论文地址:https://kns.cnki.net/kcms/detail/11.2127.TP.20221009.1217.003.html
目录
摘 要
1. Transformer 基本结构
1.1 位置编码
(1) 绝对位置编码
(2) 相对位置编码
1.2 自注意力机制
(1) 多头注意力
(2) 局部注意力
(3) 稀疏注意力机制
1.3 前馈神经网络及其层归一化
2 视觉 Transformer
2.1 Transformer 在视觉上的应用
2.1.1 图像分类 ViT 网络及其改进
2.1.2 目标检测 DETR 网络及其改进
2.1.3 其他应用方面
2.2 基于 Transformer 泛化性能不足的改进
2.2.1 基于知识蒸馏的改进
2.2.2 针对训练样本不足的改进
2.2.3 针对提高泛化能力的改进
2.3 基于 Transformer 面向结构模块的改进
2.3.1 针对补丁嵌入的改进方法
(1)基于提高特征提取能力的补丁嵌入方法
(2)基于长度受限的补丁嵌入
2.3.2 针对自注意力机制的改进方法
(1) 基于注意力机制的改进方法
(2) 针对局部区域改进的局部注意力机制
(3) 基于局部注意力与全局注意力相结合的改进方法
2.3.3 针对提高计算效率的改进结构--金字塔结构
3 CNN+Transformer 混合结构
3.1 基于结构拼接的混合结构
3.2 基于卷积局部性改进的混合结构
3.3 基于特征融合的改进方法
(1) 模型层特征融合
(2) 交叉注意力特征融合
4 Transformer 在 CNN 中的运用
4.1 基于 CNN 的注意力模块
4.2 动态权重
4.3 其他方法
5 总结与展望
参考文献
摘 要
Transformer 是一种基于自注意力机制的深度神经网络。近几年,基于 Transformer 的模型已成为计算机视觉领域的热门研究方向,其结构也在不断改进和扩展,比如局部注意力机制、金字塔结构等。通过对基于 Transformer结构改进的视觉模型,分别从性能优化和结构改进两个方面进行综述和总结;此外,也对比分析了 Transformer 和CNN 各自结构的优缺点,并介绍了一种新型的 CNN+Transformer 的混合结构;最后,对 Transformer 在计算机视觉上的发展进行总结和展望。
Transformer[1]是一种基于自注意力机制的模型,不仅在建模全局上下文方面表现强大,而且在大规模
预训练下对下游任务表现出卓越的可转移性。这种成功在机器翻译和自然语言处理(NLP)领域上得到了广泛的见证。 2018 年 Devlin 等人在 Transformer 的基础上提出了基于掩码机制双向编码结构的 Bert[2]模型,在多种语言任务上达到了先进水平。此外,包括 Bert 在内许多基于 Transformer 的语言模型,如 GPTv1-3[3-5], Ro-BERTa[6], T5[7]等都展现出了强大的性能。
在计算机视觉任务中,由于 CNN 固有的归纳偏好[8],如平移不变性、局部性等特性,一直占据着主导地位(CNN[9],ResNet[10]等)。然而 CNN 有限的感受野使其难以捕获全局上下文信息。受 Transformer 模型在语言任务上成功的启发,最近多项研究将 Transformer 应用于 计算机视觉任务中。 Parmar 等人 (2018) 基于Transformer 解码器的自回归序列生成或转化问题提出了 Image Transformer[11]模型用于图像生成任务。Carion 等人(2020)基于 Transformer 提出了 DETR[12](一种端到端目标检测),其性能取得了与 Faster-RCNN 相当的水平。最近 Dosovitskiy 等人提出的另一个视觉Transformer 模型 ViT[13],在结构完全采用 Transformer的标准结构。ViT 在多个图像识别基准任务上取得了最先进的水平。除了基本的图像分类之外,Transformer还被用于解决各种其他计算机视觉问题,包括目标检测[14,15]、语义分割[16]、图像处理和视频任务[17]等等。由于其卓越的性能,越来越多的研究人员提出了基于Transformer 的模型来改进广泛的视觉任务。
目前,基于 Transformer 的视觉模型数量迅速增加,迫切需要对现有研究进行整体的概括。在本文中,我们重点对视觉 Transformer 的最新进展进行全面概述,并讨论进一步改进的潜在方向。为了方便未来对不同结构模型的研究,我们将 Transformer 模型按结构分类,主要分为纯 Transformer、CNN+Transformer 混合结构以及利用 Transformer 改进的 CNN 结构。
虽然 Transformer 在计算机视觉领域上展现了其先进的性能,但也面临着参数量大、结构复杂、尺寸大小不可调节等问题。本文分别从训练技巧、补丁嵌入、自注意力机制、金字塔架构等多方面介绍了 Transformer 的各种改进结构。在本文最后一部分,我们给出了结论和面临的一些问题,并对未来的发展方向进行展望。
1. Transformer 基本结构
2017 年 Vaswani 等人首次提出了 Transformer 模型(如图 1 所示),它是由 6 个编码器-解码器模块组成,每个编码器模块由一个多头自注意层和一个前馈神经网络层组成;每个解码器模块由 3 层组成,第一层和第三层类似于编码器模块,中间是交叉注意力层,该注意力层 k,v 的输入是由相应编码器模块的输出组成。本节主要对 Transformer 中各个模块的特点进行介绍。
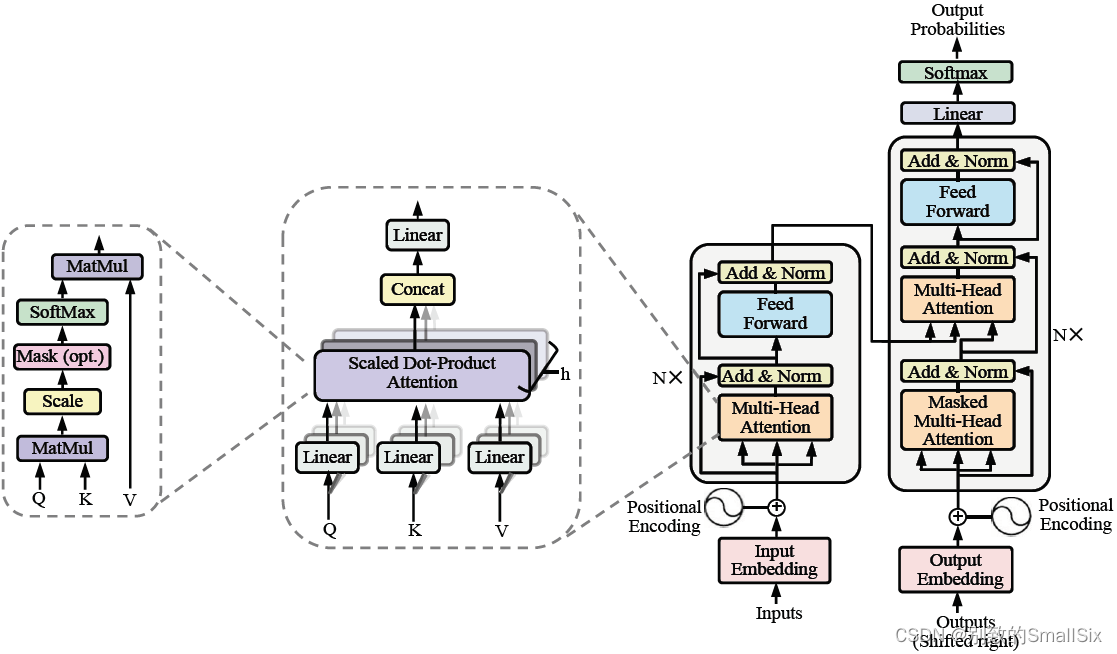
图 1 Transformer 整体结构
1.1 位置编码
由于 Transformer 的输入是一种单词(句子)特征序列 ( 这种序列具有置换不变性 ), 而 Transformer 中Attention 模块是无法捕捉输入的顺序,因此模型就无法区分输入序列中不同位置的单词。为了得到输入序列的位置信息,Transformer 将位置编码添加到输入序列中以捕获序列中每个单词的相对或绝对位置信息。
(1) 绝对位置编码
绝对位置编码通过预定义的函数生成[1]或训练学习得到[2],具有与输入序列相同的维度,采用相加操作将位置信息添加到输入序列中。[1]中使用交替正弦函数和余弦函数来定义绝对位置编码,其公式如下:
其中 pos 是目标在序列中的位置,i 是维度,d 是位置编码维度。
(2) 相对位置编码
相对位置编码不同于绝对位置编码直接在其输入序列加入位置信息,而是通过扩展自我注意机制,以有效地考虑相对位置或序列元素之间的距离。在计算Attention 时考虑当前位置与被 Attention 位置的相对距离。[18]中考虑输入元素之间的成对关系在注意力计算中加入了相对位置向量 ,公式如下:
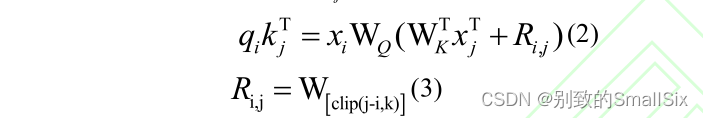
对设置了截断,丢弃长远距离的无效信息,从而减少了计算量,可以使模型泛化到在训练过程中未见的序列长度。
其他方式的位置编码。除了上述方法之外,还有一些其他类型的位置编码 , 例如 递归式的位置编码[19],CNN 式位置编码[20],复数式位置编码[21],条件位置编码 CPVT[22]等。
1.2 自注意力机制
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛应用于自然语言处理[1]、语音和计算机视觉[13]等领域。注意力机制现在已成为神经网络领域的一个重要概念。其快速发展的原因主要有三个:首先,它是解决多任务较为先进的算法,其次被广泛用于提高神经网络的可解释性,第三有助于克服RNN 中的一些挑战,如随着输入长度的增加导致性能下降,以及输入顺序不合理导致的计算效率低下。
自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性,通过对序列中元素之间的所有成对交互关系进行建模[12],让机器注意到整个输入中不同部分之间的相关性。自注意力层通过定义三个可学习的权重矩阵,将输入序列投影到这些权重矩阵上,得到三元组
。自注意力计算公式如下:

其中等于矩阵 K 的维度大小。
(1) 多头注意力
多头注意力(如图 1 左部分)是在单头注意力的基础上将输入序列 X 在其通道维度上划分成 h 个头,即[B,dim]-->[B,h,dim/h]。每个头使用不同的可学习权重,对应生成不同的
组。由于注意力在不同的子空间中分布不同,使用多头注意力机制可以形成多个子空间,从而将输入映射到不同的空间中,使模型学习到输入数据之间不同角度的关联关系。多头注意力总的参数量不变只改变每个头的维度,计算量和单头自注意力相当。
多头自注意力机制中并行使用多个自注意力模块,不同头部关注不同的信息(如全局信息和局部信息)可以丰富注意力的多样性,从而增加模型的表达能力。
(2) 局部注意力
局部注意力仅在相邻的部分区域内执行注意力,解决了全局注意力计算开销过大的问题。对于视觉图像平面空间上局部区域计算,Parmar 等人提出了 2D 局部注意力模块[11],网络可以更均匀地平衡水平和垂直方向相邻空间上的局部上下文信息(如图 2 所示),大大降低了计算复杂度。其中(a)是 Local Attention[11]整体结构(由局部注意力和前馈网络组成),输入一个单通道像素 q,预测生成像素 qˊ。mi 表示先前预测生成的像素块,pq 和 pi 是位置编码。(b)是 2D 局部注意力执行过程图。q 表示最后预测生成的像素,白色网格表示对预测位置贡献为 0 具有屏蔽作用,青色矩形为最后生成的所有像素区域。

图 2 局部注意力
(3) 稀疏注意力机制
局部注意力虽然可以减少计算量,但其无法捕获全局上下文信息。Child 等人[23]提出了稀疏注意力机制,通过 top-k 选择将全局注意退化为稀疏注意。这样可以保留最有助于引起注意的部分,并删除其他无关的信息。这种选择性方法在保存重要信息和消除噪声方面是有效的,可以使注意力更多地集中在最有贡献的价值因素上。稀疏注意力有两种方式,第一种步长注意力(图 3c 所示)是在局部注意力的基础同时每隔 N 个位置取一个元素进行注意力计算。但是对于一些没有周期性结构的数据(如文本),步长注意力关注的信息可能与该元素并不一定是最相关的信,可以采用固定式注意力(图 3d 所示)将先前预测的特定位置的信息传播到未来所有需要预测的元素中,具体公式如下:
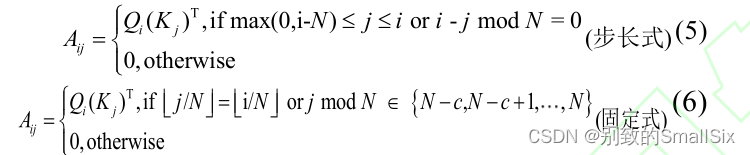
其中c是超参数。
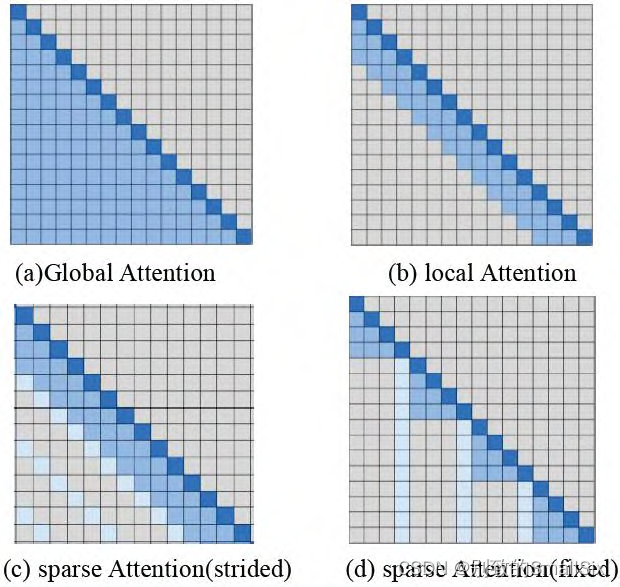
图 3 4 种注意力方案
1.3 前馈神经网络及其层归一化
Transformer 中除了注意力子层之外,每个编码器和解码器都包含一个完全连接的前馈神经网络[1],该模块由两个线性层组成,中间包含一个 ReLU 激活层。前馈网络对序列中不同位置的元素使用相同的处理方式,虽然不同位置的线性变换是相同的,但它们在层与层之间使用不同的参数。其计算公式如下:
![]()
其中输入输出维度是 512,内层的维度是 2048。
随着网络深度的增加,数据的分布会不断发生变化。为了保证数据特征分布的稳定性,Transformer 在注意力层和前馈网络层之前加入 Layer Normalization 层,这样可以加速模型的收敛速度,该过程也被称为前归一化,其计算公式如下:
![]()
然而每个残差块输出的激活值被直接合并到主分支上。随着层数的加深该激活值会逐层累积,使得主分支的振幅会越来越大。导致深层的振幅明显大于浅层的振幅,而不同层中振幅的差异过大会导致训练不稳定。为了缓解这个问题,Swin-Transformer v2[24]提出一种后归一化处理,将 Layer Normalization 层从每个子层之前移到每个子层之后,这样可以使得每个残差块的输出在合并回主分支之前被归一化。当网络层数增加时,主分支的振幅不会累积,其激活幅度也比原始的前归一化处理要温和得多,可以大大提高大型视觉模型的稳定性。
2 视觉 Transformer
2.1 Transformer 在视觉上的应用
本节重点从图像分类、目标检测两个应用场景出发, 介绍了 Transformer 在视觉任务上一些应用以及相应的改进方法。
2.1.1 图像分类 ViT 网络及其改进
Dosovitskiy 等人[13]首次提出了 ViT(如图 4 所示),将原始的 Transformer 应用于图像分类任务,是一种完全基于自注意力机制的纯 Transformer 结构,网络结构中不包含 CNN。
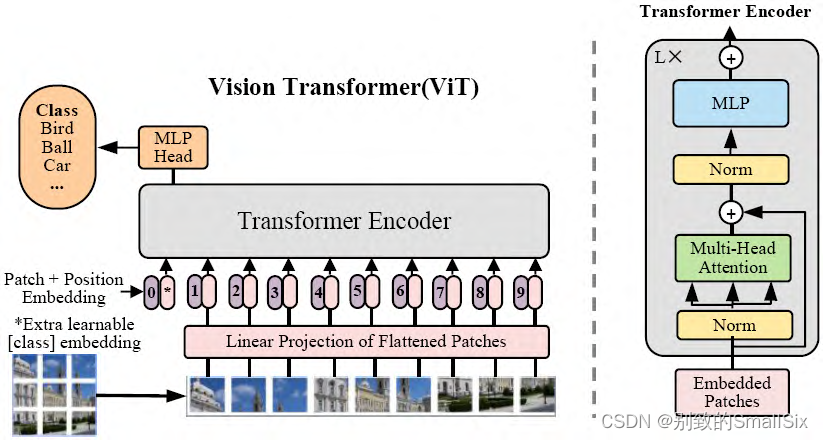
图 4 视觉 Transformer(ViT)
对于输入的 2D图像数据,ViT 将其重新塑造成一系列扁平的 2D 图像块
,其中 C是通道数。将输入分辨率为(H,W)的原始图像,划分为每个分辨率为(p,p)的图像块(补丁),其有效的输入序列长度为 n=HW/p2。ViT 也采用了与 Bert 类似的[class]分类标记,该标记可以表示整个图像的特征信息,被用于下游的分类任务中。ViT 通常在大型数据集上预训练,针对较小的下游任务预训练。在 ImageNet 数据集上取得了 88.55% Top-1 的准确率超越了 ResNet 系列模型,打破了 CNN 在视觉任务上的垄断,相较于 CNN具有更强泛化能力。
ViT 取得了突破性的进展,但在机器视觉领域中也有其缺陷。(1)ViT 输入的 token 是固定长度的,然而图像尺度变化非常大;(2)ViT 的计算复杂度非常的,不利于具有高分辨率图像的视觉应用。针对这些问题,Liu等人提出了 Swin Transformer[25],通过应用与 CNN 相似的分层结构来处理图像,使 Transformer 模型能够灵活处理不同尺度的图片。Swin Transformer 采用了窗口注意力机制,只对窗口内的像素区域执行注意力计算,将 ViT token 数量平方关系的计算复杂度降低至线性关系。
2.1.2 目标检测 DETR 网络及其改进
Carion 等人提出的 DETR[12],使用 CNN 主干网络提取紧凑特征表示,然后利用 Transformer 编码器-解码器和简单的前馈网络(FFN)做出最终的目标检测任务(如图 5 所示)。DETR 将目标检测视为集合预测问题,简化了目标检测的整体流程,将需要手动设计的技巧如非极大值抑制和锚框生成删除,根据目标和全局上下文之间的关系,直接并行输出最终的预测集,实现了端到端的自动训练和学习。在 COCO[26] 数据集上,DETR 的平均精确度 AP 为 42%,在速度和精度上优于 Faster-RCNN。
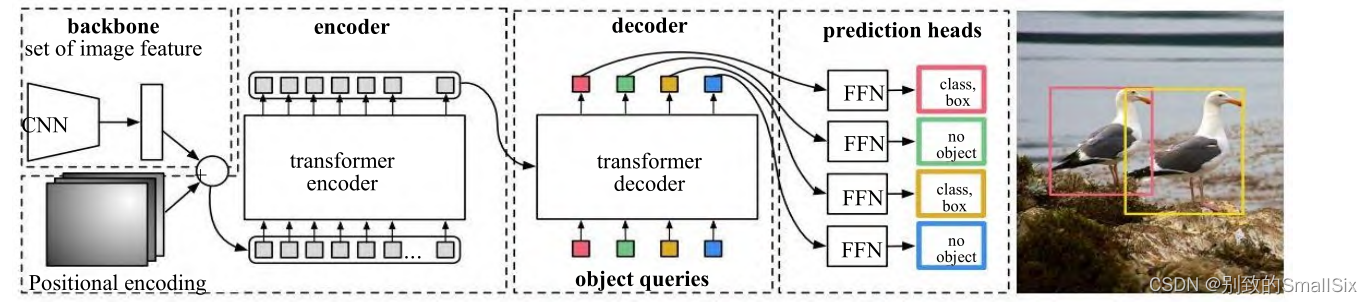
图 5 DETR 模型结构
DETR 具有良好的性能,但与现有的 CNN 模型相比,它需要更长的训练周期才能收敛。在 COCO 基准测试中,DETR 需要迭代 500 次才能收敛,这比 FasterR-CNN 慢 10 到 20 倍。Zhu 等人提出的 DeformableDETR[14]模型,结合了形变卷积[27]稀疏空间采样的优点和 Transformer 长远关系建模提出了可变形注意模块,该模块只关注所有特征图中突出的关键元素,可以自扩展到聚合多尺度特征,而无需借助 FPN(特征金字塔)模块[28],取得了比 DETR 更好的结果且训练收敛速度也更快。Sun 等人[29]表明导致 DETR 收敛缓慢的主要这些问题提出了两种解决方案 ,即 TSP-FCOS 和TSP-RCNN。该方法不仅比原始 DETR 收敛速度快得多,而且在检测精度和其他基线方面也明显优于 DETR。
其次,DETR 在检测小物体的性能上相对较低。目前目标检测模型通常利用多尺度特征从高分辨率特征图中检测小物体,然而高分辨率特征图会导致 DETR不可接受的复杂性。Zheng 等人[30]提出的 ACT 模型,一种自适应聚类注意力,通过使用局部敏感哈希(LSH)自适应地对查询特征进行聚类,并使用原型键在查询键交互附件进行聚类,降低了高分辨率图像的计算成本,同时在准确性上也取得了良好的性能。
2.1.3 其他应用方面
其他基于 Transformer 在视觉各领域中的应用:有Image Transformer 模型用于图像生成任务;SETR[16]用于图像分割模型,使用 Transformer 编码器替换基于堆叠卷积层的编码器进行特征提取;ViT-FRCNN[31]模型主要是将 ViT 与 FRCNN 的结合用于大型目标检测任务中。有基于掩模的视觉 Transformer(MVT)[32]用于野外的面部表情识别任务。表 1 对 Transformer 不同的应用场景进行了分类。
表 1 关于 Transformer 在视觉任务中的应用
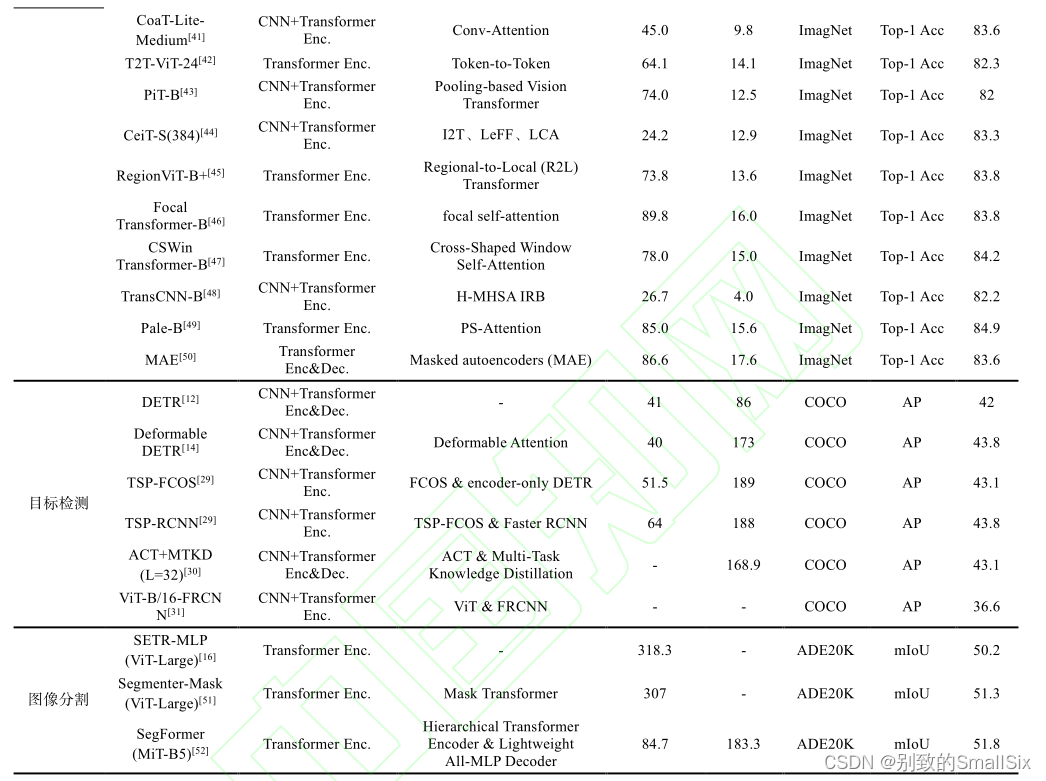

从表1中可以发现,图像分类中20年发表的有1篇,21年发表的有17篇,22年发表的有1篇;目标检测中20年发表的有4篇,21年发表的有2篇;图像分割中21年发表的有3篇;图像生成中18年发表的有1篇;表情识别中21年发表的有1篇。
2.2 基于 Transformer 泛化性能不足的改进
本节介绍了提高 Transformer 泛化性能的改进方法。现有的工作主要在知识蒸馏、特征融合、样本量以及泛化能力几个方面 Transformer 提出各种改进进行研究。
2.2.1 基于知识蒸馏的改进
知识蒸馏可以解释为将教师网络学到的信息压缩到学生网络中。Touvron 等人提出的 DeiT[33](如图 6 所示)在 Transformer 的输入序列中加入了蒸馏 token,该蒸馏 token 与分类 token 地位相当都参与了整体信息的交互过程,蒸馏 token 通过使用 Convnet 教师网络对比学习,可以将卷积的归纳偏好和局部性等特性融合到网络中使 DeiT 更好地学习。蒸馏学习的过程有两种方式:一种是 Hard-label 蒸馏,直接将教师网络的输出坐标标签;另一种是使用 KL 散度衡量教师网络和学生络的输出。实验结果表明,Transformer 通过蒸馏策略可以取得更好的性能。
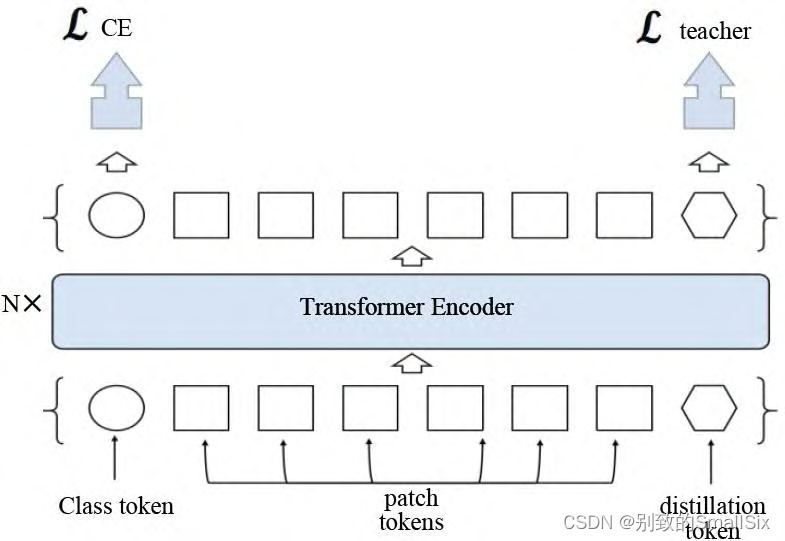
图 6 DeiT 模型结构
2.2.2 针对训练样本不足的改进
最近的研究发现[13,33,34],基于 Transformer 的网络模型参数量很大,如果训练样本不足,很容易造成过拟合。为了解决这一问题,可以在训练过程中应用数据增强和正则化技术,例如 Mixup[35]和CutMix 等基于混合的数据增强方法能够明显提高视觉 Transformer 的泛化能力[33]。CutMix 混合标签公式如下:
![]()
其中 λ 是混合标签后的裁剪面积比。图 7 中介绍了上述几种数据增强方法的效果对比图。然而基于混合生成图像中可能没有有效对象,但标签空间仍有响应。Chen 等人提出了 TransMix[34]方法,该方法基于 Transformer 中的注意力图生成混合标签。

图 7 数据增强方法
TransMix 网络根据每个数据点在注意图中的响应动态地重新分配标签权重,标签的分配不再是裁剪到输入图像的显著区域而是从更准确地标签空间中分配标签,可以改进各种 ViT 模型性能,对下游密集预测任务(图像分割、目标检测等)表现出了较好的可移植性。其权重分配计算公式如下:
![]()
其中(∙)↓为最近邻下采样,M 是图像覆盖区域的位置。
2.2.3 针对提高泛化能力的改进
泛化能力是指网络对新样本的可扩展能力。对于泛化能力的改进可以从两个方面进行:一方面由于网络对数据学习的不充分,导致泛化能力不足,Yun 等人提出了补丁标记 MixToken[53],将除了分类 token 以外的所有补丁 token 生成一个软标签计算 loss,通过多监督的方式学习提高模型的性能,该方法有利于具有密集预测的下游任务,例如语义分割。另一方面由于高容量的 ViT 模型容易对训练样本过拟合,对新样本表现欠拟合,通过自监督学习图像重要的表征信息,可以提高模型的泛化能力,Chen 等人提出的 MoCoV3[54],通过将同一图像不同变换作为正例,不同图像作为负例,使用双分支网络对比学习图像的表征信息。
此外,基于 Transformer 自监督学习在自然语言处理中的成功启发(如 BERT 掩码自编码等),何恺明等人提出了一种简单、 有效且可扩展的掩码自编码器MAE[50],从输入序列中随机屏蔽掉 75%的图像块,然后在像素空间中重建被屏蔽的图像块。MAE 是一种非对称的编码器-解码器结构(如图 8 所示),其中编码器仅作用于无掩码标记块,而解码器通过隐表达与掩码标记信息进行原始图像重建.该结构采用小型解码器大幅度减少了计算量,同时也能很容易地将 MAE 扩展到一些大型视觉模型中。在 ViT-Huge 模型上使用 MAE 自监督预训练后,仅在 ImageNet 上微调就可以达到 87.8%的准确率.在对象检测、实例分割和语义分割的迁移学习中,使用 MAE 预训练要优于有监督的预训练。
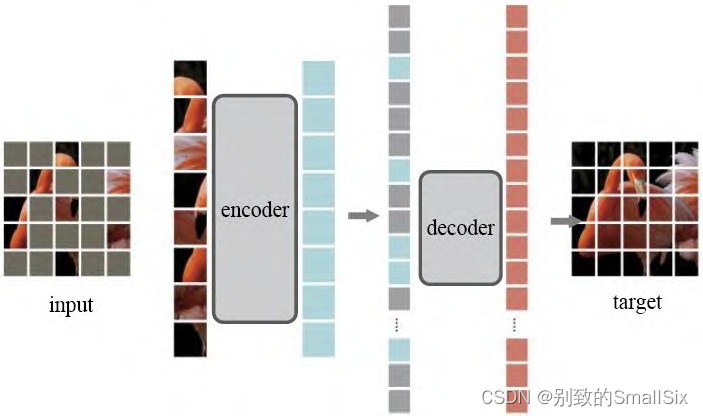
图 8 非对称编码器-解码器结构(MAE)
2.3 基于 Transformer 面向结构模块的改进
目前遵循 ViT 的范式 , 已经提出了一系列Transformer 变体来提高视觉任务的性能。主要的改进结构包括补丁嵌入、自注意力改进和金字塔架构等,本节主要从这几个方面介绍了最新的一些研究发方法。
2.3.1 针对补丁嵌入的改进方法
(1)基于提高特征提取能力的补丁嵌入方法
Han 等人提出的 TNT[37](如图 9 所示),将补丁划分为多个更小的子补丁(例如,将 27×27 的补丁再细分为 9个 3×3 的块,并计算这些块之间的注意),引入了一种新颖的 Transformer in Transformer 架构,用于对 patch 级和 pixel 级的表征建模。该架构利用 Inner TransformerBlock 块从 pixel 中提取局部特征,Outer TransformerBlock 聚合全局的特征,通过线性变换成将 pixel 级特征投影到 patch 空间中将补丁和子补丁的特征进行聚合以增强表示能力。

图 9 TNT 网络结构
Yuan 等人提出的 CeiT[44],结合 CNN 提取 low-level特征的能力设计了一个 Image-to-Tokens(I2T)模块,该模块从生成的 low-level 特征中提取 patch。
Wang 等人提出的 CrossFormer[55],利用跨尺度嵌入层 CEL 为每个阶段生成补丁嵌入,在第一个 CEL 层利用四个不同大小的卷积核提取特征,将卷积得到的结果拼接起来作为补丁嵌入。
(2)基于长度受限的补丁嵌入
许多视觉 Transformer 模型面临的主要挑战是需要更多的补丁数才能获得合理的结果,而随着补丁数的增加其计算量平方增加。Ryoo 等人提出了一种新的视觉特征学习器 TokenLearner[56](如图 10 所示),对于输入 x 通过 s 个 ai 函数(该函数由一系列卷积组成)学到一个空间权重(H*W*1),去乘以 x 然后通过全局池化,最终得到一个长度为 s 的 token 序列。TokenLearner可以基于图像自适应地生成更少数量的补丁,而不是依赖于图像均匀分配补丁。实验表明使用TokenLearner 可以节省一半或更多的内存和计算量,而且分类性能并不会下降甚至可以提高准确率。
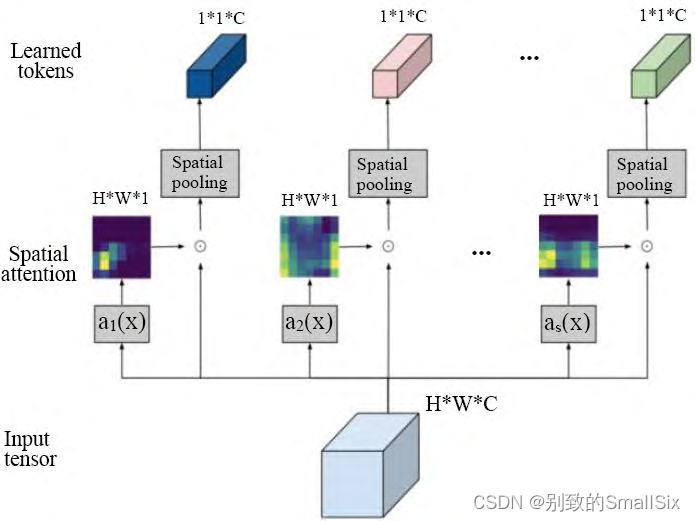
图 10 TokenLearner 模块
PSViT[57]采用补丁池化在空间维度上减少补丁的数量。T2T-ViT[42]通过 T2T 模块递归地将相邻的补丁组合成为单个补丁,这样可以对相邻的补丁表示进行跨局部建模同时减少了一半的补丁数。
2.3.2 针对自注意力机制的改进方法
(1) 基于注意力机制的改进方法
Shazeer 等人提出了一种交谈注意力机制[58],在softmax 操作前引入对多头注意力之间的线性映射,以增加多个注意力机制间的信息交流。PSViT[57]将相邻的 Transformer 层之间建立注意力共享,以重用相邻层之间具有强相关性的注意力图。Refiner[59]探索了高维空间中的注意力扩展,并应用卷积来增强注意力图。
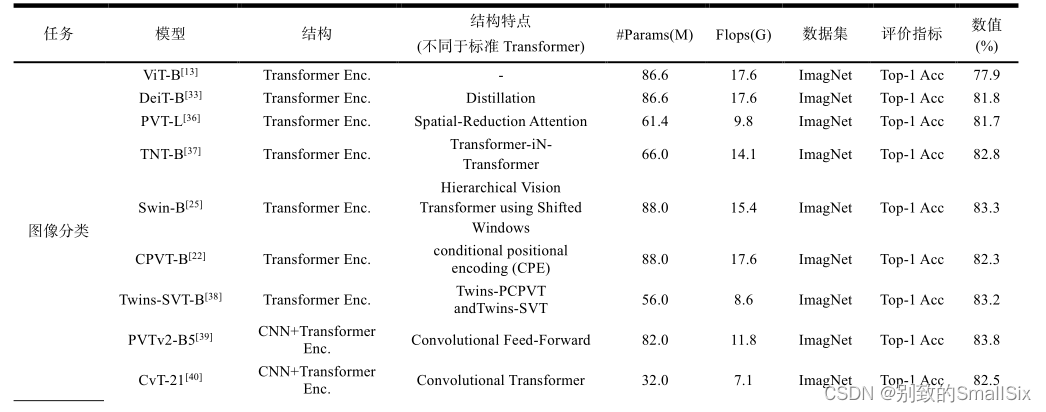
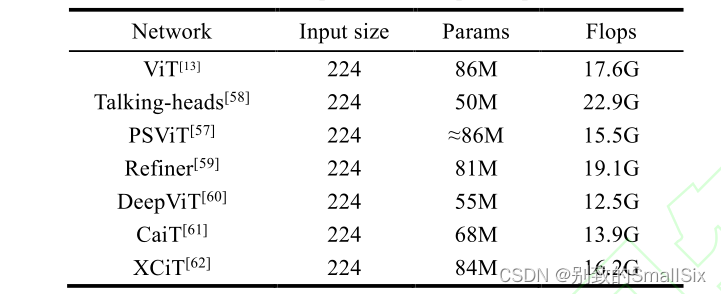
Zhou 等人提出了 DeepViT[60]模型,通过重新生成注意力图以增加不同层的多样性。CaiT[61]将补丁之间的自注意力层与类注意力层分离,使类标记专注于抽取图片的信息。XCiT[62]利用互协方差注意力(XCA)跨特征通道执行自注意力计算,其操作具有线性复杂性,可以对高分辨率图像进行有效处理。表 2 总结了上述几种方法的参数量和计算量的一些情况。
表 2 模型的参数量和计算量对比
(2) 针对局部区域改进的局部注意力机制
Swin Transformer[25]在局部窗口内执行注意力计算。RegionViT[45]提出了区域到局部的注意力计算。Multi-Scale Vision Longformer[63]利用 Longformer[64]设计了自注意力模块,加入了局部上下文信息。KVT[65]引入了 k-NN 注意力利用图像块的局部性通过仅计算具有前 k 个相似标记的注意力来忽略不想关的标记。
CSWin Transformer[47]提出了一种新颖的十字形窗口自注意力,在其基础上 Pale Transformer[49]提出了一种改进的自注意力机制 PS-Attention,在一个 Pale-Shaped的区域内进行自注意力的计算 ( 图 11 中介绍了Transformer 不同注意力机制的效果图),可以在与其他的局部自注意力机制相似的计算复杂度下捕获更丰富的上下文信息。DAT[66]提出了一种新的可变形的局部自注意力模块,该模块以数据依赖的方式选择自注意力中 key 和 value 对的位置。这种更灵活的自注意力模块能够聚焦于更相关的区域信息。Han 等人[67]从稀疏连接、权重共享和动态权重等方面揭示了局部视觉Transformer 的网络特征。
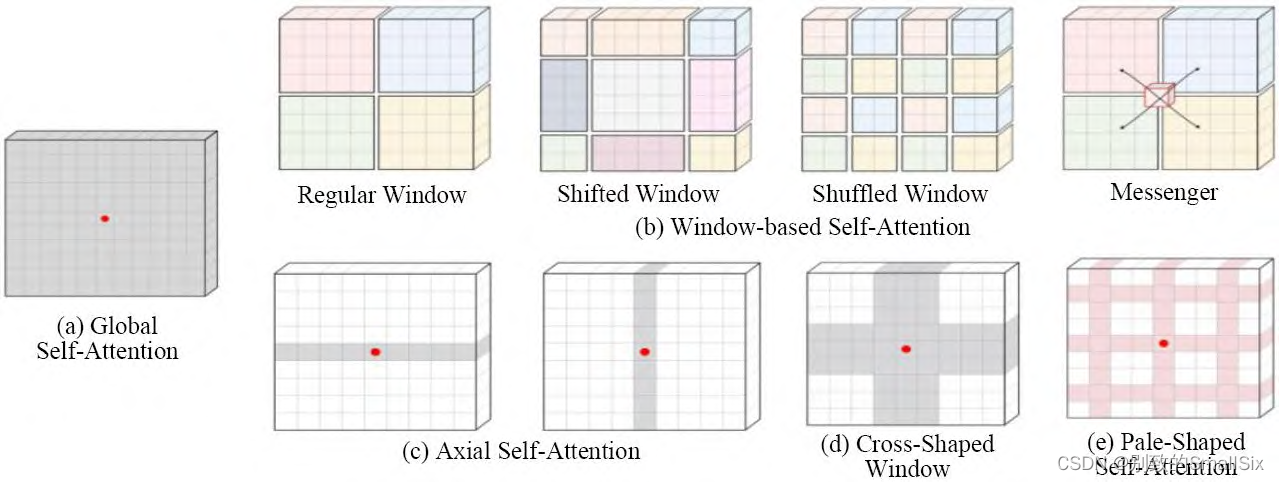
图 11 Transformer 中不同自注意力机制
(3) 基于局部注意力与全局注意力相结合的改进方法
尽管局部窗口[25]的自注意力机制是计算友好的,但缺少丰富的上下文信息。为了捕获更丰富的上下文信息。Twins[38]将每个子窗口概括为一个代表元素执行全局子采样注意力(GSA)。CAT[68]将每个通道的特征图分离并使用自注意力来获取整个特征图中的全局信息。Focal Transformer[46]引入了焦点自我注意以捕获全局和局部关系。CrossFormer[55]引入了长短距离注意力(LSDA),以捕捉局部和全局视觉信息。TransCNN[48]设计一种分层多头注意力模块(H-MHSA)可以更有效地对全局关系进行建模。
2.3.3 针对提高计算效率的改进结构--金字塔结构
金字塔结构一般常用于卷积网络中,通过缩减空间尺度以增大感受野,同时也能减少计算量。但是对于Transformer 其本身就是全局感受野,可以直接堆叠相同的 Transformer encoder 层。而对于密集预测任务中当输入图像增大时,ViT 计算量会急剧上升,如果直接增大 patch size(如 16*16)得到粗粒度的特征,这对于密集任务来会有较大的损失。
Wang 等人提出的 PVT[36]是第一个采用特征金字塔的 Transformer 结构,包含了渐进式收缩金字塔和空间缩减注意力模块 SRA(如图 12 所示 ),SRA 通过reshape 恢复 3-D(H*W*C)特征图 ,重新均分为大小R*R 的补丁块将 K,V 的补丁数量缩小 R 倍,相较于 ViT其渐进式收缩金字塔能大大减少大型特征图的计算量,可以替代视觉任务中 CNN 骨干网络。
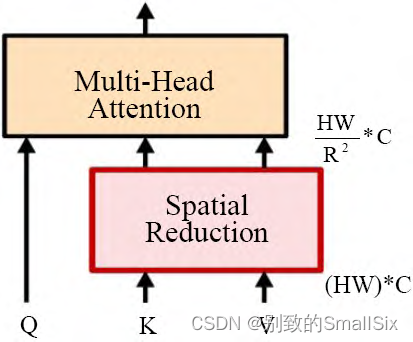
图 12 空间缩减注意力模块
PVTv2[39]和 SegFormer[52]通过引入重叠补丁嵌入、深度卷积来改进原始 PVT,PVTv2 在空间缩减注意力模块中利用具有线性复杂度的平均池化操作代替了PVT 中的卷积操作。这种特征金字塔的设计思想使Transformer 成为了视觉任务骨干网络的一个替代方案 , 诸如 Focal Transformer[46] 、 CrossFormer[55] 、RegionViT[45]、Multi-Scale Vision Longformer[63]等都采用了金字塔结构的设计方案。
除了上述方法之外,还有一些其他方向可以进一步改进视觉 Transformer, 例如位置编码 CPVT[22] 、iRPE[69]、残差连接优化策略 LayerScale[61]、快捷连接[70]和去除注意力[71,51]、ResMLP[72]、FF Only[73]。
3 CNN+Transformer 混合结构
基于深度学习的方法在计算机视觉领域最典型的应用便是 CNN,通过共享卷积核来提取特征,一方面可以极大的降低参数量来避免更多冗余的计算从而提高网络模型计算的效率,另一方面又结合卷积和池化使网络具备一定的平移不变性和平移等变性。而Transformer 依赖于更灵活的自注意力层,在提取全局语义信息和性能上限等方面的表现要优于 CNN。目前新的研究方向是将这两种网络结构的优势结合起来。本节从架构拼接、内部改进、特征融合几个方面介绍了 CNN+Transformer 的混合模型。
3.1 基于结构拼接的混合结构
Carion 等人提出的 DETR[12],利用 ResNet 主干网络提取图像紧凑特征表示生成一个低分辨率高质量的特征图,有效的减少了输入前 Transformer 图像尺度大小,提高模型速度与性能。
Chen 等人提出的 Trans- UNet[74],将 Transformer与 UNet 相结合,利用 Transformer 从卷积网络输出的特征图中提取全局上下文信息,然后结合 Unet 网络的 U型结构将其与高分辨率的 CNN 特征图通过跳跃连结组合以实现精确的定位。在包括多器官分割和心脏分割在内的不同医学应用中取得了优于各种竞争方法的性能。
Xiao 等人提出的 ViTc[75],将 Transformer 中 PatchEmbedding 模块替换成 Convolution, 使得替换后的Transformer 更稳定收敛更快,在 ImageNet 数据集上效果更好。
3.2 基于卷积局部性改进的混合结构
Wu 等人提出的 CvT[40]结合了卷积投影来捕获空间结构和低级细节。Refiner[59]应用卷积来增强自注意力的局部特征提取能力。CoaT[41]通过引入卷积来增强自注意力设计了一种卷积注意力模块该模块,可以作为一种有效的自注意力替代方案。Uni- Former[76]将卷积与自注意力的优点通过 Transformer 进行无缝集成,在浅层与深层分别聚合局部与全局特征,解决了高效表达学习的冗余与依赖问题。 Liu 等人提出的TransCNN 网络[48],通过在自注意力块后引入 CNN 层使网络可以继承 Transformer 和 CNN 的优点。CeiT[44]将前馈网络(FFN)与一个 CNN 层相结合,以促进相邻补丁之间的相关性。Le-ViT[77]在 non-local[78]的基础上提出了一种用于快速推理图像分类的混合神经网络。PiT[43]利用卷积池化层实现 Transformer 架构的空间降维。ConViT[79]引入了一个新的门控位置自注意力层(GPSA)以模拟卷积层的局部性。
3.3 基于特征融合的改进方法
CNN 与 Transformer 结合的另一形式是通过特征融合,采用一种并行的分支结构将中间特征进行融合。
(1) 模型层特征融合
Peng 等人提出了 Conformer[80](如图 13),通过并行结构将 Transformer 与 CNN 各自的特征通过桥架相互结合实现特征融合,使 CNN 的局部特征和 Transformer的全局特征得到最大程度的保留。
图 13 Conformer 模型结构
(2) 交叉注意力特征融合
Chen 等人提出了 MobileFormer[81],将 MobileNet和 Transformer 并行化,使用双向交叉注意力将两者连接起来即 Mobile-Former 块,与标准注意力相比 k 和 v通过局部特征直接投影得到,节省了计算量使注意力更多样化。实验表明,该方法在准确性和计算效率都取得了显著效果。
4 Transformer 在 CNN 中的运用
4.1 基于 CNN 的注意力模块
Wang 等人提出了 Non-local[78]模块(如图 14(a))旨在通过全局注意力捕获长距离依赖关系,将某个位置的输出等于特征图中所有位置的特征加权和,使局部CNN 网络得到了全局的感受野和更丰富的特征信息。此外为了减少全局注意力计算的负担,Huang 等人[82]提出了十字交叉注意模块,该模块仅在十字交叉路径上生成稀疏注意图(如图 14(b)所示),通过反复应用交叉注意力,每个像素位置都可以从所有其他像素中捕获全局上下文信息。与 Non-local 块相比,十字交叉注意力减少了 11 倍 GPU 显存,具有 O(√N)的复杂度。Aravin 等人提出的 BoTNet[83], 将多头注意力模块Multi-Head Self-Attention(MHSA)替代 ResNet Bottle-neck 中的 3×3 卷积,其他没有任何改变,形成新的网络结构,称为 Bottleneck Transformer,相比于 ResNet 等网络提高了在分类,目标检测等任务中的表现,并且比EfficientNet 快 1.64 倍。
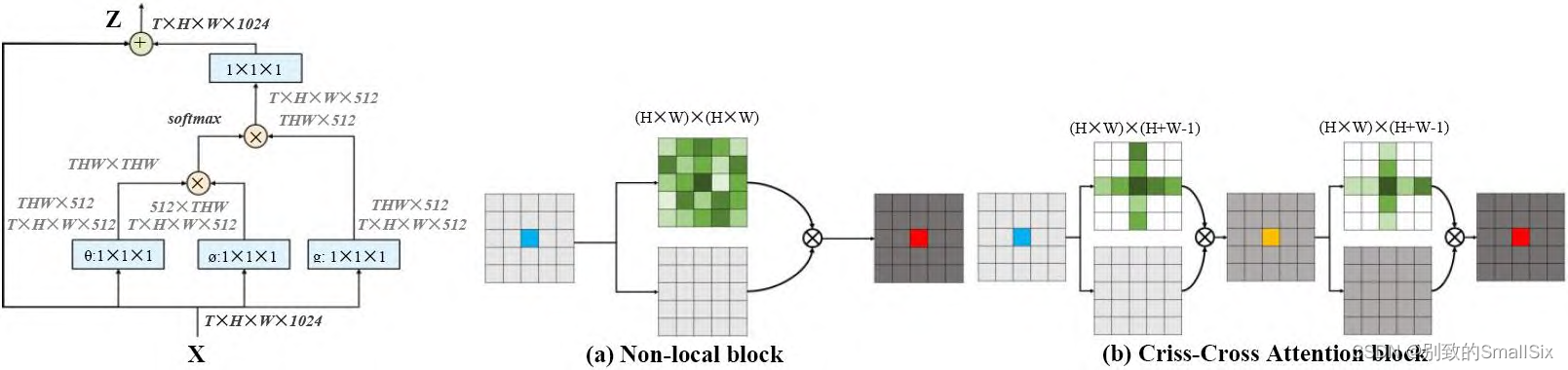
图 14 Non-local 块。(a)非局部自注意力块和(b)十字交叉自注意力模块
4.2 动态权重
动态权重是指为每个实例学习专门的连接权重,以增加模型的容量。[67]中利用动态权重来增加网络
容量,在不增加模型复杂度和训练数据的情况下提高了模型性能。
Han 等人[84]提出了 LR-Net,根据局部窗口内像素与特征之间的组合关系重新聚合其权重。这种自适应权重聚合将几何先验引入网络中,实验表明该方法可以改进图像识别任务。
大体上,动态权重在卷积网络中应用可以分为两类:一类是学习同构连接权重,如 SENet[85]、动态卷积[86]。另一类是学习每个区域或每个位置的权重(GENet[87]、Lite-HRNet[88]、Involution[89])。
4.3 其他方法
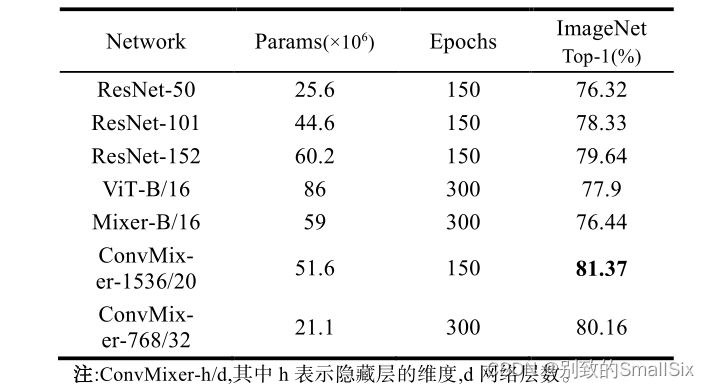
Trockman 等人提出的 ConvMixer[90]模型,仅使用的标准卷积直接将补丁作为输入,其性能要优于 ViT、MLP-Mixer 以及 ResNet 等视觉模型。作者表示这种补丁嵌入结构允许所有下采样同时发生,并立即降低内部分辨率,从而增加视觉感受野大小,使其更容易混合远处的空间信息。表 3 展示了 ConvMixer 与几种方法的对比情况。
表 3 ConvMixer 对比实验
5 总结与展望
本文介绍了视觉 Transformer 模型基本原理和结构,分别从面向性能优化和面向结构改进两个方面对视觉 Transformer 的关键研究问题和最新进展进行了概述和总结,同时以图像分类和目标检测为例介绍了Transformer 在视觉任务上的应用情况。视觉 Transformer 作为一种新的视觉特征学习网络 ,文中结合CNN 对比总结了两种网络结构的差异性和优缺点,并提出了 Transformer+CNN 的混合结构。CNN和 Transformer 相结合具有比直接使用纯 Transformer 更好的性能。然而两者结合的方式有很多不同的方法,如[7]中应用 CNN 提取紧凑特征,[52]中重叠补丁生成等。两者如何相结合才能更有效?对此,开发一个更强大通用的卷积 ViT 模型还需要进行更多研究。
目前,大多数 Transformer 变体模型计算成本很高,需要大量的硬件和计算资源[91-94]。未来一个新的研究方向是应用 CNN 剪枝原理对 Transformer 的可学习特征进行剪枝,降低资源成本,使模型可以更容易的部署在一些实时设备中(如智能手机、监控系统等)。自监督学习的方式可以在无标注数据上对模型进行表征学习,基于 Transformer 的自监督学习可以解决模型对数据的依赖性从而有望实现更强大的性能。此外,视觉Transformer 采用了标准的感知器数据流方式,为时序数据、多模态数据融合和多任务学习提供了一种统一的建模方法,基于 Transformer 模型有望实现更好的信息融合和任务融合。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J].tech.rep., OpenAI, 2018.
[4] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8):9.
[5] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[6] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[7] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. arXiv preprint arXiv:1910.10683, 2019.
[8] 周志华.机器学习:MACHINE LEARNING[M].北京:清华大学出版社,2016:6-10. ZHOU Z H.MACHINE LEARNING[M].Beijing: Tsinghua University Press,2016:6-10.
[9] LeCun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural computation, 1989, 1(4): 541-551.
[10] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[11] Parmar N, Vaswani A, Uszkoreit J, et al. Image transformer[C]//International Conference on Machine Learning. PMLR, 2018: 4055-4064.
[12] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European conference on computer vision. Springer, Cham, 2020: 213-229.
[13] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[14] Zhu X, Su W, Lu L, et al. Deformable detr: Deformable transformers for end-to-end object detection[J]. arXiv preprint arXiv:2010.04159, 2020.
[15] Zhu X, Hu H, Lin S, et al. Deformable convnets v2: More deformable, better results[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9308-9316.
[16] Zheng S, Lu J, Zhao H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 6881-6890.
[17] Zeng Y, Fu J, Chao H. Learning joint spatial-temporal transformations for video inpainting[C]//European Conference on Computer Vision. Springer, Cham, 2020: 528-543.
[18] Shaw P, Uszkoreit J, Vaswani A. Self-attention with relative position representations[J]. arXiv preprint arXiv:1803.02155, 2018.
[19] Liu X, Yu H F, Dhillon I, et al. Learning to encode position for transformer with continuous dynamical model[C]//International Conference on Machine Learning. PMLR,2020: 6327-6335.
[20] Islam M A, Jia S, Bruce N D B. How much position information do convolutional neural networks encode?[J].arXiv preprint arXiv:2001.08248, 2020.
[21] Wang B, Zhao D, Lioma C, et al. Encoding word order in complex embeddings[J]. arXiv preprint arXiv:1912.12333,2019.
[22] Chu X, Tian Z, Zhang B, et al. Conditional positional encodings for vision transformers[J]. arXiv preprint arXiv:2102.10882, 2021.
[23] Child R, Gray S, Radford A, et al. Generating long sequences with sparse transformers[J]. arXiv preprint arXiv:1904.10509, 2019.
[24] Liu Z, Hu H, Lin Y, et al. Swin Transformer V2: Scaling Up Capacity and Resolution[J]. arXiv preprint arXiv:2111.09883, 2021.
[25] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[26] Lin T Y, Maire M, Belongie S, et al. Microsoft coco: Common objects in context[C]//European conference on computer vision. Springer, Cham, 2014: 740-755.
[27] Dai J, Qi H, Xiong Y, et al. Deformable convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 764-773.
[28] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2017: 2117-2125.
[29] Sun Z, Cao S, Yang Y, et al. Rethinking transformer-based set prediction for object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3611-3620.
[30] Zheng M, Gao P, Zhang R, et al. End-to-end object detection with adaptive clustering transformer[J]. arXiv preprint arXiv:2011.09315, 2020.
[31] Beal J, Kim E, Tzeng E, et al. Toward transformer-based object detection[J]. arXiv preprint arXiv:2012.09958, 2020.
[32] Li H, Sui M, Zhao F, et al. Mvt: Mask vision transformer for facial expression recognition in the wild[J]. arXiv preprint arXiv:2106.04520, 2021.
[33] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[C]//International Conference on Machine Learning. PMLR, 2021: 10347-10357.
[34] Chen J N, Sun S, He J, et al. TransMix: Attend to Mix for Vision Transformers[J]. arXiv preprint arXiv:2111.09833,2021.
[35] Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond empirical risk minimization[J]. arXiv preprint arXiv:1710.09412, 2017.
[36] Wang W, Xie E, Li X, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 568-578.
[37] Han K, Xiao A, Wu E, et al. Transformer in transformer[J].Advances in Neural Information Processing Systems, 2021,34.
[38] Chu X, Tian Z, Wang Y, et al. Twins: Revisiting the design of spatial attention in vision transformers[J]. Advances in Neural Information Processing Systems, 2021, 34.
[39] Wang W, Xie E, Li X, et al. PVT v2: Improved baselines with Pyramid Vision Transformer[J]. Computational Visual Media, 2022, 8(3): 415-424.
[40] Wu H, Xiao B, Codella N, et al. Cvt: Introducing convolutions to vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.2021: 22-31.
[41] Xu W, Xu Y, Chang T, et al. Co-scale conv-attentional image transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 9981-9990.
[42] Yuan L, Chen Y, Wang T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 558-567.
[43] Heo B, Yun S, Han D, et al. Rethinking spatial dimensions of vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 11936-11945.
[44] Yuan K, Guo S, Liu Z, et al. Incorporating convolution designs into visual transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.2021: 579-588.
[45] Chen C F, Panda R, Fan Q. Regionvit: Regional-to-local attention for vision transformers[J]. arXiv preprint arXiv:2106.02689, 2021.
[46] Yang J, Li C, Zhang P, et al. Focal self-attention for local-global interactions in vision transformers[J]. arXiv preprint arXiv:2107.00641, 2021.
[47] Dong X, Bao J, Chen D, et al. Cswin transformer: A general vision transformer backbone with cross-shaped windows[J]. arXiv preprint arXiv:2107.00652, 2021.
[48] Liu Y, Sun G, Qiu Y, et al. Transformer in convolutional neural networks[J]. arXiv preprint arXiv:2106.03180, 2021.
[49] Wu S, Wu T, Tan H, et al. Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention[J]. arXiv preprint arXiv:2112.14000, 2021.
[50] He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[J]. arXiv preprint arXiv:2111.06377, 2021.
[51] Strudel R, Garcia R, Laptev I, et al. Segmenter: Transformer for semantic segmentation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 7262-7272.
[52] Xie E, Wang W, Yu Z, et al. SegFormer: Simple and efficient design for semantic segmentation with transformers[J]. Advances in Neural Information Processing Systems,2021, 34.
[53] Jiang Z H, Hou Q, Yuan L, et al. All tokens matter: Token labeling for training better vision transformers[J]. Advances in Neural Information Processing Systems, 2021, 34.
[54] Chen X, Xie S, He K. An empirical study of training self-supervised vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.2021: 9640-9649.
[55] Wang W, Yao L, Chen L, et al. Crossformer: A versatile vision transformer based on cross-scale attention[J]. arXiv e-prints, 2021: arXiv: 2108.00154.
[56] Ryoo M S, Piergiovanni A J, Arnab A, et al. TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?[J]. arXiv preprint arXiv:2106.11297, 2021.
[57] Chen B, Li P, Li B, et al. Psvit: Better vision transformer via token pooling and attention sharing[J]. arXiv preprint arXiv:2108.03428, 2021.
[58] Shazeer N, Lan Z, Cheng Y, et al. Talking-heads attention[J]. arXiv preprint arXiv:2003.02436, 2020.
[59] Zhou D, Shi Y, Kang B, et al. Refiner: Refining self-attention for vision transformers[J]. arXiv preprint arXiv:2106.03714, 2021.
[60] Zhou D, Kang B, Jin X, et al. Deepvit: Towards deeper vision transformer[J]. arXiv preprint arXiv:2103.11886,2021.
[61] Touvron H, Cord M, Sablayrolles A, et al. Going deeperwith image transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 32-42.
[62] Ali A, Touvron H, Caron M, et al. Xcit: Cross-covariance image transformers[J]. Advances in neural information processing systems, 2021, 34.
[63] Zhang P, Dai X, Yang J, et al. Multi-scale vision long-former: A new vision transformer for high-resolution image encoding[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 2998-3008.
[64] Beltagy I, Peters M E, Cohan A. Longformer: The long-document transformer[J]. arXiv preprint arXiv:2004.05150,2020.
[65] Wang P, Wang X, Wang F, et al. Kvt: k-nn attention for boosting vision transformers[J]. arXiv preprint arXiv:2106.00515, 2021.
[66] Xia Z, Pan X, Song S, et al. Vision Transformer with Deformable Attention[J]. arXiv preprint arXiv:2201.00520,2022.
[67] Han Q, Fan Z, Dai Q, et al. Demystifying local vision transformer: Sparse connectivity, weight sharing, and dynamic weight[J]. arXiv preprint arXiv:2106.04263, 2021.
[68] Lin H, Cheng X, Wu X, et al. Cat: Cross attention in vision transformer[J]. arXiv preprint arXiv:2106.05786,2021.
[69] Wu K, Peng H, Chen M, et al. Rethinking and improving relative position encoding for vision transformer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10033-10041.
[70] Tang Y, Han K, Xu C, et al. Augmented shortcuts for vision transformers[J]. Advances in Neural Information Processing Systems, 2021, 34.
[71] Tolstikhin I O, Houlsby N, Kolesnikov A, et al. Mlp-mixer: An all-mlp architecture for vision[J]. Advances in Neural Information Processing Systems, 2021, 34.
[72] Touvron H, Bojanowski P, Caron M, et al. Resmlp: Feed-forward networks for image classification with data-efficient training[J]. arXiv preprint arXiv:2105.03404,2021.
[73] Melas-Kyriazi L. Do you even need attention? a stack of feed-forward layers does surprisingly well on imagenet[J].arXiv preprint arXiv:2105.02723, 2021.
[74] Chen J, Lu Y, Yu Q, et al. Transunet: Transformers make strong encoders for medical image segmentation[J]. arXiv preprint arXiv:2102.04306, 2021.
[75] Xiao T, Singh M, Mintun E, et al. Early convolutions help transformers see better[J]. Advances in Neural Information Processing Systems, 2021, 34: 30392-30400.
[76] Li K, Wang Y, Zhang J, et al. UniFormer: Unifying Convolution and Self-attention for Visual Recognition[J]. arXiv preprint arXiv:2201.09450, 2022.
[77] Graham B, El-Nouby A, Touvron H, et al. LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 12259-12269.
[78] Wang X, Girshick R, Gupta A, et al. Non-local neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7794-7803.
[79] d’Ascoli S, Touvron H, Leavitt M L, et al. Convit: Improving vision transformers with soft convolutional inductive biases[C]//International Conference on Machine Learning. PMLR, 2021: 2286-2296.
[80] Peng Z, Huang W, Gu S, et al. Conformer: Local features coupling global representations for visual recognition[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 367-376.
[81] Chen Y, Dai X, Chen D, et al. Mobile-former: Bridging mobilenet and transformer[J]. arXiv preprint arXiv:2108.05895, 2021.
[82] Huang Z, Wang X, Huang L, et al. Ccnet: Criss-cross attention for semantic segmentation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.12019: 603-612.
[83] Srinivas A, Lin T Y, Parmar N, et al. Bottleneck transformers for visual recognition[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 16519-16529.
[84] Hu H, Zhang Z, Xie Z, et al. Local relation networks for image recognition[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 3464-3473.
[85] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[86] Jia X, De Brabandere B, Tuytelaars T, et al. Dynamic filter networks[J]. Advances in neural information processing systems, 2016, 29.
[87] Hu J, Shen L, Albanie S, et al. Gather-excite: Exploiting feature context in convolutional neural networks[J]. Advances in neural information processing systems, 2018, 31.
[88] Yu C, Xiao B, Gao C, et al. Lite-hrnet: A lightweight high-resolution network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2021: 10440-10450.
[89] Li D, Hu J, Wang C, et al. Involution: Inverting the inherence of convolution for visual recognition[C]//Proceedingsmof the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12321-12330.
[90] Trockman A, Kolter J Z. Patches Are All You Need?[J].arXiv preprint arXiv:2201.09792, 2022.
[91] Khan S, Naseer M, Hayat M, et al. Transformers in vision: A survey[J]. ACM Computing Surveys (CSUR), 2021.
[92] Han K, Wang Y, Chen H, et al. A survey on visual transformer[J]. arXiv e-prints, 2020: arXiv: 2012.12556.
[93] 田永林, 王雨桐, 王建功,等. 视觉 Transformer 研究的关键问题: 现状及展望 [J]. 自动化学报, 2022, 48(4):957-979.Tian Yong-Lin, Wang Yu-Tong, Wang Jian-Gong, Wang Xiao, Wang Fei-Yue. Key problems and progress of vision Transformers: The state of the art and prospects[J]. Acta Automatica Sinica, 2022, 48(4): 957-979 doi:10.16383/j.aas.c220027
[94] 刘文婷, 卢新明. 基于计算机视觉的 Transformer 研究进展[J]. 计算机工程与应用, 2022, 58(6): 1-16.LIU Wenting, LU Xinming. Research Progress of Transformer Based on Computer Vision[J]. Computer Engineering and Applications, 2022, 58(6): 1-16.