1 为什么研究者这么想把这个双流网络替换掉,想用3D 卷积神经网络来做?
大家好,上次我们讲完了上半部分,就是 2D 网络和一些双流网络以及。它们的。变体。今天我们就来讲一下下半部分,就是 3D 网络和 video Transformer 在视频理解领域里的应用。那上次其实我们也讲了很多工作了,他们的这个效果也都不错,而且用上这种光流以后听起来。也很合理。一个网络去学习这种图像特征,另外一个网络去学习这种运动特征,各司其职,互不打扰,最后结果也非常好。那为什么研究者这么想把这个双流网络替换掉,想用这个 3D 卷积神经网络来。做?其实主要原因就在这个光流抽取这一块。比如说大家之前常用的一种算光流的方法叫 TVL one,这种。算法。它如果我们使用一种 GPU 的实现的话,它只需要零点儿零六秒就能处理一个视频帧的一个。对,你乍一听可能觉得 0. 06 秒挺快的,但是如果你想一下这个视频数据集它有多大,你就会发现提前抽取这个光流是一个非常耗时的事情。那我们先拿一个比较小的数据集 UCF 101 来说的话,它就有1万个视频。那 UCF 101 它这个平均视频长度大概是 6 秒,如果我们按这个帧率 30 f p s 来算的话,那最后这个 UCF 101 数据集大概就有 180 万张这个视频帧。那如果我们把这个 180 万和这个 0. 06 秒去一乘,你就会发现如果你只有一个GPU,而且不做什么优化的话,你最后需要 1. 5 天的时间去抽取这个光流,那现在如果我们换到一个稍微大一点的数据集,就是大家常用的这个 K400 数据集,它里面有 24 万个视频,那这个时候 K400 的平均视频长度大概是 10 秒,如果我们还按这个帧率 30 IPS 来算的话,它最后就有 7200 万个视频帧。那这时候你再跟这个 0. 06 秒一乘了,你就会发现你如果你只有一个GPU,而且不做任何优化的话,最后你要抽 50 天。当然一般做视频也不可能只有一个GPU,而且因为这个 TVL one 算法它很省内存,所以一个 GPU 也可以同时跑好多个对,所以最后肯定是花不到 50 天的。但是对于一般实验室来说,抽个一两个礼拜还是很正常的。那这也就意味着每当你想尝试一个新的数据集,你都要先去抽取这个光流,然后才能做这种模型的开发。那在这抽光流的一两个礼拜时间里,你什么也干不了。就这个预处理实在是太耗时了,而且它也很占空间。即使是按照双流方法里那样把这个光流存成这个 PG 图片,那对于 UCF 101 数据集来说,大概也需要 20 多 g 的这个存储空间去存储。然后对于 K400 来说,大概是需要 500G 的存储空间去存储。那你有可能会想这个存储空间一点都不贵,很便宜,现在都是 4 个 t 8 个 t 的硬盘, 500G 根本不算什么。但是你还要考虑到这个运算的时候的IO,如果你的训练数据集这么大的话,那训练的时候是很容易卡 IO 的。而且抽取光流不光是说对训练有着一定的影响,它对这个推理也是有影响的,因为你不论用在哪个场景里,你都要先去抽取这个光流。那假设我们就用 TVL one 这种算法去抽光流的话,那它处理一个视频,对呢?大概是花 0. 06 秒,那你 1 / 0. 06,你换算过来,它的这个帧率就是 15 IPS,那这个 IPS 是低于这个实时要求的,因为实时的处理一般是需要 25 IPS 或者30。FPS。那这也就意味着你什么模型都没用,你光抽光流你就已经不是实时了。那你再加上模型,那就肯定更不是事实了。但可惜视频理解一般的应用很多都是需要实时处理的,所以说其实后面的很多工作都是针对这些缺点去攻击这些基于光流的方法,比如说双流网络,就尽量想避开使用双流网络,如果我能直接从视频里进行学习,那该多好。
所以这也就有了从 2017 年到现在这个 3D 卷积神经网络的。火热。因为 3D 卷积神经网络它按道理来说,你就是想去学习一个这个时空特征,就它既有这个special,又有这个 Tempo 上的信息,它是一起学习的,所以你没有必要单独的再去对这个运动信息或者时序信息进行单独建模了,也就意味着你不需要这种光流了。但事实上我们回头也可以看到,因为这个 3D 网络越做越大,或就说这个 video Transformer 也越做越大,所以说其实这个效率上的问题并没有得到解决,大部分模型也都不是。事实的。而且如果你给这些 3D 网络,或者给这些 video Transformer 去加上这种光流输入的话,其实它们都还能继续提高性能,也就意味着光流这个东西其实还是很好的。一个特征。
2 C3D 给你一个更好的特征,用于下游任务
那我们直接进入正文,今天要说的第一篇论文就是 ICC V15 的这篇 C3D 网络,题目就是用 3D 卷积神经网络去学习这种时空上的特征。作者团队来自 fair 和达特茅斯,但其实 Loranzo 后面也已经去了fair,所以说其实就都是 fair 的工作。我们从摘要的第一句话其实就可以看出来这篇文章的主要贡献是什么,其实作者已经说了,他们就是提出了一个简单但是有效的方法,去学习视频中的这种时空特征,用什么工具就是用一个简单的这个 3D 卷积神经网络就可以了,但他们的贡献主要就是用了一个更深的 3D 卷积神经网络,而且是在一个特别大的这个数据集上去进行训练。而这个数据集就是我们上回讲的 DIFF video 那篇论文里提出来的 Sports one million,就是有 100 万个视频的那个数据集。
2.1 效果不错
然后作者其实在这个引言部分也已经提到了,就是他们并不是第一个用这个 3D 卷积神经网络来做视频理解的,其实之前这个 15 和 18 这两个工作也都是用 3D 卷积神经网络来做的,没有什么区别,最主要的区别就是 C3D 这篇论文,就是他们这篇论文是在用了大规模的这个数据集去训练模型,而且用了这种现代的这种深度学习,其实就是更深的网络,从而能在一系列的任务上得到了非常好的结果。所以站在我们现在的角度再去回看这篇论文的话,它的想法上还是很简单的,所以我们直接来看这个效果和这个模型。总览图。
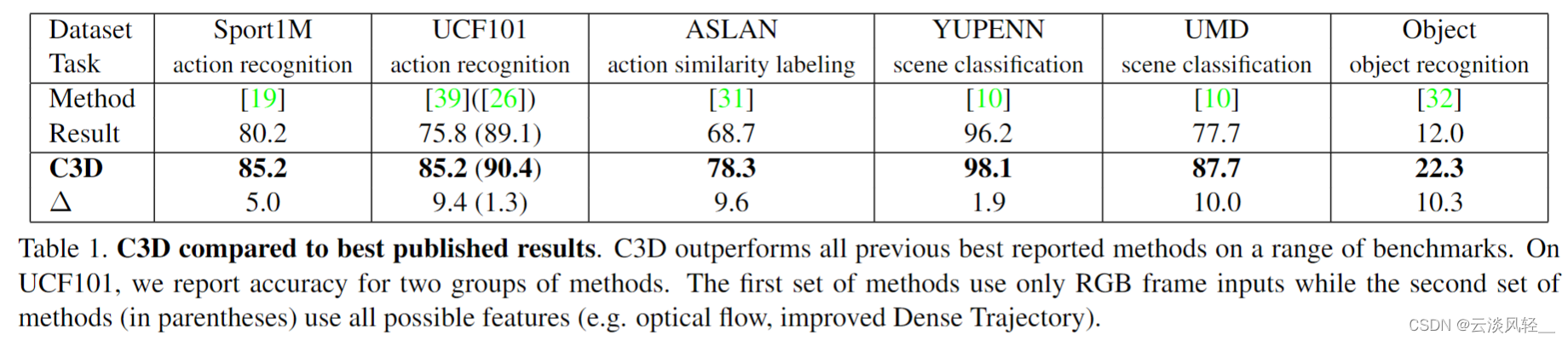
那首先作者把他们的这个最后结果放到这个表一里,直接就放到这个论文的第二页,因为这算是他们论文的一个卖点,就是说在这四个数据集上他们都取得了最好的这个结果。然后在这两个数据集上他们也取得了不错,就是competitive。的结果。
2.2 模型结构

那接下来我们直接看模型的结构,在这里作者其实是用一个简略图框画出来的,而不是一个特别fancy,特别好看的一张图。那大体的这个网络结构就是你有这个 count 1PU1,然后 count 2PU2, count 3A3B PU 3,还有 COUNT 4A4B 扑4, COUNT 5A5B 扑5,然后最后还有两层FC,最后还有一个分类层 FC 8。所以说整体来看这个网络结构是有 11 层的。至于所有这个 3D 卷积层里的这个卷积核是怎么构造,作者这里也说了,其实就是把所有的这种 3 * 3 的卷积核都变成了这个 3 * 3 * 3。那其实我们看到这儿你就会发现,唉,这个网络怎么跟 VGG 这么像呢?那其实说白了它其实就是一个 3D 版本的 VGG 网络。那如果我们回顾一下 VGG 16 那个网络的话,其实在 count 一这块,它是有两层count,然后一层pulling,然后又有两层comb,一层。pulling。然后从第 345 这三个 block 来说,它是三个 comb 加一个pulling,三个 column 加一个pulling。所以说相当于 C3D 网络,就是把 VGG 网络每一个 block 里面都减少了一层conv,然后把所有的 CONv kernel 都从 3 * 3 变成 3 * 3 * 3 了,所有的改动其实就是这些。所以这也就是为什么作者说他们的这个方法设计非常简单而且。直观。是因为确实很简单,也没有像 Inception net 那种 Multipass 就是多路径的那种结构,而且当时也还没有Resnet,所以说也没有残差连接,所以就是简简单单的这种卷积操作的堆叠。就是。convpulling。
2.3 前向过程
那现在我们给定一个输入,然后走一遍这个模型的前向过程,就能更好地理解这个模型是怎么运作的了。那在这篇论文里,它的输入是 16 * 112 * 112,就说明有 16 个视频帧,也就是时序上你的这个维度。是16。然后你的这个空间上是 112 * 112,之所以没有用这个 224 * 224,是因为这个 GPU 内存塞不下。作者后来也实验了一下,发现 12 乘 12 其实效果也一样,因为一般对于分类任务来说,其实这个图片大小不是那么的重要,所以这个 3D 网络的输入就是 16 * 12 * 12 了。
然后过完一层 CONV 和 pooling 之后,因为第一层的这个pooling,他们这里写的是 1 * 2 * 2,就是在这个时序上它不做这个下。采样。因为想尽可能的多的再保留一下时序上的这个信息,那所以说这个时序上 16 还是16,但是这个空间上就降了一半,就变成 56 * 56 了。
然后再做一层 count pulling,那接下来所有这个 pulling 操作也都是 2 * 2 * 2 了,所以说不仅是时间上从 16 变成8,空间上进一步降低变成 28 * 28,
然后再过了第三层这个 count 之后就变成 4 * 14 * 14,然后过了第四层 count 之后就变成 2 * 7 * 7,然后在过了第五层 count 和 pulling 之后,最后在 FC 这一层这个特征维度就变成一个 1 * 4696,就变成一个一维的一个向量了,也就是我们最后抽取的这个特征。当然了 FC 7 也是 4096 乘4096,然后最后一层 FC 8 分类层就是 4096 乘101,就是101。类了。
但是在这篇论文里,作者当时发现这个 fine tuning 这个网络其实最后的结果也不是很好,而且又费时费力。对,其实作者每次都是抽取特征,他最后选择了就是从 FC 6 这层去抽取这个 4096 的。特征。拿出来,然后再去训练一个 SVM 的这个分类器,去做这个分类任务,又快效果又好。那其实这篇文章的名字C3D,其实更多时候指代的就是这个 C3D 特征,也就是 FC 6 抽出来的这个特征叫 C3D 特征,那模型上其实就是这些能讲的并不是很多,
2.4结果

那接下来我们就直接看结果,首先在这个表 2 里,作者就表展示了一下在这个 Sports one meaning 这个数据集上的结果。那前两行这个就是 deep video CVPR 14 的那篇论文,也是第一次提出 Sports one million 这个数据。集的。我们可以看出来 C3D 这个工作如果也是在 Sports one million 这个数据集上去从头训练的话,它的这个效果大概是446084,所以比原来对应的这个版本这一行还是要高一些的,所以说证明了 C3D 这个网络的有效性。那如果把这个 C3D 网络在更大的数据集上去做预训练,也就是他这里说这个 S380K 其实是 Facebook 自己一个从来没有 release 过的一个 Instagram 的视频。数据集。在这个上面去做这个预训练之后,他发现这个效果就更好了,这也就是这篇作者在这个摘要里还有在引言里反复强调了,就是他们认为这种 3D 的直接学习时工特征的方法是比使用 2D 网络要好的。因为这个 deep video 这个方法其实还是可以看作成是一个。2D。网络,它里面虽然有一些这个什么二 diffusion 或者 slow fusion,但是终归而言它还是用这个 2D 网络去抽特征,只不过是在后面做了一下这个合并,那这个 C3D 才是真真正正从头到尾都是一个 3D 卷积神经网络,从头到尾都是在做这种时空学习。所以作者就得出了说这个 3D 网络要比 2D 网络要更优,或者说更适合这个视频理解这个任务。
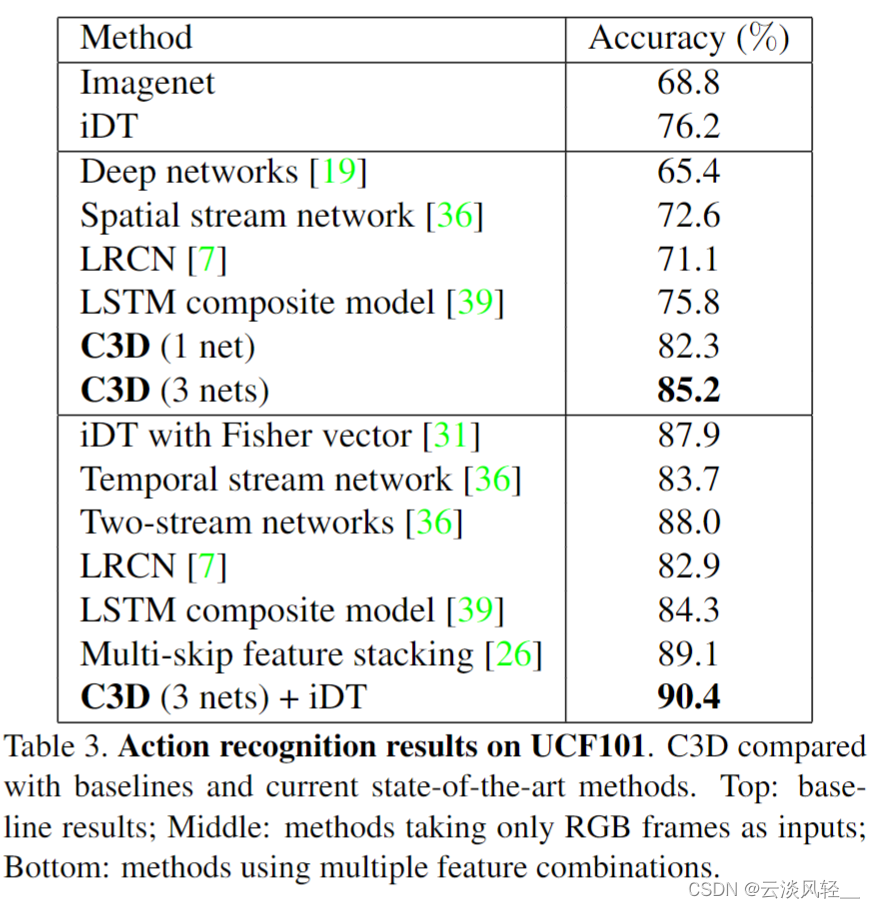
那接下来我们看一下这个表3,也就是在 UCF 101 这个数据集上, C3D 的表现到底如何?我们这里也可以看出来,就是 C3D 这个网络,其实如果你只用一个网络的话,它的结果只有八十二三。如果你训练了三个网络,把它们这个 assemble 起来,它最后的这些结果才有 85. 2。这么高。但其实85。 2 这个效果是远低于同期其他工作的。我们之前说过这个,之前最好的手工特征都有88,双流网络也有88,然后用 LCM 网络的也有 84 或者 88 这么高,而且其实比它更早就是 CVP R15 发出来的一篇论文,就王立斌老师在 TDD 每篇论文其实已经在 UCF 上有 91. 5 的这个。结果了。是比它这里的90。 4 还要高的。
2.5整体上来看,其实 C3D 的这个效果并不突出,那 C3D 为什么会这么火?他的接受度又这么高?
所以说整体上来看,其实 C3D 的这个效果并不突出,那 C3D 为什么会这么火?他的接受度又这么高?其实我认为是作者抓住了。一个机会。他没有把这篇文章的卖点放到这个网络训练上,而是把这个文章的卖点放在了这个抽特征上,而且它还给出了对应的这个 Python 和 MATLAB 的实现,这个在当时 15 年的时候是非常关键的。那这个时候 C3D 的作者其实他也发现了,因为当时开会的时候跟他聊过,他训练这个 C3D 网络当时花了一个月,也就以 Facebook 这个算力,他训练这么一个视频模型都要花一个月的时间,那对于大多数人来说肯定是训练不动了,所以他知道的如果大家想在这个视频理解或者在对应的其他领域里去用这种视频的特征或者视频模型的话, fine tuning 这个模型在当时不是一个好的选择,抽特征才是最好的选择。所以说作者就提供了一个Python,还有一个 MATLAB 的接口,也就说你只要给我一个视频输入,你也可以用 Opencv 读进来,MATLAB, Python 都可以。然后我就返还给你一个 1 * 4696 的特征,中间的细节你通通都不用管,你就拿这个特征去做你其他的下游任务就可以了。所以很快其他任务纷纷都用起 C3D 这个特征了,比如说 video detection 或者 video captioning,都可以直接抽取一个特征,然后就去做它的下游任务。这个其实跟现在我们大家用 Transformer 也是一个套路,因为 Transformer 训起来太贵了,很多人也训练不动,微调都训练不动。所以说大家在做多模态的时候,往往是把这个 transformer 去抽一个特征,然后抽完特征以后在特征上再去做这种特征的融合,或者做这种多模态的学习,这个训练起来的代价就小很多了。
所以说从这个角度上来看,做研究也不光要成天去考虑这种新意度的问题,更主要的是要考虑一下你这个东西到底有没有用,如果你做出来的这个东西真的能够推动整个领域的进步,那其实才是真的好的,真的有用的研究工作。
总之 C3D 这篇论文它的意义还是非常巨大,它不光是通过这种抽特征的方式,让更多的研究者能够把深度学习时代更好的这个视频理解的特征用作其他的下游任务,同时它还系统性地研究了这种 3D 卷积神经网络以及如何使用到这个视频理解的任务上来,从而为后续的这一系列的这个 3D 工作做了一个铺垫。
3 I3D降低了网络训练的难度,提出了一个很好很大的数据集,效果很好
那接下来就不得不提一下 I3D 这篇论文的意义就是降低了网络训练的难度,提出了一个很好很大的数据集,而且它在标准这些 Benchmark 上的结果都比之前 2D 或者双流的方法要好,从而奠定了 3D 网络的这个地位。我们也可以看出来,这个 C3D 是发表在 SCV 15 上的,而这个 I3D 是发表在 CVPR 17 上,这中间将近过了两年的时间,所以说明这个 3D 网络的一个调试和这个模型的迭代还是非常。困难的。这也就更进一步地体现出了 I3D 这片网络的意义。如何能通过这种 Boost drapping 的形式降低网络训练的难度,那鉴于之前我们已经精读过 S3D 这。篇论文了,对,这里我就快速的过一下。
那其实 I3D 这篇论文最大的亮点其实就是在这个字母 i 上,也就是这里这个。inflated。扩充的膨胀的一个 3D 网络。那之所以作者想到这么做,其实主要是看到 C3D 这个网络在这么大的数据集上去做过预训练之后的效果不太行,所以 I3D 的作者就坚信就是我们这里一定要有一个类似于 Imagenet 这样一个预训练的模型,我们要有一个好的。初始化。从而接下来这个训练变得更简单。那之前 image net 预训练的模型全都是。2D 的。那你现在如果是一个 3D 网络,那怎么把一个 2D 变成 3D 呢?这也就是这里的膨胀的意思,它就是要把一个 2D 的网络扩充成一个 3D 的网络,而这个网络整体的结构是并不改变。那在这里我们用这个图 3 做个leads,它这里也就是把一个 2D 的一个 inception 网络给扩充成了一个 3D 的I3D。网络。那对于一个 2D 的 exception V1 网络来说,其实这里也就是看我pulling,然后接下来都是这种 inception module,也就意味着说这个 2D 的 inception 和这个 3D 的inception,它这个网络结构没有改变,那只是这里的这些卷积核从 3 * 3 变成了 3 * 3 * 3,或者刚开始这 7 * 7 变成 7 * 7 * 7,然后像这个 pulling layer,那刚开始有 1 * 3 * 3,后面有 3 * 3 * 3,然后最后还有2 *。2 *2。就是都是由 2D 变成了3D。那这样一个好处就是说因为你 2D 网络和 3D 网络共享了一个同样的一个 Meta 结构,就是总体架构一样,那这样你就能想到一种比较简单的方式,那么把 2D 预训练好的参数移植到 3D 的模型上来,那这个对于 C3D 网络它就做不到。 C3D 网络虽然我们之前说过它有点像 VGG 十六,基本上就是按 VGG 那个网络的这个设计理念来设计的,但是因为它每一个 block 里面都少了一层卷积页,所以导致它没法很简单的把这个 VGG 的 2D 网络参数移植到这个它的 3D C 3D 网络中来,这也就导致了他们没法使用这种 image net 预训练的参数,从而导致了他们很难优化,很难得到一个更好的结果。所以说 SND 这篇论文最大的亮点就是这个 inflation 这个操作,不仅不用设计一个网络,直接把一个 2D 网络扩充成 3D 就可以了,而且还能利用 2D 网络预训练好的模型参数,从而简化这个。训练过程。最后也能利用更少的训练时间达到。更好的效果。
那如果我们快速看一下 I3D 网络在 UCF 101 和 h m d b 51 这两个数据集上的结果,我们就可以发现它的这个结果是远远比之前的方法都要高的。那如果我们就拿 3D 网络之间做对比,我们可以看到这个 RGB I3 d 的这个结果就比对应的这个 C3D 用 RGB 的结果高了大概是三个点,所以说这个提升是相当显著的。而且 s and d 这篇论文还有另外几个意义所在,第一个意义就是它还是做了这种 RGB SND 和 flow SND,就是即使它是一个 3D 网络,它还是。用了光流。这就我们之前说的,即使你是一个 3D 网络,你用了光流之后的你的这个效果还是会很好,所以光流不是没用,只是计算代价。太高而已。
那第二个意义就是说 S3D 网络通过简单的这种膨胀过钟的这个操作,能大幅提高这个实验结果,从而把这个 UCF 101 和 HMDB 51 这两个数据集基本上都刷爆了。所以在这之后,大家基本也就不用这两个数据集,转而去用他们提出的新的这个K400。数据集了。它相当于是以一己之力把整个这个视频理解领域从双流变成了 3D 网络,而且把这个做测试的数据集也从 U4F101 变成了 K400 数据集。
I3D 论文带来的第三个影响就是说它证明了从这个 2D 网络迁移到 3D 网络的这种有效性。所以在 I3D 网络把 2D 的 Inception net 转成 3D 的 inception net 之后,很快就有其他的工作就跟进了。那比如说在 CVPR 18 的时候,大家就把这个 Resnet 就全都变成这个Resnet。3D 了。然后 ECCV 18 的时候就一篇论文把 Resnet 的思想应用过来,变成了叫 multifiber network,也就是。MF net。然后来大家又把 2D 的这个 SE net 里这种 channel attention 的思想借鉴了过来,然后变成了 CPR 19 的一篇 STC net 的文章,所以说是非常里程碑式的。一个工作。
那说完了 C3D 和I3D,那基本上 3D 网络的这个基本结构就定好了,接下来就是做各种各样的改进了。那对于视频问题来说,大家更关心的肯定是时序上该怎么去建模,或者说我怎么能处理好更长的这个时间序列呢?
4 Nonlocal Neural Networks
那对于之前的这个传统方法,或者对于 2D 网络双流方法来说,大家就是在后面加一个LSTM。就行了。
那 3D 这边当然也可以在后面加一个LSTM。没问题。但是在 3D 网络火起来的同时,在 NLP 领域发生了一件巨大的事情,那就是 Transformer 这个模型出来了,也就是说 self attention 自助力这个操作被提出来了,而且效果。特别的好。那自助力操作我们也知道它本身就是用来学习这种远距离。信息的。正好跟这个 LSTM 的作用不谋而合。所以说 non local 的作者可能就想了一下,那我为什么不把这个 self attention 拿来替代一下LSTM,看看这个自助力在视觉里到底应用的好不好,结果证明把自主寓意用到视觉领域,效果还是非常不错的。所以说在 snow local 这篇论文出来之后,很快视觉的别的一些下游任务,比如说检测和分割,全都是把 non local 这个算子应用到别的这个网络之中了。尤其是对于分割而言, 2019 年简直都卷疯了。不知道有多少论文把这个自助力尝试加到分割各种不同的这个网络结构里,然后做各种不同的变体,或者说加速或者说提点,总之是。五花八门。然后再后面就有了 vision consumer,然后又有了Transformer,现在在 CV 这个领域里大杀死崩,总体而言就是自助力这个操作真的有效,那在摘要里作者就说无论是这个卷积操作还是递归的这种操作,它每次处理都是在一个很局部的区域里进行处理的,那如果我们能看到更长或者更多的这个上下文,肯定是对各种任务都会有帮助的。所以在这篇论文里,作者就提出来了一个不是局部操作,也就这里说到 non local 的一个算子,它是一个可以泛化的,而且可以即插即用的一个 building block,就是一个模块,而这个模块的作用就是用来建模这种长距离的信息的。然后作者接下来说他们是受到这个 CV 里的,之前有一个方法叫做 non local means 的方法,所以才想到用这个 non local 这个算子去做这种长距离建模的,然后作者最后就说,因为这个模块是一个即插即用的模块,所以我可以把它运用到各种任务里去。首先我们在视频这边就取得了不错的效果,其次我们还在这个检测分割,还有这个姿态检测,全都取得了。很好的效果。这也可以说是凯明或者说菲尔这个工作一系列的这风格就是实验非常的详尽,每次基本上就是把能做的任务全都给你。做了个遍。让审稿人无话可说。那具体这篇论文提出的这个 non local block 到底长什么样?其实它就画在这个。图 2 里。而且它这个图 2 里画的是一个 space time 的 NON logo block 就是一个时空的算子,也就是用来做视频理解的,但是我们先不管它是做 3D 的还是做 2D 的,如果我们只看这个结构,其实我们一眼就发现它就是一个自助意义操作,先是一个特征进来,然后通过这个KQV,对吧?key, query 和 value network 得到三个特征,那这三个特征全都是由自己变来的,然后 key 和 query 去做一下这个 tension 操作,就得到了一个自助力,然后再拿这个自助力去和这个 value 做这个加权。平均。然后得到最后的这个值,之后再有一个这个残差连接,最后得到最后的输出。所以说完全就是一个标准的自助力的模块,这里只不过是为了适配这个视频理解,所以把这个 2D 的操作全都变成了3D。那鉴于我们这个论文精读系列之前已经讲过Transformer,而且也讲过 vision Transformer,所以对自助力大家应该都不陌生,那这里我就不再过多复述了。那我们先来看一些消重实验,其实这个消重实验很重要,因为这也体现了作者是怎么一步一步设计出来这个网络结构的。比如首先第一步就是这个自助力该怎么算,那作者就在这个表 a 里就列出了几种方式,比如说到底是用高兴还是用 dot product,还是直接 concat 一下,那最后发现用 dog product 这个效果是。最好的。但其实 Transformer 默认的也就是。dot product。接下来确认使用 dot product 来做这个自助力之后,那接下来一个问题就是说我们怎么把这个 non local block 插入到这个已有的这个网络结构之中?那像之前作者在摘要里已经说了,因为这是一个 Plug and play 的,就是即插即用的一个网络结构,所以你插在哪儿都可以。那作者这里先做了简单的尝试,就是我先加一层这个 non local block,我先试一试把它加到哪最好,它就在每一个这个 residual block 后面,因为对于一个 Resnet 来说,它有四个block,Resso、2345、四个block,它就尝试要么在这个 2 后面加一个,要么就在 3 后面加一个,看看到底加在哪一个 block 上这个效果最好。然后作者就发现加在这个 234 上这个效果不错,加在 5 上这个效果不太行,作者觉得这个加在 5 上不行的原因是因为 5 的这个特征图太小了,它已经没有多少这个空间信息在里面了,所以也没有什么远距离的特征,你可以学那这个 non local 的这个操作就起不到它应有的作用。然后又因为刚才说的这个自制力操作比较贵,所以作者也不想在这个 rise 2 就是特别早的腾出的时候去做这个 non local 操作,所以作者最后就决定就在这个 rise 3 和 rise 4 上去做这个 non local。的操作。那接下来又有新的问题了,那之前你是给整个网络里就加了一个 non local block,那这个 non local block 肯定是加得越多越好,因为就相当于你在每一层你都去做这种远距离的建模,所以作者这里的问题就是说我到底加多少?好,所以他就试了一下加一个block、加 5 个 block 和加 10 个block,那这里十个 block 的意思其实就是说在 rise 3 和 rise 4 这两个阶段之中,所有的这个卷积后面都加了一个 non local block。因为我们也知道这个 rise 50 这个网络,它的这个层数分别是3463,所以中间这个 rest 3 和 rise 4 对应的是 4 和6,所以它一共就有 10 个卷积。层。所以也就是说对应的这 10 个卷积层后面都有一个 non local,那最后就是有 10 个 non local block,那这个五个 non local block 那就是隔一个来的,所以说就刚好。是五个。那对于 rise 101 来说,虽然它后面两层的这个层数更多,但它就是隔得多一点,那它还是五个 block 和。10 个block。那作者就发现确实是更多的。这个脑 local block 带来的效果提升更多,也就意味着说自助力这个操作真的是有用,尤其是在这个视频里面,这个长距离的建模是更有帮助的。那接下来这个消融实验主要是为了证明作者新提出的这个 space time nonlocal 到底有没有用,因为有的人可能会质疑这个 self attention 本来提出就是在这个特征图上去做的,有可能只在 special 上做这个 self attention 就可以了,你没有必要做这种 space time 上的这个 self attention,那所以作者这里就把它拆分开来了,就是如果我在光在空间上去做自助力会怎么样?如果光在时间上去做自助力怎么样?那或者我在这个时空上去做自助力又会怎么样?然后作者就会发现时间和空间上作者自助力一样重要,有的时候甚至在时间上做这种自助力比在空间上做更有效。如果你在两个上面都做,就是这个 space time 上都做,它的结果是最好的,所以就证明了这篇论文提出的这个时空自助力才是对视频理解更有效的方法。那最后我想大概提一下的表格,其实也就是这里的表格 g 了,也就是利用更长的这个视频输入会怎么样?因为它这篇论文从头到尾讲的就是说,如果我能有更长的上下文,效果会不会更好,那如果你这个 non local 的目的就是为了抓住更长的上下文之间的。信息。那如果你的输入只有 16 帧或者 32 帧,那也就是 1 秒的话,其实也不长,你也没什么长距离的信息可以抓住的。所以作者这里就说,我一定得找一个更长的这个时间序列输入,来证明一下脑 logo 到底有没有用。而事实上对于这个 128 帧的一个输入也就大概 4 秒多,那 NON local 这个方法还是能够持续地提高这个波形的性能,而且提升还是非常显著的,也从侧面说明了 NON local 是对这种长距离的这种时序建模更有好处的。那说完了消重实验,最后我们就来看一下结果,那因为这个时候已经是 s and d 之后了,所以说大家主要的结果都是在 K400 这个数据集上去做比较,那我们可以看到这里这个表 3 其实非常的小,总共对比的方法也就只有S3D,就是7,还有之前的另外一篇论文。3。为什么呢?因为之前讲过的那么多方法, 2D 的或者说双流网络的方法,他们的结果全都是在 UCF 101 和 HMDB 51 上做的,他们都没有 K400 上的这个分,所以作者也没法比,总不能把之前所有的方法全都复现一遍吧,所以说这里能比的也就只有这两种方法了。那我们这里可以看到,如果拿这个 non local 的 SMD 去跟这个 SMD 去做对比的话,它有两个区别,一个就是它把这个 backbone 给换了,是把 exceptionate 换成了这个Resnet,这个改变大概带来了一个点的提升,然后加上 non local 之后又带来了两三个点。的提升。对,最后从 72. 1 到 76. 5,大概就有四个多点的提升,也是非常显著的。而且我们可以看到用上 non local 之后,它的这个结果甚至比之前这个双流 SMD 的结果还要好一点。这其实也就给做 3D 网络的人了信心,就说我不用光流,我照样效果能很好。然后 non local network 如果换成了 rust 101,当这个 backbone 它的最后结果就有 77. 7 这么高,已经是非常的高了。我们可以看到比之前这个 3 里面的方法,它不仅用了 Inception Resnet, VR 就一个更好更强的结构,而且还用了三个模态,就是说 RGB 图像、 flow 图像和这个音频。信息。那全都用了的情况下,也就是77。7。所以说明 non local 这个操作真的非常。有效。那这篇论文的贡献就是把这个自助力操作引入到了视觉领域,而且针对这个视频理解的任务,它还把这个 space 自助力操作变成了 space time,就时空上的这个自助。力操作。而把这个视频理解上几个任务的分都刷得很高,也证明了它的有效性。那在这篇论文之后,就更少有人去使用 LSTM 了,因为在 NRP 那边,大家也是使用 Transformer 而不是使用。LSTM 了。那在 CV 这边,自从有了 non local 算子,大家也不用 LSTM 了,那作者的愿望其实也实现了。作者最后说他们希望这个 non local 这个层能够成为一个重要的这个神经网络的组成部分,之后的这个网络结构都能用到它。那确实,不管是在之后的这个网络设计上,还是在这个下游任务上,那 non local 这个算子是有巨大的影响力的。那说完了 non local 这篇论文,那接下来我们讲一篇同期的,也是 C v P R E 8 的另外一篇论文,就是 r 加ED。论文的题目就是说对于这个动作识别来说,他们做了一个详尽的调查,那调查的是什么呢?就是这种时空的卷积到底该怎么做好?到底用 2D 还是用3D,还是 2D 加3D,还是怎么串联一下,或者并联一下?总之是一篇非常实验性的论文。那作者在摘要里其实也说了他们这篇论文的研究动机是什么,就是说他们发现如果就用这种 2D 的这个网络,然后在视频上这个一帧一帧去抽特征,或者说一帧一帧这么做,结果也很好,至少是在这个视频动作识别领域里来说,他们的这个结果还是表现得相当不错的,并没有比 3D 网络低多少。那这篇论文的作者就想,那既然 2D 网络表现也真不好,那如果能用一下 2D 或者部分用一下这个 2D 卷积,其实也是不错的,毕竟 2D 卷积比 3D 卷积便宜太多了,所以这篇文章整个就是在测试各种各样的结构。一会我们在这个图里也可以看到,到底是先 2D 在 3D 还是先 3D 在2D,还是说把这个 3D 拆分成 1D 加2D。的结构。那最后作者发现把这个 3D 卷积拆分成这个空间上的 2D 和这个时间上的1D,最后能得到更好的效果,而且这个训练也简单了很多,然后在得到了一个更优的结构之后,他们在很多数据集上都取得了很好的结果。那包括比较大的这个 Sports one million 和K400,以及之前的小一些的这个 UCF 101 和HMDB。五幺。那具体来说作者就是在这几个方式上去做了这个消融实验,看看到底哪种组合最好?那首先第一种就是纯 2D 的网络R2D,那他的意思就是视频中的每一帧,这么过去抽特帧或者做训练,完全是一个 2D 网络。那对于第二种这个 MCX 方法来说,这个头重脚轻的方法就是说我先有一个视频 clip 进来,然后我通过这个 3D 卷积去做,先在这个底层上学一学这个时空特征,然后到上层我换成这个 2D 的,然后把这个计算复杂度降一下,但因为 2D 比较便宜,所以我说它是头重脚轻。那很显然那第三种结构这个 r m c x 来说,那就肯定就是说头轻脚重了。那就是说我先刚开始的时候把一个视频 clip 拆分成每一帧,然后我一帧一帧输入这个 2D count,然后在得到这些 2D count 出来的特征之后,我再用这个 3D 看 5 去做一些这个融合,最后出这个结果。那第四种当然就是说全部都是都使用 3D 网络了,那这也就是C3D、 S3D 这一系列的网络做法,包括 C a P R E 8 的时候,还有一篇叫 RR 3 d 的网络,就是纯粹使用 Resnet 的一个。3D 版本。那最后这个 e 这个 RR 加 ED 结构,就是这篇论文提出的。结构。也就是说他把这个 3D 卷积拆分成了两个。卷积。就是先做一个 2D 上的 special 上的卷积,然后再做一个 1D 的这个时间上的这个卷积,那作者发现其实他们的这种效果是。最好的。那接下来我们就具体来看一下这个结果,看看到底哪一个设置会更好。那首先我们看一下这个参数量,从参数量上来看,那如果纯用 2D 的这个网络肯定是更便宜的,所以我们可以看到它的这个参数量都明显小。很多。但是其他用了 3D 网络的明显这个参数量就上去了。第二个就是我们从这个实验结果上来看,那实验结果上明显如果只用 2D 网络的这个结果是。最差的。那纯用 3D 网络的结果也不咋样,反而是这种 2D3D 混合用的结果还不错,如果是头重脚轻就有 50 多,头轻脚重也有将近 50 的效果,都比前面单纯使用 2D 或者 3D 的效果要好一些。那最后就是这篇论文提出的 r 加ED,就是这种拆分结构的形式,它的参数量是目的是为了和之前的这个 3D 网络保持一致,但是效果好了非常多,无论是在短一点的视频上还是长一点的视频上,它的效果都比所有的之前这些设计。都要好。那其实对于网络结构的这种设计的探索,其实也不光是 r 加 ED 这一篇论文在做,那之前也有 P3D 这篇论文在做,然后它之后也有 S3D 和 ECO 这两篇论文也都是用类似的方法在做的,尤其是 S3D 和ECO,他们都提出了这种头重脚轻或者头轻脚重的这种设计方式,然后去做这种消重实验,所以说大家的想法其实也都是差不多的,那可能读到这儿很多同学还是不知道什么是 r 加ED,到底什么叫拆分。那作者这里其实在图 2 里就大概画了一个简单的示意图,那意思就是说你用了一个 t 乘 d 的一个卷积核,当然你可以是 3 * 3 * 3 了,但式你这个时间上和空间上可以是不一样。然后 r 加 1D 的方式就是说把这个 3D 给拆分了。我现在空间上做这种 2D 卷积,就是在时间这个维度上是一,就什么操作都不做,然后在空间上去做这个 d 乘 d 的这个卷积,然后中间作为一层这个特征投射,就是把这个维度。变化一下。那这里之所以变换这个维度是想让这个 r 加 ED 最后的这个网络参数和这个 R3D 这个纯 3D 网络的网络参。数保持一致,这样子更能够做这种公平的对比来显示这个 r 加 ED 网络的这个优越性。那至于这里这个维度 MI 是怎么算的,其实它在多文论文里也在这里展现出来了,用这个公式去算的,能够尽可能的逼近这个 R3D 的这个网络。参数。那一旦做完这个特征投射之后,它接下来就做了一个 t 乘 1 * 1 的一个直序上的一个卷积,那这里只在时间上做了一次卷积,那后面是空间上就是 1 * 1,还没有做什么操作的,所以就是通过这种方式把一个 3D 的卷积拆分成了一个顺序的,先做空间再做时间的卷积形式,那作者这里也说了两点,就是说这种拆分的形式为什么比原来这个纯使用 3D 网络好的。原因。一个就是增强了网络这个非线性。因为你原来如果只有一个 3D com 的话,你后面就只接了一个 value 激活层,所以你只做了一次非线性操作。但是你现在做了两次卷积,那你每个卷积后面都有一个 value 激活层,所以你就有两次非线性的变换,你这个模型的非线新能力就加强了,那他的学习能力也就增加了。那第二个好处,也就是从优化的角度来看,如果你直接去学一个 3D 卷积的话是不好学的,那如果你把它拆分成一个 2D 和 1D 来说,它就相对容易优化。一些。那作者在右边的这个图 3 里也展示一下训练和测试的这个。错误。就是拿 r 加 1D 和这个 r 二 3D 做了一个对比。我们可以看到不论是对浅一点的网络,就是 R3D 18 或者 r 加 ED 18,就是只有 18 层。还是说对于一个深一些的网络,就 R 3D 34 和 r 加 1D 34 来说,它的这个结论都是统一的,就是你用上 r 加 1D 这种拆分式的结构之后,你不论是训练的这个误差,还是测试的时候,误差都比原来这个 R3D 是要低一些的。这也就证明了这既不是过拟合,也不是欠拟合,这就简单地证明了模型是更容易训练。那说完了 r 加 ED 到底是怎么做拆分的,也做完了这个形容实验,那最后就是看一下结果,我们首先来看一下这个 K400 上的这个结果对比,那同样的,因为 r 加 1D 这篇论文也是 CVPR 18,所以说在它之前其实只有 S3D 这一篇工作在 K400 上数据集有这个分数,所以说它就只能跟 I3D 去比。那这里面其实还是有一个比较有意思的现象,就说 r 加 ED 不论是在 RGB 上还是在 flow 上,它它的这个结果都比对应的这个 SMD 是要高一些的。但是当你最后做这个 late Fusion,就是当你把这两个结果加权平均之后,你会发现这个 SMD 的提升非常明显,反而是这个 r 加 ED 没什么提升,所以导致这个双流 r 加 ED 的结果还不如双流 SMD 的结果,不过这个作者也没有给出。解释。另外我们可以看一下这个在 UCF 101 和 HMDB 51 上的这个结果,同样我们可以看出 r 加 1D 表现还是不错的,但是如果跟 I3D 去比,还是比较怪的现象就是它虽然在 RGB 上比这个 I3D 的 R7B 要高,但是它在 flow 上就已经比 S3D 的 flow 要低了,然后再把这两个加起来之后,它的这个结果就更低了。那作者这里可能觉得这不行,那在 K400 上已经比 I3D 低了,那如果在 UCF 101 会是 MDB 上再低,这就不好给审稿人交代了。所以他这里还在题目里稍微解释一下,他说我们的这个模型是光在 K400 上去做预训练的,但是上面这个 SND 模型是在 Imagenet 加 K400 上去做这个预训练的,他们比我多用了 Imagenet 这个预训练,所以说他们比我高这是理所当然的。但是事实上这句话可能不太成立,因为我们之前如果精读过 S3D 那篇论文,我们就会知道 S3D 那篇论文里也做了就是单独用 K400 去预训练模型的。结果。而且事实上最后这里的结果应该是97。8,而这里应该是 80. 9,所以是丝毫不比这个用了 image net 要差的,反而有可能在 h NGB 上是更好的。所以这也就意味着,其实 R2 加 ED 这个模型至少在 R U C F 101 和 HMD 51 这两个数据集上效果是不如 SMD 的,当然这个我觉得其实是情有可原的,因为毕竟 r 加 ED 它用的这个输入是 112 乘112,它是比原来这个 SND r 24 * 24 要小一倍的,所以效果低这么一点也没什么关系。而且 r 加 ED 这种拆分的模式确实有助于这个模型的训练,确实有助于降低这种过拟合。而且它不需要借助于 Imagenet 这个预训练模型,它是可以从头自己开始训练的,而不是像 S3D 一样借助了 2D 模型,也借助了 2D 模型的这个预训练参数,才导致这个比较。好优化。所以说 r 加 ED 这个网络本身的结构也是非常值得学习的。那在前两年对比学习或者说自监督学习在视频领域里也比较火的时候,很多人都是采用 r 加 ED 当做这个网络的白克崩去做这种视频的自监督训练的一个很重要的原因,也是因为它比较好优化,而且它的一个输入是 112 乘 112 也比较小,对 GPO 内存比较友好。然后接下来我们还会讲到 time Sommer 这篇论文,其实也是 r 加 ED 这篇论文里有些。作者写的。想法上也非常类似,就是把一个 special temporal 的一个 Transformer 拆分成了在空间上和时间上分别去做这个自助。利益操作。这样子就大大简化了对显存的要求,从而在视频上也能训练起一个vision。Transformer。总之, r 加 ED 这篇论文当你读完以后,你就会发现它是一个纯实验性的论文,它主要的贡献就在于它的这个消融实验,以及它带给你的各种这种观察和见解,从而能够帮助你理解视频领域里不同架构之间的这个区别和联系,以及到底应该怎么去构建一个适合于视频理解的这个模型框架。那 3D 网络的最后我们来看一下 slow fast 这篇论文,那作者又是我们熟悉的一帮人,这篇论文其实是 3D 网络里结合这个精度,而且这个效率结结合的比较好的一个工作。他的想法很简单,也非常有意思,其实有点借鉴了双流网络的思想,但是并没有用光流作为这个模型的输入,它还是一个单纯的 3D 网络。作者在文章中其实说他们的这个研究动机来源于说人的这个视觉系统有两种细胞,一个叫 p 细胞,一个叫叫 m 细胞, p 细胞数量比较多,占到这个视觉细胞的80%,它主要是负责处理这个静态图像的,就是说现在当前这个图像里这个场景是什么信息?它要描绘得非常具体, p 细胞是干这个的, m 细胞是处理这个运动信息的,它能处理这种高频率的这个运动信息,它只占这个视觉细胞的大概20%。的数量。所以作者想了想,他觉得这个诶跟这个双流系统也有点像,就是有一只是处理这个动态信息,一只是处理这个静态信息。那 3D 这边其实我也可以这么设计一下,所以就有了 slow fast 的这个网络。 slow fast 顾名思义就是有一支网络是 slow 的,有一支网络的。是fast。具体怎个 slow 和fast。法?那假设说我们现在有一个视频,那这个视频有 64 帧,就说大概两。秒多。那如果我们现在先用很低的这个帧率,就比如说每隔 16 帧取一帧,取出来 4 帧的话,这一支就叫慢分支。它就像那个 p 细胞一样,主要是学习这个静态图像,主要是学习这个场景信息的,因为 p 细胞它占了整个视觉细胞的30%,所以这里面作者觉得这个静态图像的这个描绘也比较难,所以说他也想把大部分的这个模型参数给这个慢分支,所以说这个慢分支的这个网络结构其实是比较大的。简单地说其实它就是一个 SMD 网络,但是因为给这个大 SMD 网络的输入只有 4 帧,所以说相对而言它这个计算复杂度不是太高。然然后就到了底下这个快分支,那快分支就是假如说你有 64 帧,那我现在每隔 4 帧取一帧,就我用这个很快的帧率现在去取样,最后我就取得到 16 帧,然后我把这个 16 帧输入给这个块分支,那现在因为你这个输入变多了,我为了维持整个这个模型的计算开销还是比较小,所以我就要让这个块分支的网络尽可能的小。这样就模拟了这个视觉里这个 m 细胞,它只占整体的20%,主要就是描述运动信息,因为你描述运动信息,所以你需要更多的这个帧,然后这样能快速地看出来它们之间的改变,所以说听起来是非常合理的。所以整体上来看, slow fast 也是一个 2 分支的结构,跟双流网络一样,然后上面是这个慢分支,下面是这个快分支,慢分支用小输入,但是大网络,快分支用大输入和。小网络。然后这两个分支之间还用这种 lateral connection 把它们都结合了起来。所以它们之间的这些信息是可以互相交互的,从而能够更好地学习到这个时空特征,最后达到了一个比较好的这个精度和速度的这个结合。那看完图一之后,其实大家基本上已经知道 slow fast 这个网络到底是什么结构了?那接下来我们就具体来看一下这个表,一从头到尾走一遍这个前向过程,看一看这个输入输出的大小,就能更形象地了解这个网络了。首先这个是慢分支,这个是快分支,然后这个是他们这个输出的大小。首先我们来看一下网络的话,我们刚才也说了,这个慢分支其实就是一个标准的 SND 网络,这里也就是一个Resnet,我们也可以看到有RESR345,有四个stage,然后这里面就是 rise 50,所以有 3463 这么多这个。residual block。所以说这个慢分制本身就是个I3D,是非常标准的,作者这里也没有过多的强调。然后对于这个块分支,作者其实就把这几个数字变成这个黄色了,那它之所以变成黄色,它就是想让你看一下这个慢分支和快分支的这个通道数的对比。我们可以看到这个快分支的通道数是远远小于这个慢分支的这个通道数的,也就意味着这个快分支是非常轻量。但是整体结构这个快分支跟慢分支也是一样的,也是一个残差网络也是 3463 这么多。residual block。那看完网络结构之后,我们就来过一下这个。前线过程。那首先这个输入是 64 帧,这个帧是 24 * 24 这么大,那对于慢分支来说,就像我们刚才说的一样,每隔 16 帧取一帧,所以说这个慢分支的输入只有 4 帧,但是块分支它这里其实是每隔一帧就取了一帧,所以说一个还取了 32 帧,比我刚才说的 16 帧还要多一倍。所以说这个快分支的输入是相当大的,这也就是为什么作者一定把这里的通道数要减小的原因,否则这个计算开销实在是受不了。然后我们可以看到这个 slow fast 跟之前这个 I3D 网络或者 r 加 ED 网络都一样,它们在这个时序上其实都是没有进行下采样的。你的输入是 4 帧,那接下来都是 4 帧, 4 帧一直到最后。也是 4 帧。你的这个快分支输入是32,你到最后还是32,所以它在这个时间的维度上始终不做下采样,因为它想尽可能地保持这么多帧去学习更好的这个时序信息。因为本身就不多,它这个下载项全都是在这个空间纬度上做的,从刚开始的24,然后降到11256,然后2814,然后到。最后的7。那最后再接一个这个全局平均池化,然后再接一层这个 FC 就可以直接做输出了。值得一提的就是这每一个 residual block 后面都有一个,这个 letter connection 其实就是一个简单的连接,能让这两个分支之间进行简单的信息交互,从而更好地学习时空上的特征。因为 slow fast 这篇论文的想法确实比较直截了当,所以我们这里就直接看结果了。当然 slow fast 它还做了这个视频分类,视频检测,还做了好几个数据集,它的结果都是非常好的。那我们这里就简单看一下 K400 上的效果。就可以了。我们直接来看这个表2,那到 SCV 19 的时候,其实 K400 已经提出有两年了,所以说我们可以看到这里面之前的工作也有很多在 K400 上这个汇报了分数。我们首先可以看到作者把上面这个区域给灰色化了,因为作者觉得这里这些模型全都是利用了这个 Imagenet 预训练模型,它没办法从头训练。但是对于接下来的这些模型,比如我们刚才讲过的 r 加ED,还有新的这个slofaas,它都是可以重头训练,不需要任何的这个预训练模型的。当然了,它训练的这个 epoch 数量会非常多,需要 196 个epoch,训练时长也非常长, 8 卡的机器也要训练十几天,所以说不用这个 image net 预训练参数也不见得是个好事,那接下来我们看一下结果。那 slow fast 这篇文章不光是迈这个精度,它更主要的是想说他们这个模型非常的有高效,所以我们可以看到他们这里还加了一列就是专门做 g Flops,那像它最小的这个 slow fast 4 * 16 rise 50 这个模型,它的这个 g flops 就只有 36. 1,如果我们跟上面这些 3D 模型去比的话,发现它是非常小的。而且 slow fast 随着使用的这个帧数越来越多,而且用的这个模型越来越大,或者说也用了这个 non local block 之后,它这个性能一直会增长,一直到最后的这个 79. 8,这个也是比之前的这些方法通通都要。高的。而且这个基本也算是 3D 网络在 K400 这个数据集上最好的表现了,那 3D 网络这部分我们就算过完了了,还有很多优秀的 3D 网络的工作我们没有时间去设计。而且还有一些有趣的工作,它既不用光流,它也不用 3D 网络,也能比较好的高效地把这个视频理解。做了。比如我之前就有一篇论文叫 hidden to stream network,就是把这个光流的学习融入到网络之中了,这样不论是在训练的时候,还是在推理的时候,我们都不需要去抽取这个光流,抽光流这个步骤就在网络之中了,所以是比较高效的。然后还有另外一篇论文, TSM temporal shift module S C V E 9 的一篇论文,它是把 shift 这个操作用到了这个视频理解里,能让一个 2D 网络就能媲美一个大的 3D 网络,而且在很多任务上效果都非常的好,而且因为是 2D 网络,所以比较方便。去部署。作者在官方代码还提供了一些手势检测的Demo,非常有意思,感兴趣的同学也可以去。试一下。总之, 3D 网络从 17 年 I3D 火了之后,就一直霸占这个视频理解领域,一直到 2020 年,然后自从有了 vision Transformer,大家这个注意力又全都转移到这上面了,所以说就到了我们今天要讲的第四个部分,就是 video Transformer。怎么把在图像上用得比较好的这个 vision Transformer 能移植到视频领域里来,做一个视频的 vision Transformer,那 video consumer 这篇我们就准备讲一篇这个timesqmer,也是最早的一篇把 vision consumer 用到视频理解领域的一篇论文,它这个题目也是让人一看就懂时空注意力是不是 all you need?这个就跟 2017 年 Transformer 的原文是一样的,自助力是不是 all you need?那这篇论文我们之前在讲 r 加 ED 的时候也说过,是跟 r 加 ED 的作者团队差不多的。那这篇论文也是一篇比较实验性的论文,就是探索了一下怎么把这个 vision Transformer 从这个图像领域迁移到视频领域里来。那具体来说作者就尝试了这五种结构,那第一种结构 space attention 就是只在这个空间特征图上去做这种自助力,那这个其实就是图像里这个 vision Transformer 用的这个自制为例,意思就是说你一个这个特征进来做一次这个空间自制为例,然后再接一个MLP,然后通过残差连接,最后。得到这个输出。那这个就属于是图像上的一个 baseline 了。那接下来就是说怎么用到这个视频上?那首先视频上第一个就是我暴力地去使用,对吧?那我就是给一个视频,那我就在这个视频三个维度上通通去做这个自注意力,我一起做,也就是他这里说的这个 joint waste time attention。那这样呢?一个输入进来过这个时空司注意力,然后再过一个MLP,然后通过残差连接就得到最后的输出了。但是这种方式其实我们肯定就能想到这个 GPU 内存肯定塞不下,那图像那边 vision consumer 都快塞不下了,那更别提你现在把这个视频 30 帧 60 帧扔给一个 vision Transformer,你在三个维度上去算这个自助力它肯定是塞不下的。所以你一旦这个 GPU 内存塞不下,那该怎么办?那其实就像 r 加 ED 做的一样,你 3D 塞不下,不就把你拆分了嘛,我就把你拆成 2D 和 1D 就行了。那这里呢?其实还是同样。的套路。那你既然一个 3D 的这个时空的自助力你做不动,那我就在时间上先做自助力,然后再在空间上再做自助力不就行了吗?所以说就按照这个 r 加 e d 的方式,作者就提出了他们这篇论文里的这个 divided space time attention 就是把这个时空分开来做,这里他没有用 factorize 这个词,他换了一个词换成divided,但其实都是。一个意思。具体做法就是你一个特征近了,我先在这个时间维度上给你做一下自助运力残差连接,然后我再在空间上做一下这个自助运力,然后最后过一个MLP,最后得到输出。这样这个计算复杂度就大大降低了,因为你每一个这个序列长度都变得。很小。当然了,除了这种时间和空间上的这种拆分之外,你还可以有很多别的拆分方式,那比如之前大家常用的就是这种 local global 的形式,就是既然你全局的这个序列长度太长,你没法算,那我就先在局部算好以后,我再在这个全局。上去算。这个其实就有点这个 swing transfer 的意思,我在一个局部的一个小窗口里去算这个四处余力,它这个计算复杂度也会变得。很低。所以说这里就是说我先一个特征进来,我先局部。算特征。然后我再去全局算特征,那这个复杂度也就会降低。最后一种也就是这个 Excel attention,就是说我只沿着你特定的这个轴去做attention。这个之前我们在讲 vision Transformer 的时候也。提到过。就是说我一个特征进来,我先沿着这个时间轴去做自主运力,然后我再沿着这个横轴,就是这个图像的宽去做 4 除以力,然后再沿着这个图像的高度这个竖轴去做 4 除以力。那意思就是说把一个三维的问题拆成了三个一维的问题,那这个复杂度一下又会降得很低很低。但总之你一看这个图,你就会立马联想起来跟 r 加 ED 这篇论文。的联想。r 加 ED 也画了 5 个图,分别讲了讲这个 2D 和 3D 该怎么融合,到底哪种结构好。那这篇 Timesformer 他们也是画了 5 个图,讲了讲这个微症 Transformer 怎么能用到。视频里来。套路是非常相似的。然后反正是实验性论文可以写的,这个方法部分并不多,所以作者为了让这个读者更好理解,所以把刚才那 5 个图又用可视化的方式展现了出来,形象的告诉你,这 5 种自注意力的方式到底是怎么做的。这个图确实画。的也很好。首先我们来看就是单纯用这种图像上的这种空间自注意力,那意思就是说如果我们有前一帧,那 frame t 减一,中间这一帧 frame t 和下一帧 frame t 加一的话,如果我们拿这个蓝色的 patch 当基准点,那其实它会跟谁去算这个自助力?它只会跟它当前的这一帧去算。自助运力。因为它就是一个图像的自助运力,它不牵扯这个时间轴上的,所以说它看不到前后这两帧,它只是跟本帧上所有的别的 patch 去做这个自主。引力操作。那接下来的这四种方法就全是跟视频有一些关系了,那比如说接下来的这个在时空上一起做自助力的方式,那这个当然是最好了,因为我们可以看到如果拿这个蓝色的 patch 当基准点,前一帧这一帧和后面一帧所有的这个 patch 它都要去做自制自主一力,效果肯定应该是最好的,但是这个复杂度也是你承受。不起的。那我们就来看看后面三种这个简化方式是。怎么做。那第三种也就是他们这篇论文中主要提出的方法,这个 divided space time 自助力,那同样我们还是以这个蓝色的 patch 作为基准,那先做这个时间上的自助力,也就是说他先做这个 patch 对应的前一帧的这个 patch 上,他去跟这个 patch 去做自助力,然后同样在下一帧同样的位置上这个 patch 上去做自助力,也就是这个他们在做这个自助力操作,它跟前一帧剩下所有的这些 patch 和下一帧所有这些 patch 都是不做主。自主义力的,没有关系。那做完了这一步,这个时间上的自助力接下来就该做空间自主义力了。那这个空间自助力就跟第一个这个 2D 的空间自助力。是一样。的,它跟这个图像里的所有的别的 patch 都会去算一下自助力。那接下来第四种方式,这种先局部再全局的方式,就是说首先我先去算这个局部小窗口里的自注意力,那如果我们拿这个蓝色 patch 当这个基准点,那对于当前帧来说,我们就算这个小窗口里,那前一帧也是这个小窗口,后一帧也是这个小窗口。那当算完了所有这个小窗口之后,接下来就该算这个全局的了,那全局为了减少这个计算量,它就得变得非常的稀疏,所以也就是。这些点。是要去做这个自助力操作的。那最后就到了这个轴自助力,那也就是说把一个三维问题变成了三个一维问题。这里也非常形象,就是说如果这个是基准 patch 的话,它的时间上是跟前后这两层绿色去做自主义力,那它在横轴上是跟这个黄色的去做。自主力。在竖轴上是跟这个紫色去做自主义力。那其实这个 x attention,也就是这个 divided space time attention 的一个极端情况,就说为了进一步地减少这个消耗,那在当前帧上也不做所有 patch 的这个自助运力,而是专门去选这个轴。上去做。那这个效果肯定是会有 trade off 的。总之作者就是详尽的把这些设计方案全部都试了一遍,看看到底哪个设计方案最后的效果最好。最后就依据中间的这个 divided space time attention 提出了他们这个Times。former 的架构。我们简单来看一下这个消重实验,那消重实验这个表一里就是把刚才说的这五种设计方案全对比了一下,那从结果上来看,这个 divided space time 确实取得的效果是。最好的。那在 K400 上单纯用这种 2D 的这种自注意力效果也不错,或者说这种 joint 的这种时空自助力效果。也不错。但是单纯用 2D 的这个自助力之所以效果好,是因为 K400 这个数据集是一个比较偏重这个静态图像的,那如果我们换到这个 something 数据集上,我们就可以看到光用这个 2D 的这个自注意力效果一下就下降了很多,我们还是要把这个时间维度考虑上。所以说唯一表现比较好的就剩下这个 joint space time 和 divided space time 这两种方式。但是我们之前也说过这个 joint 的这种时空的自助力,它的这个内存消耗是非常巨大,作者也就在这个图 3 里画了一下,就是如果我们把这个视频帧的大小变大,从 224 变成 336448 或者更大,它们这个 Timeformer 这个计算量的增长是基本呈线性的,但是这个 joint 的自注意力就会增长得非常快,尤其是后面这个灰色部分,其实就已经是 GPO out of memory 就已经报显存了,其实是没法进行训练的。同样的道理,如果我们把这个输入加长,从 8 帧变成 32 帧,一直到最后的 96 帧,我们可以看到这个 joint space time attention 其实从 32 帧开始就已经爆显存了,对你也是没法训练的。所以最后总结下来就是说,即使这个 joint space time,它的这个结果也不错,而且它这个参数量稍微少一点,但是因为它这个占用的 GPU 选存实在是太大了,我们根本训练不动。那最后最好的方案就只剩下这个 divided space time attention 了。那最后我们来看一下结果。首先我们来看一下这个表2,作者这里就是对比一下 Transformer 和之前的这两种 3D 网络, I3D 是最经典的, slow fast 是最新的,所以说它就跟这两种去做了一个对比。那其实我们这里可以发现,如果单纯从这个准确度的角度上来说,这个 times former 不是太行,虽然他这里用这个 78 黑体了说他们是最高的,但我们也知道这个 slow fast 如果你换成 rise 101 或者换成 non local 之后,它这个准确度已经到。80 了。那作者这里为了突出使用这个 region consumer 的。好处。作者这里就发现他的这个训练的时间和这个做推理的这个 flops 都变低了。那比如说训练时间的话, slow fast 一个 rise 50 就要训练 6000 多个小时,但是他们这个 times former 只需要训练 400 个小时。这个微声 transformer 拿来做微调,这个确实效果非常好。那推理上,因为 transmer 需要的这个输入更少,所以说他推理时候用的这个 t flops 也。更低。也就是说从效率角度而言, time sqmer 是优于之前的这个 3D 网络的。但是大家也知道, CV 领域的人一般只认这个效果,不太认这些效率这些东西,所以说作者肯定还是得再刷一刷分的。那作者就是把这个 time former 变得更大,用了 time former large,然后又用了 image net 21K 去做预训练,最后还是把 K400 刷到这个上 80 了。那这样子的话就别人无话可说了,这个效果确实是最好的,在 something 上这个结果也是不错。总之作为第一篇把这个 vision consumer 用到视频理解领域来,本文的结果其实已经算不错了。接下来很快我们组这边也有一篇VIDTR,也是用类似的思想去做 video Transformer 的,然后 Facebook 那边还有另外一篇 MVIT Multi skill vision Transformer,也是做 video Transformer 的,效果会更好。然后 Google 那边还有一个 VI VIP,想法都差不多,都是把这种时空自注意力拆分,只不过用了拆分的方式不太一样,所以其他的这些工作我这里就不讲了。那最后我们来总结一下这篇论文,那其实作者在这里也总结说,他们的这个 Timeformer 有 4 个好处,第一个就是想法非常的简单,第二个就是效果非常好,在好几个这个动作识别的这个数据集上都取得了最好的。效果。第三个就是不论是训练还是在做推理的时候,它这个开销都是非常小的,这点对于视频理解来说还是非常具有。吸引力的。然后最后其实我并没有讲,就是说这个 Timeformer 可以用于处理超过一分钟的视频,也就意味着说我们之后可以做这种长时间的这个视频理解了,这个其实视频理解里非常重要的一个部分,但是之前很少有工作做,因为确实这个训练成本各方面都非常的高,这个任务也比较困难,而且也没有合适的一个数据集去做这种测试。所以说综合以上这些优点,而且 vision Transformer 在视觉这方面大杀四方,这个扩展性、稳健性都这么的好,我觉得接下来 video consumer 确实是大有可为,而且更主要的是视频本身就是一个多模态的信号,它可可能会有字幕这种文字信息,然后它可能会有这种音频信息。然后你如果从中抽取这种光流,或者抽取这种深度图,它就是属于别的这种多模态信息,它自己就是一个非常丰富的这个输入来源,从中可以设计出各种各样的这个自监督信号。如果我们在和这个 Transformer 结合起来,很有可能就能达到 CV 里面像 NLP 那样的这个 Bert GPT 时代。那说完了最新的这个 video Transformer,最后我们就来把之前讲过的所有东西大概再。串一下。首先就是从 14 年开始,最早的在 Alex net 之后把这个卷积神经网络用到视频领域里来,就是 deep video 这篇论文。但是 deep video 没有很好的利用这种运动信息,所以说它刚开始的效果不是很好,它还没有这种手工特征 IDT 的效果好。所以说这个双流网络的作者就想了一下,那为什么不把 IDT 里用的这种运动特征加进来,所以说这两个方法结合起来就造就了这个双流。网络。所以双流网络的结果就变得很高,那从此就开始了用这个深度学习做这个视频理解的时代。那因为双流网络证明了它的这个有效性,所以说接下来大家就在它之上去做各种各样的改进,那首先最常见的一个改进就是说对视频来说,我们想要更长的这种时序理解的能力,所以说我们加上这个LSTM,就有了这个 C V P R E 5 的 beyond short snippet 这篇论文。然后因为这个双流网络又是做的这种 late Fusion,就在最后把这个结果加做了个加权平均,那所以肯定就会有人想我们能不能做一下 early Fusion,那于是就有了这个 CVPR 16 的这个 early Fusion。这篇论文。然后因为双流方法里只是简单地利用了这个光流,并没有真的根据光流的这个轨迹去做这种视频特征的叠加。所以说在双流网络的基础上, C V P R E 5 的 TDD 这篇论文就按照轨迹去直接加特征,得到了非常好。的效果。那最后一点就是对于视频,我们想要处理这种长时间的视频信息,而且要让它变得更加的这个高效,这就有了 ECCV16 的这个 TSN 这篇论文。 Tempo segment networks 就是把一个视频打成几个段,然后每一段里去做这个分析,最后把这个分析取一个合并。那因为 TSN 这个做的比较简单,所以很快在 TSN 的基础上,大家又纷纷地去做各种改进和尝试,就是把之前传统学习里的这种全局建模已经加了进来,比如说全局建模已有这个 feature vecting coding、 VR ad encoding 这些方法,那像这个 DOVF 就是把这个 feature VC encoding 用了进来,这个 TLE 就是把这个 by Linear encoding 用了进来。那这个 action Vlad 其实顾名思义就是把 Vlad 给。用了进来。那基本到这个阶段,其实这个 2D 的双流网络就已经把 UCF 101 和 HMD B51 基本给刷得非常高了,也没有什么太多可以做的了。同时也就是在 2017 年,这个 S3D 这个网络就。出来了。那所以我们现在再来看 3D 网络这条线。那在这个 deep video 提出这个 Sports y million 之后,这个很多人就想,那既然这个视频是一个 3D 的输入,我们为什么不用一个 3D 的网络来处理它呢?那用一个 3D 的卷积神经网络来学习,肯定听起来是一个更合理的事情,所以很快就有人做了这个C3D,就是纯粹的用一个 3D 神经网络来学习视频,而且因为有了 Sports one million 这么大一个数据集,他觉得它还是能训练出来一个非常好的网络的。那事实上这个网络抽取特征效果还可以,但是如果在一些刷分比较厉害的这个数据集上,它跟别的方法效果还是差。得比较远。的。那接下来大家就想,那为什么 3D 就是训练不好?可能还是因为初始化做的不好,那如果我能把这个初始化做的再好一点,这个训练这个优化就会变得更简单。于是就有了 I3D 这篇论文,就是 inflated 3D network,它可以借助这个 2D 网络的初始化和 2D 网络的这个结构,很快就能得到一个很好的结果,所以说 I3D 把 UCF 101 和 HMDB 51 这两个数据集直接就给刷爆了,在那之后大家就开始用这个 K400 去汇报结果。所以说在 3D 网络这边,基本上所有的这些工作都是在 K400 或者说 something 这几个数据集上去汇报结果。那在 3D 网络这边,一旦证明了这个 S3D 网络的有效性,那接下来就有几个方向。那首先第一个方向就是说,那你这个 I3D 是从一个 2D 的 exceptionat 搬到 3D 的,那其实我也可以把别的 2D 网络搬过来,那所以说把一个 2D 的 Resnet 搬过来就成了R3D,把一个 2D 的 Resnet 搬过来就是 MF net 那如果把一个 2D 的 SE net 搬过来,那就是STC。那第二个思路就是说这个 2D 网络表现。也不错。而且 2D 比 3D 要便宜很多,那我们能不能把这个 2D 和 3D 结合起来使用?所以这也就有了接下来几个工作,就是 S3 D r 加 EDE code 和这个P3D。他们的想法都很像,基本都是把这个 3D 给 p 成 2D 和 1D 了,准确度上没什么降低,但是这个计算效率和训练速度上都有了。大幅度的提高。那第三个方向当然跟 2D 或者双流网络也一样,我想去尝试这种LSTM,或者尝试这种 TSN 去处理更长的这种时间序列。所以说也有对应的一系列工作,比如说这个 LTC 就已经使用了 120 帧。左输入。还有接下来这个T3D、nonlocal、 V4D 这些工作通通都是为了能处理更长的这个时序信息而设计的。那最后一个方向就是做这种高效率的,比如说这种CSN,就是 channel separate。network。还有我们今天刚才说过的这个 slow fast,还有通过这个 auto ML 搜出来的是X3D,这个网络非常小,但是效果。也很好。然后因为 X3D 使用了这种 auto Mo 的方式去搜索这个网络,所以说搜出来的这个网络不仅效果好,而且参数量特别的小,那基本上就很难再有人能打过它了。那正当大家发愁这个视频理解该怎么往下做的时候,大救星来了,被人 Transformer 出现了,对,大家迅速就抛弃了 3D 网络,全去搞被帧Transformer,因为反正 3D 网络我也刷不动。那在短短几个月的时间里,在 2 月份就有了 time swarmer, 3 月份有了VIVIT,然后 4 月份我们的 VIDTR 和这个 Facebook MVIT 也就都放出来了。基本上方法都差不多,就说这个 joint space time attention 这种合并起来的,这个时空自注意力太贵了,这个视频里直接做这种 Transformer 做不起,所以我们就要拆分它,那要我先做一下时间,再做一下空间,就跟 r 加 ED 一样在这个维度上去拆分。要我就是先做一下局部,再做一下全局,就是在用小窗口大窗口之上去。拆分一下。总之 vision Transformer 在视频理解里的应用还是比较初级的,我能想象到的方向就是利用 Transformer 这种长时间序列建模的能力去做这种长时间的视频理解,而且还有就是这种多模态的学习,还有这种自监督的学习。总之,虽然我关注了视频 a 学习这么多年,但我觉得视频领域还是处在一个非常初级。的阶段。接下来有太多太多可以做的,而且有太多太多需要做的任务了。我虽然不知道真实的这个视觉应用里到底有多少需要这种视频理解,但是我非常赞同 Andrej capacity 之前在 Twitter 上说过的一句话,如果想训练一个非常强大的这个视觉模型,拿视频数据做输入可能才是比较合理的做法。