昨天互联网圈子里发生了一件大事,那就是语雀的 P0 级事故,前后足足停服了 7 个多小时,放眼整个互联网的发展史,都是相当炸裂的表现。
语雀是技术大牛玉伯在蚂蚁金服内部孵化出来的一个云端知识库,整体的界面非常清爽,书写方式也非常丝滑,所以得到了不少小伙伴的青睐,我自己也是语雀的重度用户。
我平常的知识库,也都托管在语雀平台上,因为我觉得比较适合沉浸式地阅读。
昨天 16.46 我还技术交流群里发了一个通知,说《Java 面试指南》中又收录了不少新的面经和学习心得,小伙伴们可以刷一波了,然后就有不少小伙伴反馈说语雀已经崩了,内容无法查看。
不少小伙伴应该都是语雀的重度用户,相信大家对这波事故背后的原因非常好奇,说好的高可用、异地多活、容灾备份、两地三中心呢?面试的时候不是经常问吗?真遇到事了,又解决不了?
况且背靠蚂蚁金服这么牛逼的大厂,7 个多小时才搞定?那些所谓的技术大牛都去干嘛了?
语雀官方给出的解释是,由于数据量过于庞大,所以从备份系统中恢复存储数据花费了比较久的时间,从 15.10 分一直持续到 19 点才完成数据恢复,后来又用了 3 个多小时进行数据完整性的校验和联调,所以直到 22 点才终于结束这场闹剧。
并且官方给出了一个相对友好的解决方案,所有语雀的个人用户,赠送 6 个月的会员服务。
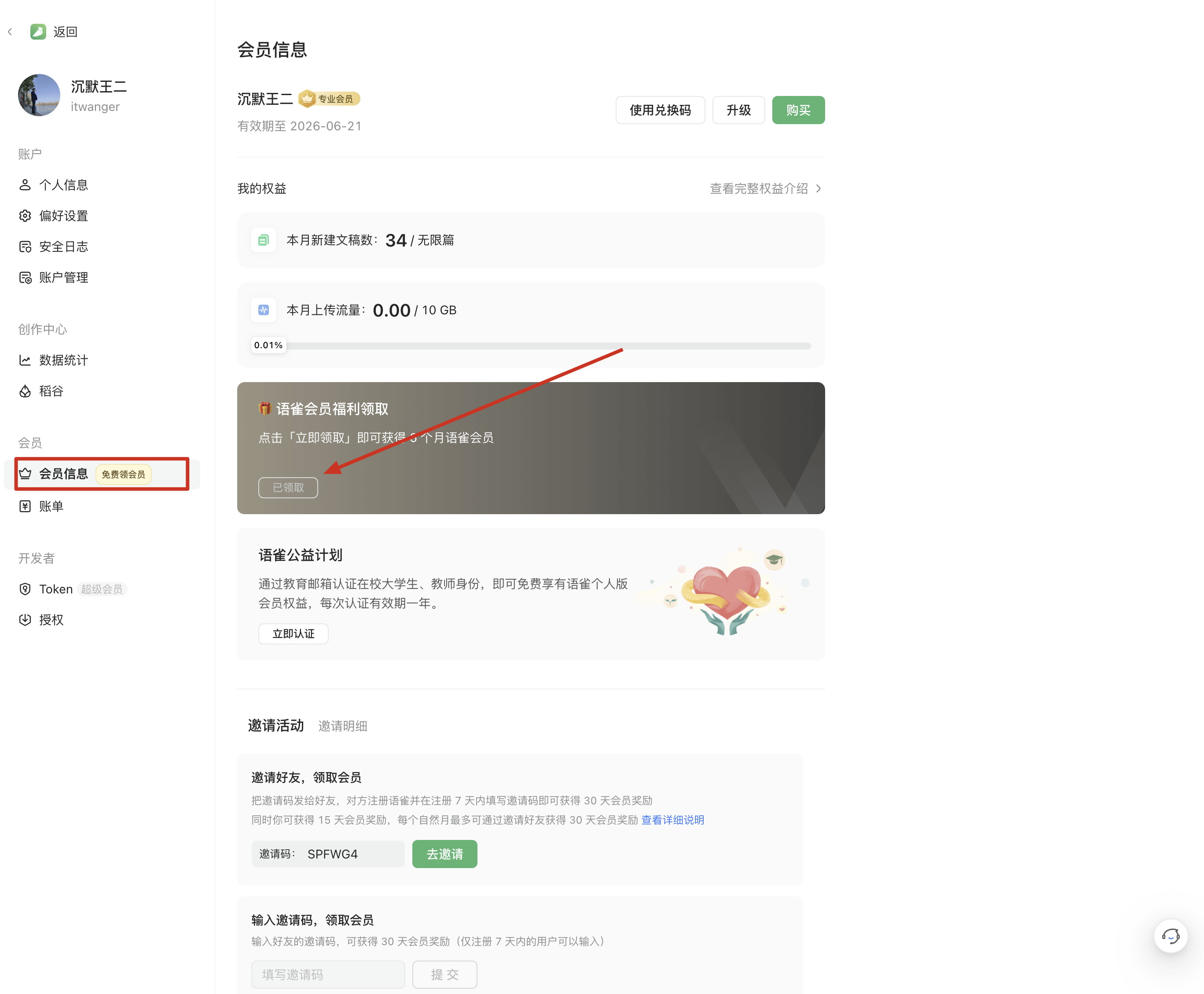
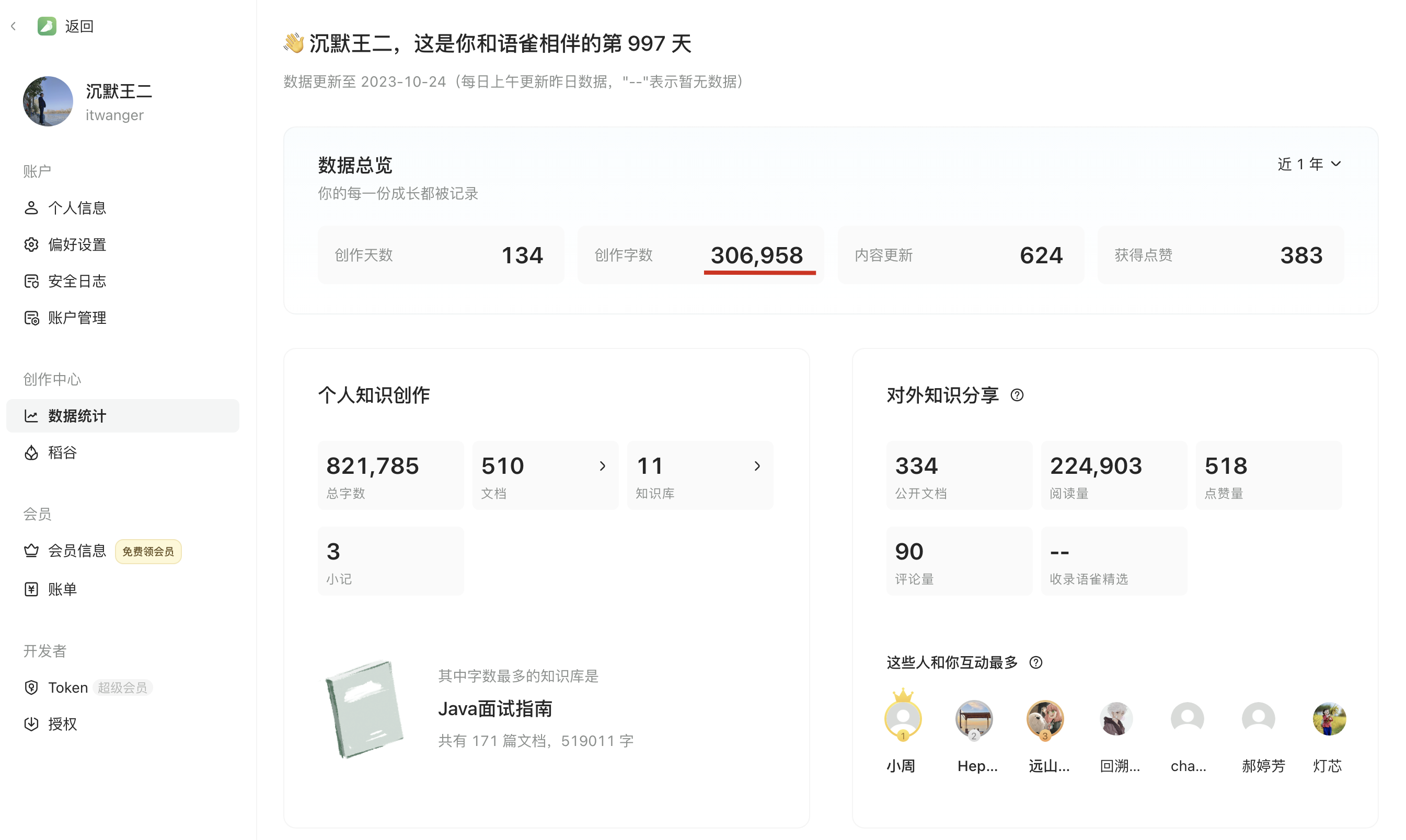
大家一定要记得领一下,我自己又续费了 2 年,一共 198 元,支持语雀一把。毕竟我已经是语雀的重度用户,数据统计里显示我已经创作了 30 万+字,厚厚好几本书了。
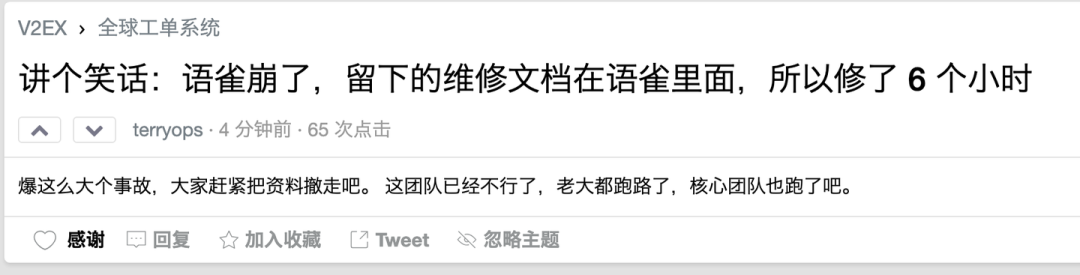
针对语雀这次故障,有小伙伴调侃说是因为维修文档在语雀里面,这个我觉得不太可能哈,语雀不至于蠢到连本地服务都没做。
我猜想的原因是,之前负责这块运维的老员工因为一些原因离职了(你懂的),导致目前维护语雀的员工在第一次遇到这个问题时傻眼了,就算是对照着文档也不知道怎么去操作。
想想也是,如果换成是我遇到这种故障,估计人当场就傻眼了,精神高度紧张,会的东西也不会了,毕竟这可是 P0 级事故,年终奖没了不说,后续可能还要背锅。
能处理好吗?
处理不好,所以,运维这个岗位平常可能看上去没啥用,运维搞的事情一个资深后端也能搞定,可真遇到事了,还得是有经验的上啊。
当然,时间耗这么久,肯定还有开会和汇报的时间占了大头,这种事故肯定大老板是要介入的。
话说,这次解决问题的员工下次面试时就可以自信满满地说:“劳资当年可是处理过语雀 P0 级事故的程序员。”说完这句话,后面估计就不用再继续面了,直接录用发 offer 就对了,这可是宝藏级的程序员啊。
所以,大家平常遇到比较重大的 bug 时一定要记得更新一波自己的简历,这绝对是加分项(😂)。
![[SQL开发笔记]IN操作符: 在WHERE子句中规定多个值](https://img-blog.csdnimg.cn/61963ae9ac534502af20a6d98f5c72cf.png)






![2023年中国临床决策支持系统发展趋势分析:综合性决策系统将成市场主流[图]](https://img-blog.csdnimg.cn/img_convert/bcd9efd3aa6f9596baa5cb6e5ec7102a.png)