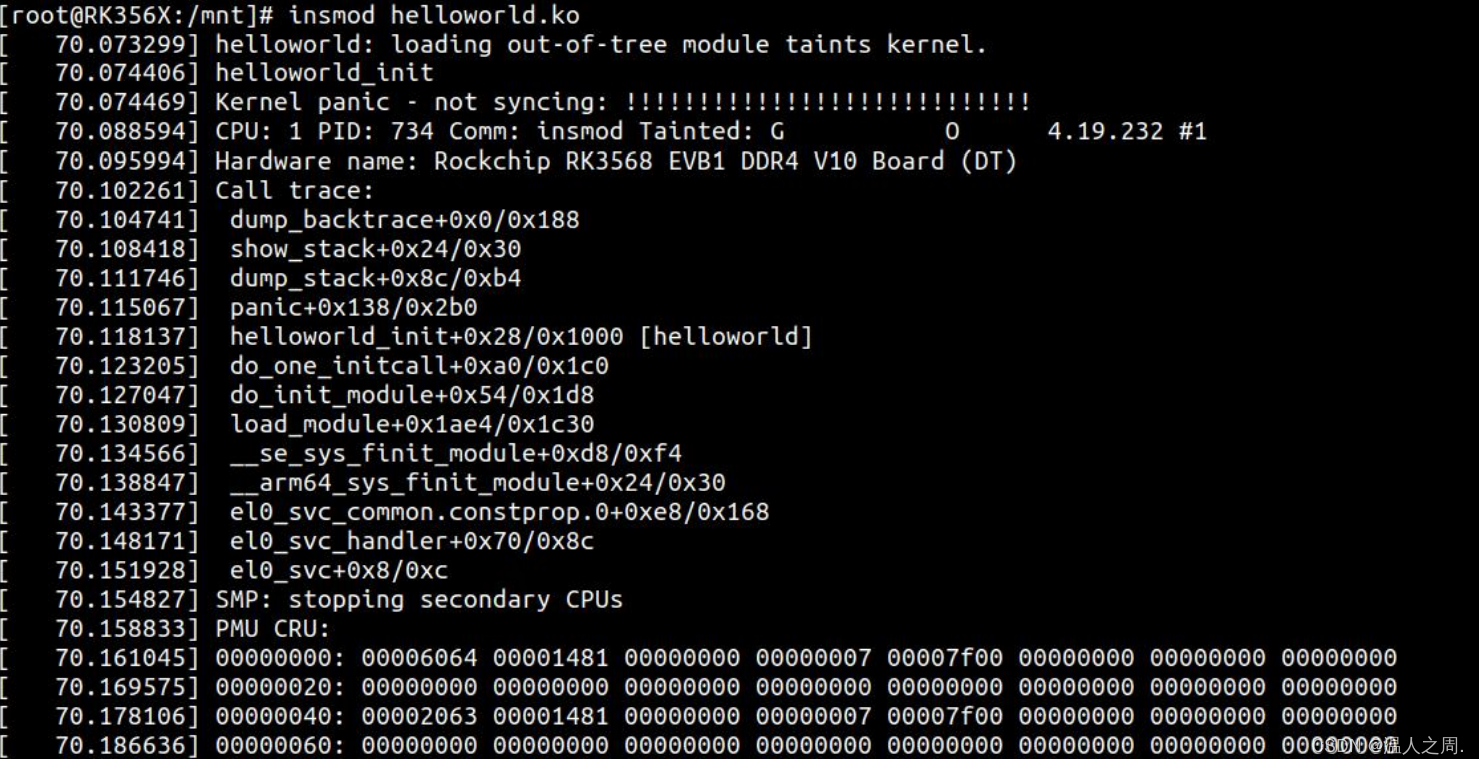
以下是一个使用Scala和Sttp库编写的视频爬虫程序,该程序使用了proxy来获取IP。请注意,这个示例需要在上找到一个具体的视频链接,然后将其传递给crawlVideo函数。
import scala.util.{Failure, Success}
import scala.concurrent.{Future, ExecutionContext}
import sttp.client3._
object FacebookCrawler {
def main(args: Array[String]): Unit = {
val proxyUrl = ""
val facebookUrl = ""
val videoUrl = "your_video_url_here" // 请将此处更改为你要爬虫的视频链接
val sttpBackend = new BlockingSttpBackend(executionContext)
val client = new SttpClient(sttpBackend)
val proxyResponse: Future[Either[String, String]] = client.send(get(proxyUrl)).map(_.body)
val videoResponse: Future[Either[String, String]] = client.send(get(videoUrl).header("Referer", facebookUrl)).map(_.body)
for {
proxy <- proxyResponse
video <- videoResponse
} yield {
println("IP: " + proxy)
println("视频内容: " + video)
}
}
def getProxy(client: SttpClient[Future, Nothing], executionContext: ExecutionContext): Future[Either[String, String]] = {
client.send(get("")).map(_.body)
}
def crawlVideo(client: SttpClient[Future, Nothing], executionContext: ExecutionContext, videoUrl: String): Future[Either[String, String]] = {
client.send(get(videoUrl).header("Referer", "")).map(_.body)
}
}
在这个示例中,我们首先获取了一个IP地址,然后使用这个IP地址向发送一个请求,获取视频,你需要根据你的具体需求调整代码。在实际应用中,你可能需要处理错误、加入异常处理、添加日志等。