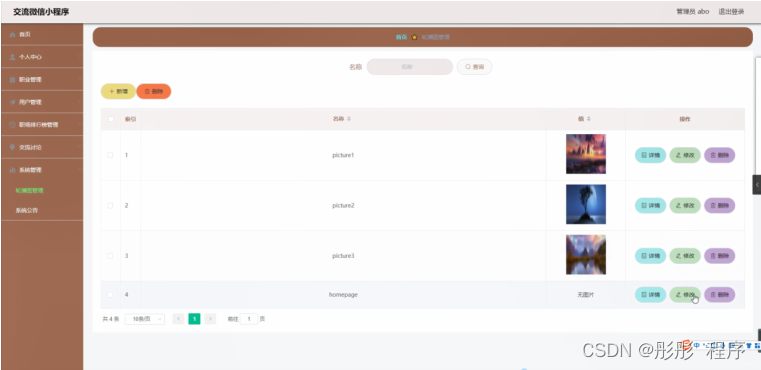
基本原理
特征网络
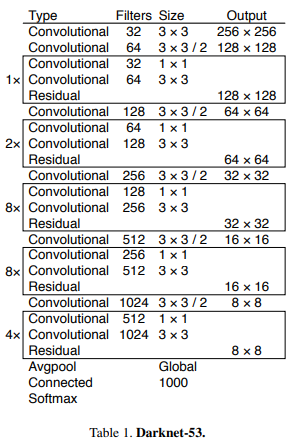
输入输出
输入
416
∗
416
∗
3
416*416*3
416∗416∗3大小的图片(不唯一,但图片大小必为32的倍数),输出3个尺度的feature map,分别为
13
∗
13
∗
255
13*13*255
13∗13∗255,
26
∗
26
∗
255
26*26*255
26∗26∗255,
52
∗
52
∗
255
52*52*255
52∗52∗255,即分成
13
∗
13
13*13
13∗13,
26
∗
26
26*26
26∗26,
52
∗
52
52*52
52∗52个grid cell.
每个grid cell生成3个anchor,每个anchor对应一个预测框,每个预测框有
5
+
80
5+80
5+80个参数,
{
(
x
,
y
,
w
,
h
,
c
)
,
80
k
i
n
d
s
o
f
c
l
a
s
s
}
\{(x,y,w,h,c),80 \space kinds \space of \space class\}
{(x,y,w,h,c),80 kinds of class}
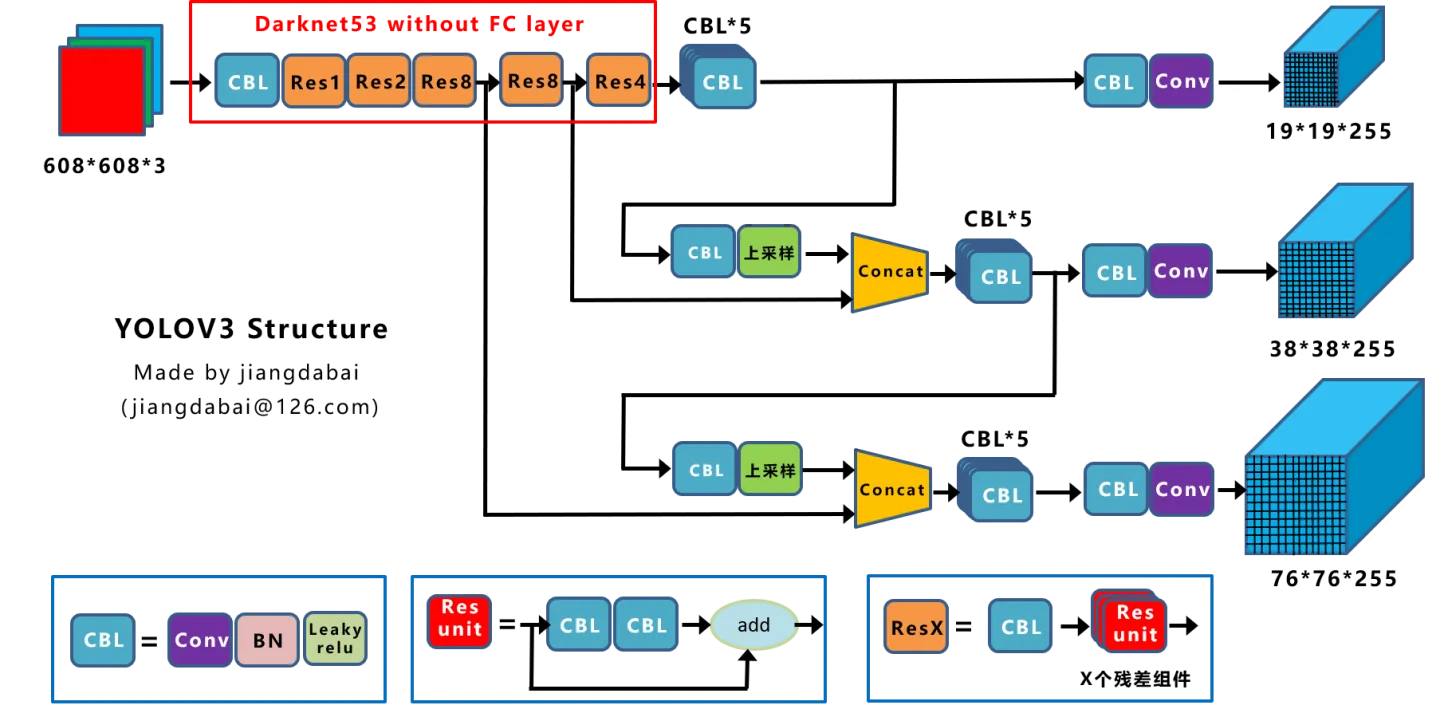
输出分析
(该图取自知乎博主)
13
∗
13
∗
255
13*13*255
13∗13∗255,
26
∗
26
∗
255
26*26*255
26∗26∗255,
52
∗
52
∗
255
52*52*255
52∗52∗255分别预测大,中,小物体。
13
∗
13
∗
255
13*13*255
13∗13∗255为下采样32倍得到的特征;
26
∗
26
∗
255
26*26*255
26∗26∗255为下采样16倍与
13
∗
13
13*13
13∗13一次上采样结合得到的特征;
52
∗
52
∗
255
52*52*255
52∗52∗255为下采样8倍与
26
∗
26
26*26
26∗26一次上采样结合得到的特征;
正负样本
正样本为anchor与真实框的IOU大于指定阈值,且最大IOU的anchor;
负样本为anchor与真实框IOU小于指定阈值的anchor。
损失函数
由正样本的坐标损失、置信度损失和类别损失,负样本的置信度损失构成。
λ
c
o
o
r
d
∑
i
=
0
S
2
∑
J
=
0
B
1
i
,
j
o
b
j
[
(
b
x
−
b
x
^
)
2
+
(
b
y
−
b
y
^
)
2
+
(
b
w
−
b
w
^
)
2
+
(
b
h
−
b
h
^
)
2
]
+
∑
i
=
0
S
2
∑
J
=
0
B
1
i
,
j
o
b
j
[
−
l
o
g
(
p
c
)
+
∑
i
=
1
n
B
C
E
(
c
i
,
c
i
^
)
]
+
λ
n
o
o
b
j
∑
i
=
0
S
2
∑
J
=
0
B
1
i
,
j
n
o
o
b
j
[
−
l
o
g
(
1
−
p
c
)
]
\lambda_{coord} \sum_{i=0}^{S^2}\sum_{J=0}^{B}1_{i,j}^{obj}[(b_x-\hat{b_x})^2+(b_y-\hat{b_y})^2+(b_w-\hat{b_w})^2+(b_h-\hat{b_h})^2]\\+\sum_{i=0}^{S^2}\sum_{J=0}^{B}1_{i,j}^{obj}[-log(p_c)+\sum_{i=1}^{n}BCE(c_i,\hat{c_i})]\\+\lambda_{noobj}\sum_{i=0}^{S^2}\sum_{J=0}^{B}1_{i,j}^{noobj}[-log(1-p_c)]
λcoordi=0∑S2J=0∑B1i,jobj[(bx−bx^)2+(by−by^)2+(bw−bw^)2+(bh−bh^)2]+i=0∑S2J=0∑B1i,jobj[−log(pc)+i=1∑nBCE(ci,ci^)]+λnoobji=0∑S2J=0∑B1i,jnoobj[−log(1−pc)]
S
2
S^2
S2为grid cell的总数,
B
B
B为每一个grid cell的anchor数目。
第一行为计算正样本的坐标与真实框的坐标损失;
第二行为计算正样本的置信度和类别损失,
1
i
,
j
o
b
j
1_{i,j}^{obj}
1i,jobj表示是否为正样本;
−
l
o
g
(
p
c
)
-log(p_c)
−log(pc)中,若
p
c
p_c
pc越接近于1,则
−
l
o
g
(
p
c
)
-log(p_c)
−log(pc)越接近于0;类别损失中,对于检测的80类,每一个类别进行二叉熵损失运算。
第三行为负样本的置信度损失,
−
l
o
g
(
1
−
p
c
)
-log(1-p_c)
−log(1−pc)中
p
c
p_c
pc越接近于0,该式越小,接近于0
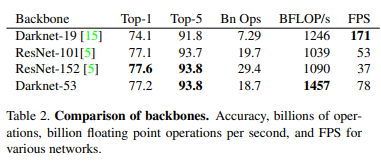
性能


![gerber 文件格式 [一]](https://img-blog.csdnimg.cn/4c65cb8778694172ac1b7fa96293ccfd.png)