception:
return None
return None
# 对页面多次搜索
# 参数1: 需要解析的html文本
# 参数2: 需要解析的页面定位
# 参数3: 提取标签属性
# 参数5:设置返回类型(attribute 返回属性字段,text 返回文本字段)
def search_page(data,regx,attrs,type):
respon_page = []
if data != None:
soup = BeautifulSoup(data, "html.parser")
ret = soup.select(regx)
for item in ret:
if type == "attribute":
respon_page.append( str(item.attrs[attrs] ))
if type == "text":
respon_page.append(str(item.get_text()))
return respon_page
通过使用上述两个封装函数,读者就可以轻松的实现对特定网页页面元素的定位,首先我们通过CSS属性定位一篇文章中的图片链接,这段代码如下;
if __name__ == "__main__":
# 通过CSS属性定位图片
ref = get_page_attrs("https://www.cnblogs.com/LyShark/p/15914868.html",
"#cnblogs_post_body > p > img",
"src",
5,
"attribute"
)
print(ref)
当上述代码运行后,即可提取出特定网址链接内,属性#cnblogs_post_body > p > img中图片的src属性,并提取出图片属性attribute自身参数。
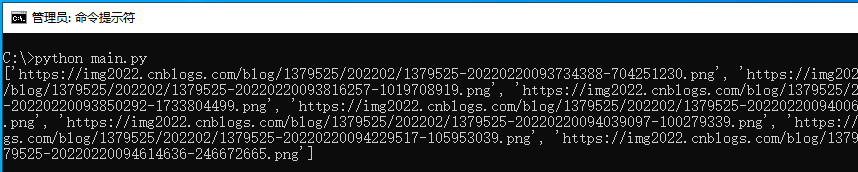
接着我们继续使用该函数实现定位文章列表功能,文章列表的定位同理,此处第二个参数应修改为href属性,如下代码分别使用两种方式实现对文章列表的定位功能;
if __name__ == "__main__":
# 定位文章列表,两种方式均可
ref = get_page_attrs("https://www.cnblogs.com/lyshark",
"#mainContent > div > div > div.postTitle > a",
"href",
5,
"attribute"
)
print(ref)
ref = get_page_attrs("https://www.cnblogs.com/lyshark",
"div[class='day'] div[class='postCon'] div a",
"href",
5,
"attribute"
)
print(ref)
代码运行后即可输出lyshark网站中主页所有的文章地址信息,输出如下图所示;
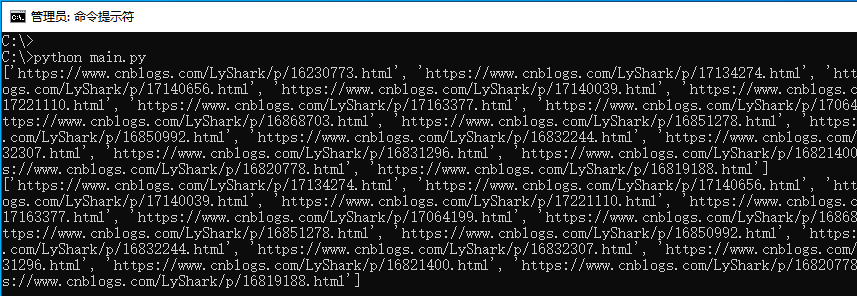
当需要定位文章内容时,我们只需要将第二个属性更改为空格,并将第四个属性修改为text此时则代表只提取属性内的文本。
if __name__ == "__main__":
# 定位文章文本字段
ref = get_page_attrs("https://www.cnblogs.com/lyshark",
"div[class='day'] div[class='postCon'] div[class='c_b_p_desc']",
"",
5,
"text"
)
for index in ref:
print(index)
运行上述代码片段,即可提取出主页中所有的文本信息,如下图所示;
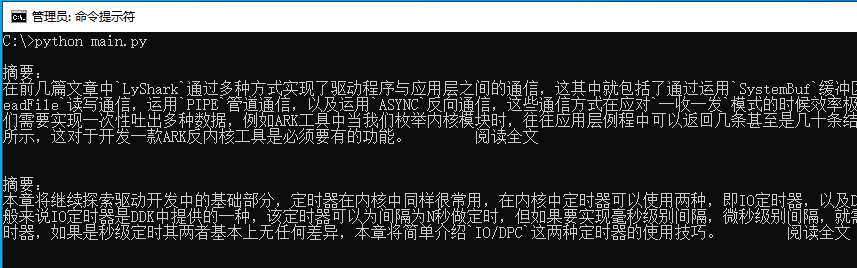
如果需要在同一个页面中多次定位那么就需要使用search_page函数了,如下代码中我们需要在一个页面内寻找两个元素,此时就需要定位两次;
if __name__ == "__main__":
respon = requests.get(url="https://yiyuan.9939.com/yyk_47122/", headers=header, timeout=5)
ref = search_page(respon.text,
"body > div.hos_top > div > div.info > div.detail.word-break > h1 > a",
"",
"text"
)
print(ref)
ref = search_page(respon.text,
"body > div.hos_top > div > div.info > div.detail.word-break > div.tel > span",
"",
"text"
)
print(ref)
代码运行后,即可通过依次请求,分别输出该页面中的两个元素,如下图所示;

21.8.2 查询所有标签
使用find_all函数,可实现从HTML或XML文档中查找所有符合指定标签和属性的元素,返回一个列表,该函数从用于精确过滤,可同时将该页中符合条件的数据一次性全部筛选出来。
其基本语法为:
find_all(name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)
- name:标签名或列表,用于查找指定标签名的元素,如果为 True 或 None,则查找所有标签元素
- attrs:字典,用于指定属性名和属性值,用于查找具有指定属性名和属性值的元素
- recursive:布尔值,表示是否递归查找子标签,默认为 True
- text:字符串或正则表达式,用于匹配元素的文本内容
- limit:整数,限制返回的匹配元素的数量
- kwargs:可变参数,用于查找指定属性名和属性值的元素
我们以输出CVE漏洞列表为例,通过使用find_all查询页面中所有的a标签,并返回一个列表,通过对列表元素的解析,依次输出该漏洞的序号,网址,以及所对应的编号信息。
import re
import requests
from bs4 import BeautifulSoup
header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98"}
# 查找文中 所有a标签 且类名是c_b_p_desc_readmore的 并提取出其href字段
# print(bs.find_all('a',class_='c_b_p_desc_readmore')[0]['href'])
# 提取 所有a标签 且id等于blog_nav_admin 类等于menu 并提取出其href字段
# print(bs.find_all('a',id='blog_nav_admin',class_='menu')[0]['href'])
# print(bs.find_all('a',id='blog_nav_admin',class_='menu')[0].attrs['href'])
if __name__ == "__main__":
url = "https://cassandra.cerias.purdue.edu/CVE_changes/today.html"
new_cve = []
ret = requests.get(url=url, headers=header, timeout=5)
soup = BeautifulSoup(ret.text, 'html.parser')
for index in soup.find_all('a'):
href = index.get('href')
text = index.get_text()
cve_number = re.findall("[0-9]{1,}-.*",index.get_text())
print("序号: {:20} 地址: {} CVE-{}".format(text,href,cve_number[0]))
读者可自行运行上述代码,即可匹配出当前页面中所有的CVE漏洞编号等,如下图所示;
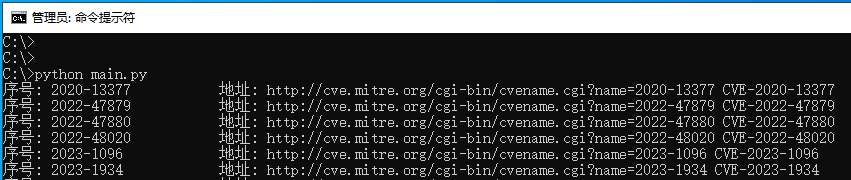
21.8.3 取字串返回列表
在BeautifulSoup4中,stripped_strings是一个生成器对象,用于获取HTML标签内所有文本内容的迭代器。它会自动去除每个文本的前后空格和换行符,只返回纯文本字符串。stripped_strings可以用于处理HTML文档中的多行文本、空格等特殊符号,也可用于将元素下面的所有字符串以列表的形式返回。
import requests
from bs4 import BeautifulSoup
header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98"}
if __name__ == "__main__":
ret = requests.get(url="https://www.cnblogs.com/lyshark", headers=header, timeout=3)
text = str(ret.content.decode('utf-8'))
bs = BeautifulSoup(text, "html.parser")
ret = bs.select('#mainContent > div > div > div.postTitle > a > span')
for i in ret:
# 提取出字符串并以列表的形式返回
string_ = list(i.stripped_strings)
print(string_)
运行后即可获取选中元素的字符串内容,并通过list将其转换为列表格式,如下图所示;
通过find_all以及stripped_strings属性我们实现一个简单的抓取天气的代码,以让读者可以更好的理解该属性是如何被使用的,如下代码所示;
from bs4 import BeautifulSoup
import requests
head = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
ret = requests.get(url="http://www.weather.com.cn/textFC/beijing.shtml", headers=head, timeout=3)
text = str(ret.content.decode('utf-8'))
bs = BeautifulSoup(text,"html.parser")
# 定位到第一个标签上
bs.find_all('div',class_='conMidtab')[1]
# 在conMidtab里面找tr标签并从第3个标签开始保存
tr = bs.find_all('tr')[2:]
for i in tr:
# 循环找代码中的所有td标签
td = i.find_all('td')
# 找所有的td标签,并找出第一个td标签
city_td = td[0]
# 获取目标路径下所有的子孙非标签字符串,自动去掉空字符串
city = list(city_td.stripped_strings)[0]
# 取出度数的标签
temp = td[-5]
temperature = list(temp.stripped_strings)[0]
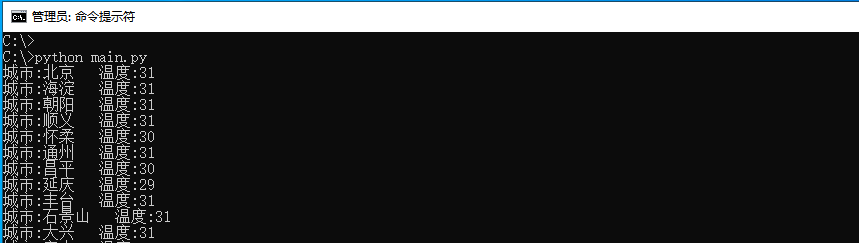
print('城市:{} 温度:{}'.format(city,temperature))
我们以提取北京天气为案例,当运行代码后即可取出北京市所有地区的气温数据,如下图所示;
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/ac89ee84.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!




![[ubuntu系统下的文本编辑器nano,vim,gedit,文件使用,以及版本更新问题]](https://img-blog.csdnimg.cn/d67618acd4a848a7a3b5d4b72b0176f6.png)