Linux进程间通信之匿名管道
- 进程间通信介绍
- 1. 进程间通信的目的
- 2. 进程间通信发展
- 什么是管道
- 匿名管道
- 1. 什么是匿名管道
- 2. 匿名管道样例详解
- 3. 原理
- 4. 单个父进程与多个子进程管道间通信
- 建立子进程任务相关的头文件
- 主文件的建立
- 执行结果
- 5. 管道读写规则
- 6. 管道特点
进程间通信介绍
1. 进程间通信的目的
Linux进程间通信(IPC,Inter-Process Communication)的主要目的是使不同的进程能够协同工作、共享信息和资源,以便完成各种任务。IPC 在多进程或多线程的应用程序中是至关重要的,因为它允许进程之间进行数据传输、同步和协调操作。以下是一些主要的目的和应用场景:
- 数据共享:进程之间通信的一个主要目的是允许它们共享数据。这对于多个进程需要访问相同数据的应用程序非常重要,如数据库服务器或共享内存。
- 协调操作:多个进程可能需要协同工作以完成某些任务,IPC 可以用于确保它们按照特定顺序执行操作。例如,进程 A 可能需要等待进程 B 完成某项任务后才能继续执行。
- 通知和事件:IPC 可以用于实现事件通知机制,其中一个进程可以通知其他进程有关特定事件的信息。这对于消息传递、信号、套接字或消息队列非常有用。
- 进程间数据传输:IPC 允许进程在彼此之间传输数据。这在分布式计算、网络通信和进程间通信的应用中非常重要。
- 进程间同步:IPC 提供了机制来协调多个进程之间的操作,以避免竞争条件和数据不一致。例如,互斥锁、信号量和条件变量可以用于进程同步。
- 进程管理:IPC 也可以用于进程管理和控制。一个进程可以通过IPC与另一个进程通信,请求其启动、终止或传递信息。
- 分布式计算:在分布式系统中,不同的进程可能在不同的计算节点上运行。IPC 允许这些进程协同工作,共享资源和信息。
2. 进程间通信发展
进程间通信(IPC)是操作系统中的一个重要概念,它允许不同的进程之间交换数据和协作。IPC 方法的发展经历了不同的阶段和技术。在 Linux 和其他类 Unix 操作系统中,主要有以下三个重要的 IPC 机制:管道、System V IPC 和 POSIX IPC。这些机制有不同的特点和用途,它们一起构成了进程间通信的演进历史。
- 管道:
- 管道是最早的 IPC 机制之一,最早出现在 Unix 系统中。管道用于在同一台计算机上的不同进程之间传输数据,通常是通过管道操作符
|来连接命令。 - 管道是单向的,只能在一个方向上传输数据,通常用于将一个进程的输出连接到另一个进程的输入,实现数据流的传递。
- 管道不适用于跨计算机的通信,它主要用于在本地系统内部进行进程协作。
- 管道分类
- 匿名管道pipe
- 命名管道
- 管道是最早的 IPC 机制之一,最早出现在 Unix 系统中。管道用于在同一台计算机上的不同进程之间传输数据,通常是通过管道操作符
- System V 进程间通信:
- System V IPC 是一组进程间通信机制,包括消息队列、信号量和共享内存。这些机制允许进程在不同计算机上或同一计算机上进行通信和同步。
- 消息队列用于在不同进程之间传递消息,信号量用于控制多个进程对共享资源的访问,而共享内存允许多个进程在共享的内存区域中进行数据交换。
- System V IPC 提供了更灵活的进程间通信方式,适用于不同场景,但也相对复杂。
- System V IPC 分类
- System V 消息队列
- System V 共享内存
- System V 信号量
- POSIX 进程间通信:
- POSIX 进程间通信是一组与 POSIX 标准相关的 IPC 机制,包括命名管道、信号、信号量和共享内存。这些机制是为了提供跨平台的 IPC 解决方案。
- POSIX IPC 保留了 System V IPC 的一些特性,同时也引入了新的机制,例如命名管道,以简化进程间通信的实现。
- 由于 POSIX 进程间通信是与 POSIX 标准兼容的,因此可以在不同的 Unix-like 操作系统上实现,提供了跨平台的进程间通信能力。
- POSIX IPC 分类
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
这篇文章我们先介绍管道通信中的匿名管道pipe
什么是管道
在计算机科学中,管道(Pipe)是一种进程间通信(IPC)机制,用于在一个进程的输出流直接传递到另一个进程的输入流,实现数据的传输和协作。管道通常用于将多个命令或进程连接在一起,其中一个命令的输出成为另一个命令的输入。这种机制非常有用,因为它可以将多个小任务组合成一个更大的任务,实现数据流的传递和处理
在 Unix/Linux 操作系统中,管道通常通过管道操作符 | 来实现,它将两个或多个命令连接在一起,使其执行时将数据从一个命令传递到下一个命令。以下是一个简单的示例:
假设你有一个名为 input.txt 的文本文件,其中包含一些文本数据。您希望将该数据按行排序,然后查找包含特定关键字的行。您可以使用管道将 sort 命令和 grep 命令连接起来完成这个任务:
cat input.txt | sort | grep "关键字"
在这个示例中,cat 命令用于将文件的内容读取并将其传递给 sort 命令,sort 命令对文本进行排序,并将结果传递给 grep 命令,grep 命令查找包含特定关键字的行。整个操作是通过管道实现的,数据从一个命令流向下一个命令,形成数据处理流。
管道的主要特点包括:
- 数据传递:管道允许数据在不同命令或进程之间传递,使它们可以进行处理。
- 连接命令:多个命令可以通过管道连接在一起,实现协作处理。
- 实时处理:数据流是实时的,不需要等待整个数据文件被处理完。
- 节省资源:不需要在磁盘上创建中间文件,可以节省磁盘和内存资源。
管道是 Unix/Linux 系统中强大的工具,它可以用于构建复杂的数据处理流程,从简单的文本处理到复杂的系统管理任务。它在 shell 脚本和命令行中被广泛使用,以提高任务的效率和可组合性。
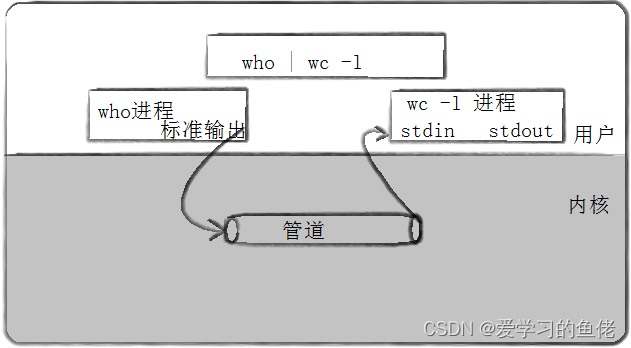
匿名管道
1. 什么是匿名管道
匿名管道(Anonymous Pipe)是一种轻量级的进程间通信(IPC)机制,用于在同一计算机上的两个相关进程之间传递数据。匿名管道被称为“匿名”是因为它们没有独立的文件系统路径或标识符,而是在内存中创建的通道,用于实现进程之间的数据传递。
匿名管道通常是单向的,支持从一个进程的输出流传递数据到另一个进程的输入流。它们是进程通信的一种基本方式,特别适用于父子进程之间的通信。
在 Unix/Linux 操作系统中,匿名管道通常由 pipe() 系统调用创建。一旦管道被创建,两个相关的进程(通常是父子进程)可以使用管道进行通信。一个进程可以将数据写入管道,而另一个进程可以从管道中读取数据。
匿名管道的典型用途包括:
- 进程通信:父进程和子进程之间可以使用匿名管道来传递数据,实现协作和数据共享。
- 管道命令:在命令行中,您可以使用管道操作符
|来将一个命令的输出连接到另一个命令的输入,这背后就是匿名管道的工作机制。 - 进程控制:父进程可以通过管道向子进程发送命令或指令,实现进程控制。
- 数据传输:用于在进程之间传递数据,如文本、二进制数据或其他格式的信息。
请注意,匿名管道只能在有关的进程之间使用,通常用于协作性任务。如果需要在不相关的进程之间进行通信,或者需要更复杂的通信机制,可以考虑其他进程间通信机制,如命名管道、System V IPC 或网络套接字。
#include <unistd.h>
功能:创建一无名管道
原型
int pipe(int fd[2]);
参数
fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码
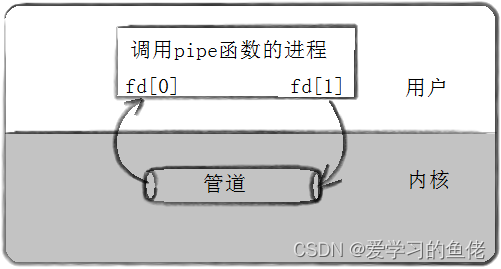
pipe 函数的原型如下:
#include <unistd.h>
int pipe(int filedes[2]);
参数 filedes 是一个包含两个整数的数组,用于存储管道的文件描述符。filedes[0] 是管道的读端,filedes[1] 是管道的写端。
下面是一个简单的示例,演示如何使用 pipe 函数创建管道并在父子进程之间传递数据:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int filedes[2];
char buffer[30];
pid_t child_pid;
// 创建管道
if (pipe(filedes) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
child_pid = fork(); // 创建子进程
if (child_pid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (child_pid == 0) { // 子进程
close(filedes[1]); // 关闭管道写端
read(filedes[0], buffer, sizeof(buffer));
printf("子进程读取的数据: %s\n", buffer);
close(filedes[0]);
} else { // 父进程
close(filedes[0]); // 关闭管道读端
write(filedes[1], "Hello, child!", 13);
close(filedes[1]);
}
return 0;
}
输出结果
子进程读取的数据: Hello, child!
在此示例中,pipe 函数创建了一个管道,然后通过 fork 创建了一个子进程。父进程向管道写入数据,子进程从管道中读取数据。通过这种方式,父子进程之间实现了数据传递。
2. 匿名管道样例详解
首先我们建立一个mypipe.cpp文件
写入需要用到的头文件并展开std命名空间
#include <iostream>
#include <string>
#include <cstdio>
#include <cstring>
#include <assert.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
主函数中我们先创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n != -1); // debug assert
(void)n;
int pipefd[2] = {0};:在栈上创建一个名为pipefd的整数数组,其中有两个元素。这两个元素分别代表管道的读端(pipefd[0])和写端(pipefd[1])。int n = pipe(pipefd);:使用pipe函数创建管道。如果创建成功,pipe函数会将读端和写端的文件描述符填充到pipefd数组中。assert(n != -1);:assert是一个宏,用于在运行时检查条件是否为真。如果条件为假,它会终止程序执行,并在标准错误输出中打印一条错误消息。在这里,它用于检查pipe函数是否成功创建了管道。如果pipe函数返回 -1(表示创建失败),则程序将终止。
(void)n 这一行代码是为了在编译器的严格性检查下避免未使用的变量 n 导致的编译警告。在这段代码中,n 是用于接收 pipe 函数的返回值的变量,但在后续代码中并没有实际使用 n,因此编译器可能会生成未使用变量的警告。
将 (void)n 添加到代码中的目的是明确告诉编译器,你有意不使用变量 n,并且这是一个有意的决策。这可以帮助消除编译器关于未使用变量的警告,以保持代码的整洁性。
要注意的是,这样的代码通常是为了编程风格和规范的目的,以确保代码清晰和易于维护。实际上,你也可以在不使用 (void)n 的情况下编译代码,但这可能会导致一些编译器产生警告信息,或者在某些情况下可能导致不必要的干扰。
加入条件编译观察管道的文件描述符的值
#ifdef DEBUG
cout << "pipefd[0]: " << pipefd[0] << endl;
cout << "pipefd[1]: " << pipefd[1] << endl;
#endif
通常,DEBUG 宏会在调试模式下定义,以便在开发和测试时提供更多的信息,而在生产模式下将其禁用,以减少不必要的输出和性能开销。例如,在编译时可以使用 -D 选项定义 DEBUG 宏,如下所示:
g++ -o my_program my_program.cpp -DDEBUG
这将在编译过程中定义 DEBUG 宏,允许在代码中执行条件编译的调试输出。如果不需要调试输出,可以省略 -DDEBUG 选项,或者在代码中注释掉 #define DEBUG。
如果你使用makefile编译的话可以参考下面的文件代码
pipe:pipe.cc
g++ -o $@ $^ -std=c++11 -DDEBUG
.PHONY:clean
clean:
rm -f pipe
创建子进程
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
close(pipefd[1]);
char buffer[1024 * 8];
while (true)
{
ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s] = 0;
cout << "child get a message[" << getpid() << "] Father# " << buffer << endl;
}
else if(s == 0)
{
cout << "writer quit(father), me quit!!!" << endl;
break;
}
}
exit(0);
}
pid_t id = fork();:这行代码创建一个子进程,并将子进程的 PID(进程ID)存储在id变量中。如果fork失败,id将是 -1,因此接下来的assert用于检查fork是否成功。父子进程将根据fork的返回值分别执行不同的代码。if (id == 0):这是一个条件语句,用于判断当前代码块是否在子进程中执行。如果id等于 0,说明当前代码块在子进程中执行。close(pipefd[1]);:子进程关闭管道的写端,这是因为子进程只负责从管道中读取数据。关闭写端有助于确保管道的正确使用。char buffer[1024 * 8];:定义一个字符数组buffer用于存储从管道中读取的数据。while (true):进入一个无限循环,子进程将一直尝试从管道中读取数据。ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1);:子进程使用read函数从管道的读端读取数据,并将读取的字节数存储在s中。数据将存储在buffer中,但要确保不超过buffer的大小减 1,以便在末尾添加 null 终止字符。if (s > 0):如果成功读取了数据,进入这个条件,然后子进程将打印接收到的消息。else if (s == 0):如果read返回值为 0,这表示管道的写端已经被关闭,通常意味着父进程已经完成了数据的写入。子进程在这种情况下打印一条消息,然后退出。exit(0);:子进程退出,结束其执行。
父进程写入
close(pipefd[0]);
string message = "我是父进程,我正在给你发消息";
int count = 0;
char send_buffer[1024 * 8];
while (true)
{
snprintf(send_buffer, sizeof(send_buffer), "%s[%d] : %d",message.c_str(), getpid(), count++);
write(pipefd[1], send_buffer, strlen(send_buffer));
sleep(1);
cout << count << endl;
if (count == 5){
cout << "writer quit(father)" << endl;
break;
}
}
close(pipefd[1]);
pid_t ret = waitpid(id, nullptr, 0);
cout << "id : " << id << " ret: " << ret <<endl;
assert(ret > 0);
(void)ret;
close(pipefd[0]);:父进程关闭管道的读端,因为父进程只负责向管道写入数据,关闭读端可以确保管道的正确使用。string message = "我是父进程,我正在给你发消息";:定义一个字符串message,其中包含要发送给子进程的消息。int count = 0;:初始化一个计数器count,用于给消息编号。char send_buffer[1024 * 8];:定义一个字符数组send_buffer用于存储要发送的消息。while (true):进入一个无限循环,父进程将不断发送消息。snprintf(send_buffer, sizeof(send_buffer), "%s[%d] : %d", message.c_str(), getpid(), count++);:使用snprintf函数将消息格式化到send_buffer中,包括消息文本、父进程的 PID 和消息编号。write(pipefd[1], send_buffer, strlen(send_buffer));:使用write函数将消息写入管道的写端。这将把消息发送给子进程。sleep(1);:父进程休眠 1 秒,然后继续发送下一条消息。if (count == 5):当count达到 5 时,父进程输出一条消息表示它将退出,并且终止循环。close(pipefd[1]);:父进程在退出之前关闭管道的写端,以确保子进程知道不会再有更多的数据传入。pid_t ret = waitpid(id, nullptr, 0);:父进程使用waitpid函数等待子进程的终止。这确保了在子进程退出之前,父进程不会提前退出。assert(ret > 0);:使用assert检查waitpid函数的返回值ret是否大于 0,以确保子进程已经正常退出。如果waitpid返回负值,表示等待出现错误,可能需要进一步处理。
编译后执行
child get a message[11049] Father# 我是父进程,我正在给你发消息[11048] : 0
1
child get a message[11049] Father# 我是父进程,我正在给你发消息[11048] : 1
2
child get a message[11049] Father# 我是父进程,我正在给你发消息[11048] : 2
3
child get a message[11049] Father# 我是父进程,我正在给你发消息[11048] : 3
4
child get a message[11049] Father# 我是父进程,我正在给你发消息[11048] : 4
5
writer quit(father)
writer quit(father), me quit!!!
id : 11049 ret: 11049
全部代码
#include <iostream>
#include <string>
#include <cstdio>
#include <cstring>
#include <assert.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
int main()
{
//1.创建管道
int pipefd[2]={0};
int n=pipe(pipefd);
assert(n!=-1);
(void)n;
#ifdef DEBUG
cout << "pipefd[0]: " << pipefd[0] << endl;
cout << "pipefd[1]: " << pipefd[1] << endl;
#endif
// 2. 创建子进程
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
close(pipefd[1]);
char buffer[1024 * 8];
while (true)
{
ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s] = 0;
cout << "child get a message[" << getpid() << "] Father# " << buffer << endl;
}
else if(s == 0)
{
cout << "writer quit(father), me quit!!!" << endl;
break;
}
}
exit(0);
}
close(pipefd[0]);
string message = "我是父进程,我正在给你发消息";
int count = 0;
char send_buffer[1024 * 8];
while (true)
{
snprintf(send_buffer, sizeof(send_buffer), "%s[%d] : %d",message.c_str(), getpid(), count++);
write(pipefd[1], send_buffer, strlen(send_buffer));
sleep(1);
cout << count << endl;
if (count == 5){
cout << "writer quit(father)" << endl;
break;
}
}
close(pipefd[1]);
pid_t ret = waitpid(id, nullptr, 0);
cout << "id : " << id << " ret: " << ret <<endl;
assert(ret > 0);
(void)ret;
return 0;
}
3. 原理
用fork来共享管道原理

站在文件描述符角度-深度理解管道
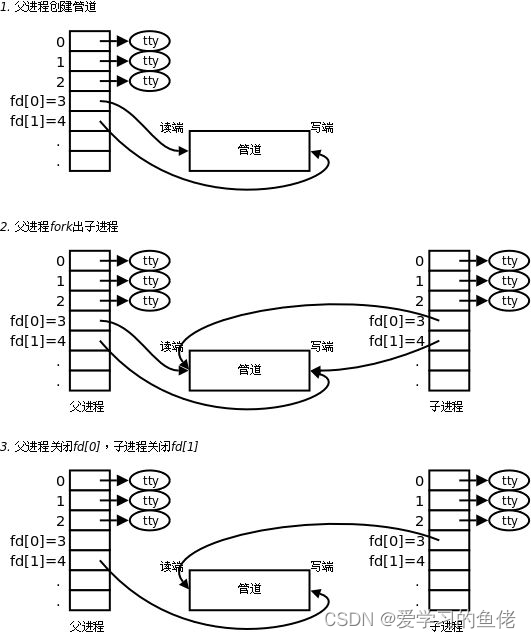
站在内核角度-管道本质
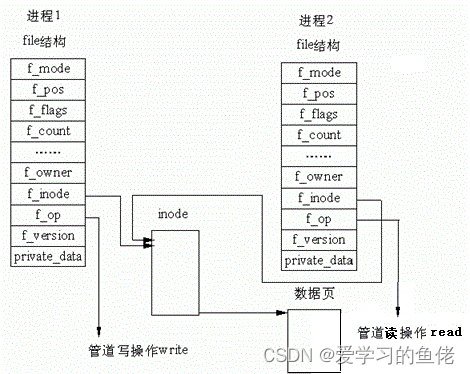
所以,看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了“Linux一切皆文件思想”
4. 单个父进程与多个子进程管道间通信
建立子进程任务相关的头文件
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
#include <unistd.h>
#include <functional>
typedef std::function<void()> func;
std::vector<func> callbacks;
std::unordered_map<int, std::string> desc;
void register_web()
{
std::cout << "sub process[" << getpid() << " ] 注册网站\n" << std::endl;
}
void login_web()
{
std::cout << "sub process[" << getpid() << " ] 登录网站\n" << std::endl;
}
void cal_sql()
{
std::cout << "sub process[" << getpid() << " ] 调用数据库\n" << std::endl;
}
void save_sql()
{
std::cout << "sub process[" << getpid() << " ] 保存数据库\n" << std::endl;
}
void load()
{
desc.insert({callbacks.size(), "register_web: 注册网站"});
callbacks.push_back(register_web);
desc.insert({callbacks.size(), "login_web: 登陆网站"});
callbacks.push_back(login_web);
desc.insert({callbacks.size(), "cal_sql: 调用数据库"});
callbacks.push_back(cal_sql);
desc.insert({callbacks.size(), "save_sql: 保存数据库"});
callbacks.push_back(save_sql);
}
void showHandler()
{
for(const auto &iter : desc )
{
std::cout << iter.first << "\t" << iter.second << std::endl;
}
}
int handlerSize()
{
return callbacks.size();
}
typedef std::function<void()> func;:这行代码定义了一个函数类型别名func,它表示一个没有参数和没有返回值的函数。std::vector<func> callbacks;:这是一个std::vector,用于存储回调函数。每个元素都是一个函数对象,表示一个回调函数。std::unordered_map<int, std::string> desc;:这是一个无序映射,用于存储回调函数的描述。它将回调函数的索引(在callbacks中的位置)映射到相应的描述字符串。void register_web(),void login_web(),void cal_sql(),void save_sql():这些是实际的回调函数,每个函数执行不同的操作,并在标准输出中打印相应的消息,指示它们的操作。void load():load函数用于初始化回调函数和它们的描述,将它们添加到callbacks和desc中。每个回调函数在添加到callbacks时都会分配一个唯一的索引,这个索引也用于关联到描述。void showHandler():showHandler函数用于显示所有回调函数的描述和它们的索引。int handlerSize():handlerSize函数返回callbacks中回调函数的数量。
主文件的建立
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <cassert>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include "task.hpp"
#define PROCESS_NUM 5
using namespace std;
int waitCommand(int waitFd, bool &quit) //如果不发,就阻塞
{
uint32_t command = 0;
ssize_t s = read(waitFd, &command, sizeof(command));
if (s == 0)
{
quit = true;
return -1;
}
assert(s == sizeof(uint32_t));
return command;
}
void sendAndWakeup(pid_t who, int fd, uint32_t command)
{
write(fd, &command, sizeof(command));
cout << "main process: call process " << who << " execute " << desc[command] << " through " << fd << endl;
}
int main()
{
load();
vector<pair<pid_t, int>> slots;
// 先创建多个进程
for (int i = 0; i < PROCESS_NUM; i++)
{
// 创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0);
(void)n;
pid_t id = fork();
assert(id != -1);
// 子进程进行读取
if (id == 0)
{
// 关闭写端
close(pipefd[1]);
// child
while (true)
{
// 等命令
bool quit = false;
int command = waitCommand(pipefd[0], quit); //如果不发,就阻塞
if (quit)
break;
// 执行对应的命令
if (command >= 0 && command < handlerSize())
{
callbacks[command]();
}
else
{
cout << "非法command: " << command << endl;
}
}
exit(1);
}
// father,进行写入,关闭读端
close(pipefd[0]);
slots.push_back(pair<pid_t, int>(id, pipefd[1]));
}
// 父进程派发任务
srand((unsigned long)time(nullptr) ^ getpid() ^ 23323123123L); // 让数据源更随机
while (true)
{
// 选择一个任务, 如果任务是从网络里面来的?
int command = rand() % handlerSize();
// 选择一个进程 ,采用随机数的方式,选择进程来完成任务,随机数方式的负载均衡
int choice = rand() % slots.size();
// 把任务给指定的进程
sendAndWakeup(slots[choice].first, slots[choice].second, command);
sleep(1);
}
// 关闭fd, 所有的子进程都会退出
for (const auto &slot : slots)
{
close(slot.second);
}
// 回收所有的子进程信息
for (const auto &slot : slots)
{
waitpid(slot.first, nullptr, 0);
}
}
- 定义了常量
PROCESS_NUM,它表示要创建的子进程的数量。 waitCommand函数:- 这个函数用于从管道中读取命令,并将命令存储在
command变量中。 - 如果成功读取命令,函数返回命令的值。如果读取到的是 EOF(管道的写端已关闭),则函数将设置
quit为true,表示退出。 - 这个函数主要用于在子进程中等待从父进程发送的命令,如果没有命令可读,它将阻塞等待。
- 这个函数用于从管道中读取命令,并将命令存储在
sendAndWakeup函数:- 这个函数用于将命令发送到指定子进程的管道中,并唤醒子进程来执行命令。
- 函数接受子进程的 PID(who)、管道的文件描述符(fd)以及要执行的命令(command)作为参数。
- 函数通过
write向管道写入命令,然后在标准输出上打印消息,表示主进程正在调用子进程执行命令。
main函数:load()函数被调用,其中包括回调函数的注册和初始化。- 创建了一个
vector类型的容器slots,用于存储子进程的 PID 和管道的写端文件描述符。 - 使用一个
for循环,创建了PROCESS_NUM个子进程。每个子进程都有一个管道,一个用于读取命令,另一个用于写入命令。 - 在子进程中,使用
waitCommand函数等待从父进程发送的命令,并执行相应的回调函数。如果命令是退出命令,子进程退出。 - 在父进程中,通过随机数选择一个任务,然后通过
sendAndWakeup函数将任务发送给一个随机选择的子进程,以实现任务派发和负载均衡。 - 最后,父进程关闭所有管道,等待所有子进程退出,确保资源被释放。
执行结果
main process: call process 11485 execute cal_sql: 调用数据库 through 6
sub process[11485 ] 调用数据库
main process: call process 11487 execute register_web: 注册网站 through 8
sub process[11487 ] 注册网站
main process: call process 11483 execute register_web: 注册网站 through 4
sub process[11483 ] 注册网站
main process: call process 11484 execute save_sql: 保存数据库 through 5
sub process[11484 ] 保存数据库
main process: call process 11483 execute cal_sql: 调用数据库 through 4
sub process[11483 ] 调用数据库
main process: call process 11485 execute login_web: 登陆网站 through 6
sub process[11485 ] 登录网站
main process: call process 11487 execute login_web: 登陆网站 through 8
sub process[11487 ] 登录网站
main process: call process 11487 execute register_web: 注册网站 through 8
sub process[11487 ] 注册网站
......
5. 管道读写规则
- 当没有数据可读时:
- 如果
O_NONBLOCK未启用(O_NONBLOCK disable),read调用将阻塞,即进程会一直等待,直到管道中有数据可读取为止。 - 如果
O_NONBLOCK启用(O_NONBLOCK enable),read调用将立即返回-1,同时errno的值将被设置为EAGAIN,表示没有数据可读。
- 如果
- 当管道已满时:
- 如果
O_NONBLOCK未启用(O_NONBLOCK disable),write调用将阻塞,直到有进程从管道中读取数据,腾出足够的空间。 - 如果
O_NONBLOCK启用(O_NONBLOCK enable),write调用将立即返回-1,同时errno的值将被设置为EAGAIN,表示管道已满。
- 如果
- 如果所有管道写端对应的文件描述符被关闭,
read返回0:- 当所有与管道相关的写端文件描述符被关闭后,
read调用将返回0,表示已达到文件结束(EOF)状态。这表明不会再有数据写入管道。
- 当所有与管道相关的写端文件描述符被关闭后,
- 如果所有管道读端对应的文件描述符被关闭,
write操作可能会产生信号SIGPIPE:- 当所有与管道相关的读端文件描述符被关闭后,
write操作可能会产生SIGPIPE信号。这是因为写入数据没有接收方,因此内核会向写进程发送SIGPIPE信号,通常会导致写进程终止。这可以用来处理管道通信中的异常情况。
- 当所有与管道相关的读端文件描述符被关闭后,
- 原子性写入:
- 当要写入的数据量不大于
PIPE_BUF时,Linux 将保证写入是原子性的。这意味着写入操作要么完全成功,要么完全失败,不会出现部分写入的情况。PIPE_BUF的值可以通过pathconf或_PC_PIPE_BUF获取,通常情况下为4096字节。 - 如果要写入的数据量大于
PIPE_BUF,Linux将不再保证写入的原子性,可能会出现部分写入的情况,这需要编程时进行适当的处理。
- 当要写入的数据量不大于
6. 管道特点
- 管道通信限制:
- 管道通常用于具有共同祖先的进程之间,这意味着它们是亲缘关系的进程。通常,一个管道由一个进程创建,然后通过
fork调用创建的父进程和子进程之间可以使用该管道进行通信。
- 管道通常用于具有共同祖先的进程之间,这意味着它们是亲缘关系的进程。通常,一个管道由一个进程创建,然后通过
- 管道提供流式服务:
- 管道提供的是流式服务,这意味着数据以流的方式传输。数据进入管道的一端,然后从另一端流出。这种特性使得它适用于需要连续流式数据传输的场景,比如进程之间的数据管道。
- 管道的生命周期:
- 一般情况下,管道的生命周期与创建它的进程相关。当创建管道的进程退出时,管道也会被释放。这意味着管道通常不会长时间存在,而是在父进程和子进程之间传递数据后被销毁。
- 内核的同步与互斥:
- 管道的操作通常由内核进行同步和互斥控制。这确保了多个进程能够正确地读取和写入管道,而不会发生数据混乱或竞争条件。
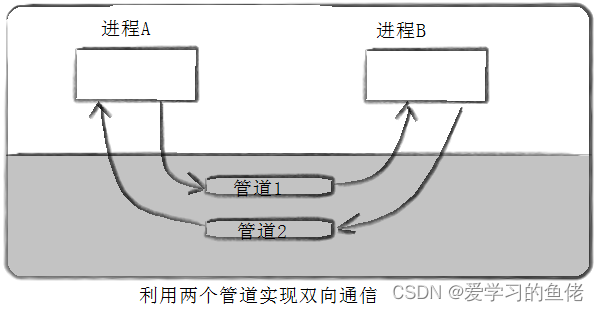
- 管道的半双工性质:
- 管道是半双工的,这意味着数据只能在一个方向上流动。一端用于写入数据,另一端用于读取数据。如果需要双向通信,通常需要建立两个管道,一个用于每个方向的数据传输。