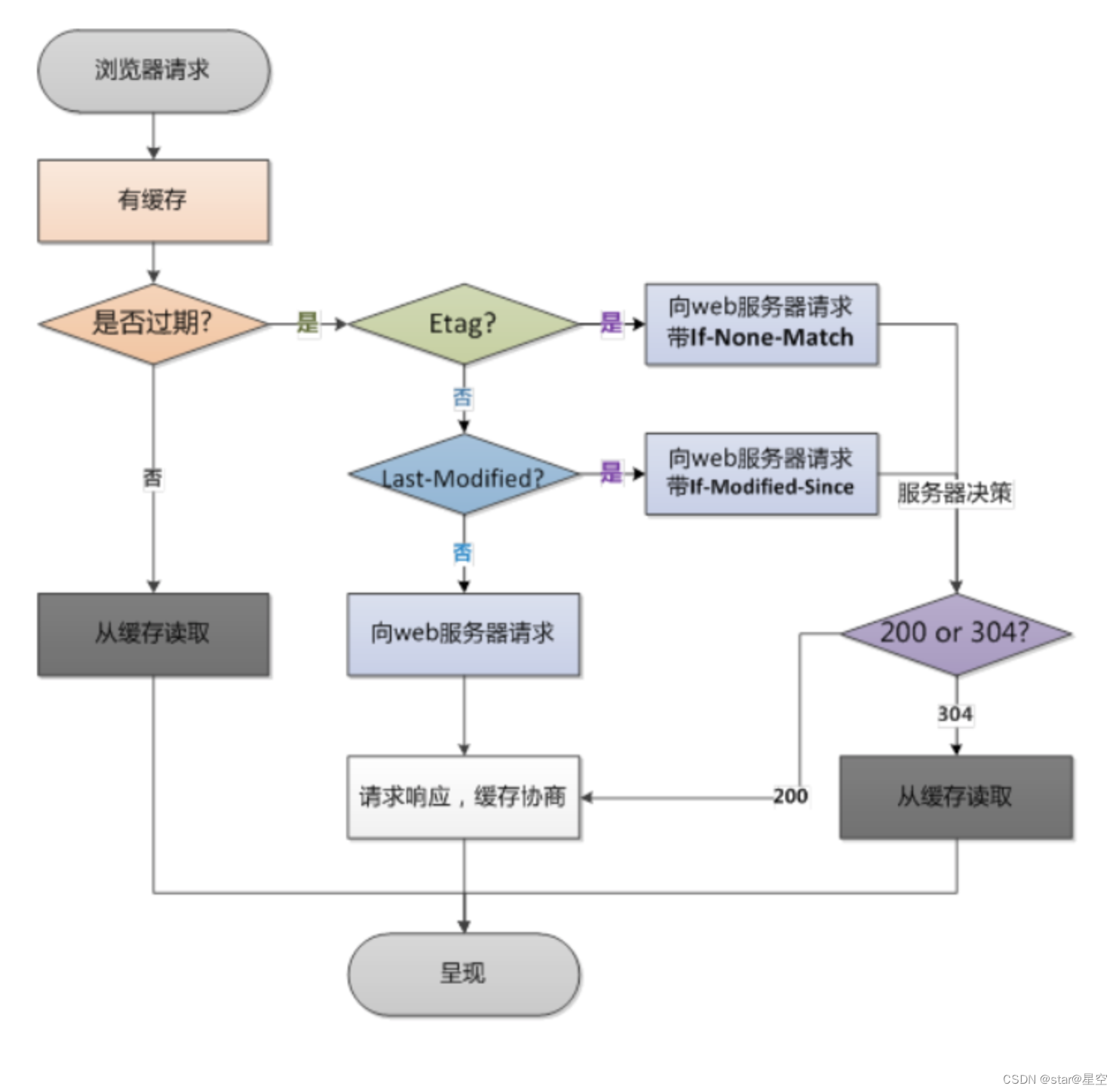
以下是一个使用Selenium和Java编写的音频爬虫程序,该程序使用了proxy的代码。请注意,这个示例需要在IDE中运行,并且可能需要根据您的系统和需求进行调整。
import java.io.IOException;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
public class TikTokCrawler {
public static void main(String[] args) {
// 设置浏览器用户
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
DesiredCapabilities capabilities = DesiredCapabilities.chrome();
capabilities.setCapability("chrome.binary", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe");
capabilities.setCapability("chrome.userDataDir", "C:\\Users\\your_username\\AppData\\Local\\Temp\\scratch\\chrome_scratch");
capabilities.setCapability("general.useragent", userAgent);
capabilities.setCapability("general.proxy", "http://127.0.0.1:1080");
// 创建ChromeDriver实例
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);
// 打开TikTok网站
driver.get("https://www.tiktok.com");
// 等待网页加载
try {
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 查找音频元素
List<WebElement> audioElements = driver.findElements(By.tagName("audio"));
// 遍历音频元素
for (WebElement audioElement : audioElements) {
// 获取音频URL
String audioUrl = audioElement.getAttribute("src");
// 下载音频文件
// 这里需要实现一个下载功能,例如使用Java的URLConnection或者其他第三方库
// 下载完成后,您可以将音频文件保存到本地磁盘或者其他存储设备上
// 处理下一个音频元素
}
// 关闭浏览器
driver.quit();
}
}
这个示例代码使用了Selenium的ChromeDriver,并设置了一个用户。它首先访问,然后查找并下载页面上的音频文件。请注意,这个示例需要在IDE中运行,并且可能需要根据您的系统和需求进行调整。