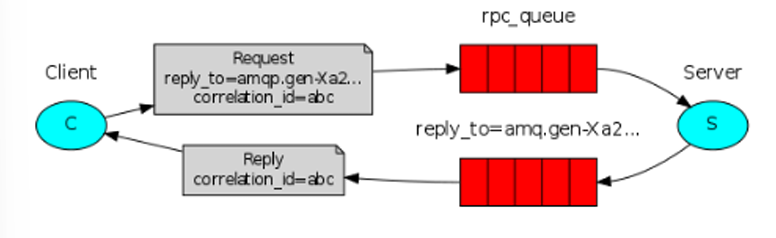
本章内容的大纲如下:
常见的字典方法
如何处理查找不到的键
标准库中 dict 类型的变种set 和 frozenset 类型
散列表的工作原理
散列表带来的潜在影响(什么样的数据类型可作为键、不可预知的
顺序,等等)
常见的映射方法
映射类型的方法其实很丰富。表 3-1 为我们展示了
dict、defaultdict 和 OrderedDict 的常见方法,后面两个数据类型
是 dict 的变种,位于 collections 模块内。
表3-1:dict、collections.defaultdict和
collections.OrderedDict这三种映射类型的方法列表(依然省略
了继承自object的常见方法);可选参数以[…]表示
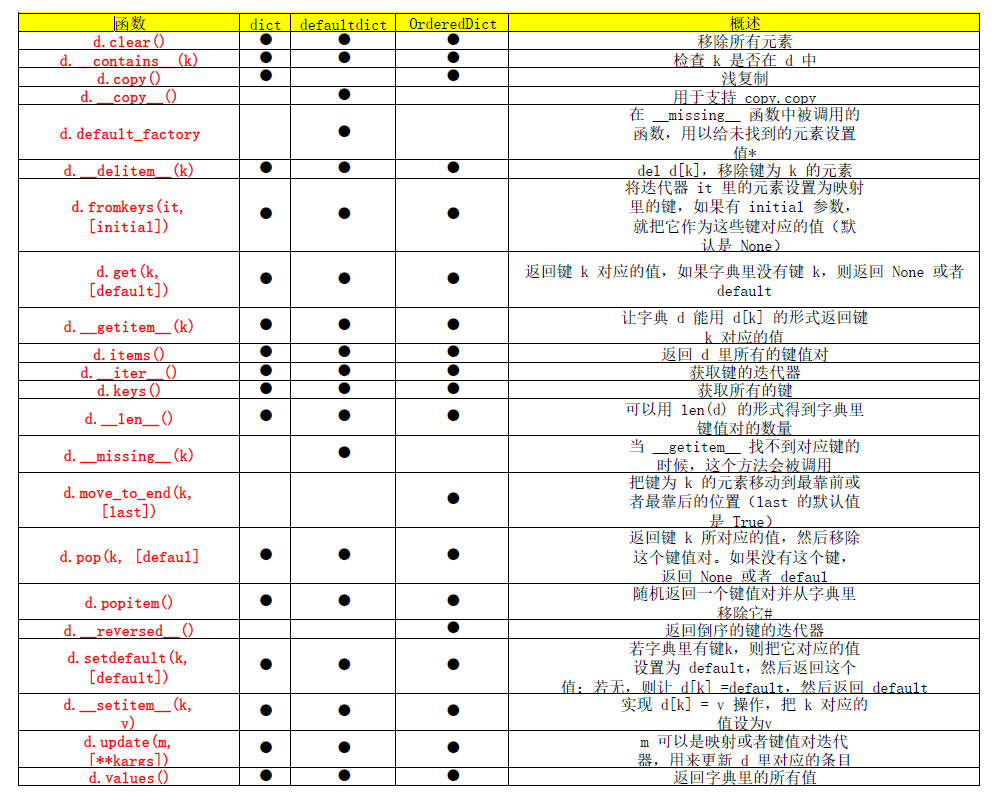
- default_factory 并不是一个方法,而是一个可调用对象(callable),它的值在
defaultdict 初始化的时候由用户设定。
#OrderedDict.popitem() 会移除字典里最先插入的元素(先进先出);同时这个方法还有一
个可选的 last 参数,若为真,则会移除最后插入的元素(后进先出)。
上面的表格中,update 方法处理参数 m 的方式,是典型的“鸭子类
型”。函数首先检查 m 是否有 keys 方法,如果有,那么 update 函数就
把它当作映射对象来处理。否则,函数会退一步,转而把 m 当作包含了
键值对 (key, value) 元素的迭代器。Python 里大多数映射类型的构造
方法都采用了类似的逻辑,因此你既可以用一个映射对象来新建一个映
射对象,也可以用包含 (key, value) 元素的可迭代对象来初始化一个
映射对象。
在映射对象的方法里,setdefault 可能是比较微妙的一个。我们虽然
并不会每次都用它,但是一旦它发挥作用,就可以节省不少次键查询,
从而让程序更高效。如果你对它还不熟悉,下面我会通过一个实例来讲
解它的用法。
用setdefault处理找不到的键
当字典 d[k] 不能找到正确的键的时候,Python 会抛出异常,这个行为
符合 Python 所信奉的“快速失败”哲学。也许每个 Python 程序员都知道
可以用 d.get(k, default) 来代替 d[k],给找不到的键一个默认的
返回值(这比处理 KeyError 要方便不少)。但是要更新某个键对应的值的时候,不管使用 getitem 还是 get 都会不自然,而且效率
低。就像示例 3-2 中的还没有经过优化的代码所显示的那
样,dict.get 并不是处理找不到的键的最好方法。
示例 3-2 是由 Alex Martelli 举的一个例子 变化而来,例子生成的索引
跟示例 3-3 显示的一样。
示例 3-2 index0.py 这段程序从索引中获取单词出现的频率信
息,并把它们写进对应的列表里(更好的解决方案在示例 3-4 中)
"""创建一个从单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
# 这其实是一种很不好的实现,这样写只是为了证明论点
occurrences = index.get(word, []) ➊
occurrences.append(location) ➋
index[word] = occurrences ➌
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper): ➍
print(word, index[word])
❶ 提取 word 出现的情况,如果还没有它的记录,返回 []。
❷ 把单词新出现的位置添加到列表的后面。
❸ 把新的列表放回字典中,这又牵扯到一次查询操作。
❹ sorted 函数的 key= 参数没有调用 str.uppper,而是把这个方法
的引用传递给 sorted 函数,这样在排序的时候,单词会被规范成统一
格式。
示例 3-3 这里是示例3-2 的不完全输出,每一行的列表都代表一
个单词的出现情况,列表中的元素是一对值,第一个值表示出现的
行,第二个表示出现的列
$ python3 index0.py ../../data/zen.txt
a [(19, 48), (20, 53)]
Although [(11, 1), (16, 1), (18, 1)]
ambiguity [(14, 16)]
and [(15, 23)]
are [(21, 12)]
aren [(10, 15)]
at [(16, 38)]
bad [(19, 50)]
be [(15, 14), (16, 27), (20, 50)]
beats [(11, 23)]
Beautiful [(3, 1)]
better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11),
(17, 8), (18, 25)]
...
示例 3-2 里处理单词出现情况的三行,通过 dict.setdefault 可以只
用一行解决。示例 3-4 更接近 Alex Martelli 自己举的例子。
示例 3-4 index.py 用一行就解决了获取和更新单词的出现情况列
表,当然跟示例 3-2 不一样的是,这里用到了 dict.setdefault
"""创建从一个单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index.setdefault(word, []).append(location) ➊
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper):
print(word, index[word])
➊ 获取单词的出现情况列表,如果单词不存在,把单词和一个空列表
放进映射,然后返回这个空列表,这样就能在不进行第二次查找的情况
下更新列表了。
也就是说,这样写:
my_dict.setdefault(key, []).append(new_value)
跟这样写:
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
二者的效果是一样的,只不过后者至少要进行两次键查询——如果键不
存在的话,就是三次,用 setdefault 只需要一次就可以完成整个操
作。
那么,在单纯地查找取值(而不是通过查找来插入新值)的时候,该怎
么处理找不到的键呢?