记录工作中和学习中的窗口函数,方便以后使用,本记持续更新和完善,版本:231019
文章目录
- 1.什么是窗口函数
- 2.窗口函数的表达式
- 3.窗口函数的类型
- 1) 排名函数
- 2) 聚合函数
- 3) 跨行取值函数
- 4.[frame]滑动窗口
- 1)窗口选择的两种模式:
- 2)滑动模式的两种表达式
1.什么是窗口函数
窗口函数,能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算, 最后将计算结果返回给该行 数据 。
使用场景:在一条数据中既想要展示明细,又想要体现一部分数据整体的效果,就可以使用窗口函数。这也是它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
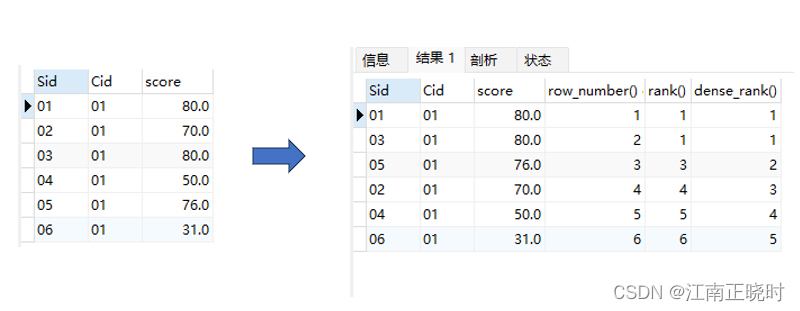
如下图式例:既想要展示sc表每个sid学生的成绩,又想要展示展示每个学生在整个年级的排名情况,rw即为窗口所展示的数据
SELECT *,row_number() over( ORDER BY score desc ) as rw FROM sc

2.窗口函数的表达式
function(args) over([partition by expression] [order by [asc|desc]] [frame])
表达式解析:
function:<窗口函数名>
over :”关键字 用于指定窗口的范围
(partition by: <用于分组的列名> order by <用于排序的列名>)
asc|desc:升序和降序,不写默认是升序
frame:计算行数的范围(详细请看下面第四点:[frame]滑动窗口)
3.窗口函数的类型
1) 排名函数
row_number()、 rank()、dense_rank()
| row_number() | 排序相同时不会重复,会根据顺序排序 即 1,2,3 |
|---|---|
| rank() | 排序相同时会重复,同一排名有几个,后面排名就会跳过几次,即 1,1,3 |
| dense_rank() | 排序相同时会重复,排名相同的名次一样,且后面名次不跳跃,即1,1,2 |
示例:
select *,
row_number() over(partition by cid order by score desc) rw,
rank() over(partition by cid order by score desc) rk,
dense_rank() over(partition by cid order by score desc) dense_rk
from sc
where cid = 01
2) 聚合函数
max()、 min()、sum()、avg()、count()
| max () | 最大值 |
|---|---|
| min () | 最小值 |
| sum () | 求和 |
| avg() | 求平均值 |
| count() | 计数 |
3) 跨行取值函数
lead()、lag()
语法:
| lead(expression,n) | 获取当前行的下边n行 、n个字段的值 |
|---|---|
| lag(expression,n) | 获取当前行的上边n行 、n个字段的值 |
expression:行数命
n:代表便宜量,想要偏移的行数
实例如下:
select * from active
select
uid,
dt,
lag(dt,1) over(PARTITION by uid ORDER BY dt) lg,
lead(dt,1) over(PARTITION by uid ORDER BY dt) ld
from active

使用范围:可以对数据进行同步和环比,针对
4.[frame]滑动窗口
function(args) over([partition by expression] [order by [asc|desc]] [frame])
1)窗口选择的两种模式:
| rows模式 | 按物理行进行划分 |
|---|---|
| range模式 | 按数据模式进行划分 |
2)滑动模式的两种表达式
{range|row}frame_start : 从自定行开始到当前行结束
{range|row}between frame_start and frame_end: 指定开始行和结束行
滑动行范围的常用表达式:
| 表达式 | 解析 |
|---|---|
| unbounded preceding | 从开始行 |
| expression preceding | 从当前行往前推 n 行 (expression 写为整数) |
| current row | 当前行 |
| expression following | 从当前行往后推n行 (expression 写为整数) |
| unbounded following | 到结束行 |
示例:通过改变row参数,改变窗口的大小
图一:
select * from sc
图二:窗口默认当前行之前的所有行
select
sid,
cid,
sum(score) over(partition by sid)
from sc
图三:使用row使窗口变成当前行的前一行到当前行,窗口只有两行,得出图三的效果
select
sid,
cid,
sum(score) over(partition by sid rows 1 preceding)
from sc


#当order by 后面缺少窗口从句条件,窗口规范默认是 从当前行到当前行以上的所有行
rows between unbounded preceding and current
#当order by 和 窗口从句条件都缺失,窗口范围默认 当前行上面所有行以及下面的所有行
rows between unbounded preceding and unbounded following