文章目录
- 一、MySQL外键基本概念
- 1. 表与表之间的关系
- 1.一对多的表关系
- 2.多对多
- 3.一对一
- 注意事项
- 2.多表查询
- 1.子查询
- 2.数据准备
- 3.连表查询(重点)
- 二、多表查询练习题
- 1.习题
- 试题的SQL文件
- 2.Navicata可视化软件
- 1.连接数据库
- 2 操作数据库
- 3.导入备份
- 4.查询数据
- 5.修改用户信息
一、MySQL外键基本概念
1、MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种。不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引。用于外键关系的字段必须在所有的参照表中进行明确地索引,InnoDB不能自动地创建索引。
2、外键可以是一对一的,一个表的记录只能与另一个表的一条记录连接,或者是一对多的,一个表的记录与另一个表的多条记录连接。
3、如果需要更好的性能,并且不需要完整性检查,可以选择使用MyISAM表类型,如果想要在MySQL中根据参照完整性来建立表并且希望在此基础上保持良好的性能,最好选择表结构为innoDB类型。
"""
缺陷
1.表的重点不清晰 可以忽略
到底是员工表还是部门表
2.表中相关字段一直在重复存储 可以忽略
浪费存储空间
3.表的扩展性极差,牵一发而动全身 不能忽略
"""
解决方式
将上述一张表拆分成两张表
emp与dep
上述的三个问题可以解决
但是带来了一个小问题,表与表之间的数据没有对应关系了
可以添加外键字段(部门编号)让你渠道其他表中查找数据
1. 表与表之间的关系
1.一对多的表关系
如何判断表的关系:换位思考法
以员工表和部门表为例:
先站在员工表
问:一个员工能否有多个部门?
答:不能
再站在部门表
问:一个部门能否有多个员工?
答:可以
结论:一个可以,一个不可以,表的关系就是:一对多,表关系中没有多对一,针对于一对多,外键字段要建在多的一方
如何在SQL层面建立一对多的关系:先把基础表中的基础字段建立出来,然后在考虑外部字段
首先需要建立出部门表才能再建立员工表
部门表:
create table dep(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(32)
);
员工表:
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade # 级联删除
);
'''在员工表里添加外键,dep_id是绑定对象,绑定给部门表里的id
还需要在后面添加上两个语句,级联更新和级联删除
'''
录入数据:
录入数据也需要先录入部门的:
insert into dep(dep_name,dep_desc) values('人事部','管理员工'),('财务部','管理资金'),('技术部','软件开发');
+----+-----------+--------------+
| id | dep_name | dep_desc |
+----+-----------+--------------+
| 1 | 人事部 | 管理员工 |
| 2 | 财务部 | 管理资金 |
| 3 | 技术部 | 软件开发 |
+----+-----------+--------------+
员工:
insert into emp(name, age, dep_id) values('jack',18,1),('tank',19,1),('jarry',20,2),('kevin',18,3);
+----+-------+------+--------+
| id | name | age | dep_id |
+----+-------+------+--------+
| 1 | jack | 18 | 1 |
| 2 | tank | 19 | 1 |
| 3 | jarry | 20 | 2 |
| 4 | kevin | 18 | 3 |
+----+-------+------+--------+
2.多对多
以图书表和作者表为例
我们站在图书表的角度
问:一本图书能不能有多个作者?
答:可以
我们再站在作者表的角度
问:一个作者能不能写多本书
答:可以
结论:如果两个都可以,那么表关系就是多对多,针对多对多的表关系,外键字段在第三张表中
针对于多对多的表关系,外键字段如何创建
先创建一个书的表:
create table book(
id int primary key auto_increment,
title varchar(32),
price decimal(8,2)
);
在创建一个作者的表:
create table book(
id int primary key auto_increment,
title varchar(32),
price decimal(8,2)
);
最后再创建一个外键(包含作者和书的):
create table book2author(
id int primary key auto_increment,
book_id int,
author_id int,
foreign key(book_id) references author(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade, # 级联删除
foreign key(author_id) references book(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade # 级联删除
);
录入书表的数据:
insert book(title,price) values('水浒传',50);
insert book(title,price) values('西游记',100);
+----+-----------+--------+
| id | title | price |
+----+-----------+--------+
| 1 | 水浒传 | 50.00 |
| 2 | 西游记 | 100.00 |
+----+-----------+--------+
录入作者表的数据
insert into author(name,addr) values('施耐庵','江苏');
insert into author(name,addr) values('罗贯中','山西');
+----+-----------+--------+
| id | name | addr |
+----+-----------+--------+
| 1 | 施耐庵 | 江苏 |
| 2 | 罗贯中 | 山西 |
+----+-----------+--------+
添加外键数据:
insert into book_author(book_id,author_id) values(2,1);
insert into book_author(book_id,author_id) values(1,1);
insert into book_author(book_id,author_id) values(1,2),(2,2);
+----+---------+-----------+
| id | book_id | author_id |
+----+---------+-----------+
| 1 | 2 | 1 | 一个作者拥有两本书
| 2 | 1 | 1 |
| 3 | 1 | 2 |
| 4 | 2 | 2 |
+----+---------+-----------+
3.一对一
以作者表和作者详情表为例
外键关系建立在哪里?
两张表都可以,但是,推荐建在查询频率较高的一张表
先建立出作者详情表:
create table author_detail(
id int primary key auto_increment,
qq varchar(32),
email varchar(32)
);
再建立出作者表:
create table author1(
id int primary key auto_increment,
name varchar(32),
age int,
gender varchar(32),
author_detail_id int unique,
foreign key(author_detail_id) references author_detail(id)
on update cascade
on delete cascade
);
先录入作者详情数据:
insert into author_detail(qq,emial) values('123456789','qerqwe@qq.com');
insert into author_detail(qq,email)values('123123123123','axecefdicd@gmail.com');
在录入作者数据:
insert into author1(name,age,gender,author_detail_id) values('zhangsan',30,'male',1);
insert into author1(name, age, gender, author_detail_id) values('lisi',40,'male',2);
注意事项
1.在创建表的时候 需要先创建被关联表(没有外键字段的表)
2.在插入新数据的时候 应该先确保被关联表中有数据
3.在插入新数据的时候 外键字段只能填写被关联表中已经存在的数据
4.在修改和删除被关联表中的数据的时候 无法直接操作
如果想要数据之间自动修改和删除需要添加额外的配置
2.多表查询
在此之前,都是单表下查询
多表查询的思路是:
1.子查询
查询jack的部门名称
应该先查询jack 的部门编号(部门表的id)
select dep_id from emp where name='jack';
+--------+
| dep_id |
+--------+
| 1 |
+--------+
select * from dep where id=(select dep_id from emp where name='jack');
+----+-----------+--------------+
| id | dep_name | dep_desc |
+----+-----------+--------------+
| 1 | 人事部 | 管理员工 |
+----+-----------+--------------+
子查询就是:一条SQL的执行结果就是另外一条SQL的执行条件!
其实就是分步操作
2.数据准备
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
"""如果两张表没有建立强制的约束关系,就使用逻辑意义上的关联"""
#插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'保洁')
;
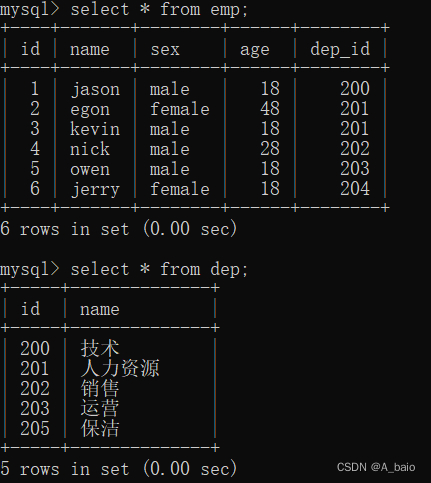
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('egon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
将以上数据录入以后,会得到这样的两张表:
3.连表查询(重点)
把多张有关系的表链接成一张大的虚拟表,连接出来的虚拟表不是实际存在的,它是在内存中存储,然后按照单表查询
专业的连表语法:
inner join 内连接,查询的是两张表中都有的数据
left join 左连接,以左表为基准,查询左表中所有的数据,右表没有的数据,使用NULL填充
right join 右连接,以右表为基准,查询右表中所有的数据,右表没有的数据,使用NULL填充
union 连接两个SQL语句的结果
1.使用内连接
select * from emp inner join dep;
+----+-------+--------+------+--------+-----+--------------+
| id | name | sex | age | dep_id | id | name |
+----+-------+--------+------+--------+-----+--------------+
| 1 | jason | male | 18 | 200 | 200 | 技术 |
| 1 | jason | male | 18 | 200 | 201 | 人力资源 |
| 1 | jason | male | 18 | 200 | 202 | 销售 |
| 1 | jason | male | 18 | 200 | 203 | 运营 |
| 1 | jason | male | 18 | 200 | 205 | 保洁 |
| 2 | egon | female | 48 | 201 | 200 | 技术 |
| 2 | egon | female | 48 | 201 | 201 | 人力资源 |
| 2 | egon | female | 48 | 201 | 202 | 销售 |
| 2 | egon | female | 48 | 201 | 203 | 运营 |
| 2 | egon | female | 48 | 201 | 205 | 保洁 |
| 3 | kevin | male | 18 | 201 | 200 | 技术 |
| 3 | kevin | male | 18 | 201 | 201 | 人力资源 |
| 3 | kevin | male | 18 | 201 | 202 | 销售 |
| 3 | kevin | male | 18 | 201 | 203 | 运营 |
| 3 | kevin | male | 18 | 201 | 205 | 保洁 |
| 4 | nick | male | 28 | 202 | 200 | 技术 |
| 4 | nick | male | 28 | 202 | 201 | 人力资源 |
| 4 | nick | male | 28 | 202 | 202 | 销售 |
| 4 | nick | male | 28 | 202 | 203 | 运营 |
| 4 | nick | male | 28 | 202 | 205 | 保洁 |
| 5 | owen | male | 18 | 203 | 200 | 技术 |
| 5 | owen | male | 18 | 203 | 201 | 人力资源 |
| 5 | owen | male | 18 | 203 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
| 5 | owen | male | 18 | 203 | 205 | 保洁 |
| 6 | jerry | female | 18 | 204 | 200 | 技术 |
| 6 | jerry | female | 18 | 204 | 201 | 人力资源 |
| 6 | jerry | female | 18 | 204 | 202 | 销售 |
| 6 | jerry | female | 18 | 204 | 203 | 运营 |
| 6 | jerry | female | 18 | 204 | 205 | 保洁 |
+----+-------+--------+------+--------+-----+--------------+
会将所有出现过的数据重复展示
2.使用左连接
select * from emp left join dep on emp.dep_id = dep.id;
+----+-------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+-------+--------+------+--------+------+--------------+
| 1 | jason | male | 18 | 200 | 200 | 技术 |
| 2 | egon | female | 48 | 201 | 201 | 人力资源 |
| 3 | kevin | male | 18 | 201 | 201 | 人力资源 |
| 4 | nick | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
| 6 | jerry | female | 18 | 204 | NULL | NULL |
+----+-------+--------+------+--------+------+--------------+
3.使用右连接
select * from emp right join dep on emp.dep_id=dep.id;
+------+-------+--------+------+--------+-----+--------------+
| id | name | sex | age | dep_id | id | name |
+------+-------+--------+------+--------+-----+--------------+
| 1 | jason | male | 18 | 200 | 200 | 技术 |
| 2 | egon | female | 48 | 201 | 201 | 人力资源 |
| 3 | kevin | male | 18 | 201 | 201 | 人力资源 |
| 4 | nick | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
| NULL | NULL | NULL | NULL | NULL | 205 | 保洁 |
+------+-------+--------+------+--------+-----+--------------+
4.使用union连接连个SQL语句
select * from emp right join dep on emp.dep_id=dep.id
-> union
-> select * from emp left join dep on emp.dep_id = dep.id;
+------+-------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+-------+--------+------+--------+------+--------------+
| 1 | jason | male | 18 | 200 | 200 | 技术 |
| 2 | egon | female | 48 | 201 | 201 | 人力资源 |
| 3 | kevin | male | 18 | 201 | 201 | 人力资源 |
| 4 | nick | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
| NULL | NULL | NULL | NULL | NULL | 205 | 保洁 |
| 6 | jerry | female | 18 | 204 | NULL | NULL |
+------+-------+--------+------+--------+------+--------------+
二、多表查询练习题
1.习题
1、查询所有的课程的名称以及对应的任课老师姓名
2、查询平均成绩大于八十分的同学的姓名和平均成绩
3、查询没有报李平老师课的学生姓名
4、查询挂科超过两门(包括两门)的学生姓名和班级
'''可能有点难,自己做,能做几个做几个.'''
###########################编写SQL不要想着一次性写完 可以边写边看######################################
-- 1、查询所有的课程的名称以及对应的任课老师姓名
-- SELECT
-- teacher.tname,
-- course.cname
-- FROM
-- teacher
-- INNER JOIN course ON teacher.tid = course.teacher_id;
-- 2、查询平均成绩大于八十分的同学的姓名和平均成绩
# 1.先确定需要使用到的表
# 2.在思考多表查询的方式
# 第一步先查询成绩表中 平均成绩大于80的学生编号
# 1.1 按照学生id分组并获取平均成绩
-- select student_id,avg(num) from score group by student_id;
# 1.2 筛选出平均成绩大于80的数据 (针对聚合函数的字段结果 最好起别名防止冲突)
-- select student_id,avg(num) as avg_num from score group by student_id having avg(num) > 80;
# 1.3 将上述SQL的结果与student表拼接
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN ( SELECT student_id, avg( num ) AS avg_num FROM score GROUP BY student_id HAVING avg( num ) > 80 ) AS t1 ON student.sid = t1.student_id;
-- 3、查询没有报李平老师课的学生姓名
# 1.先查询李平老师教授的课程编号
-- select course.cid from course where teacher_id =
-- (select tid from teacher where tname ='李平老师');
# 2.根据课程id号筛选出所有报了的学生id号
-- select distinct score.student_id from score where course_id in (select course.cid from course where teacher_id =
-- (select tid from teacher where tname ='李平老师'));
# 3.去学生表中根据id号取反筛选学生姓名
-- SELECT
-- student.sname
-- FROM
-- student
-- WHERE
-- sid NOT IN (
-- SELECT DISTINCT
-- score.student_id
-- FROM
-- score
-- WHERE
-- course_id IN ( SELECT course.cid FROM course WHERE teacher_id = ( SELECT tid FROM teacher WHERE tname = '李平老师' ) )
-- );
-- 4、查询挂科超过两门(包括两门)的学生姓名和班级
# 1.先筛选出小于60分的数据
-- select * from score where num < 60;
# 2.按照学生id分组 然后统计挂科数量
-- select student_id,count(course_id) from score where num < 60 group by student_id;
# 3.筛选出挂科超过两门的学生id
-- select student_id from score where num < 60 group by student_id
-- having count(course_id) >=2;
# 4.先将上述结果放在一边 去连接student和class表
SELECT
student.sname,
class.caption
FROM
class
INNER JOIN student ON class.cid = student.class_id
WHERE
student.sid IN ( SELECT student_id FROM score WHERE num < 60 GROUP BY student_id HAVING count( course_id ) >= 2 );
试题的SQL文件
/*
数据导入:
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50624
Source Host : localhost
Source Database : sqlexam
Target Server Type : MySQL
Target Server Version : 50624
File Encoding : utf-8
Date: 10/21/2016 06:46:46 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `class`
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `class`
-- ----------------------------
BEGIN;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
COMMIT;
-- ----------------------------
-- Table structure for `course`
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `course`
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
COMMIT;
-- ----------------------------
-- Table structure for `score`
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `score`
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
COMMIT;
-- ----------------------------
-- Table structure for `student`
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `student`
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
COMMIT;
-- ----------------------------
-- Table structure for `teacher`
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `teacher`
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
2.Navicata可视化软件
这款软件基本上不用写SQL语句
Navicat的使用需要下载
它不是免费的,收费的,所以:1. 花钱去买,2. 白嫖,3. 免费试用14天
去官网下载:https://www.navicat.com.cn/products/
1.连接数据库
打开 navicat ,点击 连接 ,选择 数据库
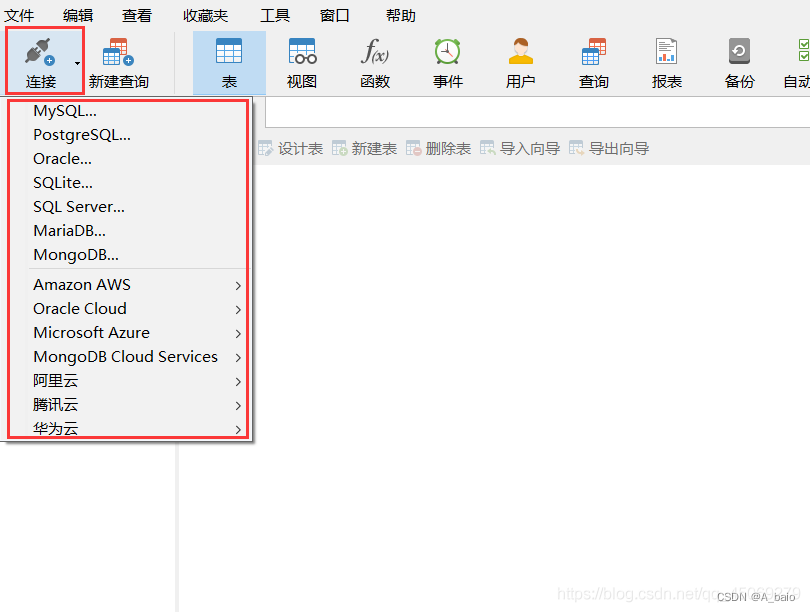
弹出以下界面 (以MySQL为例),熟悉各部分的作用
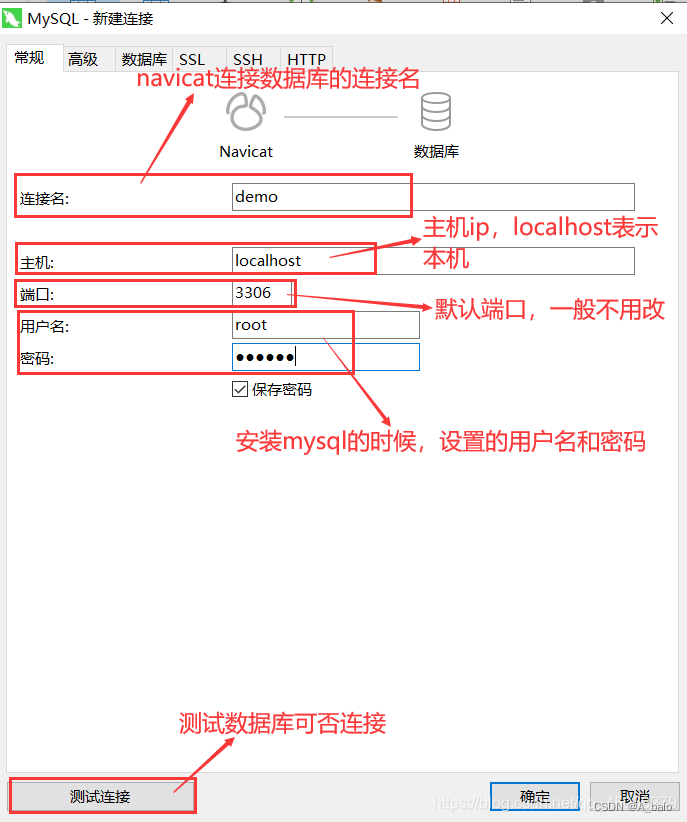
测试是否可以连接,有以下提示,点击确定开始使用数据库
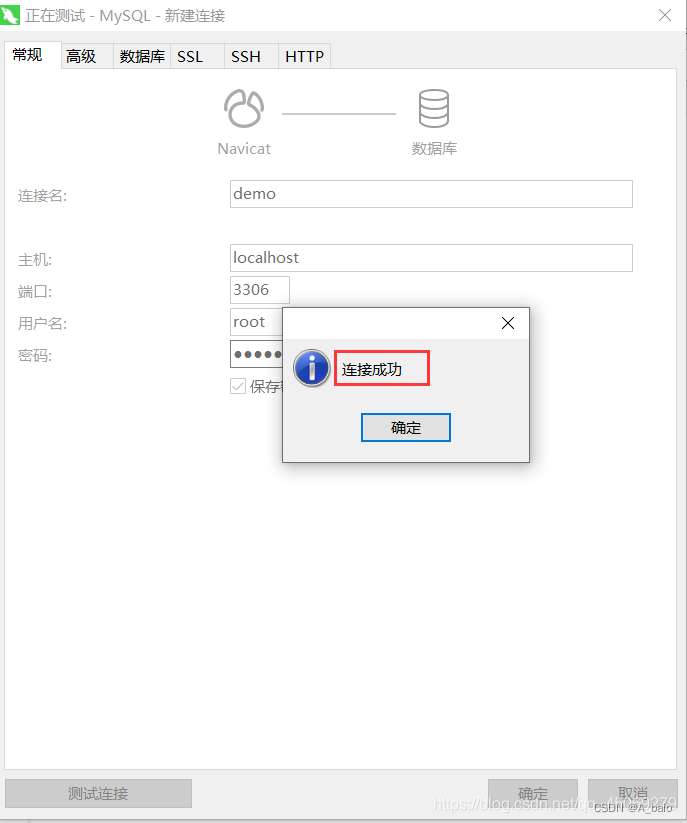
双击 或 右键 打开连接,图标变亮表示已经打开连接
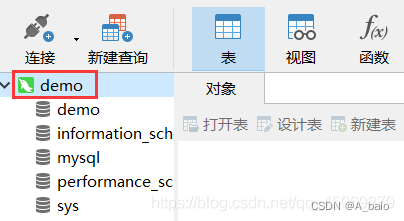
2 操作数据库
右键 连接 ,点击 新建数据库
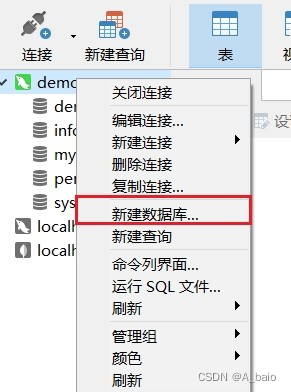
输入 数据库名 和 编码规则
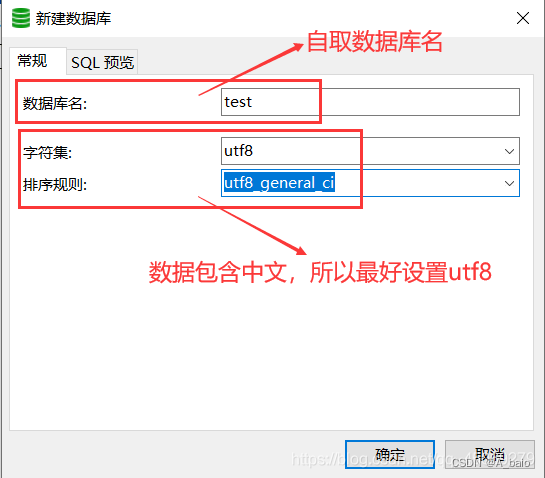
双击 或 右键 打开数据库(灰色图标变亮表示打开)
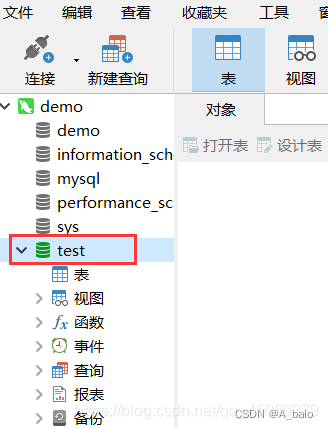
3.导入备份
打开 数据库 ,右键选择 运行SQL文件 ,备份数据库文件
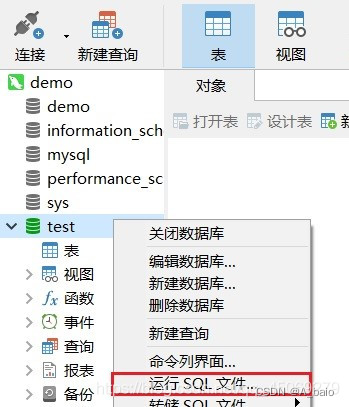
选择文件导入
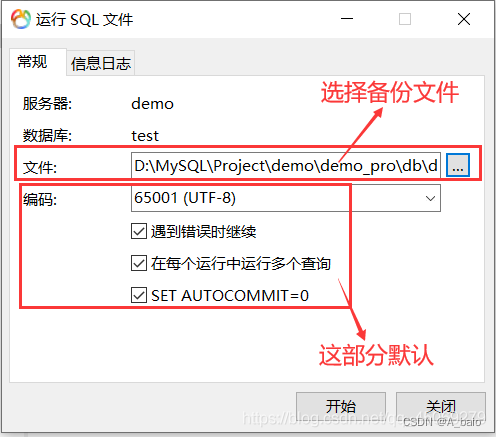
导入成功如下
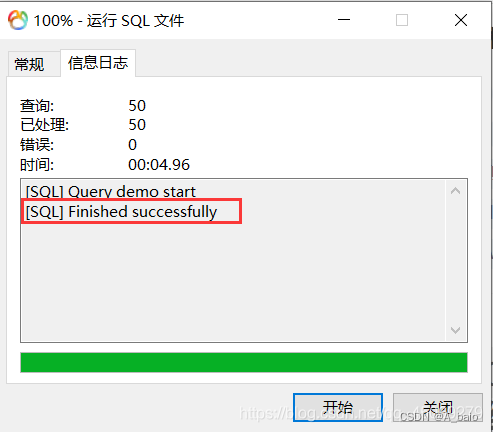
关闭数据库 , 重新打开该数据库 ,可以看到刚刚导入的表 (对比上图,表那一项本来是空的,左边没有箭头)
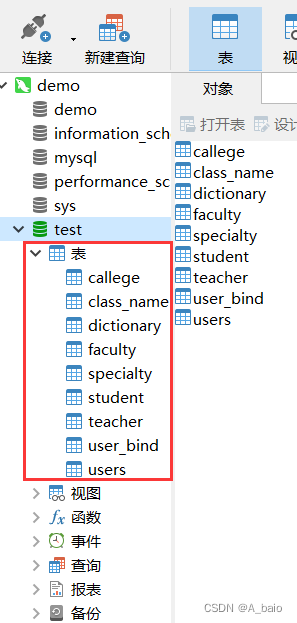
4.查询数据
直接 鼠标点击 相应的表查询数据。
用 sql语句 查询。
双击或右键打开 表 ,可以查看数据
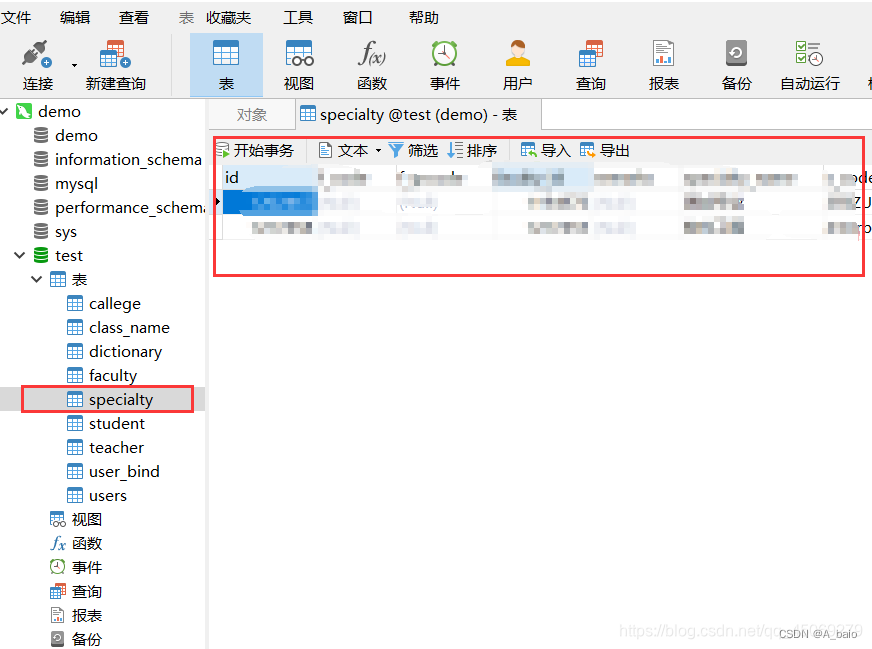
(以下是演示用sql语句查询)
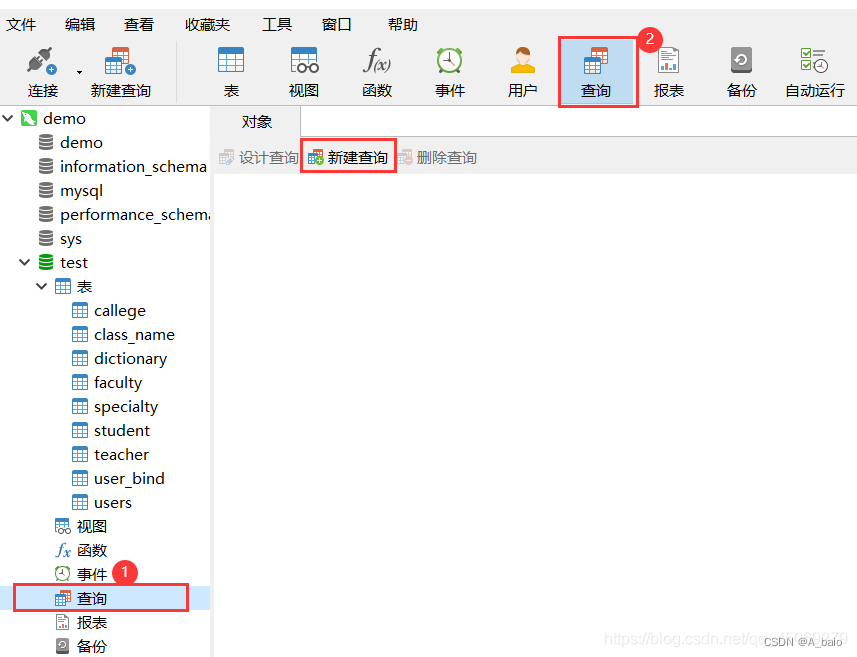
点击 ① 或者 ② ,再点击 新建查询
输入 sql语句
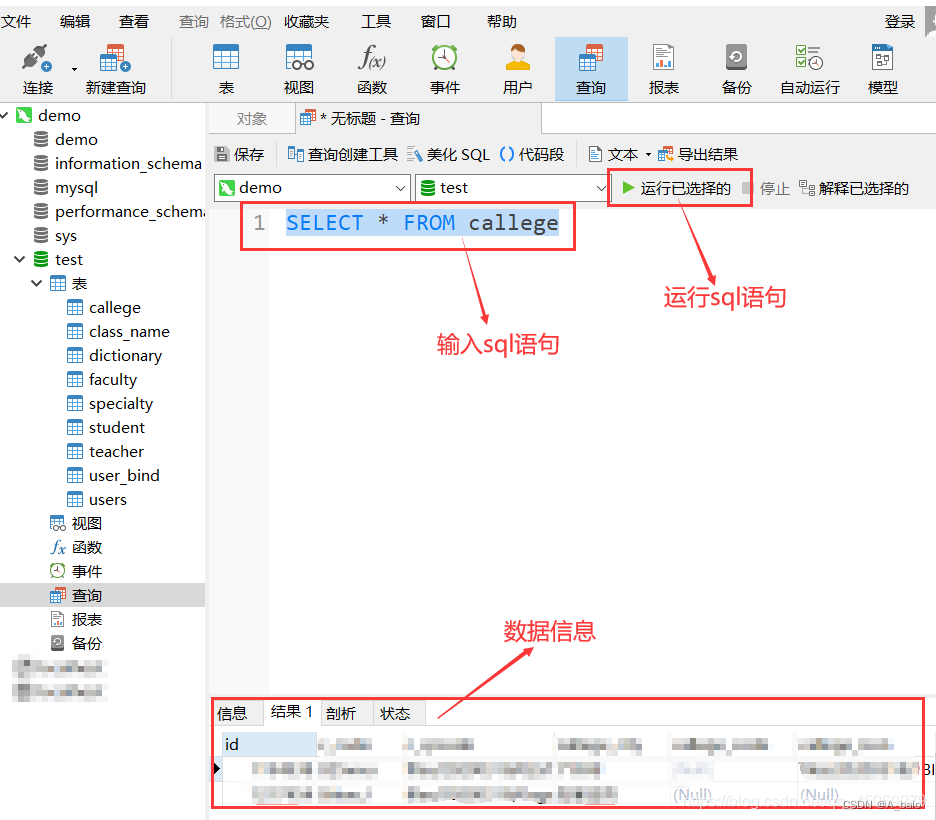
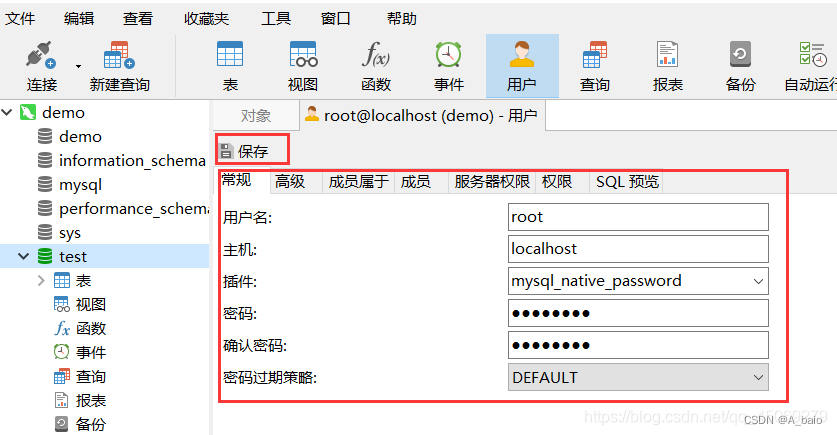
5.修改用户信息
登录 mysql ,选择需要修改用户信息的 数据库
点击上方的 用户
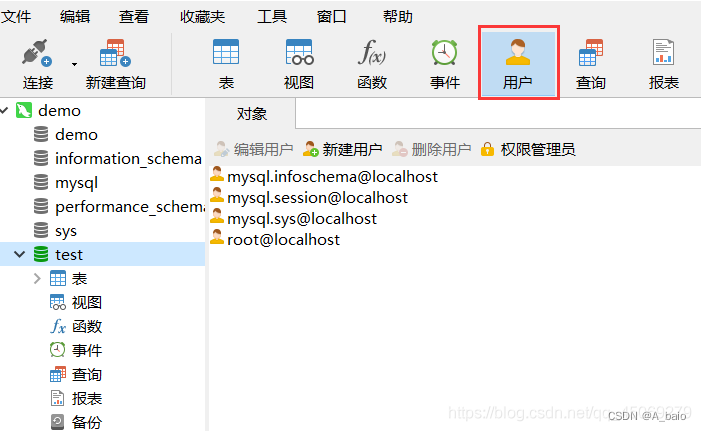
选择需要修改的 用户名 ,再点击上方 编辑用户
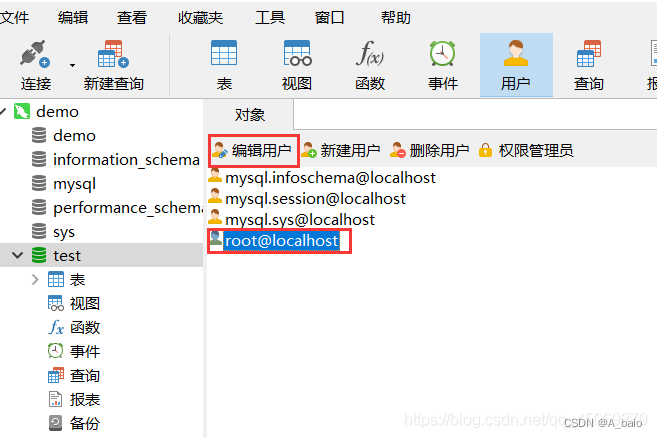
出现以下界面,修改你需要 修改的信息 ,再点击 保存