生成式人工智能时代,开发者可以借助大语言模型(LLM)开发更智能的应用程序。然而,由于有限的知识,LLM 非常容易出现幻觉。检索增强生成(RAG)https://zilliz.com/use-cases/llm-retrieval-augmented-generation 通过为 LLM 补充外部知识,有效地解决了这一问题。
在 Chat Towards Data Science 博客系列中,我们将详细介绍如何使用个人的数据知识库构建 RAG 聊天机器人。本文是该系列的第一部分,将为大家介绍如何创建一个用于 Towards Data Science https://towardsdatascience.com/ 网站的聊天机器人,如何利用网页抓取数据、创建存储在 Zilliz Cloud https://zilliz.com.cn/ 上的知识库。
01.使用 BeautifulSoup4 抓取网页数据
所有机器学习(ML)项目的第一步都是收集所需的数据。本项目中,我们使用网页抓取技术来收集知识库数据。用 requests 库获取网页并使用 BeautifulSoup4.从网页中提取信息、解析 HTML 信息并提取段落。
导入 BeautifulSoup4 和 Requests 库进行网页抓取
运行 pip install beautifulsoup4 sentence-transformers安装 BeautifulSoup 和 Sentence Transformers。在数据抓取部分只需要导入requests和 BeautifulSoup。接下来,创建一个 dictionary,其中包含我们要抓取的 URL 格式。在本示例中,我们只从 Towards Data Science 抓取内容,同理也可以从其他网站抓取。
现在,用以下代码所示的格式从每个存档页面获取数据:
import requests
from bs4 import BeautifulSoup
urls = {
'Towards Data Science': '<https://towardsdatascience.com/archive/{0}/{1:02d}/{2:02d}>'
}
此外,我们还需要两个辅助函数来进行网页抓取。第一个函数将一年中的天数转换为月份和日期格式。第二个函数从一篇文章中获取点赞数。
天数转换函数相对简单。写死每个月的天数,并使用该列表进行转换。由于本项目仅抓取 2023 年数据,因此我们不需要考虑闰年。如果您愿意,可以根据不同的年份进行修改每个月天数。
点赞计数函数统计 Medium 上文章的点赞数,单位为 “K” (1K=1000)。因此,在函数中需要考虑点赞数中的单位“K”。
def convert_day(day):
month_list = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
m = 0
d = 0
while day > 0:
m += 1
d = day
day -= month_list[m-1]
return (m, d)
def get_claps(claps_str):
if (claps_str is None) or (claps_str == '') or (claps_str.split is None):
return 0
split = claps_str.split('K')
claps = float(split[0])
return int(claps*1000) if len(split) == 2 else int(claps)
解析 BeautifulSoup4 的网页抓取响应
现在已经设置好必要的组件,可以进行网页抓取。为了避免在过程中遇到 429 错误(请求过多),我们使用 time 库,在发送请求之间引入延迟。此外,用 sentence transformers 库从 Hugging Face 获取 embedding 模型—— MiniLM 模型。
如前所述,我们只抓取了 2023 年的数据,所以将年份设置为 2023。此外,只需要从第 1 天(1 月 1 日)到第 244 天(8 月 31 日)的数据。根据设定的天数进行循环,每个循环在第一次调用time.sleep()之前会首先设置必要的组件。我们会把天数转换成月份和日期,并转成字符串,然后根据 urls 字典组成完整的 URL,最后发送请求获取 HTML 响应。
获取 HTML 响应之后,使用 BeautifulSoup 进行解析,并搜索具有特定类名(在代码中指示)的div元素,该类名表示它是一篇文章。我们从中解析标题、副标题、文章 URL、点赞数、阅读时长和回应数。随后,再次使用requests来获取文章的内容。每次通过请求获取文章内容后,都会再次调用time.sleep()。此时,我们已经获取了大部分所需的文章元数据。提取文章的每个段落,并使用我们的 HuggingFace 模型获得对应的向量。接着,创建一个字典包含该文章段落的所有元信息。
import time
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
data_batch = []
year = 2023
for i in range(1, 243):
month, day = convert_day(i)
date = '{0}-{1:02d}-{2:02d}'.format(year, month, day)
for publication, url in urls.items():
response = requests.get(url.format(year, month, day), allow_redirects=True)
if not response.url.startswith(url.format(year, month, day)):
continue
time.sleep(8)
soup = BeautifulSoup(response.content, 'html.parser')
articles = soup.find_all("div","postArticle postArticle--short js-postArticle js-trackPostPresentation js-trackPostScrolls")
for article in articles:
title = article.find("h3", class_="graf--title")
if title is None:
continue
title = str(title.contents[0]).replace(u'\\\\xA0', u' ').replace(u'\\\\u200a', u' ')
subtitle = article.find("h4", class_="graf--subtitle")
subtitle = str(subtitle.contents[0]).replace(u'\\\\xA0', u' ').replace(u'\\\\u200a', u' ') if subtitle is not None else ''
article_url = article.find_all("a")[3]['href'].split('?')[0]
claps = get_claps(article.find_all("button")[1].contents[0])
reading_time = article.find("span", class_="readingTime")
reading_time = int(reading_time['title'].split(' ')[0]) if reading_time is not None else 0
responses = article.find_all("a", class_="button")
responses = int(responses[6].contents[0].split(' ')[0]) if len(responses) == 7 else (0 if len(responses) == 0 else int(responses[0].contents[0].split(' ')[0]))
article_res = requests.get(article_url)
time.sleep(8)
paragraphs = BeautifulSoup(article_res.content, 'html.parser').find_all("[class*=\\\\"pw-post-body-paragraph\\\\"]")
for i, paragraph in enumerate(paragraphs):
embedding = model.encode([paragraph.text])[0].tolist()
data_batch.append({
"_id": f"{article_url}+{i}",
"article_url": article_url,
"title": title,
"subtitle": subtitle,
"claps": claps,
"responses": responses,
"reading_time": reading_time,
"publication": publication,
"date": date,
"paragraph": paragraph.text,
"embedding": embedding
})
最后一步是使用 pickle 处理文件。
filename = "TDS_8_30_2023"
with open(f'{filename}.pkl', 'wb') as f:
pickle.dump(data_batch, f)
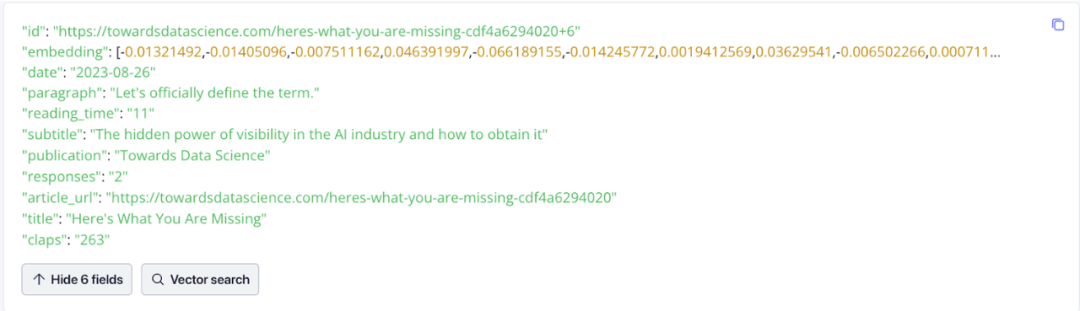
数据呈现
数据可视化十分有用。下面是在 Zilliz Cloud 中数据的样子。请注意其中的 embedding,这些数据表示了文档向量,也就是我们根据文章段落生成的向量。
02.将 TDS 数据导入到向量数据库中
获取数据后,下一步是将其导入到向量数据库中。在本项目中,我们使用了一个单独的 notebook 将数据导入到 Zilliz Cloud,而不是从 Towards Data Science 进行网页抓取。
要将数据插入 Zilliz Cloud,需按照以下步骤进行操作:
-
连接到 Zilliz Cloud
-
定义 Collection 的参数
-
将数据插入 Zilliz Cloud
设置 Jupyter Notebook
运行 pip install pymilvus python-dotenv 来设置 Jupyter Notebook 并启动数据导入过程。用 dotenv 库来管理环境变量。对于pymilvus包,需要导入以下模块:
-
utility用于检查集合的状态 -
connections用于连接到 Milvus 实例 -
FieldSchema用于定义字段的 schema -
CollectionSchema用于定义 collection schema -
DataType字段中存储的数据类型 -
Collection我们访问 collection 的方式
然后,打开之前 pickle 的数据,获取环境变量,并连接到 Zilliz Cloud。
import pickle
import os
from dotenv import load_dotenv
from pymilvus import utility, connections, FieldSchema, CollectionSchema, DataType, Collection
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'rb') as f:
data_batch = pickle.load(f)
zilliz_uri = "your_zilliz_uri"
zilliz_token = "your_zilliz_token"
connections.connect(
uri= zilliz_uri,
token= zilliz_token
)
设置 Zilliz Cloud 向量数据库并导入数据
接下来,需要设置 Zilliz Cloud。我们必须创建一个 Collection 来存储和组织从 TDS 网站抓取的数据。需要两个常量:dimension(维度)和 collection name(集合名称),dimension 是指我们的向量具有的维度数。在本项目中,我们使用 384 维的 MiniLM 模型。
Milvus 的全新 Dynamic schema https://milvus.io/docs/dynamic_schema.md#Dynamic-Schema 功能允许我们仅为 Collection 设置 ID 和向量字段,无需考虑其他字段数量和数据类型。注意,需要记住保存的特定字段名称,因为这对于正确检索字段至关重要。
DIMENSION=384
COLLECTION_NAME="tds_articles"
fields = [
FieldSchema(name='id', dtype=DataType.VARCHAR, max_length=200, is_primary=True),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
"index_type": "AUTO_INDEX",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
Collection 有两种插入数据的选项:
-
遍历数据并逐个插入每个数据
-
批量插入数据
在插入所有数据之后,重要的是刷新集合以进行索引并确保一致性,导入大量数据可能需要一些时间。
for data in data_batch:
collection.insert([data])
collection.flush()
03.查询 TDS 文章片段
一切准备就绪后,就可以进行查询了。
获取 HuggingFace 模型并设置 Zilliz Cloud 查询
注意,必须获取 embedding 模型并设置向量数据库以查询 Towards Data Science 知识库。这一步使用了一个单独的笔记本。我们将使用dotenv库来管理环境变量。此外,还需要使用 Sentence Transformers 中的 MiniLM 模型。这一步中,可以重用 Web Scraping 部分提供的代码。
import os
from dotenv import load_dotenv
from pymilvus import connections, Collection
zilliz_uri = "your_zilliz_uri"
zilliz_token = "your_zilliz_token"
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
执行向量搜索查询
连接到向量数据库并执行搜索。在本项目中,我们将连接到一个 Zilliz Cloud 实例,并检索之前创建的集合 tds_articles,用户要先输入他们的查询问题。
接下来,使用 Hugging Face 的 embedding 模型对查询进行编码。这个过程将用户的问题转换为一个 384 维的向量。然后,使用这个编码后的查询向量来搜索向量数据库。在搜索过程中,需要指定进行 ANN 查询字段(anns_field)、索引参数、期望的搜索结果数量限制以及我们想要的输出字段(output fields)。
之前,我们用了 Milvus 的 Dynamic Schema 特性来简化字段 Schema 定义流程。搜索向量数据库时,包括所需的动态字段在搜索结果中是必要的。这个特定的场景涉及请求paragraph字段,其中包含文章中每个段落的文本。
connections.connect(uri=zilliz_uri, token=zilliz_token)
collection = Collection(name="tds_articles")
query = input("What would you like to ask Towards Data Science's 2023 publications up to September? ")
embedding = model.encode(query)
closest = collection.search([embedding],
anns_field='embedding',
param={"metric_type": "L2",
"params": {"nprobe": 16}},
limit=2,
output_fields=["paragraph"])
print(closest[0][0])
print(closest[0][1])
比如,我在应用中查询大语言模型相关的信息,返回了以下两个回答。尽管这些回答提到了“语言模型”并包含一些相关信息,但它们没有提供关于大型语言模型的详细解释。第二个回答在语义上相似,但是不足够接近我们想要的内容。

04.给向量数据库知识库添加内容
到目前为止,我们使用 Zilliz Cloud 作为向量数据库在 TDS 文章上创建了一个知识库。虽然能够轻松地检索语义上相似的搜索结果,但还没有达到我们的期望。下一步是通过加入新的框架和技术来增强我们的结果。
05.总结
本教程介绍了如何基于 Towards Data Science 文章构建聊天机器人。我们演示了网页爬取的过程,创建了知识库,包括将文本转换成向量存储在 Zilliz Cloud 中。然后,我们演示了如何提示用户进行查询,将查询转化为向量,并查询向量数据库。
不过,虽然结果在语义上相似,但并不完全符合我们的期望。在本系列的下一篇中,我们将探讨使用 LlamaIndex 来优化查询。除了这里讨论的步骤之外,大家也可以结合 Zilliz Cloud 尝试替换模型、合并文本或使用其他数据集。
本文由 mdnice 多平台发布




![[SQL开发笔记]IN操作符: 在WHERE子句中规定多个值](https://img-blog.csdnimg.cn/61963ae9ac534502af20a6d98f5c72cf.png)