1. 介绍
在过去几年里,NAS技术取得了长足进展。然而,由于搜索约束与实际推理之间的差异导致高效网络搜索仍极具挑战性。为搜索一个具有高性能、低推理延迟的模型,已有方案往往在算法中添加计算复杂度约束。然而,推理速度会受多种因此影响,如FLOPs、MACs等,单一因素相关性可能并不强。
近来,重参数技术旨在将多分支结构转换成推理友好的单分支架构。尽管如此,训练阶段的多分支架构仍是人工设计的,较为低效。
本文提出提出一种适合于结构重参数技术的搜索空间,提出了一阶段NAS方法RepNAS对每一层在分支数量约束下进行ODBB(Optimal Diverse Branch Block)搜索。实验结果表明:搜索到的ODBB可以轻易超越人工设计的DBB,同时训练高效。

本文贡献主要包含以下几点:
- 提出了一种Rep搜索空间,它使得所搜到的模型在训练阶段保持任意分支结构,而在推理阶段融合为单分支结果。
- 为利用上述搜索空间,提出了一种一阶段NAS方案RepNAS;
- 实验结果表明:搜索的ODDB具有比人工设计DBB和NAS模型更优性能。
2. 重参数化网络结构搜索
我们首先对所提RepNAS进行整体性介绍并讨论与其他NAS方案的区别,然后提出一种基于Rep技术的搜索空间,最后提出RepNAS方法以适配该搜索空间。
2.1 概述
Rep技术旨在通过插入多分支结构提升CNN的训练效率,所插入的多分支结构在完成训练后可以进行融合且不会造成任何性能损失、复杂度提升。然而,多分支结构训练会占据大量GPU显存,进而导致无法进行过多分支模型优化。所提方法的核心在于:以可微分方式对某些不重要分支进行剪枝,参见下图。
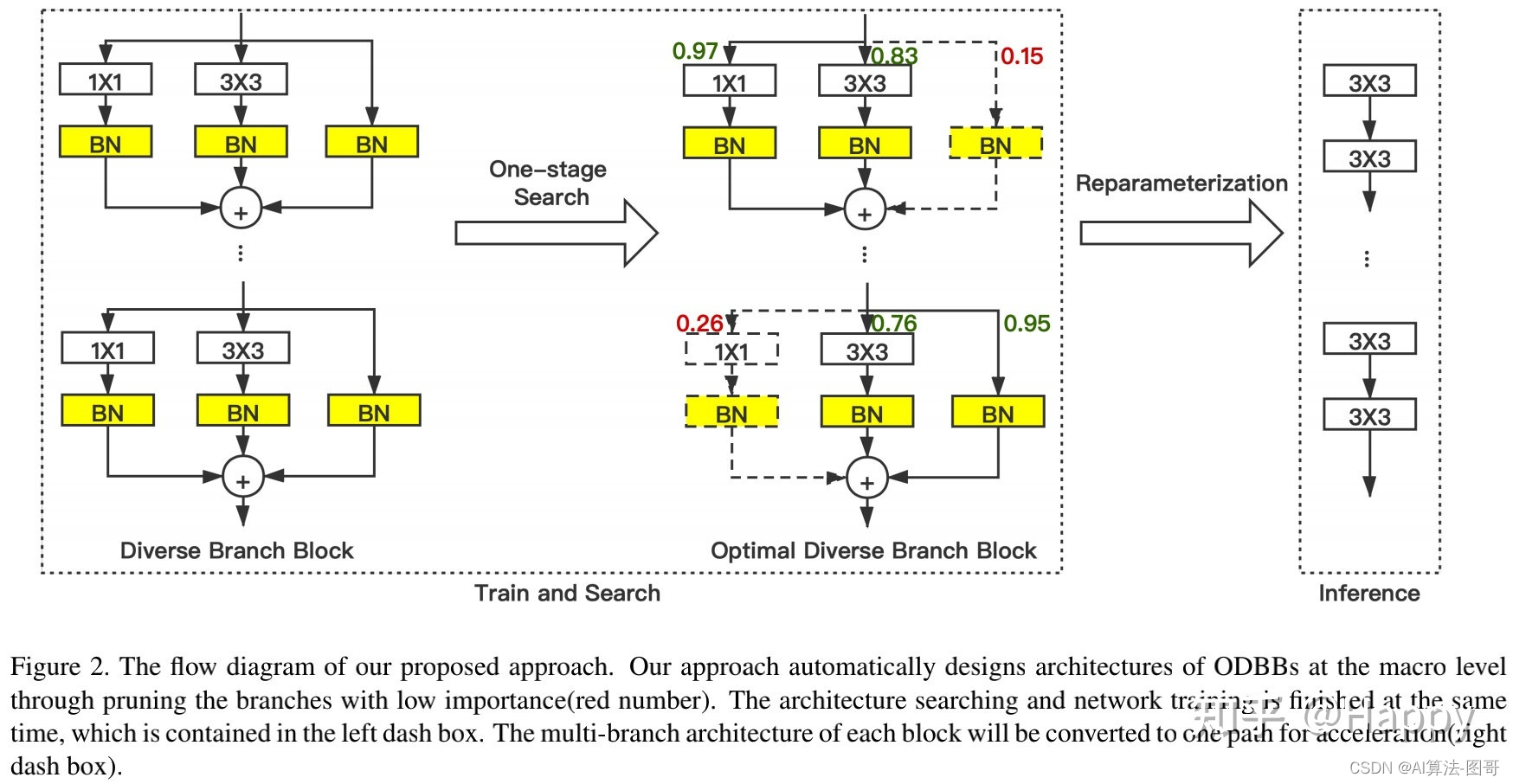
该剪枝过程有两个重要步骤:
- 给定CNN架构(比如MobileNet、VGG),我们在原始卷积操作基础上插入多个线性操作。对每个分支而言,它还存在一个可学习参数用于表征分支重要性。在训练阶段,我们同时对架构参数与与网络参数进行优化。在完成训练后,我们得到一个具有最优网络参数的剪枝架构。
- 在推理阶段,残留分支可以直接融合到原始卷积操作中,即多分支转换成单分支结构且不会造成性能损失。
相比其他NAS架构,RepNAS中不再包含复杂的多分支结构与跳过连接。相比之前的结构重参数方案,RepNAS中每一层的模块通过NAS自适应决定,而无需人工介入。
2.2 搜索空间设计
NAS方案通常需要在DARTS空间或MobileNet-like空间进行最优子网络搜索,前者包含多分支结构,这使得所搜到的架构具有更大推理延迟;而后者则通过专家经验设计搜索空间,并未引入多分支架构。已有研究表明:多分支架构可以通过增强特征表达能力提升模型性能。
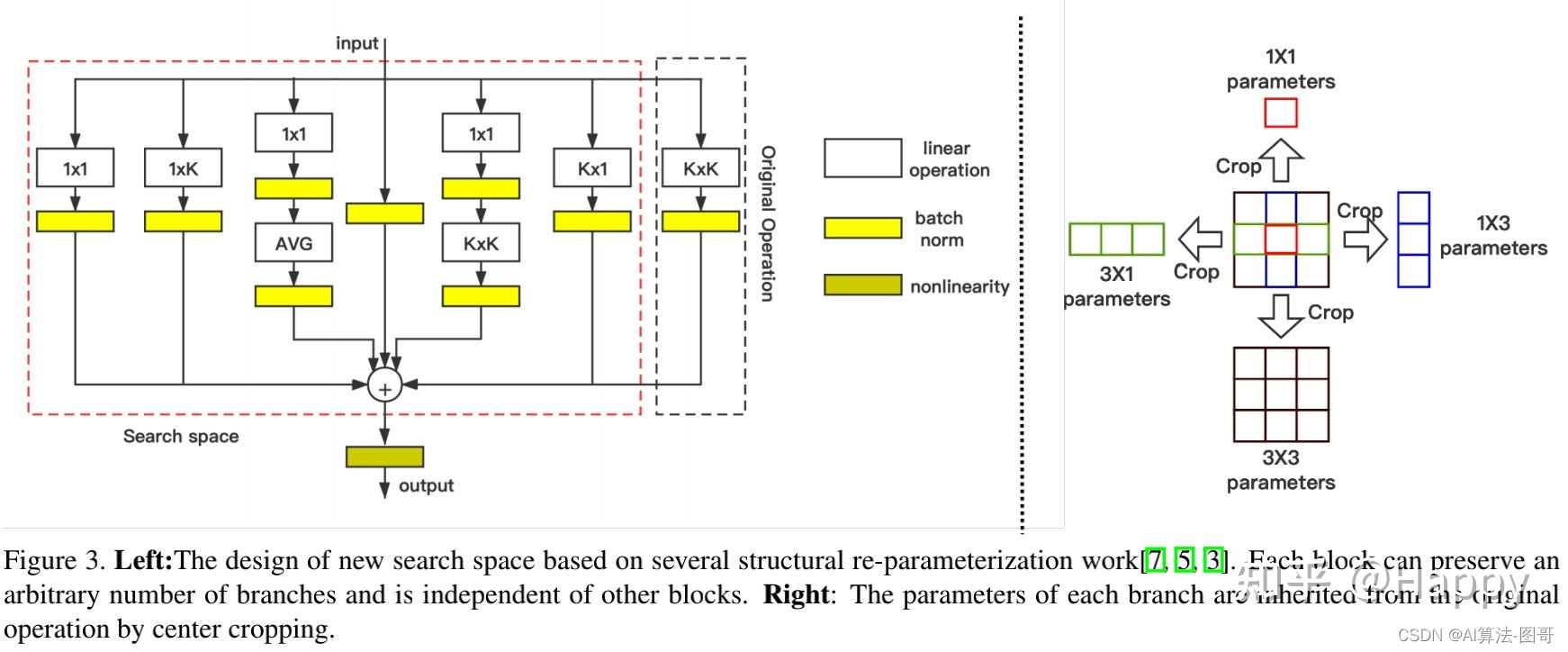
为组合多分支与单分支结构的优势,我们结合结构重参数技术设计了一种更灵活的搜索空间,见上图。可以看到:每个模块包含7个分支。不同于已有搜索空间,我们对分层约束进行了松弛以提供更高的灵活度,这意味着:每个模块可以具有不同的分支,所有模块都是独立的。需要注意的是:在推理阶段,多分支可以融合单分支,故不会造成推理耗时影响。
上述所得搜索空间包含2.29x 1 0 105 10^{105} 10105架构,远大于其他NAS的1.1x 1 0 18 10^{18} 1018,这为NAS算法带来了极大挑战。
2.3 权重共享
已有NAS方法在训练SuperNet过程中进行跨架构权值共享,而在相同模块中进行不同分支权值解耦。然而这种策略并不适用于Rep搜索空间(过多的子网络)。
受启发于BigNAS与Slimmable Networks,我们在相同模块中也进行了参数共享。我们将其表示为:

搭配上权值共享,SuperNet具有更快的收敛速度,同时分支排序可以进行更精确评估。
2.4 重参数化结构搜索

3. 实验
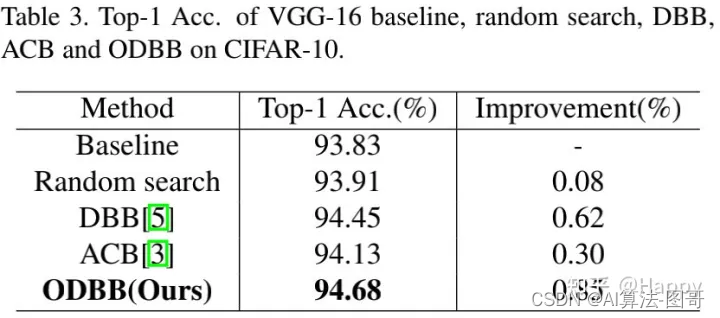
上表给出了不同重参数模型的性能对比,可以看到:
- ODBB可以提升VGG16指标达0.85%,超过了DBB与ACB。
- 随机搜索的重参数模块同样可以提升性能,但以0.77%弱于ODBB,这进一步说明了所提NAS的有效性。
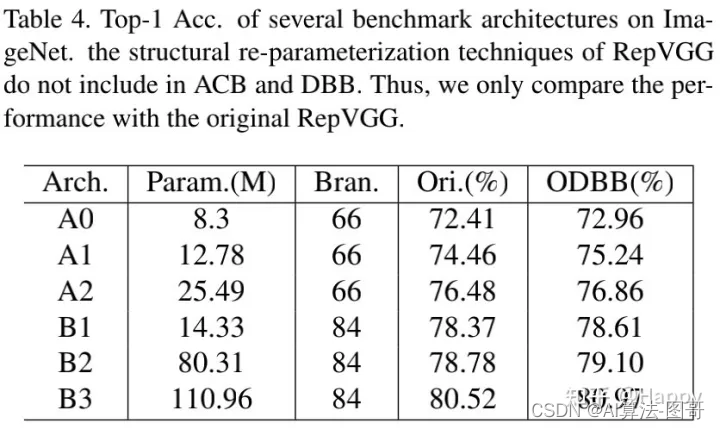
上表给出了ImageNet数据集上所搜到到的ODBB与RepVGG的性能对比,可以看到:
- 在RepVGG-A0-A2基础上,ODBB分别可以取得0.55%、0.38%、0.24%指标提升;
- 在RepVGG-B3基础上,ODBB可以进一步提升0.45%指标,将plain模型的性能从80.52%提升到80.97%.
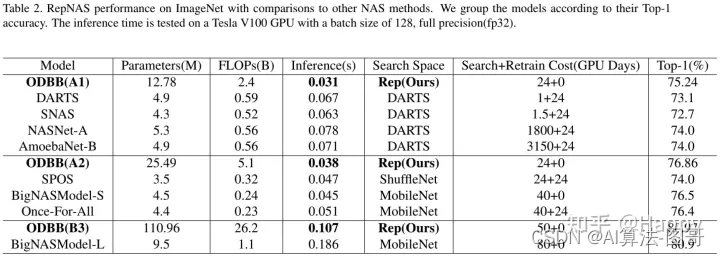
上表对比了所提RepNAS与其他NAS的性能对比,从中可以看到:
- 从Rep搜索空间得到的ODBB系列模型均优于其他搜索空间模型,同时具有更低推理延迟;
- RepNAS可以直接在ImageNet上进行搜索、训练,具有更高性能、更低GPU训练耗时。
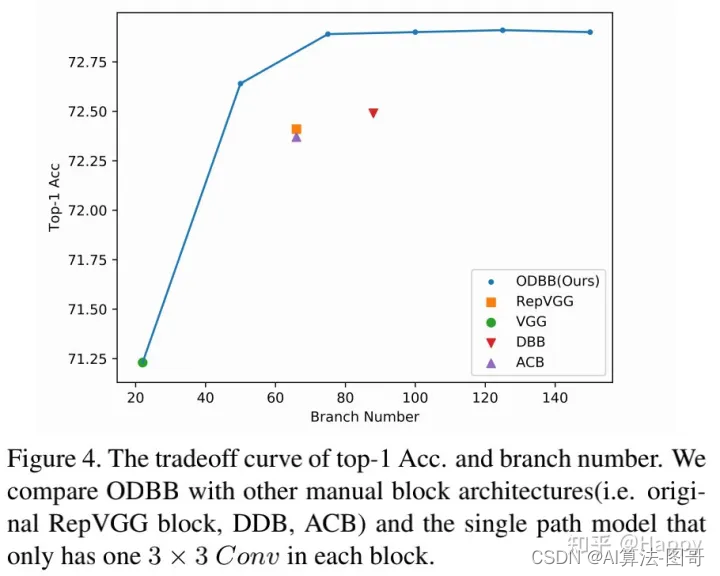
上表对比了不同分支数量下的性能,可以看到:
- ODBB的性能超越其他具有更少分支的重参数模块;
- 带75分支的ODBB已足以取得与更多分支相当的性能。
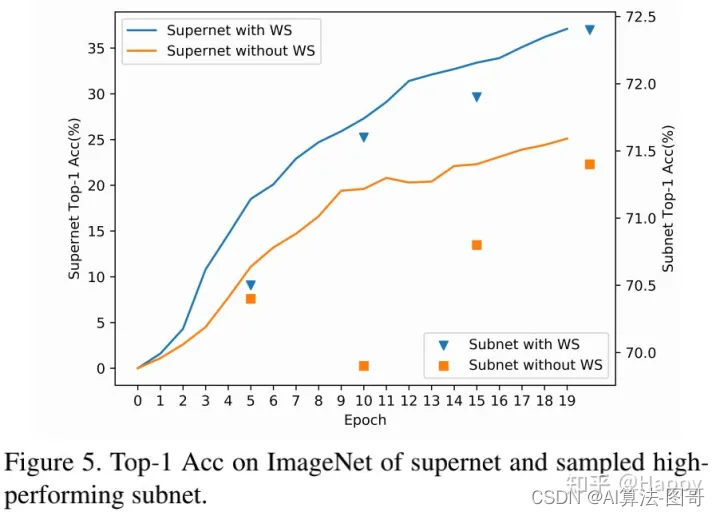
上图对比了权值共享的作用,可以看到:当移除权值共享后,模型收敛慢,精度低 。这说明:SuperNet中的权值共享可以提供好的排序指示。