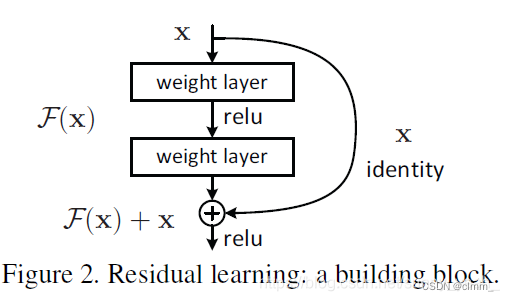
什么是Resnet?
resnet是一种残差网络,简单看一下resnet的结构
上面是ResNet,下面是传统的

ResNet里的一小块就是这样的
为什么要引入ResNet?
理论上讲,随着网络加深,我们获取的信息越来越多多,特征也越来越丰富,性能应该越来越好才对。但实际上,随着网络加深,性能反而下降(如图)

为什么呢?
这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
这个问题可以用归一化操作解决,但这个方法仅对几十层的网络有用,更深的话就没用了。
于是乎有了ResNet。
ResNet详细解释
ResNet有两种,左边的残差结构叫BasicBlock,右边的残差结构叫Bottleneck
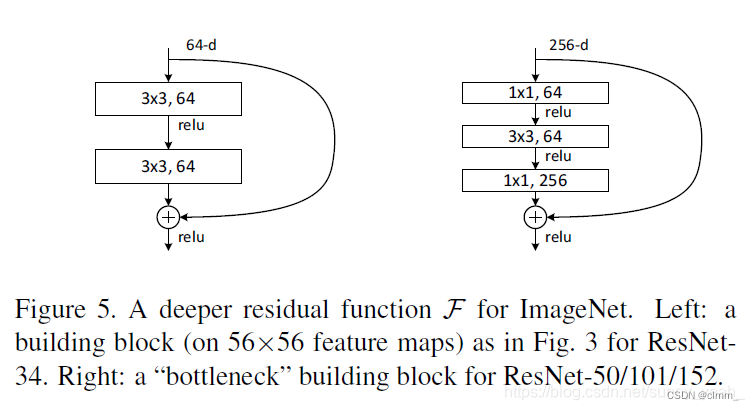
BasicBlock
经过前面若干步处理后传递过来的数值叫x,然后分为两路,
支路直接将x传递到下面(便于一会相加),称作跳跃连接(skip connection)。
主路经过函数F(x)的计算,得到的结果叫做F(x),然后与刚刚的x相加,即F(x)+x。
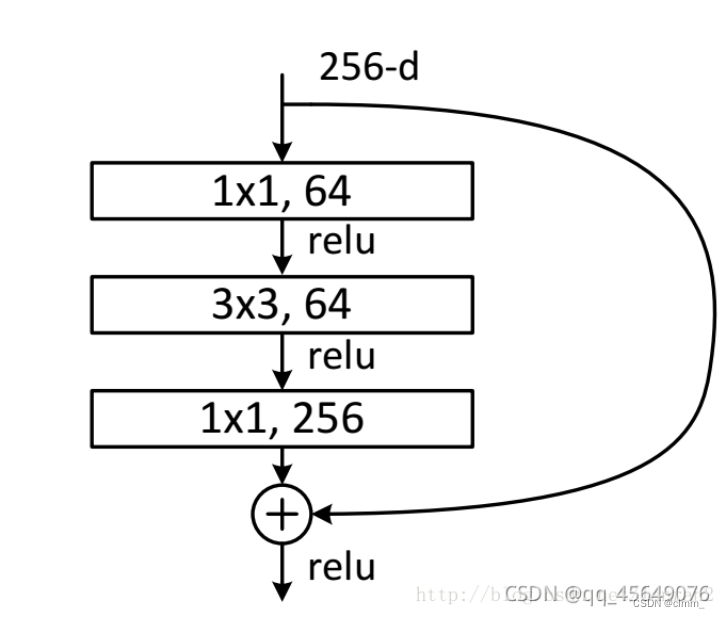
Bottleneck
其中第一层的1× 1的卷积核的作用是对特征矩阵进行降维操作,将特征矩阵的深度由256降为64;
第三层的1× 1的卷积核是对特征矩阵进行升维操作,将特征矩阵的深度由64升成256。
为什么要降维?
降低特征矩阵的深度主要是为了减少参数的个数。
为什么要升维?
为了恢复特征图尺度,以便进行加法操作
什么是反向传播?
反向传播的作用是实现参数的优化和学习,以最小化损失函数。
具体来说,反向传播通过计算损失函数对网络参数的梯度,将梯度从输出层向输入层进行传播
什么是梯度值,梯度消失,梯度爆炸?
梯度值是指在机器学习和深度神经网络中,用于表示损失函数相对于模型参数的变化率或斜率。梯度值可以告诉我们在当前参数设置下,目标函数朝着哪个方向变化最快,以及变化的速率。
梯度爆炸(Gradient Explosion)指的是在反向传播过程中,梯度值变得非常大。这可能导致权重更新过大,使模型参数迅速偏离理想状态,导致训练不稳定甚至无法收敛。类似于一个雪球越滚越大,最终无法控制。
梯度消失(Gradient Vanishing)则相反,指的是在反向传播过程中,梯度值变得非常小。这意味着在网络的较深层中,梯度信息逐渐减弱,无法有效地传递到较浅的层,导致浅层网络参数无法得到有效的更新。这使得网络较深的部分很难学习到有用的特征,限制了模型的表达能力。
(深层将信息传递给浅层时,梯度太小,无法有效传递,进而无法有效更新浅层)