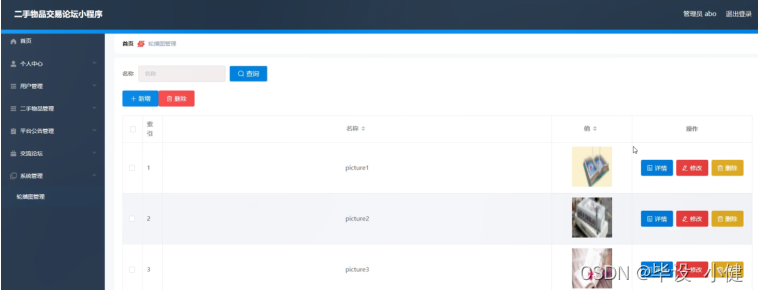
今天刚发表的一篇论文提出来了针对小目标和低分辨率图像检测性能提升的技术SPD-Conv,感觉还是挺有意义的,今天主要是基于这项技术融合进yolov5s模型中来开发对应的目标检测模型,实现五子棋的检测,本身五子棋就是比较密集的小目标检测,先来看下效果图:

论文详情如下:
《No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects》
2022年8月7日发表在ECML PKDD 2022论文集上的最新paper
作者:来自于 Missouri 大学的 Raja Sunkara and Tie Luo
论文地址:https://arxiv.org/abs/2208.03641v1
论文截图如下所示:



感兴趣的话可以自行下载仔细研读。
项目地址在这里,首页截图如下所示:

yolov5可以说是yolo系列里面开发广度和深度维系最久的一款模型了知名度也是很高的,官方的项目地址在这里,首页截图如下所示:

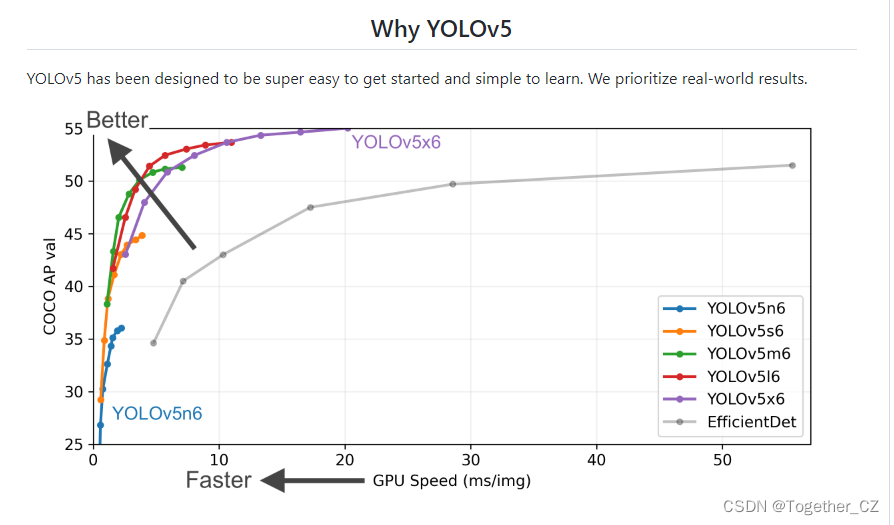
目前已经有34k的star量,还是很优秀的一个开源项目的,yolov5提供了n、s、m、l和x五种不同型号的模型,体积和参数量也是逐步递增的,我这里选用的是yolov5s系列的模型。
space_to_depth的核心实现如下:
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
# size_tensor = x.size()
# return torch.cat([x[...,0:size_tensor[2]//2,0:size_tensor[3]//2],
# x[...,0:size_tensor[2]//2,size_tensor[3]//2:],
# x[...,size_tensor[2]//2:,0:size_tensor[3]//2],
# x[...,size_tensor[2]//2:,size_tensor[3]//2:] ],1)这是官方提供的实现方式应该是验证可行的,可以直接使用。
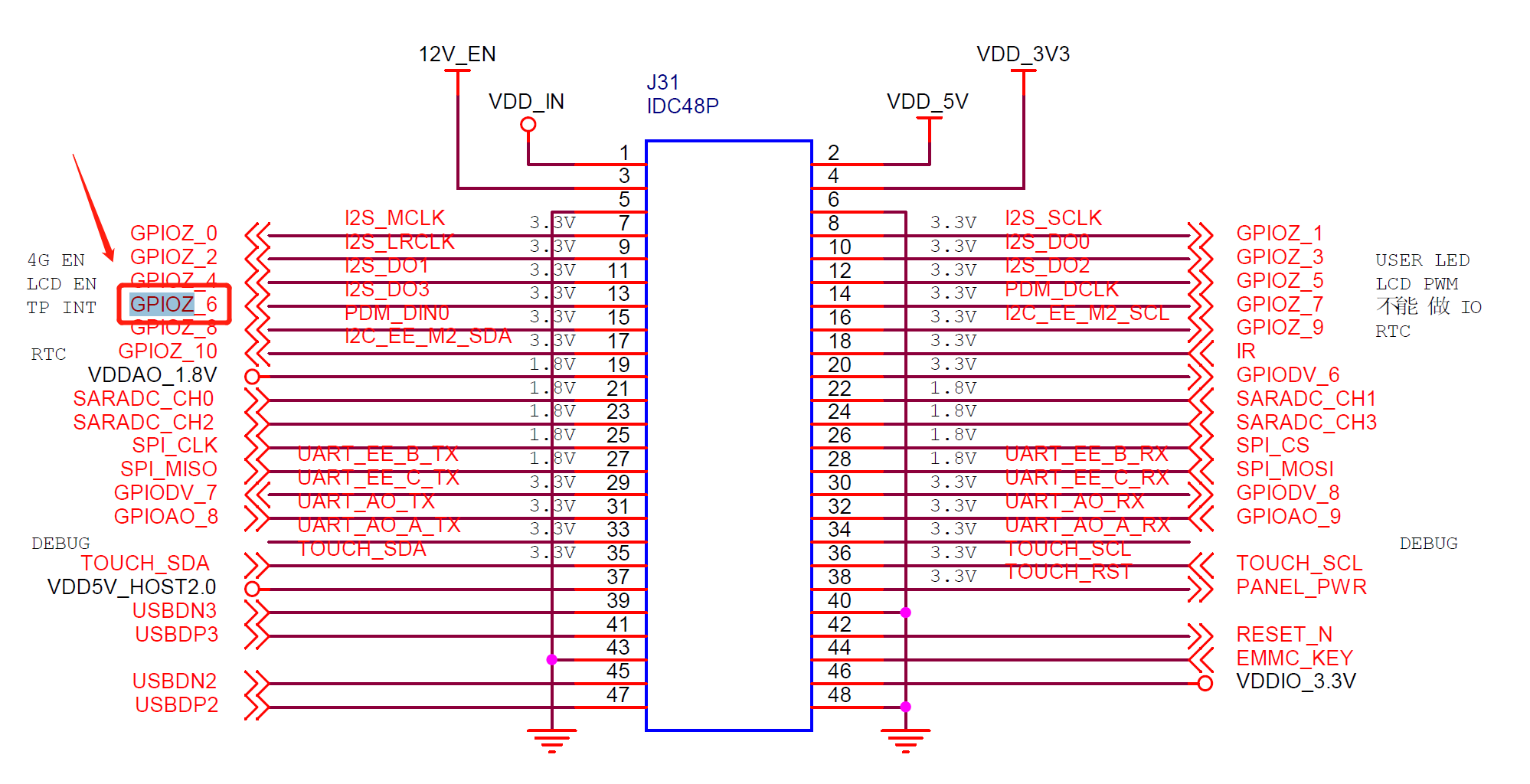
复制一份原始yolov5s.yaml,重命名为yolov5s_spd.yaml,内容如下:
#Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 1]], # 1
[-1,1,space_to_depth,[1]], # 2 -P2/4
[-1, 3, C3, [128]], # 3
[-1, 1, Conv, [256, 3, 1]], # 4
[-1,1,space_to_depth,[1]], # 5 -P3/8
[-1, 6, C3, [256]], # 6
[-1, 1, Conv, [512, 3, 1]], # 7-P4/16
[-1,1,space_to_depth,[1]], # 8 -P4/16
[-1, 9, C3, [512]], # 9
[-1, 1, Conv, [1024, 3, 1]], # 10-P5/32
[-1,1,space_to_depth,[1]], # 11 -P5/32
[-1, 3, C3, [1024]], # 12
[-1, 1, SPPF, [1024, 5]], # 13
]
#head
head:
[[-1, 1, Conv, [512, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15
[[-1, 9], 1, Concat, [1]], # 16 cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]], # 18
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19
[[-1, 6], 1, Concat, [1]], # 20 cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 1]], # 22
[-1,1,space_to_depth,[1]], # 23 -P2/4
[[-1, 18], 1, Concat, [1]], # 24 cat head P4
[-1, 3, C3, [512, False]], # 25 (P4/16-medium)
[-1, 1, Conv, [512, 3, 1]], # 26
[-1,1,space_to_depth,[1]], # 27 -P2/4
[[-1, 14], 1, Concat, [1]], # 28 cat head P5
[-1, 3, C3, [1024, False]], # 29 (P5/32-large)
[[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]因为我这里要检测的是五子棋,只有黑白两种基础的目标对象,所以这里同步修改了nc=2,可以根据自己的实际需求来修改具体的nc值。
接下来看下数据集:

单样本标注实例如下所示:
0 0.366667 0.235185 0.059259 0.059259
0 0.431481 0.431481 0.059259 0.059259
0 0.431481 0.366667 0.059259 0.059259
0 0.627778 0.366667 0.059259 0.059259
0 0.3 0.694444 0.059259 0.059259
0 0.498148 0.431481 0.059259 0.059259
0 0.3 0.562963 0.059259 0.059259
0 0.366667 0.431481 0.059259 0.059259
0 0.3 0.431481 0.059259 0.059259
0 0.3 0.498148 0.059259 0.059259
0 0.431481 0.627778 0.059259 0.059259
0 0.627778 0.759259 0.059259 0.059259
1 0.498148 0.498148 0.059259 0.059259
1 0.431481 0.562963 0.059259 0.059259
1 0.562963 0.431481 0.059259 0.059259
1 0.366667 0.627778 0.059259 0.059259
1 0.498148 0.562963 0.059259 0.059259
1 0.366667 0.562963 0.059259 0.059259
1 0.366667 0.498148 0.059259 0.059259
1 0.498148 0.627778 0.059259 0.059259
1 0.235185 0.431481 0.059259 0.059259
1 0.3 0.627778 0.059259 0.059259
1 0.562963 0.694444 0.059259 0.059259
1 0.498148 0.694444 0.059259 0.059259
训练模型的方式可以参考官方yolov5项目README操作即可。教程地址在这里,首页截图如下所示:
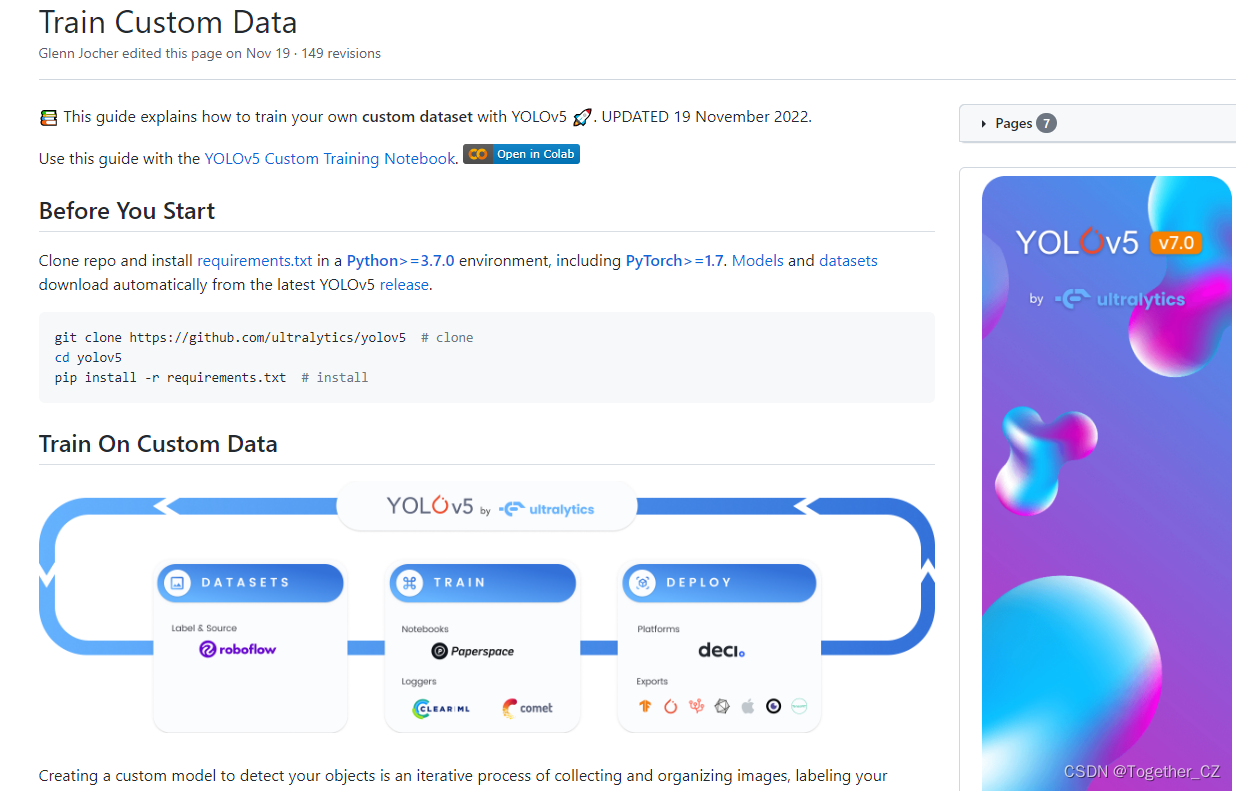
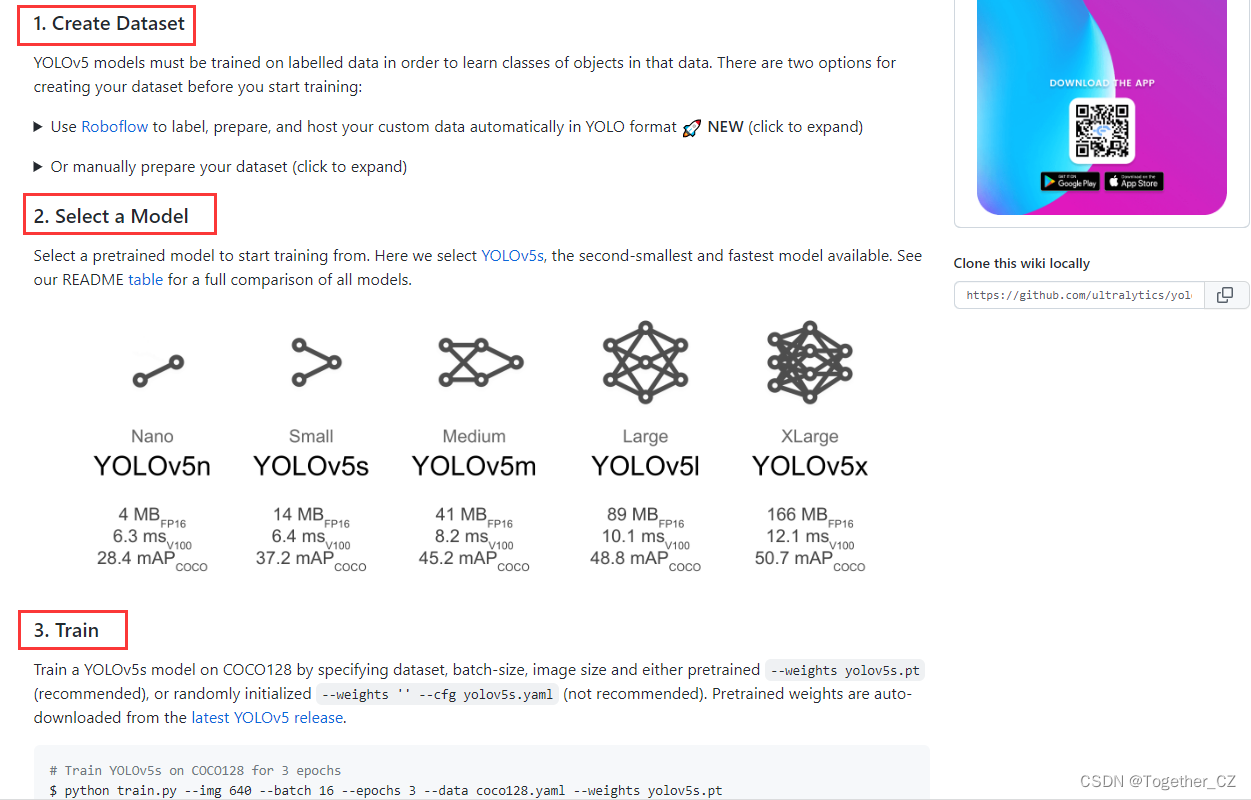
教程还是很详细的,通俗易懂,这里我就不再班门弄斧了。
启动训练后,日志输出如下所示:
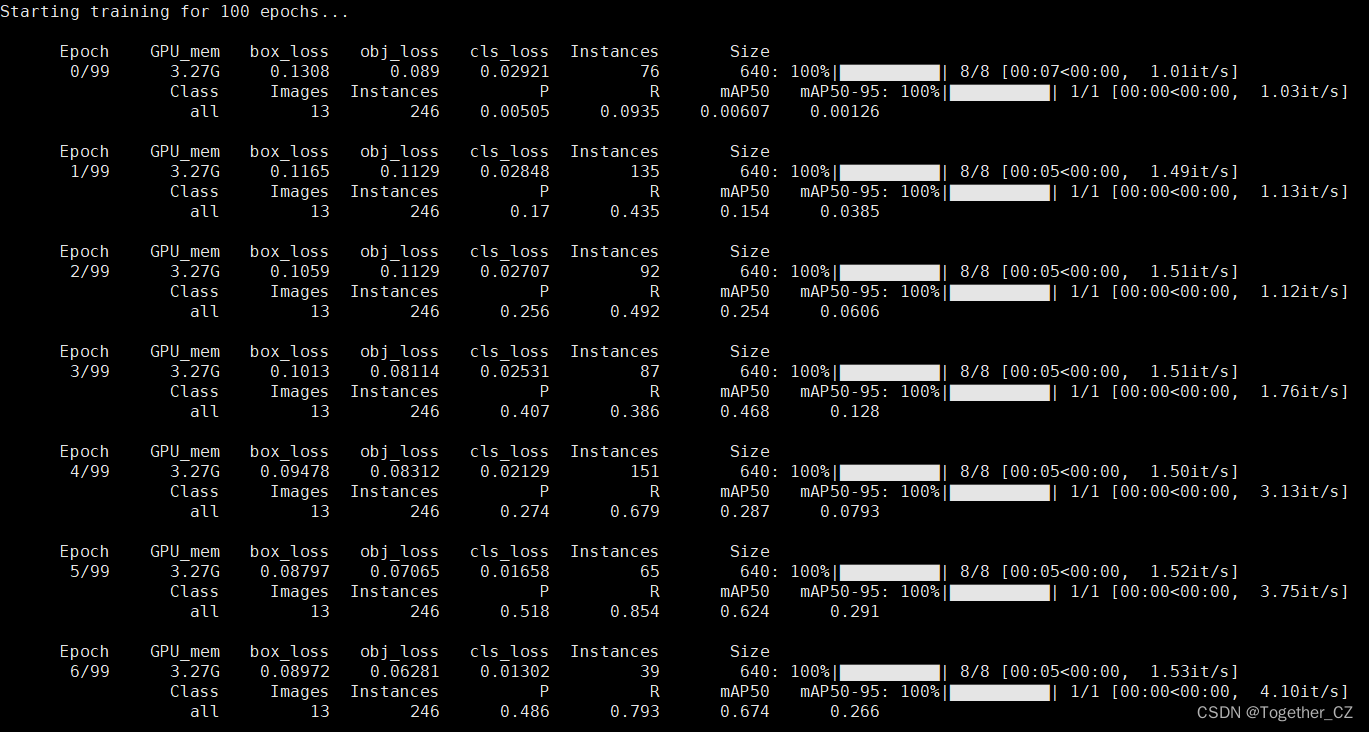

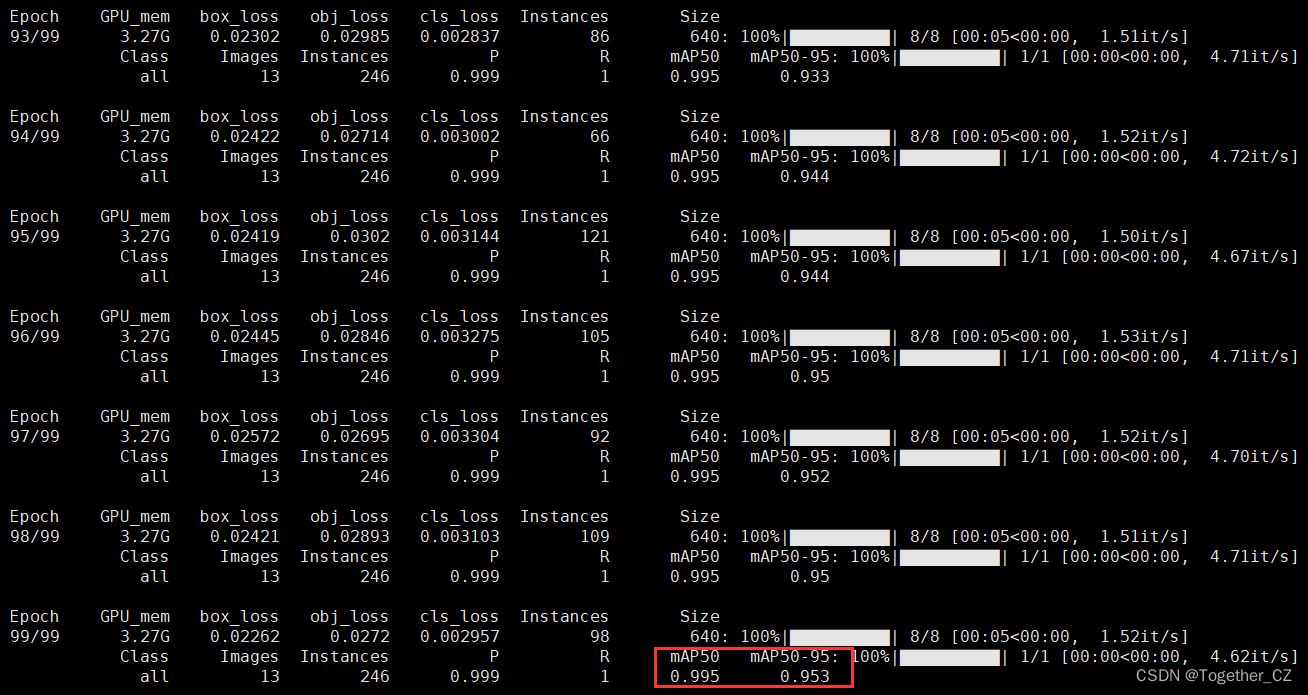
默认100epoch的迭代计算,可以看到:训练结束后得到的mAP指标已经很好了。
为了更加直观简洁地使用训练好的模型,这里编写了对应的界面模块,启动界面如下:

上传检测图像:

推理检测识别:
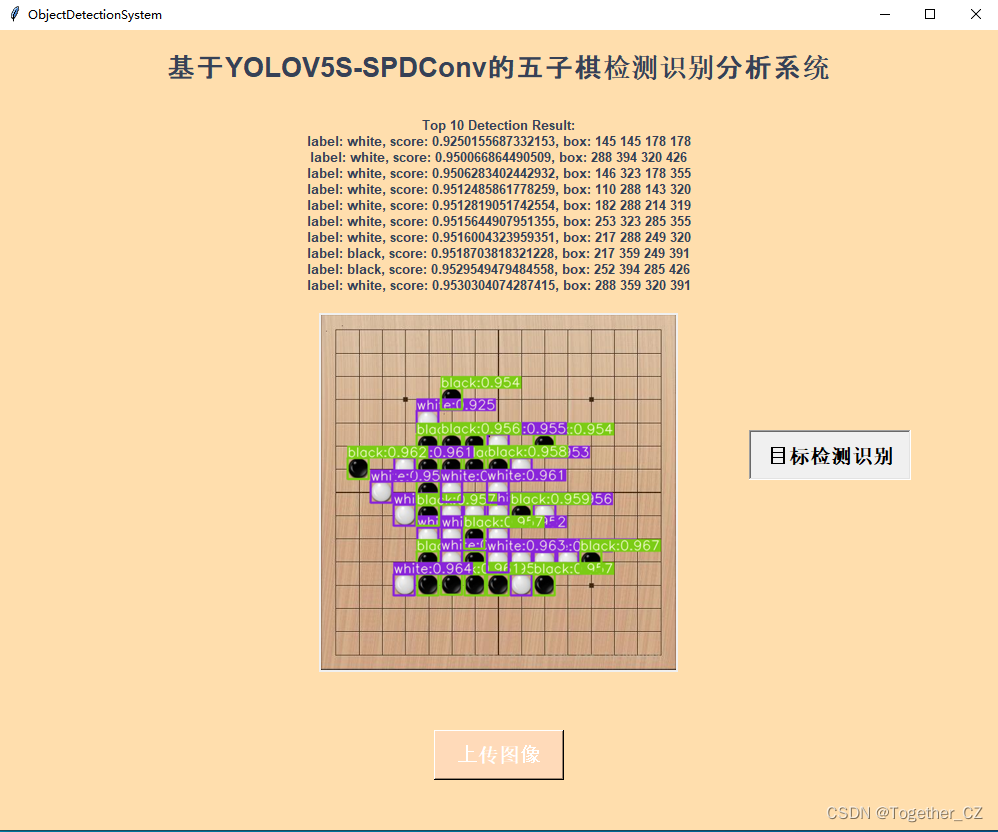


随机测试图像,可以看到整体的检测效果还是很不错的,检测框也是很贴合围棋棋子的边界。