一、写在前面
突发奇想,想批量下载Alphafold网站的蛋白pdb文件,后续再做个分子对接用。又不想手动下载,来求助CSDN和GPT。
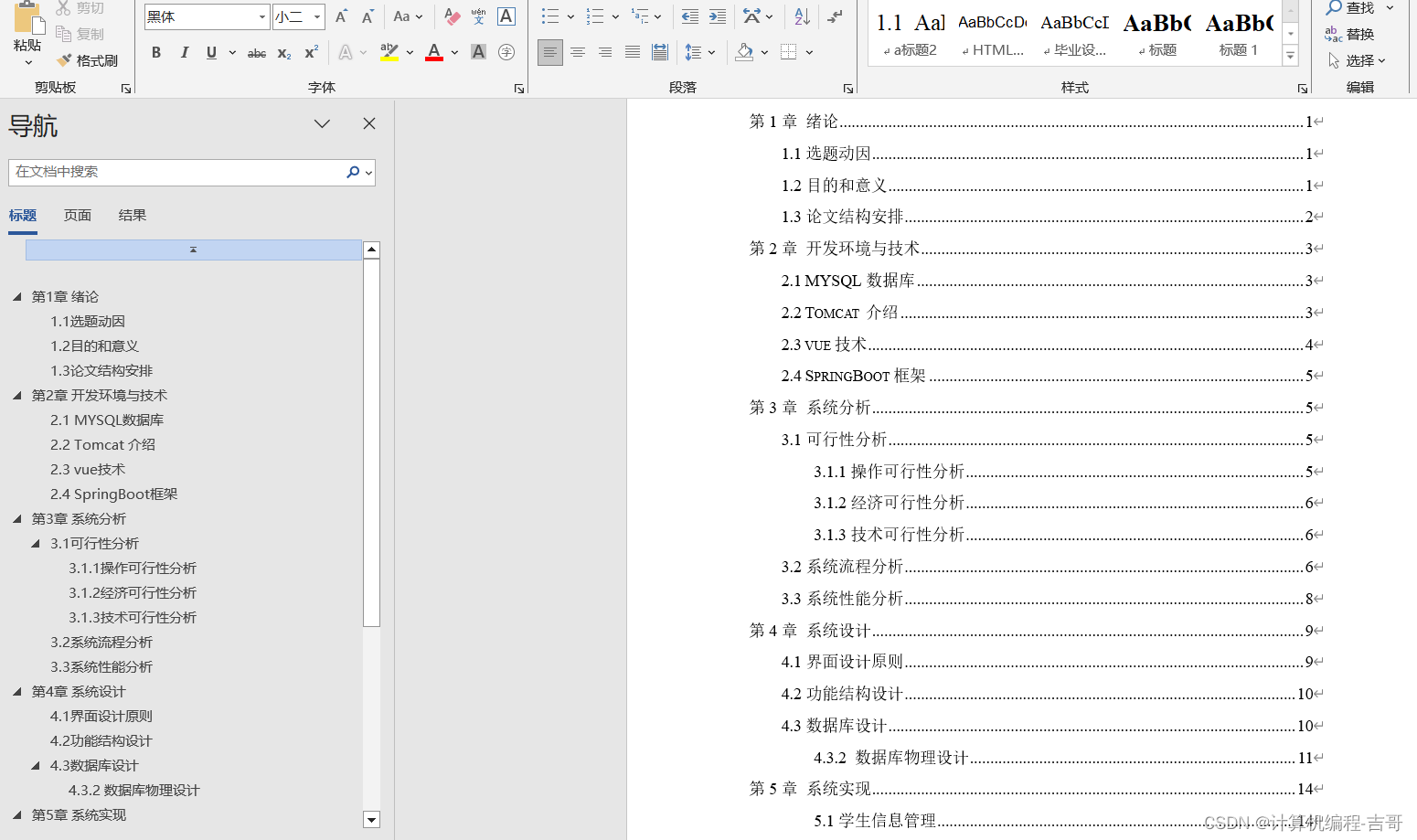
二、CSDN白嫖基础代码
CSDN大神多,这不,找到一个:
Alphafold批量下载蛋白的pdb文件_pdb文件下载-CSDN博客
不过使用的是谷歌浏览器,我自己用的是Edge浏览器,因此需要魔改。
三、GPT魔改代码
话不多说,直接上步骤。
(1)安装Selenium包
selenium是自动化测试工具,可以理解为Python使用它来操作网页。
安装代码:
pip install selenium 或者
conda install selenium(2)安装Selenium驱动
Selenium需要一个驱动程序来与所选的浏览器交互,不同浏览器驱动不同。
我的是Edge浏览器,下载地址:
Microsoft Edge WebDriver - Microsoft Edge Developer
当然,是有版本区别的,因此,先看看我们的版本号:

下载相应版本的驱动:

解压,但是要记住放的路劲地址,比如我的是:O:/msedgedriver.exe。
(3)GPT魔改后的代码
咒语要点主要是告诉GPT我们使用的是Edge浏览器、驱动放置的地点等,经过几轮Debug,代码如下:
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver import EdgeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Constants
EDGE_DRIVER_PATH = r'O:/msedgedriver.exe'
WORK_PATH = r"O:/"
PROTEIN_FILE = "test1.txt"
XPATH_DOWNLOAD_LINK = "//*[@id=\"main-content-area\"]/app-entry/div[1]/div/app-summary-text/div/div[1]/div[2]/a[1]"
PAGE_LOAD_TIMEOUT = 2500
EXPLICIT_WAIT_TIMEOUT = 30 # 设置显式等待的超时时间
# Edge Options
edge_options = EdgeOptions()
# edge_options.add_argument('--headless')
edge_options.add_argument('--disable-gpu')
service = Service(executable_path=EDGE_DRIVER_PATH)
# Change working directory
os.chdir(WORK_PATH)
# Read proteins from file
with open(PROTEIN_FILE, "r") as f:
proteins = [line.strip() for line in f.readlines()]
failed_downloads = []
# Initialize browser instance
with webdriver.Edge(service=service, options=edge_options) as driver:
driver.set_page_load_timeout(PAGE_LOAD_TIMEOUT)
wait = WebDriverWait(driver, EXPLICIT_WAIT_TIMEOUT)
for protein_id in proteins:
print(f"{protein_id} is downloading!")
driver.get(f"https://alphafold.ebi.ac.uk/entry/{protein_id}")
try:
download_link = wait.until(EC.element_to_be_clickable((By.XPATH, XPATH_DOWNLOAD_LINK)))
download_link.click()
time.sleep(4) # Wait for the file to download
print(f"{protein_id} succeed!")
except Exception as e:
print(f"{protein_id} download failed!")
failed_downloads.append(protein_id)
# Write failed downloads to file
with open("failed.txt", "w") as df:
df.write("\n".join(failed_downloads))(4)运行
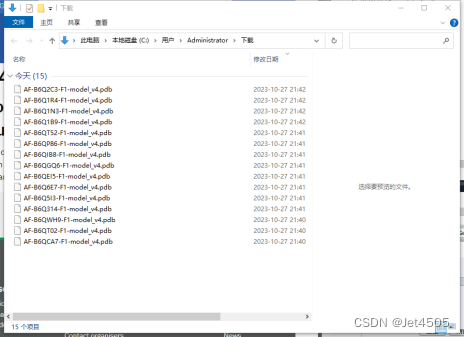
首先,把需要下载的蛋白的Uniport的ID整理到一个txt文件,蛋白后面不要有空格,一个蛋白一行!!!我的保存路劲为:O:/。

准备就绪,运行代码:
批量下载Alphafold的蛋白pdb文件
可以看到,自动打开网页,点击下载,简单粗暴有内涵~