第一章 pytorch环境部署留念
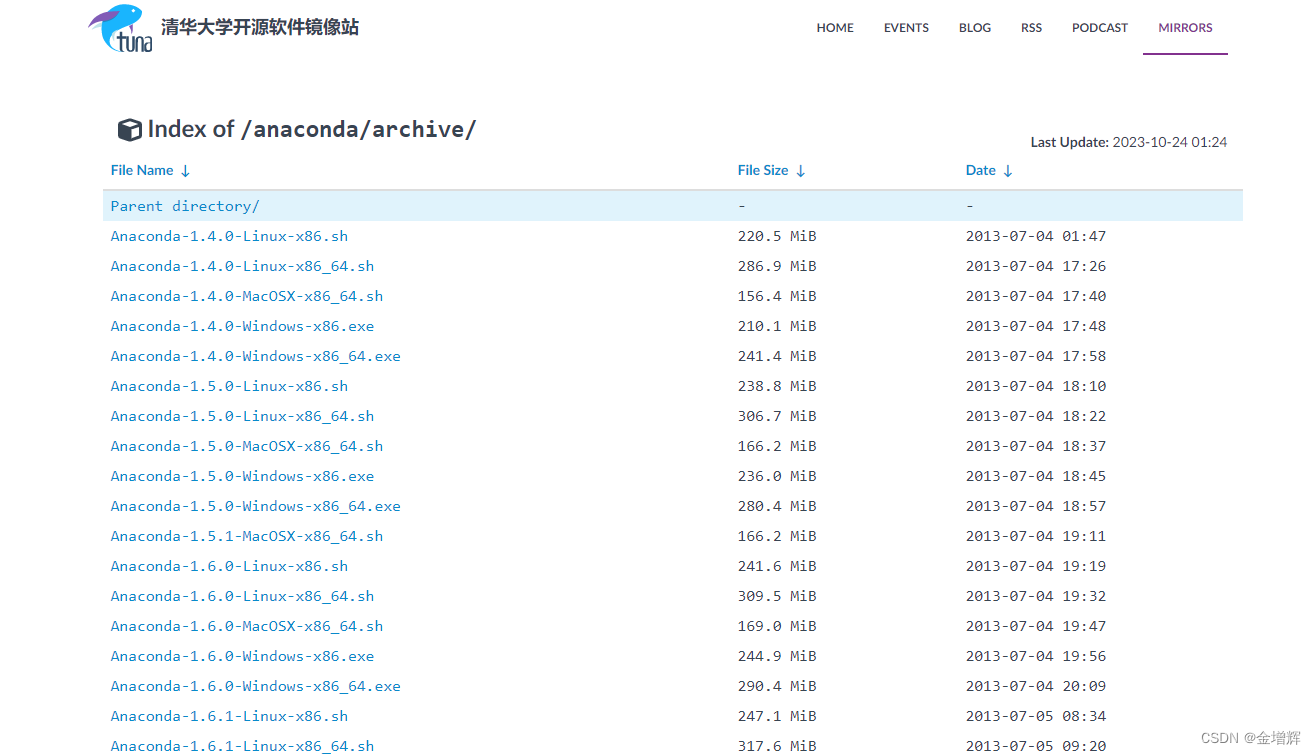
第一步:下载安装anaconda 官网地址
(也可以到清华大学开源软件镜像站下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)
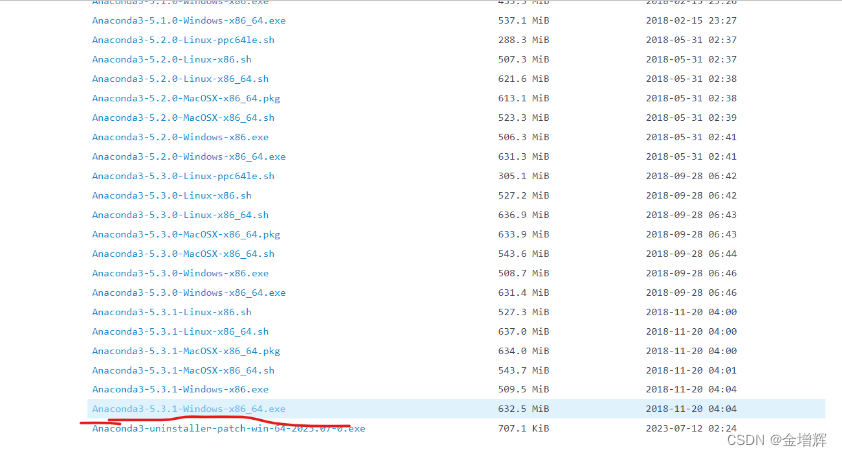
我安装的是下面这个,一通下一步就完事儿。
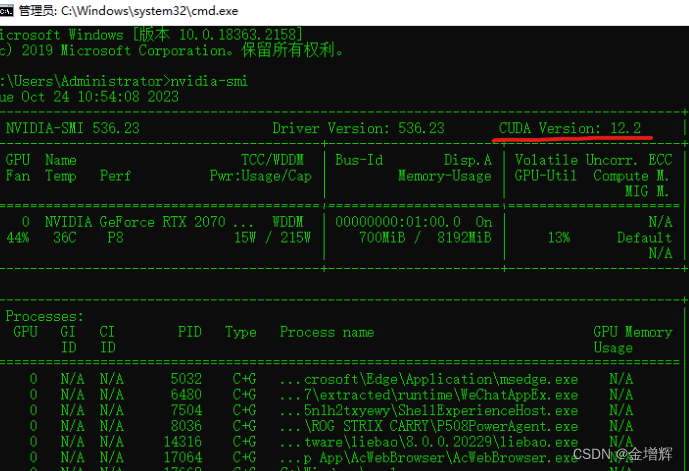
第二步:下载显卡驱动程序(大家一般都不需要,可以直接跳过)(cmd–nvidia-smi)
第三步:通过anaconda来安装pytorch
在这个base环境中先不要着急安装各种各样的python包,因为默认情况下在anaconda中创建的新的环境都是以base环境为模板的,也就是意味着新创建的环境会包含与base环境相同的Python版本和已安装的软件包列表,所以为了不必要的麻烦,我们新创建一个环境,创建环境的命令如下
conda create -n name python=3.8
-n是名字的意思,name自己取名,后面那个3.8是版本号。
在base环境中运行此命令可以进入我们创建的环境
第四步:激活环境
conda activate name (注:name是你自己创建的环境的名字)
第五步:在激活环境中下载安装pytorch
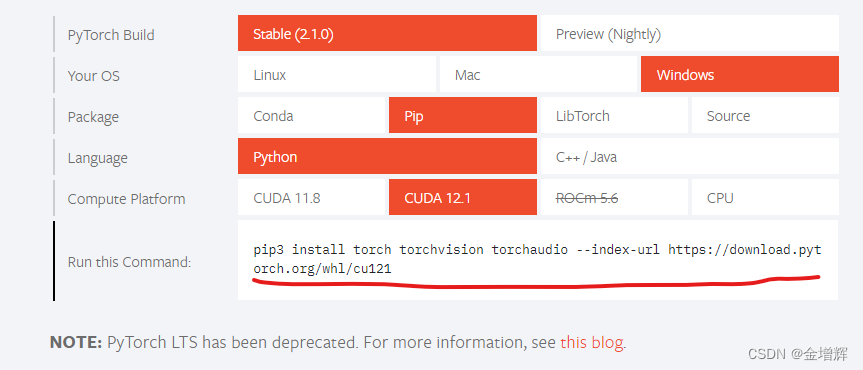
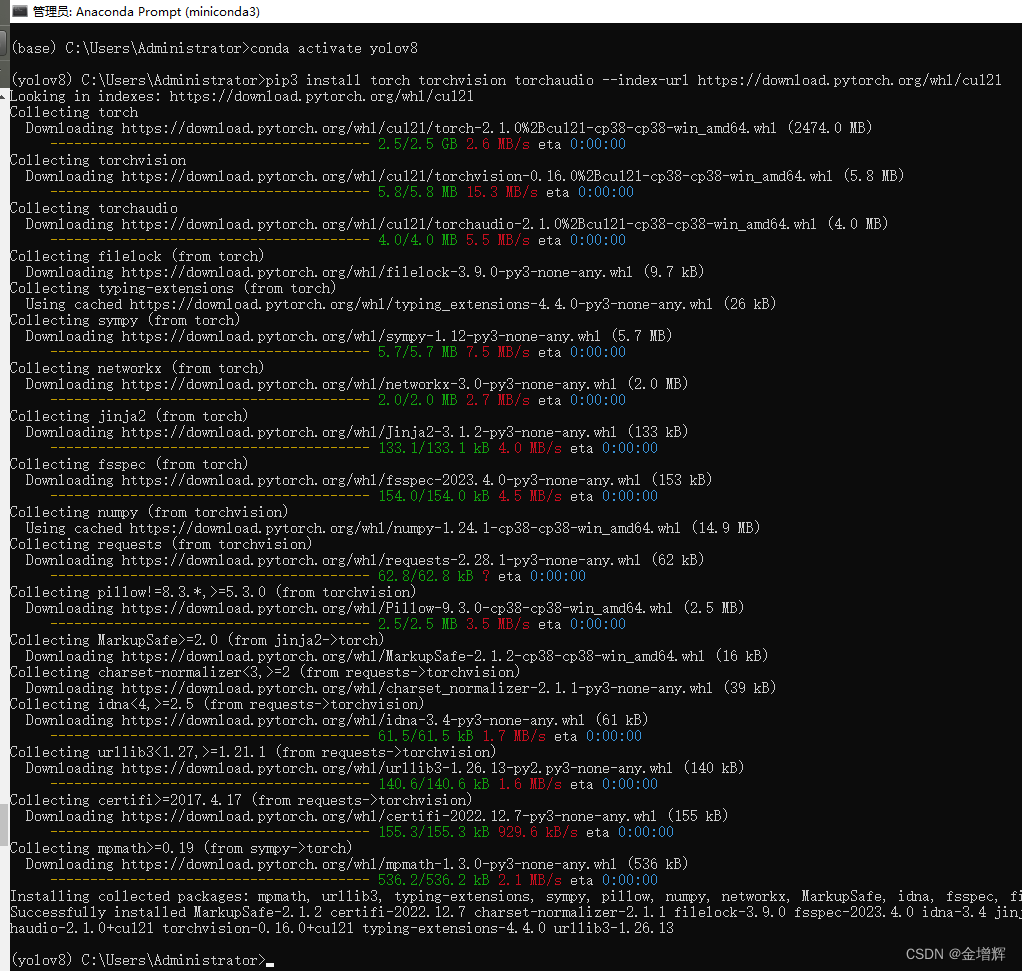
到官网去获取指令,官网链接:https://pytorch.org/,成功后的样子如图所示。
第六步:配置刚下载的环境作为pycharm中我们的python解释器
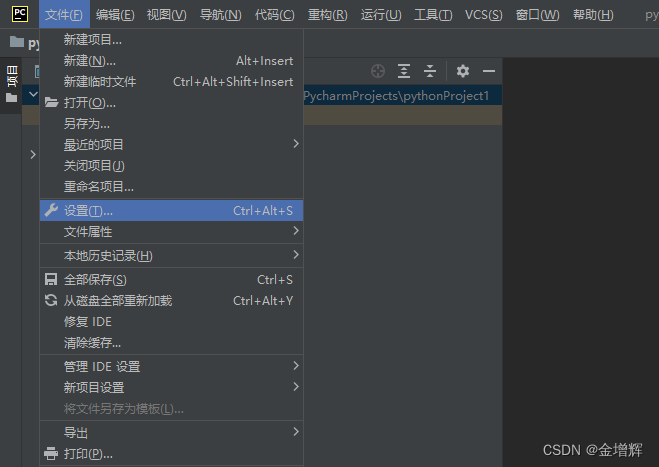
1.打开pycharm选择“文件”——设置
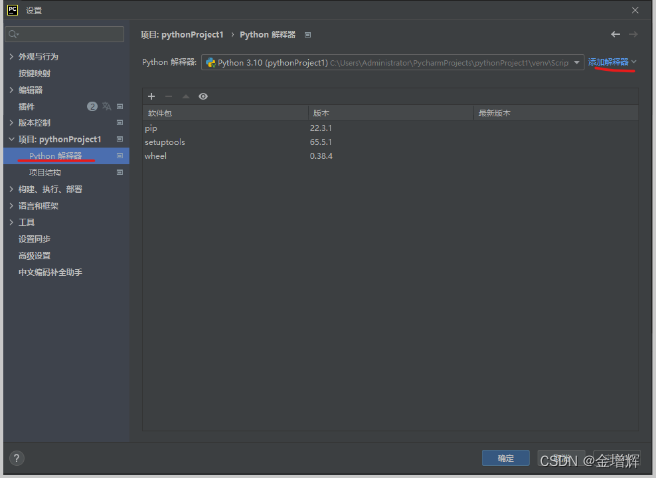
2.选择编辑器、添加解释器
3.选择conda环境,单击确定。
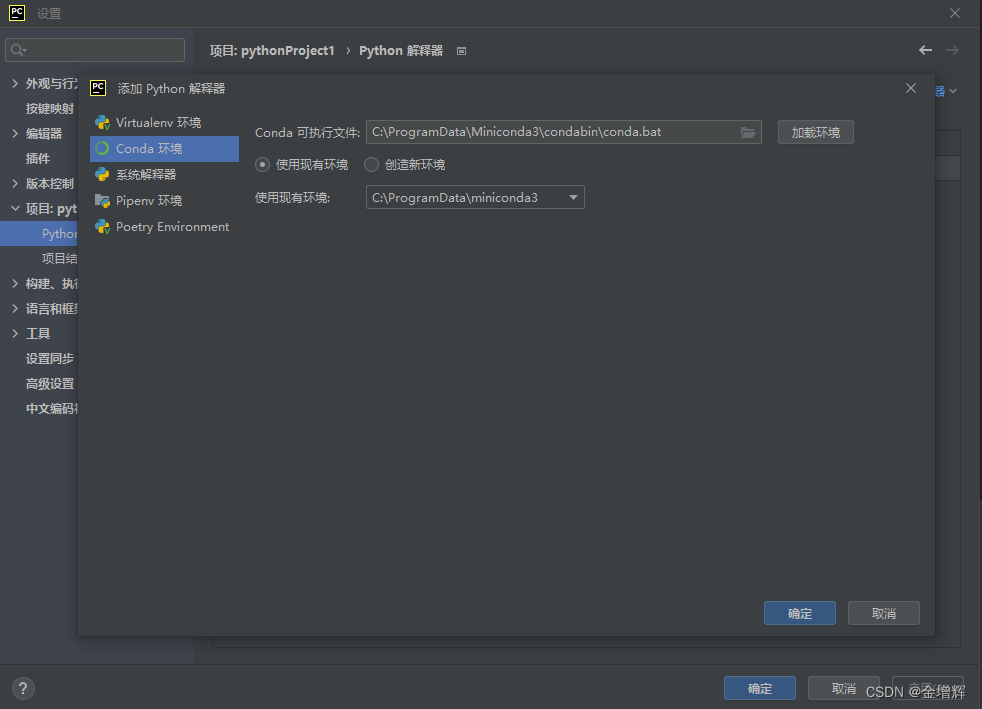
到这里就完事了。
第二章 YOLOV8的安装及测试
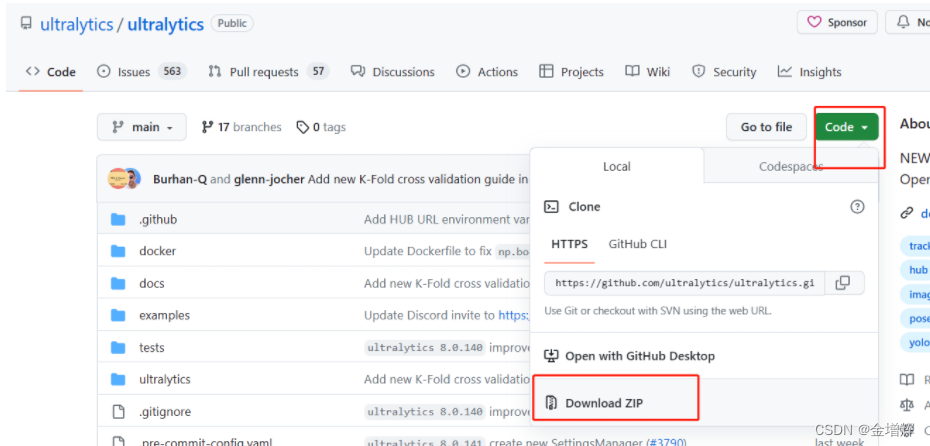
1.下载代码,到官网去找,或者其他人上传的都可以,主要下载两个内容:
第一个如下图的代码
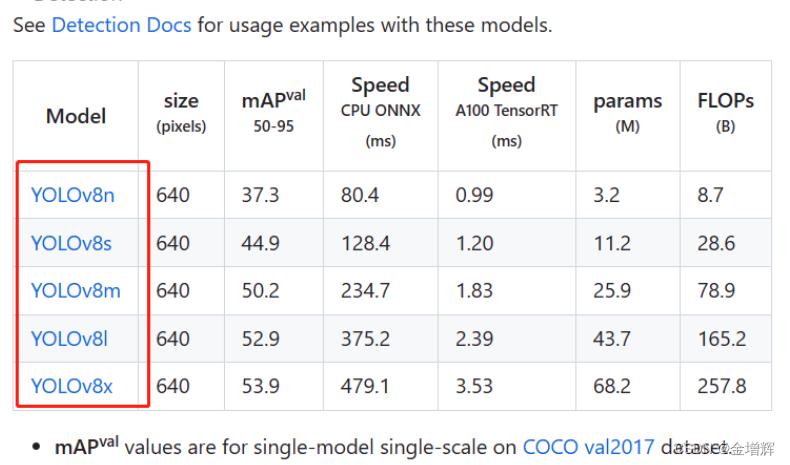
第二个如下图的模型,上面的那个把网页下拉就看到了
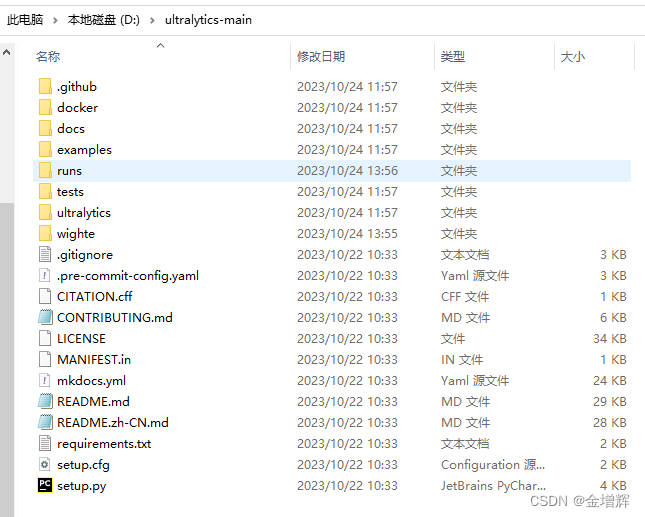
2.将下载完的代码解压拷贝到D盘的文件夹中,如下图所示
3.将下载完的模型解压拷贝到如下图所示文件夹中
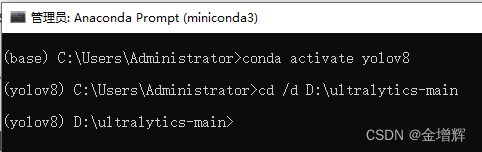
4.在Anaconda中执行下面的指令
5.安装依赖包
使用指令 pip install -r requirements.txt 安装的时候各种报错,更换源就好了。 更换源的方法就是在pip install的后面增加 -i +源名+安装包的形式,采用下面的指令进行安装即可
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
6.安装YOLO
出现下图表示成功,警告不用管。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ultralytics

7.测试
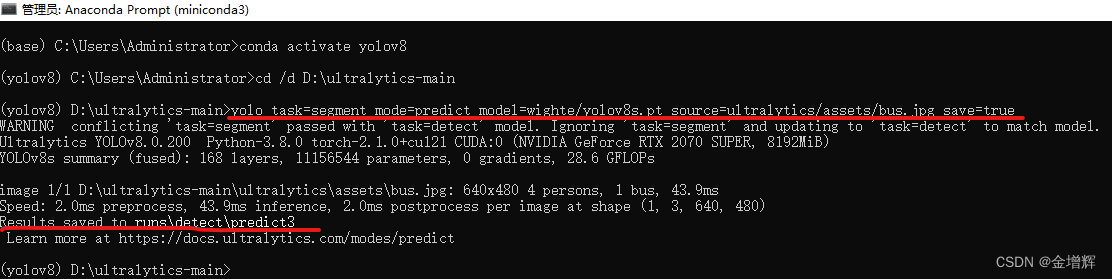
用yolov8s.pt来测试 :
yolo task=segment mode=predict model=wighte/yolov8s.pt source=ultralytics/assets/bus.jpg save=true
在程序文件夹中可以找到结果
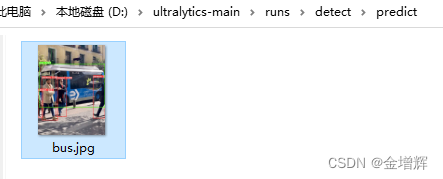
结果如下图所示:
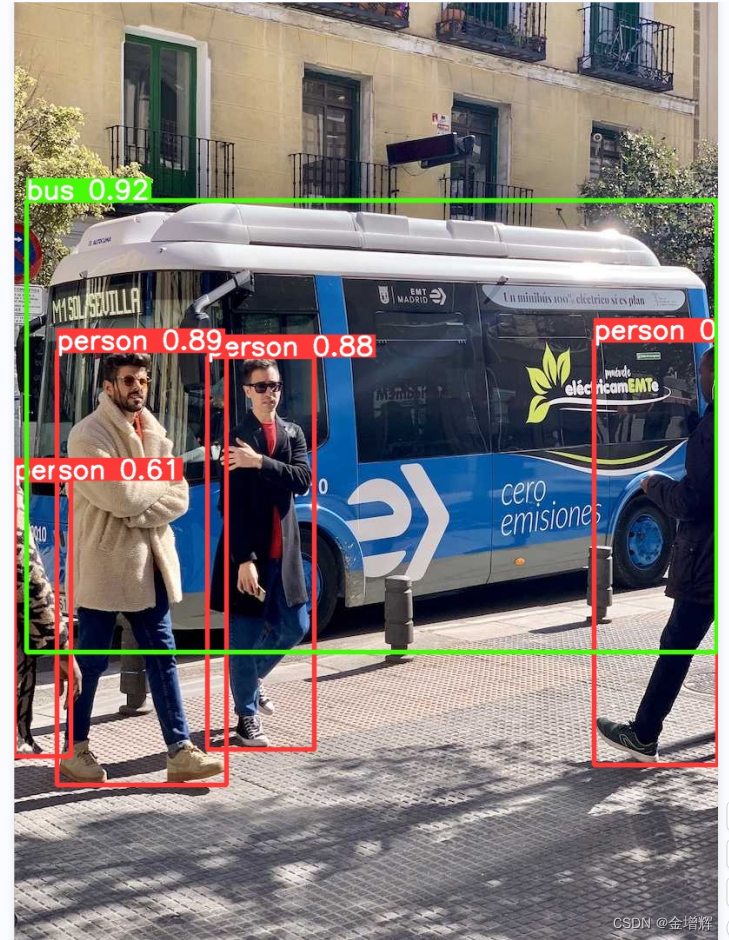
测试视频/摄像头/文件夹:(source=自己的绝对路径就行,照片也可以用绝对路径,刚才用的是相对路径),素材可以上网去找别人下载好的直接用就行,文件夹没有测试不知道是啥,前三个测试了效果挺好,尤其是摄像头,直接计算机上插一个摄像头就行。
conda activate yolov8
cd /d D:\ultralytics-main
#测试图片
yolo task=segment mode=predict model=wighte/yolov8s.pt source=ultralytics/assets/bus.jpg save=true
#测试视频
yolo task=segment mode=predict model=wighte/yolov8s.pt source=D:\car.mp4 show=true
#测试摄像头
yolo task=segment mode=predict model=wighte/yolov8s.pt source=0
#测试文件夹
yolo task=segment mode=predict model=wighte/yolov8s.pt source=D:\myimgs
第三章 制作自己的数据集
1.安装labelme,这里注意更换源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelme
出现下图表示安装成功
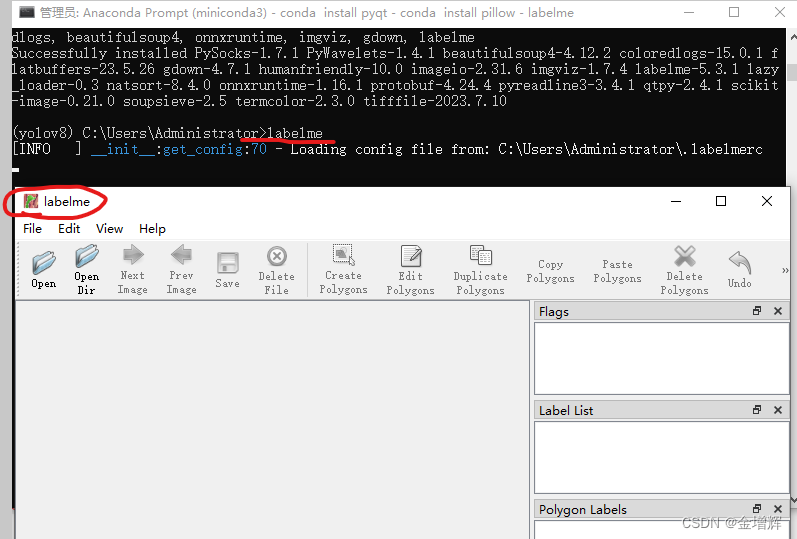
2.输入下图指令,打开labelme,结果如图所示
3.打开一张图片,进行标注。如果是目标检测就选择Create Rectangle框选图形即可,如果是图像分割就选择Create Plogons绘制边框,然后定义分类后保存成.json格式。
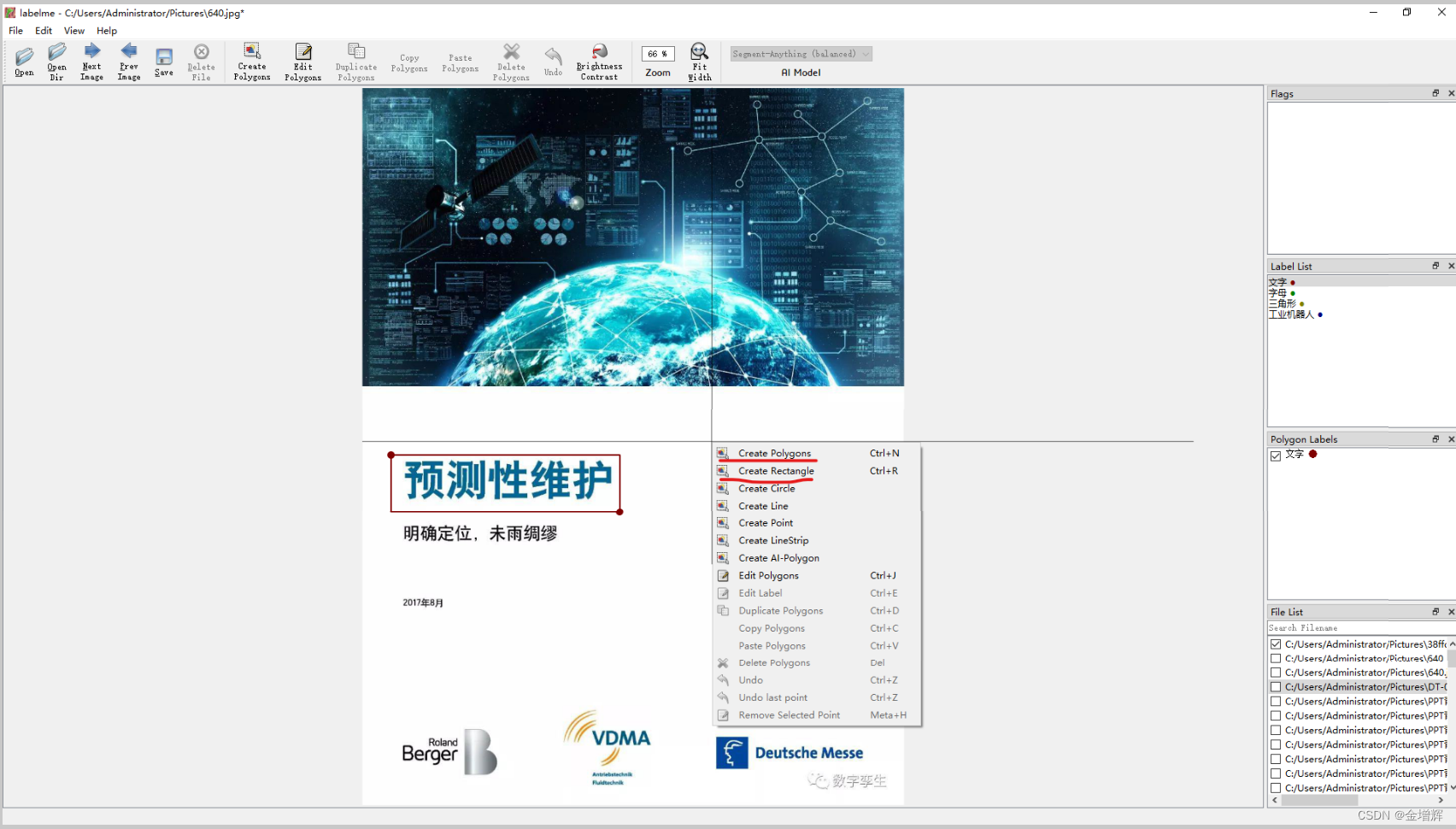
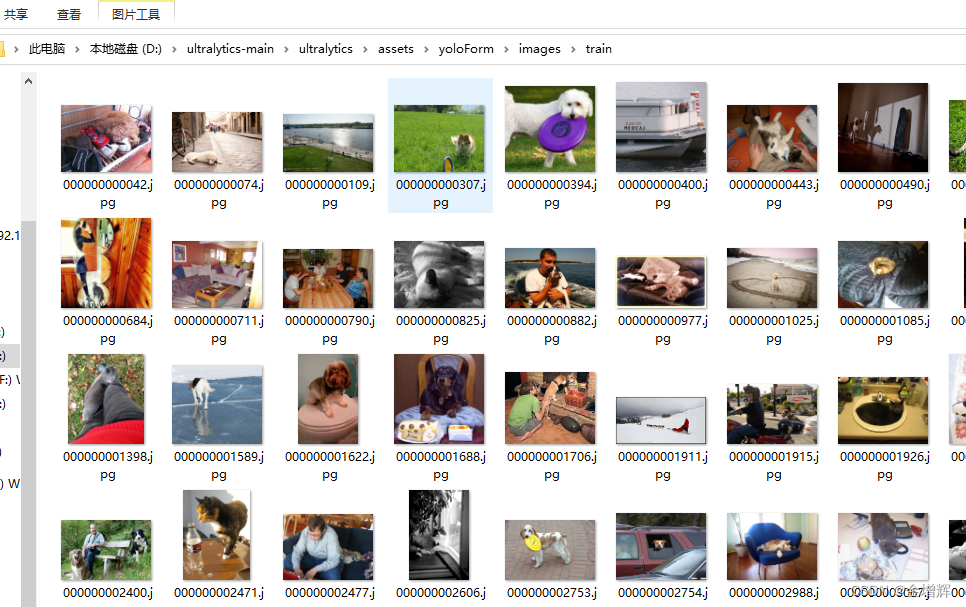
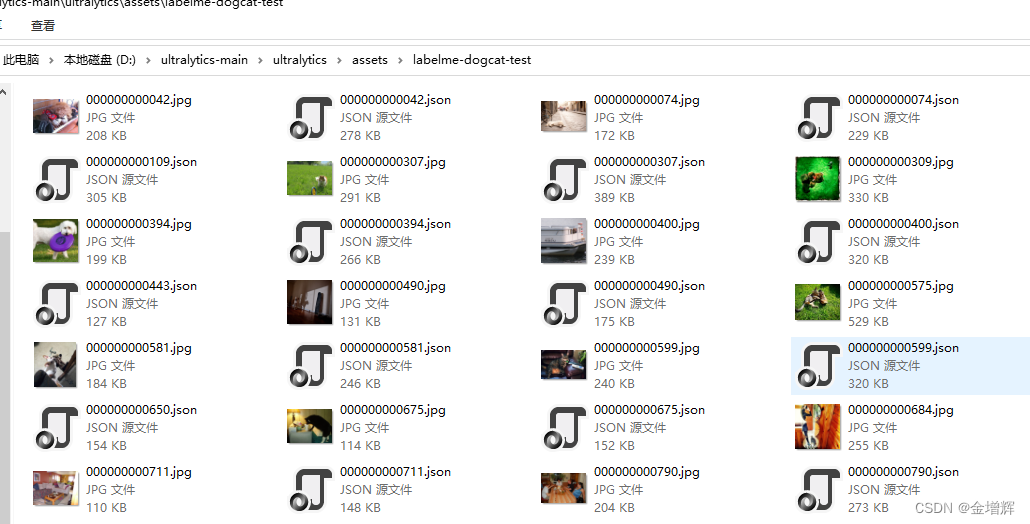
3.在网上找到的别人下载的标注好的图片库labelme-dogcat-test文件夹,里面是一些猫和狗的图片及标注文件,把他们拷贝到了D:\ultralytics-main\ultralytics\assets这个文件夹,如下图所示,在它的上一级目录中新建一个文件夹命名为yoloForm,用于存储转换后的文件。
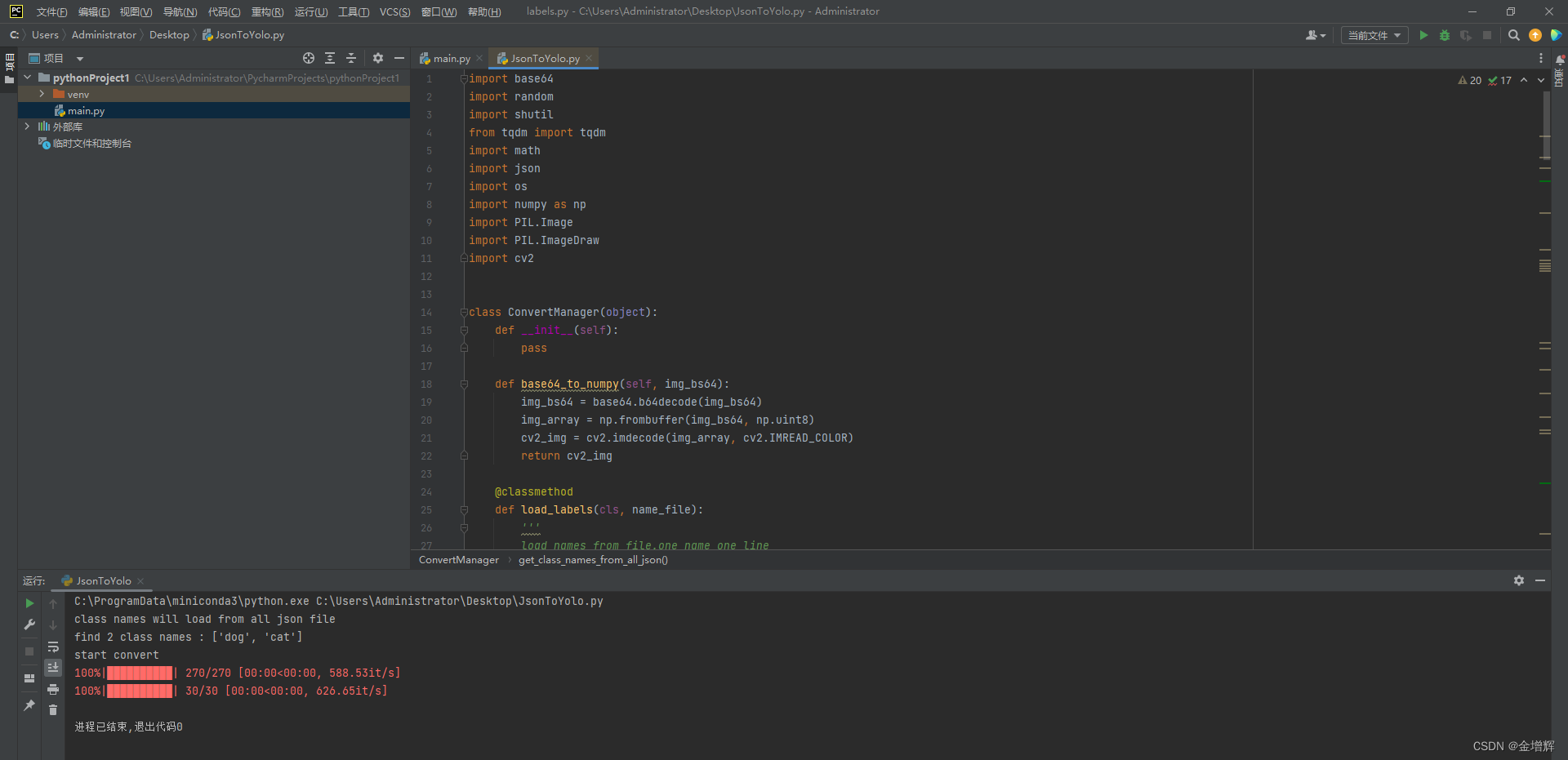
4.把labelme格式转化成yolov8支持的数据集格式,需要下面的脚本,只需要改最后一行,就是数据源地址和目标地址( cm.start(r’源文件路径’, r’保存新位置路径’)),将其存储为JsonToYolo.py格式,执行即可,执行时,如果缺少东西就安装对应的库即可。
import base64
import random
import shutil
from tqdm import tqdm
import math
import json
import os
import numpy as np
import PIL.Image
import PIL.ImageDraw
import cv2
class ConvertManager(object):
def __init__(self):
pass
def base64_to_numpy(self, img_bs64):
img_bs64 = base64.b64decode(img_bs64)
img_array = np.frombuffer(img_bs64, np.uint8)
cv2_img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
return cv2_img
@classmethod
def load_labels(cls, name_file):
'''
load names from file.one name one line
:param name_file:
:return:
'''
with open(name_file, 'r') as f:
lines = f.read().rstrip('\n').split('\n')
return lines
def get_class_names_from_all_json(self, json_dir):
classnames = []
for file in os.listdir(json_dir):
if not file.endswith('.json'):
continue
with open(os.path.join(json_dir, file), 'r', encoding='utf-8') as f:
data_dict = json.load(f)
for shape in data_dict['shapes']:
if not shape['label'] in classnames:
classnames.append(shape['label'])
return classnames
def create_save_dir(self, save_dir):
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
if not os.path.exists(save_dir):
os.makedirs(save_dir)
os.mkdir(images_dir)
os.mkdir(labels_dir)
else:
if not os.path.exists(images_dir):
os.mkdir(images_dir)
if not os.path.exists(labels_dir):
os.mkdir(labels_dir)
return images_dir + os.sep, labels_dir + os.sep
def save_list(self, data_list, save_file):
with open(save_file, 'w') as f:
f.write('\n'.join(data_list))
def __rectangle_points_to_polygon(self, points):
xmin = 0
ymin = 0
xmax = 0
ymax = 0
if points[0][0] > points[1][0]:
xmax = points[0][0]
ymax = points[0][1]
xmin = points[1][0]
ymin = points[1][1]
else:
xmax = points[1][0]
ymax = points[1][1]
xmin = points[0][0]
ymin = points[0][1]
return [[xmin, ymin], [xmax, ymin], [xmax, ymax], [xmin, ymax]]
def convert_dataset(self, json_dir, json_list, images_dir, labels_dir, names, save_mode='train'):
images_dir = os.path.join(images_dir, save_mode) + os.sep
labels_dir = os.path.join(labels_dir, save_mode) + os.sep
if not os.path.exists(images_dir):
os.mkdir(images_dir)
if not os.path.exists(labels_dir):
os.mkdir(labels_dir)
for file in tqdm(json_list):
with open(os.path.join(json_dir, file), 'r', encoding='utf-8') as f:
data_dict = json.load(f)
image_file = os.path.join(json_dir, os.path.basename(data_dict['imagePath']))
if os.path.exists(image_file):
shutil.copyfile(image_file, images_dir + os.path.basename(image_file))
else:
imageData = data_dict.get('imageData')
if not imageData:
imageData = base64.b64encode(imageData).decode('utf-8')
img = self.img_b64_to_arr(imageData)
PIL.Image.fromarray(img).save(images_dir + file[:-4] + 'png')
# convert to txt
width = data_dict['imageWidth']
height = data_dict['imageHeight']
line_list = []
for shape in data_dict['shapes']:
data_list = []
data_list.append(str(names.index(shape['label'])))
if shape['shape_type'] == 'rectangle':
points = self.__rectangle_points_to_polygon(shape['points'])
for point in points:
data_list.append(str(point[0] / width))
data_list.append(str(point[1] / height))
elif shape['shape_type'] == 'polygon':
points = shape['points']
for point in points:
data_list.append(str(point[0] / width))
data_list.append(str(point[1] / height))
line_list.append(' '.join(data_list))
self.save_list(line_list, labels_dir + file[:-4] + "txt")
def split_train_val_test_dataset(self, file_list, train_ratio=0.9, trainval_ratio=0.9, need_test_dataset=False,
shuffle_list=True):
if shuffle_list:
random.shuffle(file_list)
total_file_count = len(file_list)
train_list = []
val_list = []
test_list = []
if need_test_dataset:
trainval_count = int(total_file_count * trainval_ratio)
trainval_list = file_list[:trainval_count]
test_list = file_list[trainval_count:]
train_count = int(train_ratio * len(trainval_list))
train_list = trainval_list[:train_count]
val_list = trainval_list[train_count:]
else:
train_count = int(train_ratio * total_file_count)
train_list = file_list[:train_count]
val_list = file_list[train_count:]
return train_list, val_list, test_list
def start(self, json_dir, save_dir, names=None, train_ratio=0.9):
images_dir, labels_dir = self.create_save_dir(save_dir)
if names is None or len(names) == 0:
print('class names will load from all json file')
names = self.get_class_names_from_all_json(json_dir)
print('find {} class names :'.format(len(names)), names)
if len(names) == 0:
return
self.save_list(names, os.path.join(save_dir, 'labels.txt'))
print('start convert')
all_json_list = []
for file in os.listdir(json_dir):
if not file.endswith('.json'):
continue
all_json_list.append(file)
train_list, val_list, test_list = self.split_train_val_test_dataset(all_json_list, train_ratio)
self.convert_dataset(json_dir, train_list, images_dir, labels_dir, names, 'train')
self.convert_dataset(json_dir, val_list, images_dir, labels_dir, names, 'val')
if __name__ == '__main__':
cm = ConvertManager()
cm.start(r'D:\ultralytics-main\ultralytics\assets\labelme-dogcat-test', r'D:\ultralytics-main\ultralytics\assets\yoloForm')
5.在Pycharm中执行上面的脚本,执行完成后,刚刚新建的文件夹就会有转换后的数据了,如下图所示。