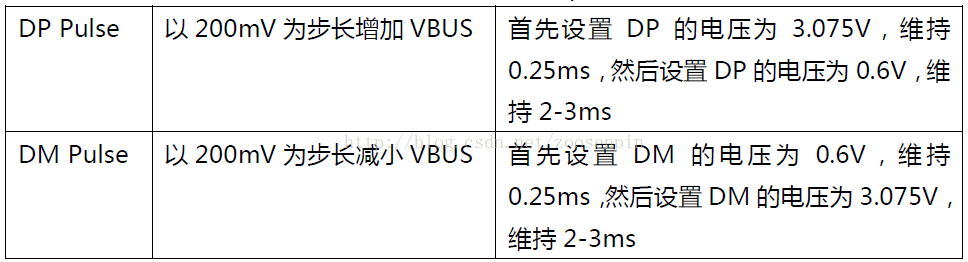
文章目录
- 《Nerf: Neural radiance field in 3d vision, a comprehensive review 》
- 一、数据集:
- 二、基于方法的分类(Method-based Taxonomy)
- 三、基于应用的分类(Application-based Taxonomy)
- 四、未来展望
《Nerf: Neural radiance field in 3d vision, a comprehensive review 》
Author: University of Waterloo,
一、数据集:
\quad
Realistic Synthetic 360°:从Blender软件中制作的,共8个场景,well bounded,聚焦于单个对象。视角方面,6个场景从上半球进行采样,2个场景从整个球体进行采样。
\quad
LLFF: consists of 24 real-life scenes captured from handheld cellphone cameras。其中图像的pose使用COLMAP制作。视角方面,forward facing towards the central object。
\quad
DTU:由一个工业机器人拍摄的,它上面绑定了一个相机和一个结构更扫描器,分别用来拍摄图像和密集点云。相机内参和pose用matlab的工具箱制作。视角方面,在以目标为中心的球体上进行采样。
\quad
ScanNet:large-scale (2.5 million views of indoor scenes) real-life RGB-D数据集,语义标签非常丰富,**适用于需要利用语义信息的模型和任务,**比如场景编辑、场景分割和语义视图合成。
\quad
ShapeNet:一个大规模的合成数据集,包含了3135个类别的CAD 模型,它的12个普通目标类别的子集最常被用到。当基于目标的语义标签是某个NeRF模型的特定部分时,这个数据集有时会被用到。
\quad 除了上面几个常用的数据集外,下面还有一些针对于特定场景下的数据集。
1)Building-scale Dataset:
- Tanks and Temples dataset
- Matterport-3D dataset
- Replica dataset
2)Large-Scale Urban Datasets:流行的自动驾驶基准数据集有多种数据模式,如图像、深度图、激光雷达点云、姿态和语义图,这些数据模式可能适用于某些希望针对城市场景的NeRF模型。
- KITTI:原始的深度预测数据集对NeRF训练有挑战,因为它的摄像机覆盖范围相对于NeRF数据集相对稀疏,在设计模型时需要考虑稀疏视图。最近的Kitti-360数据集是对它的一个扩展,甚至包括一个NVS基准。
- Waymo Open Dataset
3)Human Avatar/Face Dataset:
- Nerfies 和 HyperNerf:聚焦于人脸的单摄像机数据集。前者包含静止和动态的人类,后者关注拓扑变化,比如人类打开、关闭嘴巴或眼睛等。
- ZJU-MOCap LightStage dataset:由9个动态人体序列组成的运动数据集。
- NeuMan dataset:由6个视频组成,每10到20秒长,由手机摄像头捕捉到,跟随一个行走的人类受试者执行额外的简单动作,如旋转或挥手。
- CMU Panoptic dataset
二、基于方法的分类(Method-based Taxonomy)
\quad
作者根据目前NeRF的方法,将所有文章分为了如下7大类。

\quad 1)Improvements in the Quality of Synthesized Views and Learned Geometry(这一章的工作都是提升NVS图像质量的)
\quad a) Better View Synthesis
\quad
Mip-NeRF(2021.05)使用 cone tracing 而不是NeRF中的ray tracing,mipNeRF模型在本质上是多尺度的,并自动执行anti-aliasing。Mip-NeRF 360 是一项极具影响力的工作,它将Mip-NeRF直接扩展到 unbounded 场景。它对Mip-NeRF做出的改由有三点:①使用NeRF MLP来监督一个 proposal MLP;②这个proposal MLP只预测体积密度(而不是颜色),用于寻找适当的采样间隔。并且,针对Mip-NeRF中的高斯模型构造了一种新的场景参数化方法;③引入了一种新的正则化方法,防止漂浮几何伪影和背景坍塌。
\quad
Ref-NeRF(2021.12)建立在mip-NeRF的基础上,被设计用于更好地建模反射表面。这个方法是一个引入图形学知识比较多的方法。它根据局部法向量的观测方向的反射参数化NeRF。他们将density MLP(第一个MLP)修改为一个无方向的MLP,不仅输出 密度 和 方向MLP的输入特征向量,而且还输出漫射颜色(diffuse color)、镜面颜色(specular color)、粗糙度(roughness)和表面法线(surface normal)。漫射颜色和镜面颜色相乘,加到镜面颜色(方向MLP的输出),得到最终的颜色。此外,他们使用从由粗糙度参数化的球面高斯分布中采样的向量的球面谐波来参数化方向向量。Ref-NeRF在反射表面上表现特别好,能够准确地建模镜面反射和高光图像。
\quad Reg-NeRF(2021.12)的目的是解决NeRF训练时稀疏输入的问题,大多数之前的方法通过使用预训练网络的图像特征作为调节NeRF体积渲染的先验,与此不同,RegNeRF采用了额外的深度和颜色正则化。
\quad b) Depth Supervision and Point Cloud
\quad 通过使用从LiDAR或SfM获得的点云来监督深度,这些模型的收敛速度更快,最终质量更高,并且比baseline NeRF模型需要更少的训练视图。**这些模型大多是 few-shot / sparse views NeRF。**在本节的最后,介绍了其他几何改进的方法。
\quad DS-NeRF(2021.07),Depth-Supervised NeRF,除了使用颜色监督之外,还使用了用COLMAP [2]从训练图像中提取的稀疏点云来进行深度监督。在这个文章中,深度被建模为由稀疏点云记录的一个正态分布。增加了一个KL散度项来最小化ray分布和这个噪声深度分布的散度。
\quad 与此同时,另一项有影响力的工作 dense_depth_priors_nerf(2021.04) 先使用COLMAP提取稀疏点云,并由一个Depth Completion Network来处理生成深度和不确定性图。除了标准的volumetric loss外,作者还引入了一种基于预测的深度和不确定性的depth loss。这个工作的效果很好,比DS-NeRF、NerfingMVS的效果好很多。
\quad PointNeRF(2022年1月)使用特征点云作为体素渲染的中间步骤。point-nerf也可以选择 per-scene optimization 和 no per-scene optimization 两种模式,但它的泛化效果不好,还没有MVSNeRF、IBRNet的好。
\quad 2)Few Shot / Sparse Training View NeRF
\quad 原始NeRF需要大量的训练图像,它的一个常见失败案例是:训练样本太少或样本在姿态上变化不够。这种情况下原始NeRF对个别视图过拟合,并对场景几何不敏感。然而,a family of NeRF methods利用预先训练的图像特征提取网络(一般是CNN),以大大降低NeRF训练所需的样本数量。一些作者称这样的过程为“image feature conditioning”(其实做sparse views的工作大多同时做generalization),一些工作(如pointnerf)使用depth/3D geometry监督也可以实现这样的效果。增加深度或其他正则化的方法也可以降低对训练样本数量的需求。
\quad 这个系列的工作有:PixelNeRF(2020.12);MVSNeRF(2021.03);DietNeRF(2021.06,引入CLIP并提出语义一致性损失);NeuRay(2021.07);GeoNeRF(2021.11);LOLNeRF(2021.11,few-shot 人脸视图合成,类似于 π \pi π-GAN,但是使用Generative Latent Optimization而不是对抗学习);NeRFusion(2022.03,相当于MVVSNeRF+RNN);SinNeRF(2022.04)尝试通过整合多种技术从单个图像中进行NeRF场景重建,它利用 image warping 和相机内参和pose来制作 reference depth,以对 unseen views进行监督,还利用一个CNN 判别器来提供patch-wise的纹理监督,还使用预训练的ViT从参考补丁和unseen补丁中提取全局图像特征,并将其与L2损失项和全局结构先验进行比较。GeoAug(2022.10)用new noisy camera poses渲染新的训练图像,利用数据增强的方式来解决few-shot问题。
\quad 3)Generative and Conditional Models
\quad 生成式NeRF模型通常使用二维生成模型来创建“场景”的图像,然后用于训练NeRF模型。
\quad 4)Unbounded Scene and Scene Composition
\quad 将NeRF应用于室外场景,一个需求就是将前景与背景分离。在室外场景下还有另外一个挑战,那就是image-by-image的外貌和光线变化。为了解决这个问题,许多方法采用 image-by-image的外貌编码来制作latent condition。
\quad 场景耦合这个方向,一般都是用两个MLP,一个用于前景,一个用于背景。这两个MLP中,为了保证不同视图下的区别,可能会用condition NeRF。这种分别表征的架构,有可借鉴之处,或许可以把这种架构用在泛化性NeRF中,用来表征不变和变的组件。
\quad
NeRF-W(2020.08)这篇论文解决了传统NeRF的两个问题。由于光照条件的变化,同一个场景的 real-life photographs 可能包含图片之间的外貌变化,这就像每张图片中的transient objects是不同的那样。基于这样的观点,在NeRF-W中,对于一个场景的所有照片(视图),密度应当都是一样的,所以 density MLP都是一样的,但是,不同视图下的外貌是不一样的。所以NeRF-W制作了一个per-image appearance embedding作为 color MLP的condition,网络架构如下图所示。在这样的结构下,NeRF-W在速度上并没有提升,但是在这个数据集上的效果却提升很大。

\quad
NeRF++(2020.10)是被设计用来在unbounded scene中进行NVS的。它用一个sphere将场景分开,内部包含所有的前景目标,外部包含背景,内部和外部分别用一个MLP进行训练。此外,这篇文章更有意思的是,对NeRF模型如何强大进行了评价,即对NeRF模型如何解决shape-radiance ambiguitiy进行了评价。这个ambiguity简单来说就是sigma和rgb重点学哪一个的问题,即在给定训练数据下,网络在拟合相对准确场景view-dependent appearance的同时,可能其对场景几何预测不准确。根据这篇文章的观点,错误的密度配置往往会导致具有高频成分的颜色配置与视角有关。然而,通过它的构造(使用低频分量和在MLP的后期阶段引入视角),NeRF模型倾向于产生更平滑的颜色配置。NeRF++的分析中,指出NeRF建模的其实是一个球面,它将外貌拟合为球面上的surface light field。具体细节看原文,值得一看。
\quad GIRAFFE(2020.11)与NeRF-W的方式很像,基于GRAF,使用 latent code,用两个MLP分割前景和背景用于场景耦合。
\quad NeRFReN(2021.11)将辐射场分为transmitted 和reflected两部分,解决了NVS的NeRF的reflective surfaces问题
\quad 5)Others Neural Volume Rendering
\quad 其他神经体素渲染的方法,主要是用Transformer来代替,代表性的文章有IBRNet(2021.02)、SRT(2021.11)等。
三、基于应用的分类(Application-based Taxonomy)
\quad
作者根据应用场景,将NeRF的工作分为以下几类:

\quad
1)urban场景
\quad
随着对自动驾驶和城市摄影测量(Photogrammetry,摄影测量是通过捕捉并拼接图像信息来创建物理世界的数字模型的过程)的兴趣提升,最近来看,urban NeRF模型在street-level和remote-level的发展上已经激增。在这个过程中,urban场景的以下几个挑战逐渐突显:①户外场景是unbounded;②相机的pose通常缺乏多样性;③需要大规模的场景。
\quad Urban Radiance Fields(2021.11)在激光雷达的深度损失的辅助下,进行urban场景的重建。Block-NeRFs(2022.02)从280万张street-level街景图片进行城市级别的重建,这样的大规模户外数据集带来了瞬态外观和物体等问题。 每个单独的BlockNeRF都是建立在mip-NeRF 上,使用其IPE和NeRF-W,以及使用其外观latent code优化。作者在NeRF训练中使用语义分割来掩盖行人和汽车等瞬态物体。A visibility MLP也被平行训练,用于丢弃能见度低的block-nerf
\quad
2)Human Faces and Avatars, and Articulated Objects
\quad
这一个方向也有很多文章,以后有兴趣再看。
\quad
3)Image Processing
\quad
DeblurNeRF(2021.11)、NeRF-SR(2021.12)、NaN(2022.04)、RawNeRF(2022)等文章关注low-level CV的一些方向,比如denoising, deblurring,super-resolution等,目的是从低质量的训练图像合成高质量的视图。
\quad
4)Surface Reconstruction
\quad
NeRF模型的scene geometry是隐式的,并且隐藏在神经网络中。然而,对于某些应用而言,更显式的表示是需要的,如三维网格。对于baseline NeRF,可以通过评估和阈值化密度MLP来提取一个粗略的几何形状。一些典型的工作有:Neural Surface (NeuS)(2021.06),SparseNeus(2022.06)等。
四、未来展望
\quad 在过去的两年中,NeRF模型取得了巨大的进展,并解决了基线NeRF的一些缺点。未来,NeRF有一些几个方向需要去努力。
\quad 1)提升速度
\quad
2)关于质量
\quad
**一种已被证明有效的方法是:使用per-image的transient latent code和appearance code,**像在NeRF-W、GARF中。这些code允许NeRF模型控制每幅图像的照明和颜色变化,以及场景内容的小变化。
\quad
3)关于sparse views
\quad
sparse views 和 few-shot 的NeRF模型通常使用依赖于2D/3D特征提取技术,依赖于预训练的CNN。一些模型还合并了来自SfM的点云数据,以进行额外的监督。目前的这些方法其实已经实现了few-shot(2-10 views)的目标,即使再用更先进的backbone,也只能带来性能上微小的改进。 未来稀疏视图的NVS有以下两个方向需要努力:
\quad
一个方向是:将 sparse view 方法与 fast 方法相结合,以实现在可移动设备上的NeRF模型的快速训练和推理。
\quad
另一个方向是:使用扩散方法和图像-字符串标识符微调实现 single-shot NeRF。未来,将 few-shot NeRF 与 基于文本的扩散模型 进行结合,是一个趋势。
\quad
4)关于应用
\quad
NeRF目前有两个可行性的应用:urban环境 或 human avatars 的重建。从密度MLP中提取三维网格、点云或SDF,或者探索更快的NeRF模型,这些方向都是有必要的。diffusion-guided human avatar generation也是一个热门方向。
\quad 2D扩散模型最近使具有场景和对象编辑功能的text-to-3d NeRF模型的开发成为可能,这允许从文本提示中生成3D网格和纹理,在3D图形学中具有巨大的应用潜力。diffusion-powered NeRF目前仍处于起步阶段,在不久的将来这一领域会取得重大进展。基于NeRF的生成式3D模型 或 具有显式/混合场景表示的神经渲染,将对3D图形行业产生重要的影响。