5.1 整体介绍
- 获取执行环境
- 读取数据源
- 定义基于数据的转换操作
- 定义计算结果的输出位置
- 触发程序执行
5.2 创建集成环境
5.2.1 获取执行环境
- 批处理getExecutionEnvironment
- 提交命令行设置
bin/flink run -Dexecution.runtime-mode=BATCH ...
- 代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
使用StreamExecutionEnvironment类调用getExecutionEnvironment的方法[不推荐,直接写死了]
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
设置setRuntimeMode 方法,传入 BATCH 模式
- 流处理
// 批处理环境
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
5.3 源算子
5.3.1 读取有界流
- 数据准备
- 基本数据类型
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
//无参构造方法
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}
基本数据类型有:用户名、url以及时间戳
- 文件
Mary,./home,1000
Alice,./cart,2000
Bob,./prod?id=100,3000
Bob,./cart,4000
Bob,./home,5000
Mary,./home,6000
Bob,./cart,7000
Bob,./home,8000
Bob,./prod?id=10,9000
- 代码
3种了,从文件,从集合,从元素
public class SourceTest {
public static void main(String[] args) throws Exception{
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.从文件中读取数据(有界流)
DataStreamSource<String> stream1 = env.readTextFile("input/clicks.txt");
//3.从集合中读取数据
ArrayList<Integer> nums = new ArrayList<>();
nums.add(2);
nums.add(5);
DataStreamSource<Integer> numsStream = env.fromCollection(nums);
//泛型选择event,从event读取数据
ArrayList<Event> events = new ArrayList<>();
events.add(new Event("Mary","./home",1000L));
events.add(new Event("Bob","./cart",2000L));
DataStreamSource<Event> stream2 = env.fromCollection(events);
//4.从元素读取数据
//不用通过数组中间装载,直接可以放到fromElement中
DataStreamSource<Event> stream3 = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L));
stream1.print();
numsStream.print();
stream2.print();
stream3.print();
env.execute();
}
}
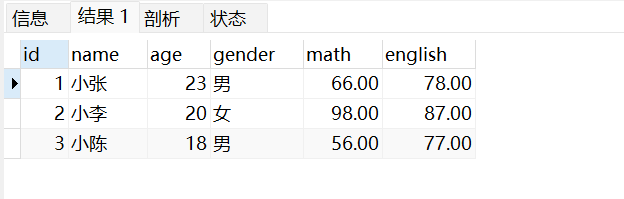
- 结果
2
5
Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:01.0}
Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:01.0}
Event{user='Bob', url='./cart', timestamp=1970-01-01 08:00:02.0}
Event{user='Bob', url='./cart', timestamp=1970-01-01 08:00:02.0}
Mary,./home,1000
Alice,./cart,2000
Bob,./prod?id=100,3000
Bob,./cart,4000
Bob,./home,5000
Mary,./home,6000
Bob,./cart,7000
Bob,./home,8000
Bob,./prod?id=10,9000
Process finished with exit code 0
5.3.2 从socket读取数据
- 启动hadoop2虚拟机中的nc -lk
- 代码
//5.从socket文本流读取
DataStreamSource<String> stream4 = env.socketTextStream("hadoop2", 7777);
stream4.print();
env.execute();
- 结果

5.3.3 读取kafka
- 引入连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
- 启动kafka
- 启动zk和kadfa
[hadoop1@hadoop2 kafka]$ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
[hadoop1@hadoop2 kafka]$ ./bin/kafka-server-start.sh -daemon ./config/server.properties
- 启动生产者
[hadoop1@hadoop2 kafka]$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic clicks
- 启动程序
使用addSource方法中传入flink连接器传入的FlinkKafkaConsumer
//6.从kafka读取数据
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","hadoop2:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));
kafkaStream.print();
env.execute();
- 结果

5.3.4 自定义Source
- 思路
自定义实现SourceFunction接口,重写两个方法run()和cancel()



- 代码
public class SourceCustomTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> customStream = env.addSource(new ClickSource());
customStream.print();
env.execute();
}
}
- 自定义的ClickSource
public class ClickSource implements SourceFunction<Event> {
//声明一个标志位控制数据生成
private Boolean running = true;
@Override
//泛型为Event
public void run(SourceContext<Event> ctx) throws Exception {
//随机生成数据
Random random = new Random();
//定义字段选取的数据集
String[] users = {"Mary","Alice","Bob","Cary"};
String[] urls = {"./home","./cart","./fav","./prod?id=100","/prod?id=10"};
//一直循环生成数据
while (running){
String user = users[random.nextInt(users.length-1)];
String url = users[random.nextInt(urls.length-1)];
//系统当前事件的毫秒数
Long timestamp = Calendar.getInstance().getTimeInMillis();
//collect收集Event发往下游
ctx.collect(new Event(user,url,timestamp));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running =false;
}
}
- 结果

5.3.5 自定义并行Source
- 分析





传入的还是SourceFunction,于是说如果是继承了ParallelSourceFunction的话,就可以设置并行度
- 代码
public class SourceCustomTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//DataStreamSource<Event> customStream = env.addSource(new ClickSource());
//这边并行度改成2
DataStreamSource<Integer> customStream = env.addSource(new ParallelCustomSource())
.setParallelism(2);
customStream.print();
env.execute();
}
//定义一个静态类吧
//实现自定义的并行SourceFunction
public static class ParallelCustomSource implements ParallelSourceFunction<Integer> {
//同样来一个标志位
private Boolean running =true;
private Random random = new Random();
@Override
public void run(SourceContext<Integer> ctx) throws Exception {
while (running){
ctx.collect(random.nextInt());
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
}
- 结果




![静态时序分析简明教程(六)]时钟组与其他时钟特性](https://img-blog.csdnimg.cn/be8a2060bc2b4fb4b23142d5a3415482.png)