为什么不建议在生产环境中使用Docker Compose
- 多机器如何管理?
- 如何跨机器做scale横向扩展?
- 容器失败退出时如何新建容器确保服务正常运行?
- 如何确保零宕机时间?
- 如何管理密码,Key等敏感数据?
Docker Swarm介绍
Docker Swarm是Docker官方推出的容器集群管理工具,基于Go语言实现。使用它可以将多个Docker主机封装为单个大型的虚拟Docker主机,快速打造一套容器云平台。
Docker Swarm是生产环境中运行Docker应用程序最简单的方法。作为容器集群管理器,Swarm最大的优势之一就是100%支持标准的Docker API。各种基于标准API的工具比如Compose、docker-py、各种管理软件,甚至 Docker本身等都可以很容易的与Swarm进行集成。大大方便了用户将原先基于单节点的系统移植到Swarm上,同时Swarm内置了对 Docker网络插件的支持,用户可以很容易地部署跨主机的容器集群服务。
Docker Swarm和Docker Compose一样,都是Docker官方容器编排工具,但不同的是,Docker Compose是一个在单个服务器或主机上创建多个容器的工具,而Docker Swarm则可以在多个服务器或主机上创建容器集群服务,对于微服务的部署,显然Docker Swarm会更加适合。
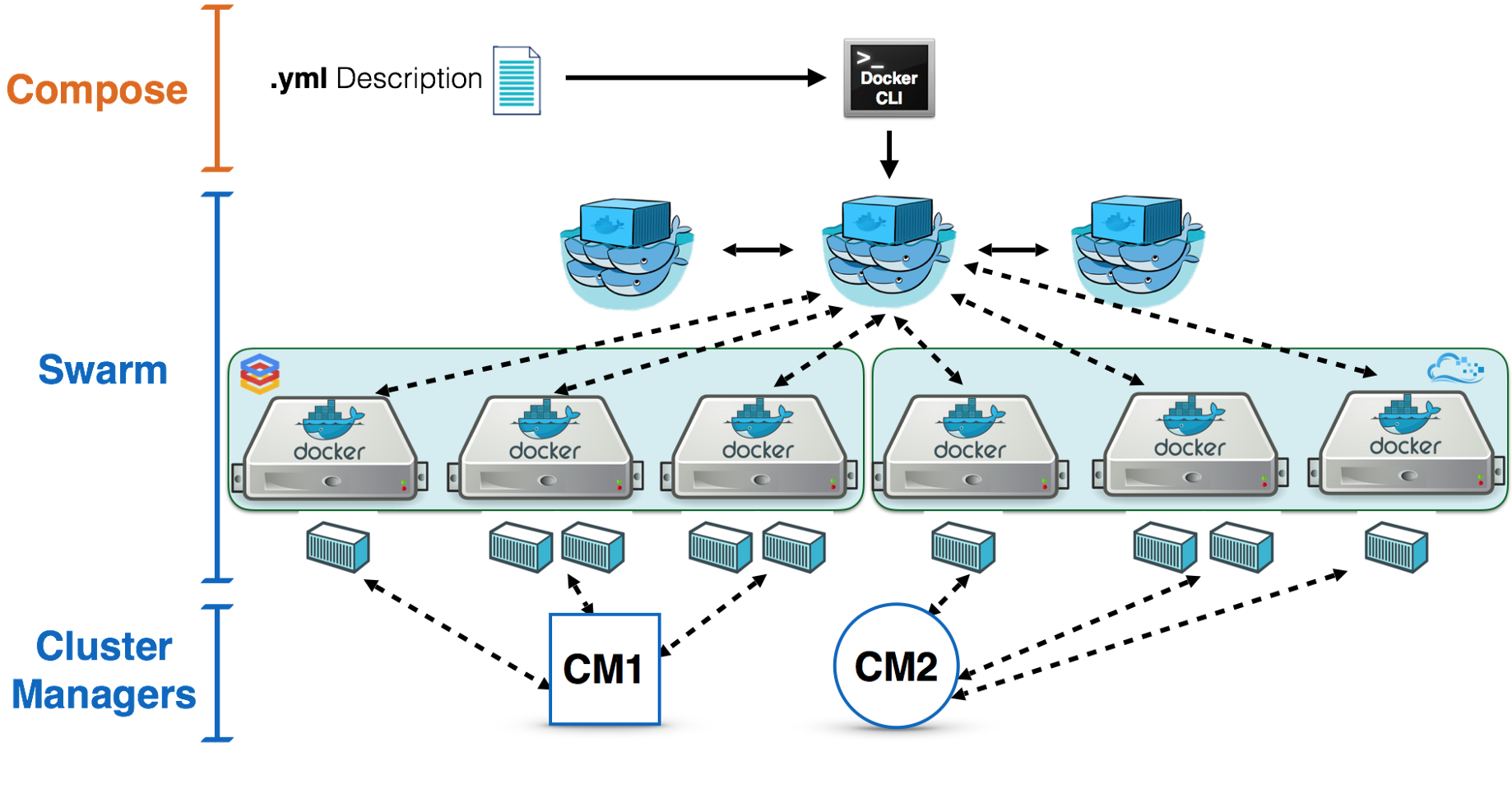
Swarm的基本架构
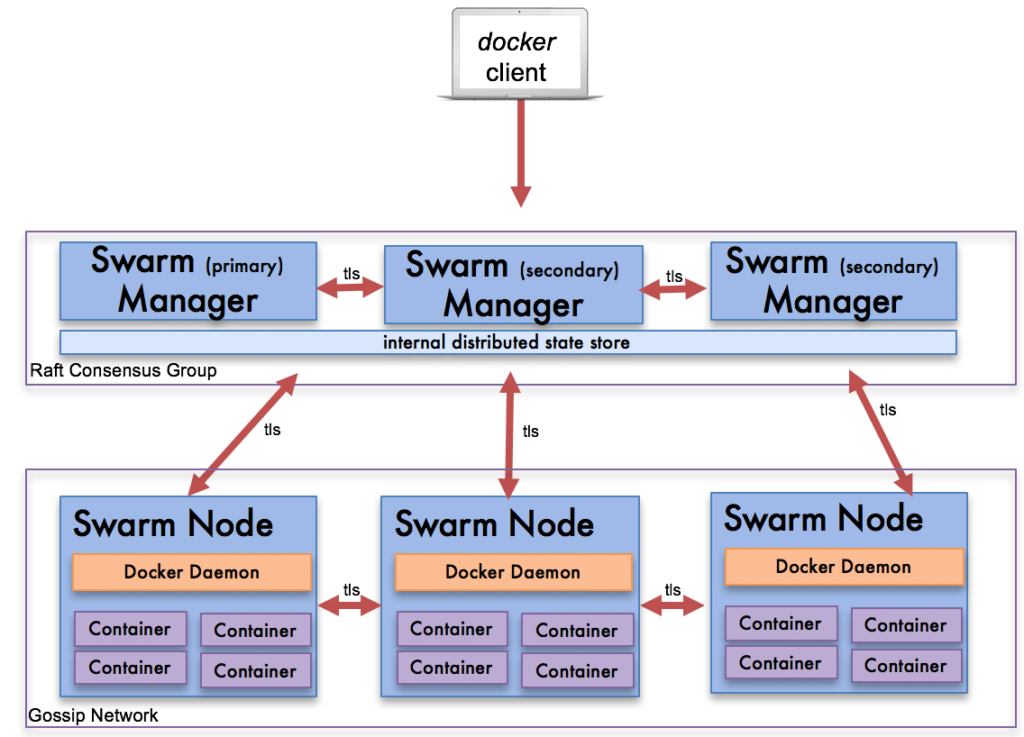
Swarm单节点快速上手
激活Docker Swarm
docker info这个命令可以查看我们的docker engine有没有激活swarm模式, 默认是没有的,我们会看到
$ docker info | grep Swarm
Swarm: inactive
激活swarm,有两个方法:
- 初始化一个swarm集群,自己成为manager
- 加入一个已经存在的swarm集群
初始化一个swarm集群,自己成为manager:
$ docker swarm init --advertise-addr 192.168.0.13
Swarm initialized: current node (1iohpmz3jxqecpeixv77bkz6k) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-45kligs4iwu0sqdy2xxvf4mrauggwc5hlmo7sj9u5ve5cjtek4-54bo11h1uwa6yfva1jf9g2blb 192.168.0.13:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
加入一个已经存在的swarm集群:
$ docker swarm join --token SWMTKN-1-45kligs4iwu0sqdy2xxvf4mrauggwc5hlmo7sj9u5ve5cjtek4-54bo11h1uwa6yfva1jf9g2blb 192.168.0.13:2377
查看swarm集群中的机器节点:
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
xk8ryecmxfqu65zvsgk41h8cd * node1 Ready Active Leader 24.0.2
再次使用docker info这个命令可以看到我们的docker engine已经激活swarm模式:
$ docker info | grep Swarm
Swarm: active
docker swarm init 背后发生了什么
主要是PKI和安全相关的自动化
- 创建swarm集群的根证书
- manager节点的证书
- 其它节点加入集群需要的tokens
- 创建Raft数据库用于存储证书,配置,密码等数据
RAFT相关资料
- http://thesecretlivesofdata.com/raft/
- https://raft.github.io/
- https://docs.docker.com/engine/swarm/raft/
Swarm三节点集群搭建
创建3节点swarm cluster的方法
- https://labs.play-with-docker.com/网站,优点是快速方便,缺点是环境不持久,4个小时后环境会被重置
- 在本地通过虚拟化软件搭建Linux虚拟机,优点是稳定,方便,缺点是占用系统资源,需要电脑内存最好8G及其以上
- 在云上使用云主机, 亚马逊,Google,微软Azure,阿里云,腾讯云等,缺点是需要消耗金钱(但是有些云服务,有免费试用)
多节点的环境涉及到机器之间的通信需求,所以防火墙和网络安全策略组是大家一定要考虑的问题,特别是在云上使用云主机的情况,下面这些端口记得打开防火墙以及设置安全策略组:
- Port 2377 TCP for communication with and between manager nodes
- Port 7946 TCP/UDP for overlay network node discovery
- Port 4789 UDP (configurable) for overlay network traffic
为了简化,以上所有端口都允许节点之间自由访问就行。
添加2个节点到Swarm
主机规划:
- 192.168.0.13:manager
- 192.168.0.12:worker
- 192.168.0.11:worker
添加192.168.0.12到Swarm:
$ docker swarm join --token SWMTKN-1-45kligs4iwu0sqdy2xxvf4mrauggwc5hlmo7sj9u5ve5cjtek4-54bo11h1uwa6yfva1jf9g2blb 192.168.0.13:2377
This node joined a swarm as a worker.
添加192.168.0.11到Swarm:
$ docker swarm join --token SWMTKN-1-45kligs4iwu0sqdy2xxvf4mrauggwc5hlmo7sj9u5ve5cjtek4-54bo11h1uwa6yfva1jf9g2blb 192.168.0.13:2377
This node joined a swarm as a worker.
查看Swarm中的节点:
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
1iohpmz3jxqecpeixv77bkz6k * node1 Ready Active Leader 24.0.2
k7sl3sg1x193nalsdjs6dw20w node2 Ready Active 24.0.2
aitp94gxkvg997b5qev271v2y node3 Ready Active 24.0.2
ID后面的*表示的是当前节点,docker node ls需要在manager节点执行。
发布一个service到swarm
可以使用docker service create来创建一个service:
$ docker service create --replicas 1 --name helloworld alpine ping docker.com
dq7ch2rdyijjvuh03k6sorw3q
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
可以使用docker service ls查看启动了哪些服务:
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
dq7ch2rdyijj helloworld replicated 1/1 alpine:latest
查看service详情
可以使用docker service inspect来查看service的详情:
$ docker service inspect helloworld
[
{
"ID": "dq7ch2rdyijjvuh03k6sorw3q",
"Version": {
"Index": 21
},
"CreatedAt": "2023-10-12T02:28:33.280090826Z",
"UpdatedAt": "2023-10-12T02:28:33.280090826Z",
"Spec": {
"Name": "helloworld",
"Labels": {},
"TaskTemplate": {
"ContainerSpec": {
"Image": "alpine:latest@sha256:eece025e432126ce23f223450a0326fbebde39cdf496a85d8c016293fc851978",
"Args": [
"ping",
"docker.com"
],
"Init": false,
"StopGracePeriod": 10000000000,
"DNSConfig": {},
"Isolation": "default"
},
"Resources": {
"Limits": {},
"Reservations": {}
},
"RestartPolicy": {
"Condition": "any",
"Delay": 5000000000,
"MaxAttempts": 0
},
"Placement": {
"Platforms": [
{
"Architecture": "amd64",
"OS": "linux"
},
{
"OS": "linux"
},
{
"OS": "linux"
},
{
"Architecture": "arm64",
"OS": "linux"
},
{
"Architecture": "386",
"OS": "linux"
},
{
"Architecture": "ppc64le",
"OS": "linux"
},
{
"Architecture": "s390x",
"OS": "linux"
}
]
},
"ForceUpdate": 0,
"Runtime": "container"
},
"Mode": {
"Replicated": {
"Replicas": 1
}
},
"UpdateConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"Monitor": 5000000000,
"MaxFailureRatio": 0,
"Order": "stop-first"
},
"RollbackConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"Monitor": 5000000000,
"MaxFailureRatio": 0,
"Order": "stop-first"
},
"EndpointSpec": {
"Mode": "vip"
}
},
"Endpoint": {
"Spec": {}
}
}
]
可以加上--pretty参数输出可读性更好的内容格式:
$ docker service inspect --pretty helloworld
ID: dq7ch2rdyijjvuh03k6sorw3q
Name: helloworld
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:eece025e432126ce23f223450a0326fbebde39cdf496a85d8c016293fc851978
Args: ping docker.com
Init: false
Resources:
Endpoint Mode: vip
可以使用docker service ps查看service运行在哪些node上:
$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
8xi2hbecua0s helloworld.1 alpine:latest node2 Running Running 7 minutes ago
也可以使用docker ps在node2上查看启动了哪些容器:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9acee1709671 alpine:latest "ping docker.com" 9 minutes ago Up 9 minutes helloworld.1.8xi2hbecua0s278o91jmod8li
对service进行扩容和缩容
可以使用docker service scale对服务进行扩容和缩容,任务数量比原来的多就是扩容,任务数量比原来的少就是缩容:
$ docker service scale helloworld=5
helloworld scaled to 5
overall progress: 5 out of 5 tasks
1/5: running [==================================================>]
2/5: running [==================================================>]
3/5: running [==================================================>]
4/5: running [==================================================>]
5/5: running [==================================================>]
verify: Service converged
$ docker service ps helloworld
ID NAME IMAGE service NODE DESIRED STATE CURRENT STATE ERROR PORTS
8xi2hbecua0s helloworld.1 alpine:latest node2 Running Running 31 minutes ago
72s13jwy17fh helloworld.2 alpine:latest node1 Running Running 21 seconds ago
l7js9yqaoela helloworld.3 alpine:latest node3 Running Running 21 seconds ago
kyj28313lqng helloworld.4 alpine:latest node3 Running Running 21 seconds ago
pzbgzk1hrihp helloworld.5 alpine:latest node2 Running Running 22 seconds ago
删除一个service
可以使用docker service rm来删除一个service
$ docker service rm helloworld
helloworld
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
滚动更新service
$ docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6
p7x6a22i3pagnpvt9pyrzack8
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
[node1] (local) root@192.168.0.13 ~
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
tynsv7a56x1t redis.1 redis:3.0.6 node1 Running Running 23 seconds ago
55c4yfweaja7 redis.2 redis:3.0.6 node2 Running Running 22 seconds ago
r3hcrtgxlehp redis.3 redis:3.0.6 node3 Running Running 23 seconds ago
[node1] (local) root@192.168.0.13 ~
$
[node1] (local) root@192.168.0.13 ~
$ docker service inspect --pretty redis
ID: p7x6a22i3pagnpvt9pyrzack8
Name: redis
Service Mode: Replicated
Replicas: 3
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: redis:3.0.6@sha256:6a692a76c2081888b589e26e6ec835743119fe453d67ecf03df7de5b73d69842
Init: false
Resources:
Endpoint Mode: vip
将redis:3.0.6滚动升级为redis:3.0.7:
$ docker service update --image redis:3.0.7 redis
redis
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
[node1] (local) root@192.168.0.13 ~
$ docker service inspect --pretty redis
ID: p7x6a22i3pagnpvt9pyrzack8
Name: redis
Service Mode: Replicated
Replicas: 3
UpdateStatus:
State: completed
Started: About a minute ago
Completed: 22 seconds ago
Message: update completed
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: redis:3.0.7@sha256:730b765df9fe96af414da64a2b67f3a5f70b8fd13a31e5096fee4807ed802e20
Init: false
Resources:
Endpoint Mode: vip
[node1] (local) root@192.168.0.13 ~
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
sard15sxoo3b redis.1 redis:3.0.7 node1 Running Running about a minute ago
tynsv7a56x1t \_ redis.1 redis:3.0.6 node1 Shutdown Shutdown about a minute ago
xzkhsd9nuqxj redis.2 redis:3.0.7 node2 Running Running 53 seconds ago
55c4yfweaja7 \_ redis.2 redis:3.0.6 node2 Shutdown Shutdown 58 seconds ago
jkadyq5a9ekq redis.3 redis:3.0.7 node3 Running Running about a minute ago
r3hcrtgxlehp \_ redis.3 redis:3.0.6 node3 Shutdown Shutdown about a minute ago
移除一个节点
现在的节点情况:
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
sard15sxoo3b redis.1 redis:3.0.7 node1 Running Running 4 minutes ago
xzkhsd9nuqxj redis.2 redis:3.0.7 node2 Running Running 3 minutes ago
jkadyq5a9ekq redis.3 redis:3.0.7 node3 Running Running 4 minutes ago
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
bbg9dqcotcgfe2ikgyjgc7nge * node1 Ready Active Leader 24.0.2
7kj69w9cdpyawh54fumibuu0u node2 Ready Active 24.0.2
x8x5ox0e6pfx4jg311m564a45 node3 Ready Active 24.0.2
可以使用docker node update --availability drain来将一个节点排除:
$ docker node update --availability drain node2
node2
可以使用docker node inspect来查看节点的详情:
$ docker node inspect --pretty node2
ID: 7kj69w9cdpyawh54fumibuu0u
Hostname: node2
Joined at: 2023-10-12 03:40:28.774753447 +0000 utc
Status:
State: Ready
Availability: Drain
。。。
Availability已经变为Drain。
再来看看redis的实例少了没:
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
sard15sxoo3b redis.1 redis:3.0.7 node1 Running Running 5 minutes ago
mxukqpq3xb5h redis.2 redis:3.0.7 node1 Running Running 53 seconds ago
xzkhsd9nuqxj \_ redis.2 redis:3.0.7 node2 Shutdown Shutdown 54 seconds ago
jkadyq5a9ekq redis.3 redis:3.0.7 node3 Running Running 5 minutes ago
发现原来部署在node2上的redis容器停止了,自动在node1上启动了一个新的redis容器。
可以使用docker node update --availability active命令将node2重新激活:
$ docker node update --availability active node2
node2
$ docker node inspect --pretty node2
ID: 7kj69w9cdpyawh54fumibuu0u
Hostname: node2
Joined at: 2023-10-12 03:40:28.774753447 +0000 utc
Status:
State: Ready
Availability: Active
Address: 192.168.0.12
。。。。。。