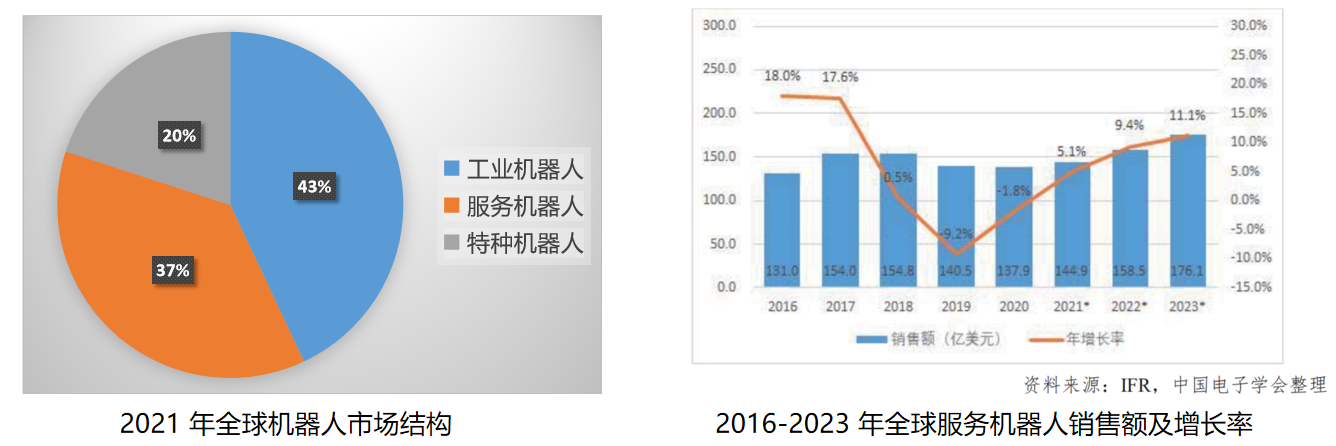
“ 架设一个亿级高并发系统,是多数程序员、架构师的工作目标。 许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”
开篇
要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。
虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。
一.什么是领域驱动设计(DDD)
首先要知道DDD是一种开发理念,核心是维护一个反应领域概念的模型(领域模型是软件最核心的部分,反应了软件的业务本质),然后通过大量模式来指导模型设计与开发。
DDD的一般过程是:
首先通过软件需求规格说明书或原型生成一个领域模型(类、类的属性、类与类之间的关系);
然后根据模式(应该如何分层?、领域逻辑写在哪?与持久化如何交互?如何协调多对象领域逻辑?如何实现逻辑与数据存储解耦等)指导来实现代码模型。
二.为什么使用DDD
DDD能应对复杂性与快速变化:
1.从技术维度实现分层:能够在每层关注自己的事情,比如领域层关注业务逻辑的事情,仓储关注持久化数据的事情,应用服务层关注用例的事情,接口层关注暴露给前端的事情。
2.业务维度:通过将大系统划分层多个上下文,可以让不同团队和不同人只关注当前上下文的开发。
3.时间维度:通过敏捷式迭代快速验证,快速修正。
01
—
传统架构与DDD经典架构区别
传统三层架构以及问题

传统架构
问题:
1.过分注重数据访问层,而不重视领域。
2.业务逻辑直接与数据访问层耦合,与领域为核心的DDD思想背道而驰。
3.没有一系列的模式与方法论指导这种分层架构的开发约束。
经典DDD架构:
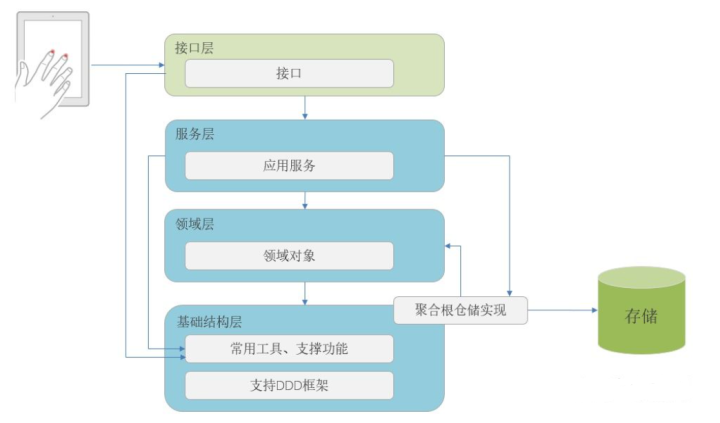
DDD经架构
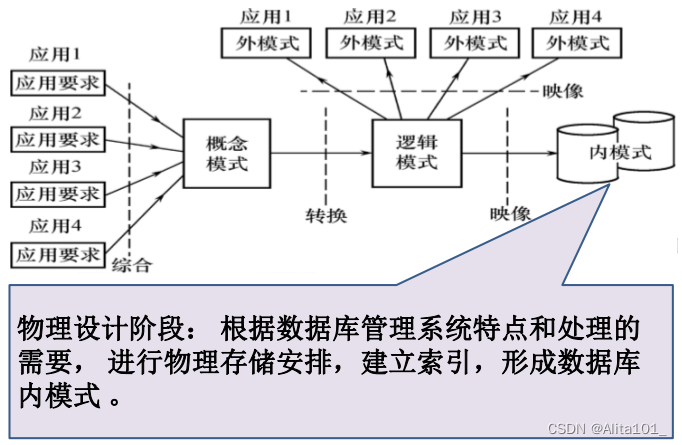
1.基础结构层:整个产品或系统的底层支撑
a.常用工具、支撑功能:这个.net core项目至少要实现以下的功能:Json配置文件的读取、WebApi返回给前端的基本格式对象的定义、Json序列化与反序列化、加密功能、依赖注入框架的二次封装等。
b.支持DDD框架:这个.net core 项目至少要实现以下的功能:聚合根接口定义、实体接口定义、值对象接口定义、仓储接口定义、仓储接口的EF Core顶层实现(工作单元模式)。
c.聚合根仓储实现:这个.net core项目严格来讲其实不属于基础结构层部分,只是由于习惯,把它放到基础结构层这个解决方案文件夹中。它其实是引用了领域层的领域对象,并且 从领域层对应的聚合根仓储接口中继承,然后实现领域对象持久化到数据库,这样,仓储实现是依赖衣领对象,领域对象与领域逻辑就不需要依赖仓储。领域模型才是系统真正的核心。
2.领域层:界限上下文的领域逻辑
a.首先要实现这个界限上下文的领域对象的POCO模型。
b.然后针对这个界限上下文的所有领域对象,建立每个领域对象自己的业务逻辑,注意的是,领域对象的业务逻辑最好不与仓储直接发生交互,就算领域逻辑要临时查询数据库也不要这样。
c.定义该界限上下文聚合根的仓储接口,这个接口代表的是聚合根与持久化打交道的基础约束,具体实现还是在基础结构层的聚合根仓储中实现,这样就实现了解耦。把聚合根仓储接口定义在领域层的意义是可以为领域层的调用方-应用服务层的用例提供对聚合持久化支持。
d.定义该界限上下文的EF Core上下文接口并实现,这样就通过映射关系,EF Core就可以处理领域对象与数据库表之间的映射了。
3.应用服务层:界限上下文的用例
a.某个上下文的应用服务层的某个用例,通过调用领域对象的领域逻辑,完成相关领域逻辑的实现。
b.领域逻辑完成后,应用服务层用例调用领域层的聚合根的仓储接口的方法,完成领域对象的预持久化。(应用服务通过基础结构层的依赖注入框架与Json配置文件找到聚合根仓储接口对应的实现)
c.应用服务层用例然后调用基础结构层的EF Core仓储接口的工作单元方式,完成真正的持久化。(应用服务通过基础接口层的依赖注入框架与Json配置文件找到顶层仓储接口对应的工作单元实现)
d.用例返回给接口层需要的前端所需的json对象格式。
4.接口层:非常薄的一层
a.只需要调用应用服务层用例
b.向前端返回所需的json对象格式
从上述架构特点可以看出,聚合根的仓储与领域逻辑完全解耦,是通过应用服务层的用例将他们协调起来完成功能。
我们讲了经典DDD架构对比传统三层架构的优势,以及经典DDD架构每一层的职责后,下面将介绍基础结构层中支持DDD的轻量级框架的主要代码。
02
—
领域建模与微服务
微服务架构众所周知,此处不做赘述。我们创建微服务时,需要创建一个高内聚、低耦合的微服务。而DDD中的限界上下文则完美匹配微服务要求,可以将该限界上下文理解为一个微服务进程。
上述是从更直观的角度来描述两者的相似处。
在系统复杂之后,我们都需要用分治来拆解问题。一般有两种方式,技术维度和业务维度。技术维度是类似MVC这样,业务维度则是指按业务领域来划分系统。
微服务架构更强调从业务维度去做分治来应对系统复杂度,而DDD也是同样的着重业务视角。 如果两者在追求的目标(业务维度)达到了上下文的统一,那么在具体做法上有什么联系和不同呢?
我们将架构设计活动精简为以下三个层面:
-
业务架构——根据业务需求设计业务模块及其关系
-
系统架构——设计系统和子系统的模块
-
技术架构——决定采用的技术及框架
以上三种活动在实际开发中是有先后顺序的,但不一定孰先孰后。在我们解决常规套路问题时,我们会很自然地往熟悉的分层架构套(先确定系统架构),或者用PHP开发很快(先确定技术架构),在业务不复杂时,这样是合理的。
跳过业务架构设计出来的架构关注点不在业务响应上,可能就是个大泥球,在面临需求迭代或响应市场变化时就很痛苦。
DDD的核心诉求就是将业务架构映射到系统架构上,在响应业务变化调整业务架构时,也随之变化系统架构。而微服务追求业务层面的复用,设计出来的系统架构和业务一致;在技术架构上则系统模块之间充分解耦,可以自由地选择合适的技术架构,去中心化地治理技术和数据。
可以参见下图来更好地理解双方之间的协作关系:
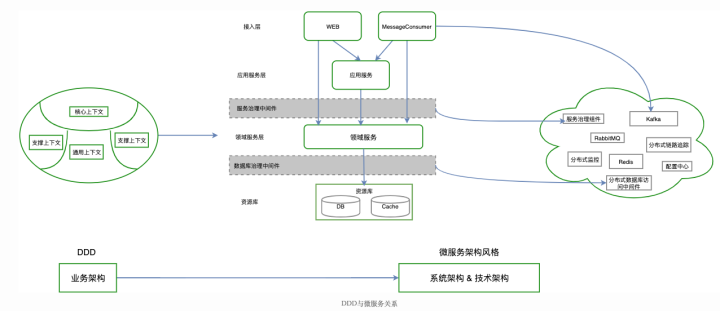
微服务与DDD建模协作
03
—
12306领域建模
我们将通过12306整个票务系统来详细介绍我们如何通过DDD来解构一个基于微服务架构的系统,从而做到系统的高内聚、低耦合。
业务场景分析
首先看下整个系统的大致需求:
-
铁路通过调度系统生成一系列列车车次票务库存;
-
旅客查询车票库存,购买相应的车票并付费;
-
票务库存扣减相关库存;
整个业务逻辑初一看还比较简单,像是一个简单的电商系统。别急着下结论我们由浅入深一点点分析, 首先我们来了解一些关于火车票的几个核心的业务知识:
领域知识
票库存:
票库存和电商业务里面说的商品SKU差不多,但解决电商的商品库存要简单得多,只需要销售时库存进行相应的扣减就可以。但火车票的库存是动态的,首先我们分析一下火车票的SKU 我们拿G20,杭州东到北京南:共经停5个站:杭州,湖州,南京,济南, 北京。
一般来说火车票分有商务座,一等座,二等座表面看起来这就是3个商品。 其实(4+3+2+1)*3 = 30个库存, 怎么来的呢?它的SKU计算方式应该是杭州到湖州, 杭州到南京,杭州到济南,杭州到北京分别是一个SKU,依次类推。更变态的是,你每卖出一张票,可能会影响其它SKU的库存。比如你买了杭州到北京的SKU一等座, 你不仅要减杭州到北京的库存,还要减杭州到湖州的,杭州到南京的,湖州到南京的等等依次减10个站到站的一等座库存。
车次及车次链:
一般我们叫类似G20, G19为车次。 一辆火车通常一天往返一次(有的也不会)当然大部分情况是去的时候一个车次,回来的时候又叫另一个车次。
当G20从杭州到北京要发车时,通常前一天会确定该车次的车底号(车厢一段时间需要返厂检修的)但车次还是需要每天跑。 这个时候其中的座位号有可能会变更,因为旅客坐车有旺季和淡季这个也有可能调整是8节车厢或者16节车厢。
了解这两个概念基本就差不多了,当然还有很多的其它领域的业务知识比如调图等,因为不涉及此次核心就不多讲了。
领域建模
了解业务知识之后,我们来进行建模。在设计领域模型的一般步骤如下:
-
根据需求划分出初步的领域和限界上下文,以及上下文之间的关系;
-
进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象;
-
对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根;
-
为聚合根设计仓储,并思考实体或值对象的创建方式;
-
在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构。
12306是一个典型特殊商品电商模型包含基本的商品域(票域)、订单域、支付域、用户域,再设计一个调度域。
火车票领域模型视图如下:
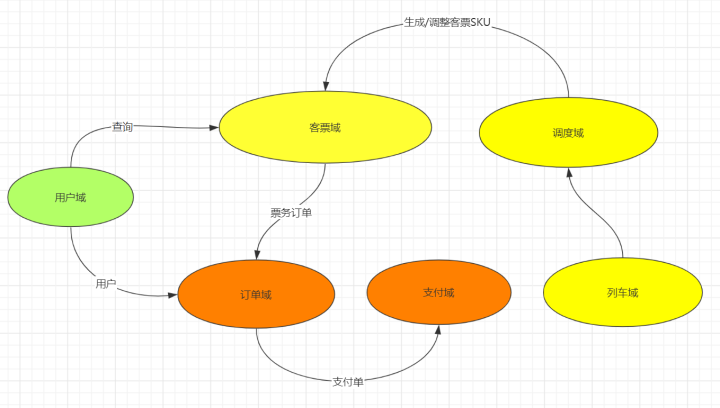
火车票业务流转模型
按上图领域流转视图,我们将各域进行分类如下:
通用域:用户域
支撑域:列车域
核心域:票务域,调度域,订单域,支付域
再细分一下各领域的模块组成:
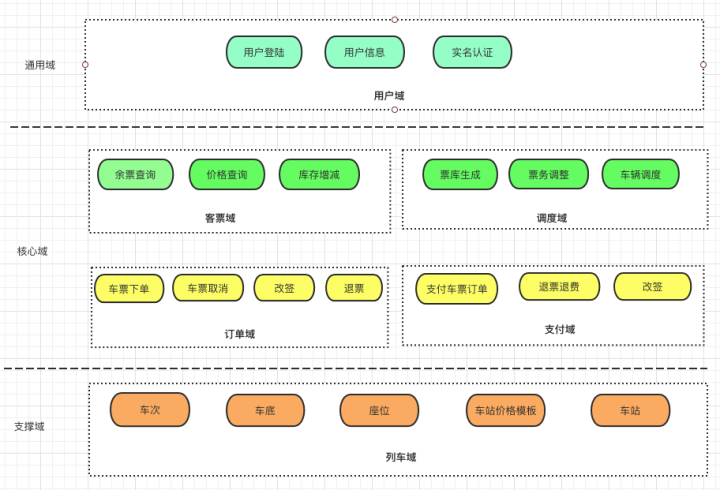
12306火车票各领域模型视图
模型定义好以后我们会有一个个的领域,领域包含上下文,我们来说一说上下文对系统及建模的意义。
领域上下文
战略和战术设计是站在DDD的角度进行划分。战略设计侧重于高层次、宏观上去划分和集成限界上下文,而战术设计则关注更具体使用建模工具来细化上下文。
现实世界中,领域包含了问题域和解系统。一般认为软件是对现实世界的部分模拟。在DDD中,解系统可以映射为一个个限界上下文,限界上下文就是软件对于问题域的一个特定的、有限的解决方案。
一个由显示边界限定的特定职责。领域模型便存在于这个边界之内。在边界内,每一个模型概念,包括它的属性和操作,都具有特殊的含义。
一个给定的业务领域会包含多个限界上下文,想与一个限界上下文沟通,则需要通过显示边界进行通信。系统通过确定的限界上下文来进行解耦,而每一个上下文内部紧密组织,职责明确,具有较高的内聚性。
划分限界上下文
我们的实践是,考虑产品所讲的通用语言,从中提取一些术语称之为概念对象,寻找对象之间的联系;或者从需求里提取一些动词,观察动词和对象之间的关系;我们将紧耦合的各自圈在一起,观察他们内在的联系,从而形成对应的界限上下文。形成之后,我们可以尝试用语言来描述下界限上下文的职责,看它是否清晰、准确、简洁和完整。简言之,限界上下文应该从需求出发,按领域划分。
限界上下文之间的映射关系
-
合作关系(Partnership):两个上下文紧密合作的关系,一荣俱荣,一损俱损。
-
共享内核(Shared Kernel):两个上下文依赖部分共享的模型。
-
客户方-供应方开发(Customer-Supplier Development):上下文之间有组织的上下游依赖。
-
遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。
-
防腐层(Anticorruption Layer):一个上下文通过一些适配和转换与另一个上下文交互。
-
开放主机服务(Open Host Service):定义一种协议来让其他上下文来对本上下文进行访问。
-
发布语言(Published Language):通常与OHS一起使用,用于定义开放主机的协议。
-
大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。
-
另谋他路(SeparateWay):两个完全没有任何联系的上下文。
05
—
总结
至此,火车票的核心模块基于宏观层面的建模就基本完成。 当然一个这么大的系统是需要一个架构师团队去搭建的。基于此模型,把各个域再分配到架构师手里里面做概要设计。
最后的话 “架构的本质是为了高内聚低耦合,紧靠本质,按自己的理解和团队情况来实践DDD即可”。