论文阅读——GPT3
news2026/2/14 1:10:23



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1141572.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
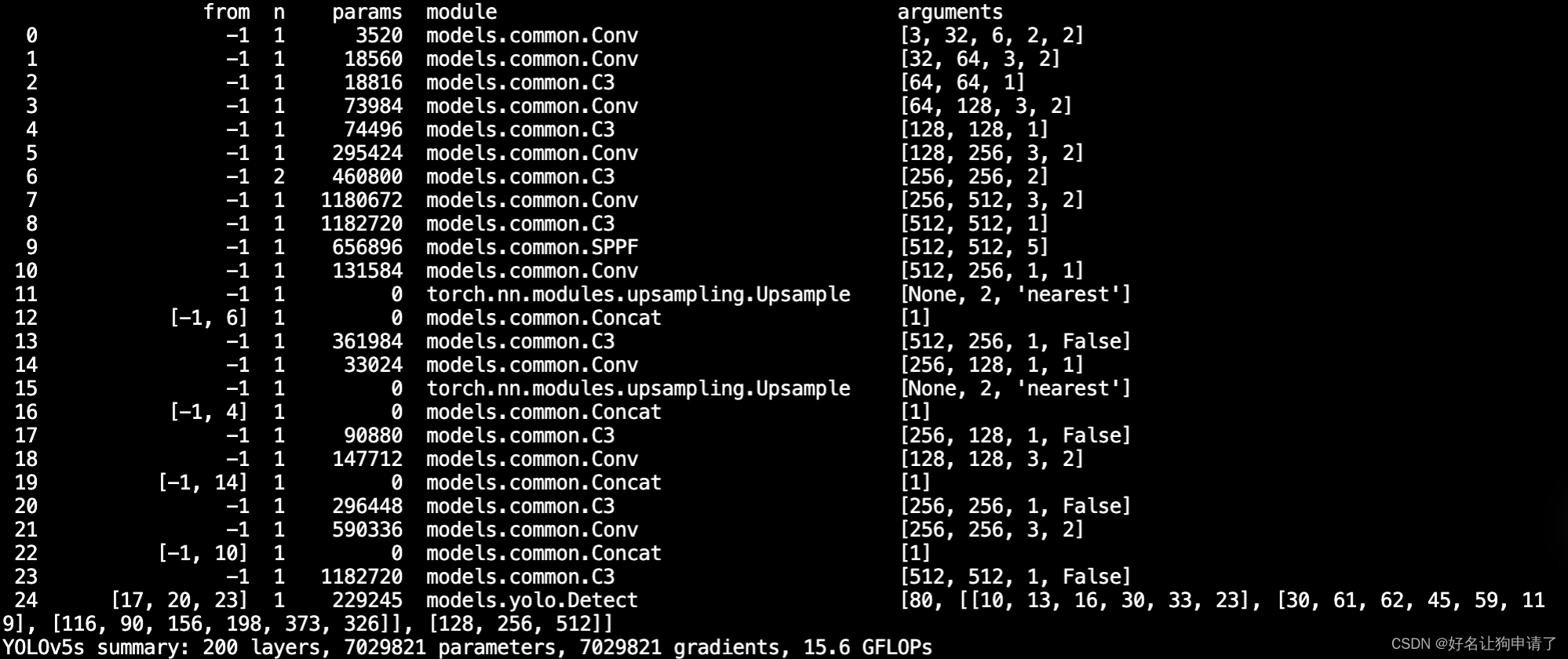
YOLOv5配置文件之 - yaml
在YOLOv5的目录中,models文件夹里存储了YOLO的模型配置。 ./models/yolov5.yaml 定义了YOLOv5s网络结构的定义文件
yaml的主要内容
参数配置
nc: 80 类别数量 depth_multiple: 0.33 模型深度缩放因子 width_multiple: 0.50 控制卷积特征图的通道个数
anchors配…

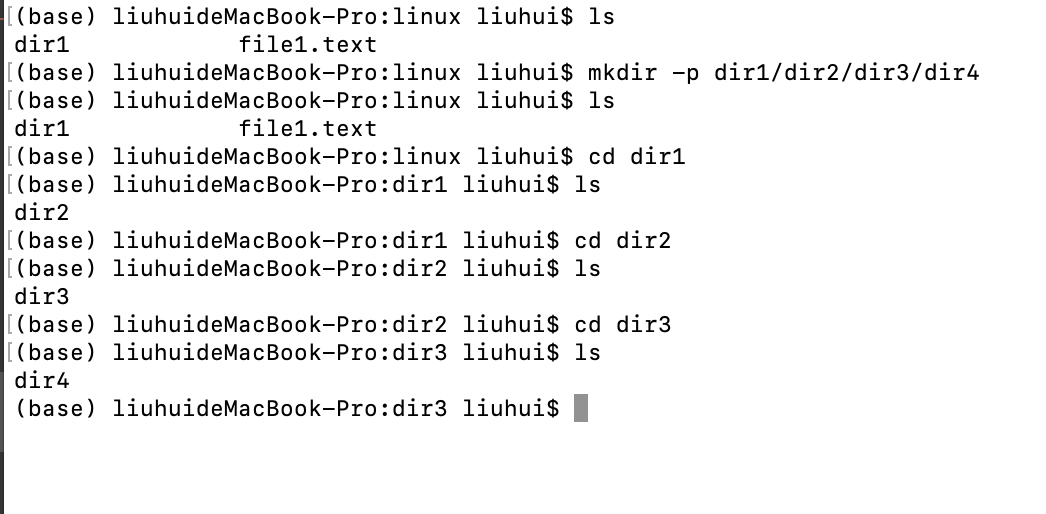
Linux mkdir命令:创建目录(文件夹)
mkdir 命令,是 make directories 的缩写,用于创建新目录,此命令所有用户都可以使用。mkdir 命令的基本格式为: [rootlocalhost ~]# mkdir [-mp] 目录名 -m 选项用于手动配置所创建目录的权限,而不再使用默认权限。 -p…


1624. 两个相同字符之间的最长子字符串
1624. 两个相同字符之间的最长子字符串 java代码:
class Solution {public int maxLengthBetweenEqualCharacters(String s) {int[] hash new int[26];Arrays.fill(hash, -1); // fill是Arrays静态方法int max -1;for (int i 0; i < s.length(); i) { // 对…
计算机毕业设计 基于SpringBoot大学生创新创业项目管理系统的设计与实现 Javaweb项目 Java实战项目 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…
ResNet简单解释
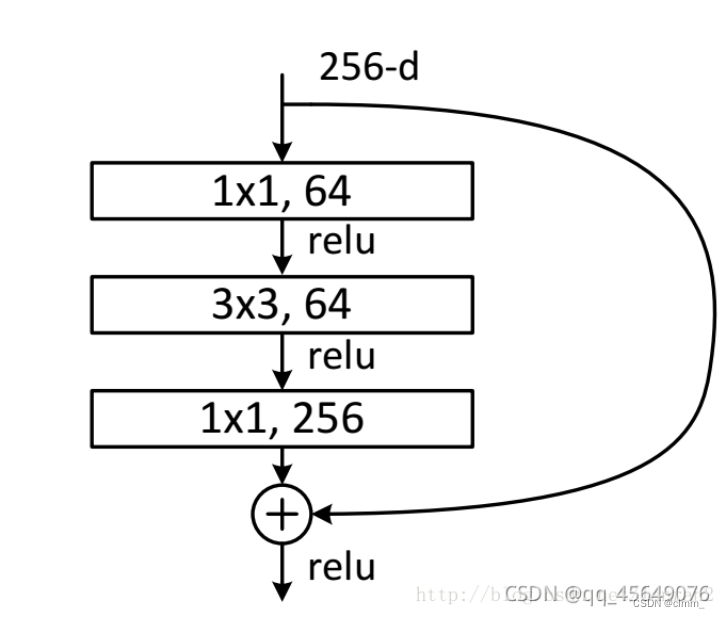
什么是Resnet?
resnet是一种残差网络,简单看一下resnet的结构
上面是ResNet,下面是传统的 ResNet里的一小块就是这样的 为什么要引入ResNet?
理论上讲,随着网络加深,我们获取的信息越来越多多࿰…
C语言 每日一题 PTA 10.27 day5
1.高速公路超速处罚
按照规定,在高速公路上行使的机动车,达到或超出本车道限速的10 % 则处200元罚款; 若达到或超出50 % ,就要吊销驾驶证。请编写程序根据车速和限速自动判别对该机动车的处理。 输入格式 : 输入在一行中给出2个正…
构造类型详解及热门题型结构体大小的计算
在编写程序时,简单的变量类型已经不能满足程序中各种复杂数据的需求,因此c语言还提供了构造类型的数据,构造数据是有基本数据按照一定的规则组成的。
目录
结构体类型的概念
结构体变量的定义
结构体变量的初始化
结构体变量的引用
结构…

老年少女测试媛入职感想
作为一枚从事通信行业测试的老年少女测试媛,入职离职也有两三次了。现在又在一家企业入职了。虽然心里也清楚离职和入职,无非也就是从一个公司的坑里跳出来,再跳到另外一个公司的坑里罢了,明明知道老东家的坑是填不完的了…

【Java 进阶篇】Java Request 获取请求头数据详解
在Java Web开发中,获取HTTP请求的请求头数据是一项常见任务。HTTP请求的请求头包含了客户端发送给服务器的额外信息,这些信息对于服务器来说很重要,因为它们可以包含用户代理、授权信息、Cookies等内容。在Java中,可以使用HttpSer…
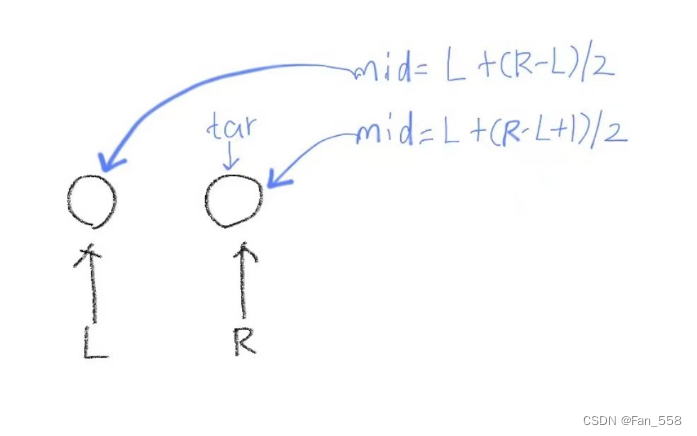
二分查找法(查找左右端点)
前言
本文将会向您介绍二分查找法(查找左右端点),关于朴素的二分查找法已经在之前讲过了朴素二分查找您可以点此超链接
查找右端点
如果您仅仅是想要参考如何查找左右端点,可以直接跳转到下文的模板处 ps:以下是本…

Linux常用的指令(2023.10.27)
文章目录 查看目录下文件的大小虚拟环境相关删除虚拟环境多版本的cuda切换修改虚拟环境名称 文件的移动、删除和复制文件的复制文件的删除文件的移动 查看目录下文件的大小
du(disk usage 磁盘使用率)命令查看当前目录和子目录文件夹、文件大小情况
du …

YOLOv7优化:渐近特征金字塔网络(AFPN)| 助力小目标检测
💡💡💡本文改进:渐近特征金字塔网络(AFPN),解决多尺度削弱了非相邻 Level 的融合效果。
AFPN | 亲测在多个数据集能够实现涨点,尤其在小目标数据集。 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现
🚀🚀🚀…
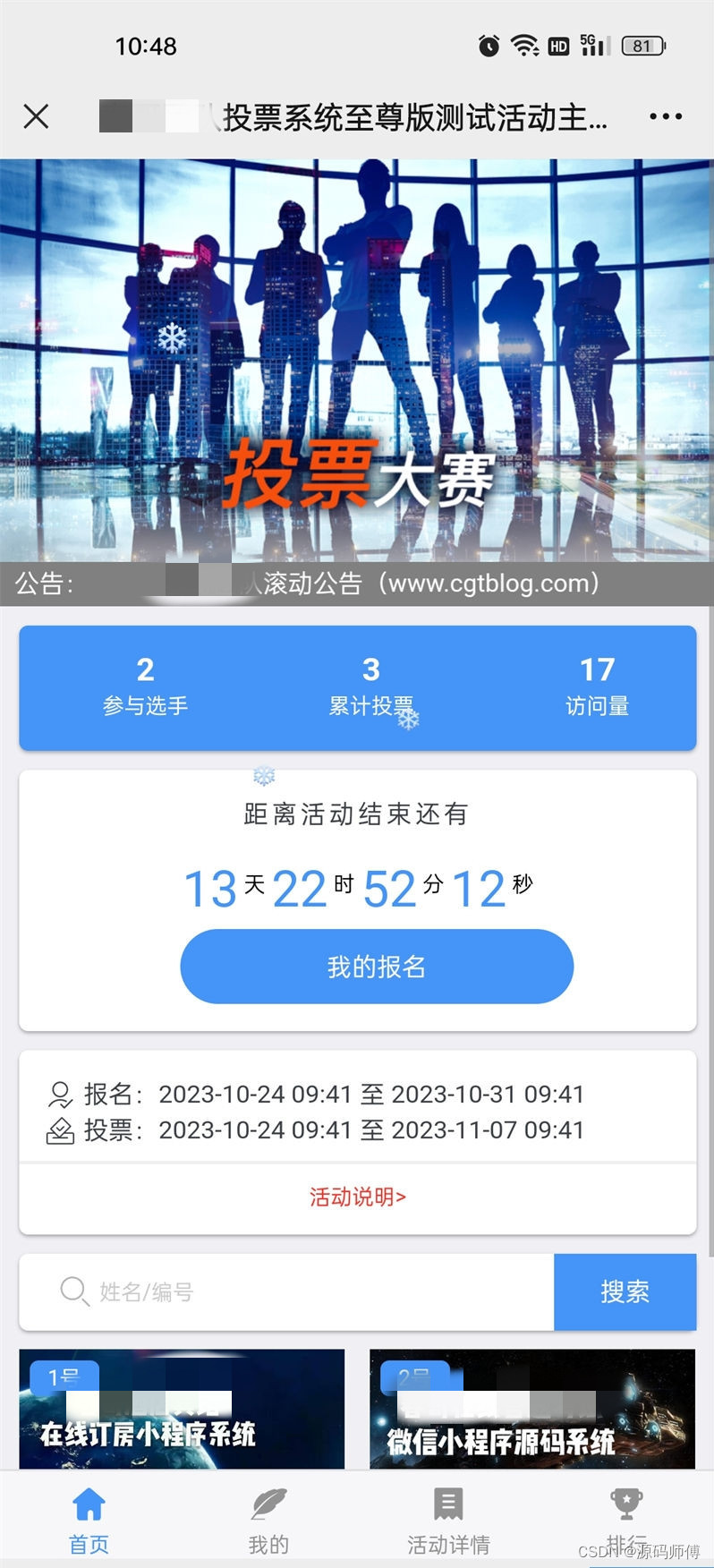
开源投票系统源码至尊版带礼物道具 无限多开 盈利模式超丰富
网络投票系统已经成为各种活动、比赛、评选等场景中不可或缺的一部分。春哥团队开源投票系统源码至尊版是一种功能强大、灵活可定制的投票系统,不仅具有高度的安全性和稳定性,还支持多种盈利模式,含完整版代码包,支持投票礼物道具…
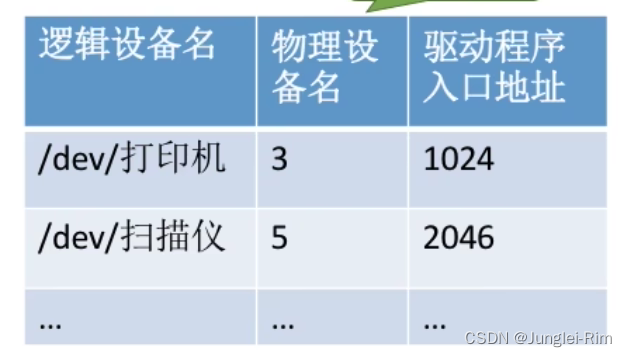
设备的分配与回收(考虑因素,数据结构,分配步骤)
目录 1.设备分配时应考虑的因素1.设备的固有属性2.设备分配算法3.设备分配中的安全性1.安全分配方式2.不安全分配方式 2.静态分配与动态分配3.设备分配管理中的数据结构1.“设备、控制器、通道”之间的关系2.设备控制表(DCT)3.控制器控制表(COCT)4.通道控制表&#…
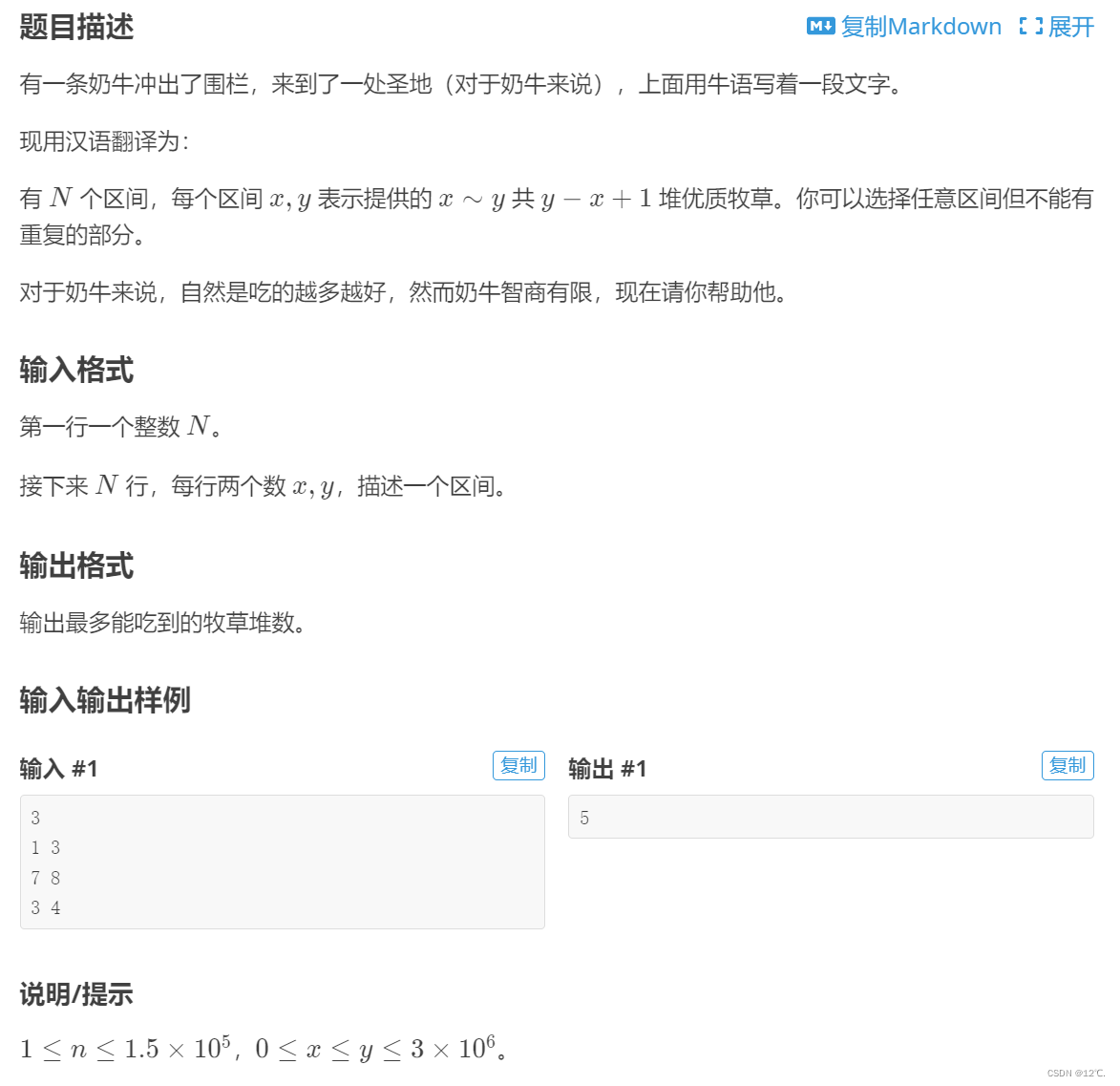
P1868 饥饿的奶牛
根据题意可以知道是一个动态规划,看完数据范围之后可以知道是一个线性DP。
解决方法有点类似于背包问题,枚举背包的每一个空间。
如果把坐标轴上每个点都看成一个块儿,只需要按顺序求出前 i 个块儿的最大牧草堆数,f[i] 就是前i的…
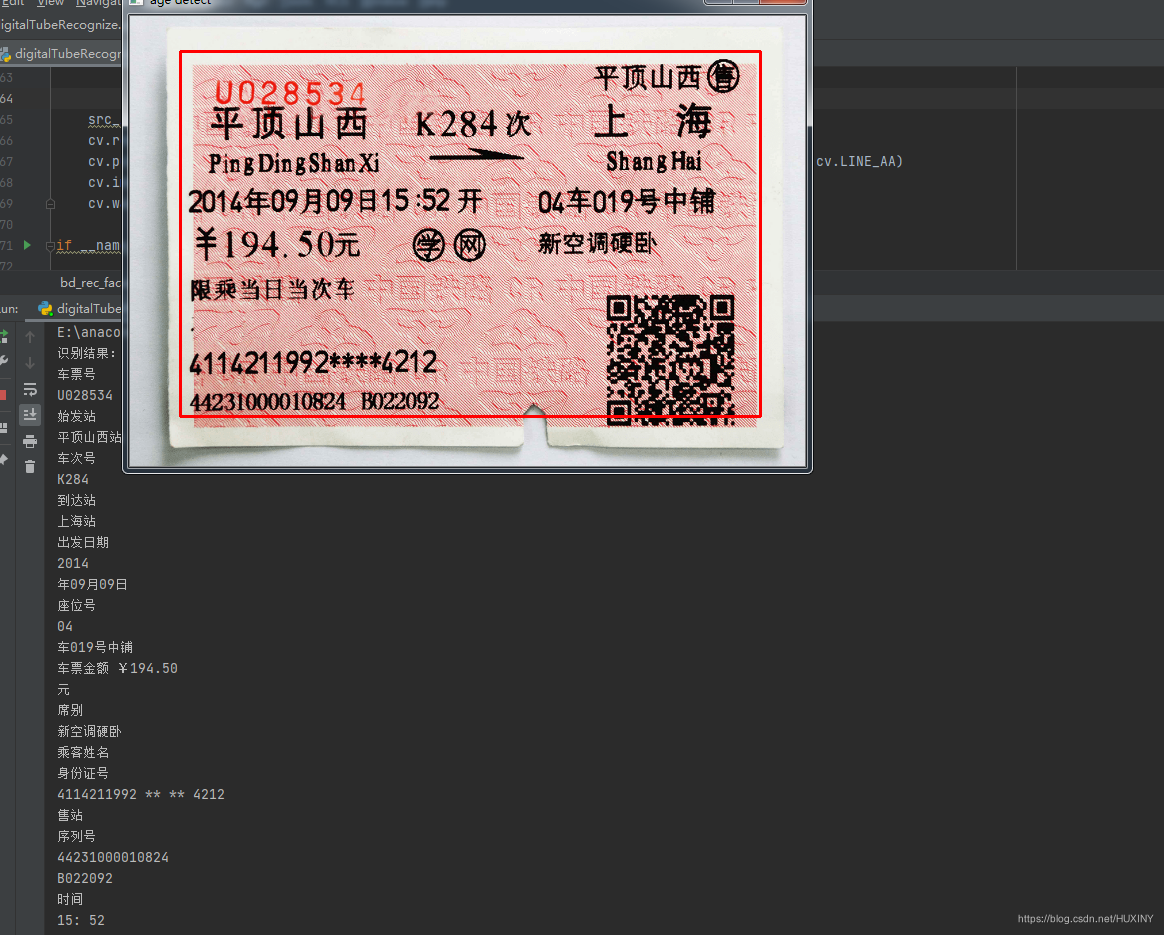
基于机器视觉的火车票识别系统 计算机竞赛
文章目录 0 前言1 课题意义课题难点: 2 实现方法2.1 图像预处理2.2 字符分割2.3 字符识别部分实现代码 3 实现效果最后 0 前言
🔥 优质竞赛项目系列,今天要分享的是
基于机器视觉的火车票识别系统
该项目较为新颖,适合作为竞赛…

BUUCTF zip伪加密 1
BUUCTF:https://buuoj.cn/challenges
题目描述: 下载附件,得到一个zip压缩包。 密文:
解题思路: 1、刚开始尝试解压,看到了flag.txt文件,但需要解压密码。结合题目,确认这是zip伪加密&#…
【0基础学Java第一课】-- 初始Java
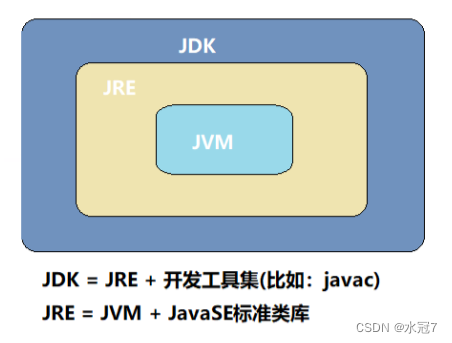
目录 1. 初识java1.1 Java是什么1.2 Java应用领域1.3 Java语言发展简史1.4 Java语言特性1.5 JRE与JDK1.6 Java开发环境1.6.1 安装JDK1.6.2 配置环境变量 1.7 初始Java中main函数1.7.1 JDK、JRE、JVM之间的关系 1.8 注释1.9 标识符1.10 关键字 1. 初识java
1.1 Java是什么
Jav…