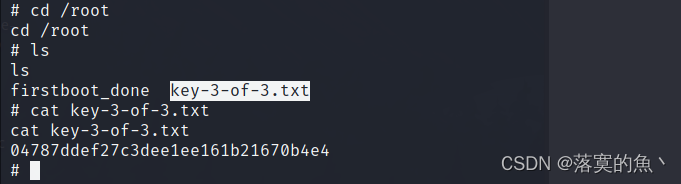
相关代码参考:https://gitcode.net/coloreaglestdio/qtcpp_demo/-/tree/master/qt_event_signal
1.问题的由来
在对 taskBus 进行低延迟改造时,避免滥用信号与槽起到了较好的作用。笔者在前一篇文章中,叙述了通过避免广播式地播发信号,以及频繁的 new 与 delete 来提高软件无线电(SDR)平台的吞吐。近期,考虑到跨线程异步操作其实事件(QEvent)可能更加适合点对点的调用,遂把taskBus的主数据流转使用 Events 进行了改造,收到了大概5-10ms的提升。
这个提升还是没有达到我的期望,因为印象里,信号与槽是非常慢的。那么,问题来了,跨线程 Signal&Slots 与 Events 到底谁要快,为什么快,以及快多少呢?
2. 回顾“信号槽很慢”的印象的源头
在经典的Qt文档里,有一段对信号与槽性能选择的性能描述:
Compared to callbacks, signals and slots are slightly slower because of the
increased flexibility they provide, although the difference for real applications
is insignificant. In general, emitting a signal that is connected to some slots,
is approximately ten times slower than calling the receivers directly, with
non-virtual function calls.
“与回调相比,信号和插槽的速度稍慢,因为它们提供了更大的灵活性,尽管实际应用程序的差异并不显著。通常,发射连接到某些插槽的信号比直接调用接收器(使用非虚拟函数调用)慢大约十倍。”
这就是印象的源头了。不过,带着上述问题,仔细阅读,发现还有更多的解释:
This is the overhead required to locate the connection
object, to safely iterate over all connections (i.e. checking that subsequent
receivers have not been destroyed during the emission), and to marshall any
parameters in a generic fashion. While ten non-virtual function calls may sound
like a lot, it's much less overhead than any new or delete operation, for example.
As soon as you perform a string, vector or list operation that behind the scene
requires new or delete, the signals and slots overhead is only responsible for a
very small proportion of the complete function call costs. The same is true
whenever you do a system call in a slot; or indirectly call more than ten
functions. The simplicity and flexibility of the signals and slots mechanism is well worth the overhead, which your users won't even notice.
“这是定位连接对象、安全地迭代所有连接(即检查后续接收器在发射过程中是否未被破坏)以及以通用方式整理任何参数所需的开销。虽然十个非虚拟函数调用听起来可能很多,但它的开销比任何new操作或delete操作都要小得多。一旦执行了一个字符串、向量或列表操作,而该操作在后台需要新建或删除,则信号和插槽开销只占整个函数调用成本的一小部分。每当您在插槽中进行系统调用时,情况也是如此;或者间接调用十多个函数。信号和插槽机制的简单性和灵活性非常值得开销,而您的用户甚至不会注意到这一点。”
会不会,上次的优化起到关键作用的不是信号与槽改成了直接函数调用,而是把频繁new delete换成静态内存导致的提升?我立刻进行了测试,发现的确如此。
- new 和 delete的开销远远大于 signal&slots的开销
3. 编程进行专门测试
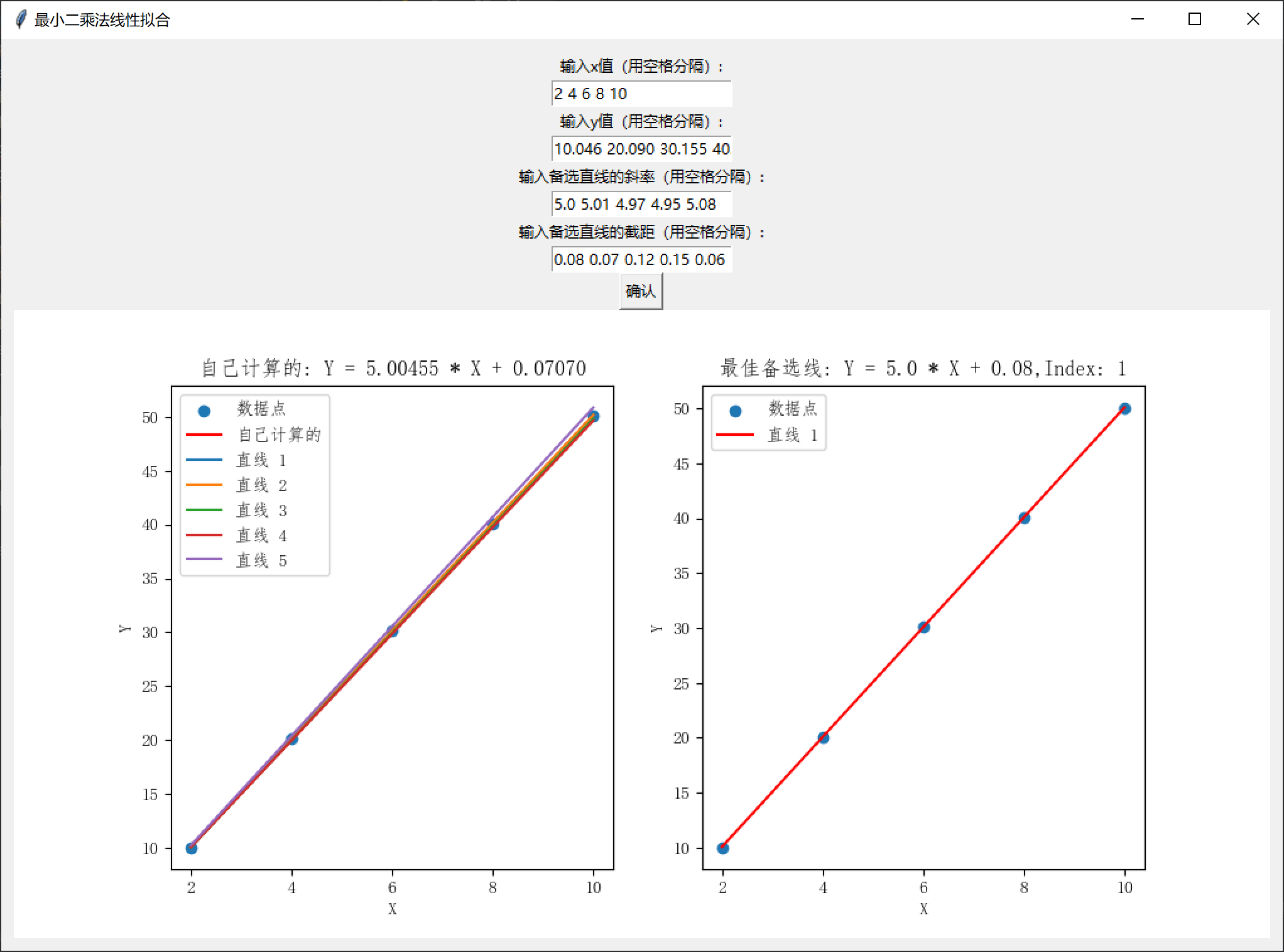
我们使用Qt专门对信号与槽、事件这两种跨线程传递消息的方法来进行测试。设计测试由两个对象之间互相以最快速度乒乓消息为场景,如下图所示:
含有时戳的消息,可以用来计算和统计平均延迟(消息生成和被处理的时差),以及最终的处理能力。
测试分为信号-槽测试,事件测试,以及单线程对比调用测试。测试进行10000次调用,并模拟实际程序对传递的消息进行一些处理,如产生一定长度的字符串。
通过观察不同长度下的开销,即可直挂感受消息传递开销与处理开销的占比。
3.1 用于测试的消息体
消息体既用于信号与槽测试,也用于Event测试以及直接调用。这样参数中都直接new消息,对大家是公平的。
testevent.h---------------
#include <QEvent>
#include <time.h>
#include <QString>
class TestMsg : public QEvent
{
private:
static QEvent::Type m_testEvt;
static QEvent::Type m_startEvt;
static QEvent::Type m_startSig;
static QEvent::Type m_quit;
clock_t m_clk = 0;
QString m_dummyLongStr;
public:
TestMsg(clock_t clk);
~TestMsg();
inline clock_t clock() {return m_clk;}
inline void fillStr(int len)
{
for (int i=0;i<len;++i)
{
m_dummyLongStr.push_back((char)(i*37%64+32));
}
}
public:
static inline QEvent::Type type() {return m_testEvt;}
static inline QEvent::Type startEvt() {return m_startEvt;}
static inline QEvent::Type startSig() {return m_startSig;}
static inline QEvent::Type quitEvt() {return m_quit;}
};
//testevent.cpp---------------
#include "testevent.h"
#include <QDebug>
//Regisit a event
QEvent::Type TestMsg::m_testEvt = (QEvent::Type)QEvent::registerEventType();
QEvent::Type TestMsg::m_startEvt = (QEvent::Type)QEvent::registerEventType();
QEvent::Type TestMsg::m_startSig = (QEvent::Type)QEvent::registerEventType();
QEvent::Type TestMsg::m_quit = (QEvent::Type)QEvent::registerEventType();
TestMsg::TestMsg(clock_t clk)
:QEvent(m_testEvt)
,m_clk(clk)
{
}
TestMsg::~TestMsg()
{
}
消息体含有一个clock时戳,用于计算传递耗时。同时,有一个fillStr的耗时操作,用于模拟真实的有效数据处理。
3.2 测试对象
测试对象直接派生自 QObject,将在线程中执行测试。为了模拟信号与槽的 meta 开销,设置了26组信号与槽,进行交叉连接,并用第16组进行测试。
#ifndef TESTOBJ_H
#define TESTOBJ_H
#include <QObject>
#include <QEvent>
#include "testevent.h"
class TestObj : public QObject
{
Q_OBJECT
public:
explicit TestObj(QObject *parent = nullptr);
void setBuddy(TestObj * buddy) {
m_buddy = buddy;
buddy->m_buddy = this;
}
void runDirectCall();
public slots:
void test_slot1(QEvent * evt){}
//...
void test_slot16(QEvent * evt);
//...
void test_slot26(QEvent * evt){}
signals:
void test_sig1(QEvent * evt);
//...
void test_sig26(QEvent * evt);
void evt_finished();
void sig_finished();
protected:
void customEvent(QEvent *) override;
private:
clock_t m_nFirstClkSig = -1;
quint32 m_nCount_Sigs = 0;
clock_t m_nFirstClkEvt = -1;
quint32 m_nCount_Evts = 0;
clock_t m_nFirstClkDir = -1;
quint32 m_nCount_Dir = 0;
private:
TestObj * m_buddy = nullptr;
private:
void run_signal();
void run_event();
private:
void direct_call(QEvent * evt);
};
#endif // TESTOBJ_H
无论以何种接口获得 TestMsg,都执行相同的操作:
//以信号槽为例
void TestObj::test_slot16(QEvent * evt)
{
clock_t curr_clk = clock();
if (m_nFirstClkSig==-1)
m_nFirstClkSig = curr_clk;
TestMsg * e = dynamic_cast<TestMsg *>(evt);
if (e)
{
++m_nCount_Sigs;
e->fillStr(fillStrLen);
if (m_nCount_Sigs==testCounts)
{
QTextStream strm(stdout);
strm << objectName()<< QString().asprintf(" (%llX) run %d Signals, total costs %.2lf ms, AVG cost %.2lf us / test.\n"
,(unsigned long long)this
,(int)(m_nCount_Sigs)
,1e3 * (curr_clk - m_nFirstClkSig) / CLOCKS_PER_SEC
,1e6 * (curr_clk - m_nFirstClkSig) / CLOCKS_PER_SEC / testCounts
);
strm.flush();
emit sig_finished();
}
delete e;
}
}
void TestObj::run_signal()
{
for (int i=0;i<testCounts;++i)
emit test_sig16(new TestMsg(clock()));
}
3.3 测试方法
在 main函数中进行测试:
#include <QCoreApplication>
#include <QThread>
#include "testevent.h"
#include "testobj.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
clock_t clk_start = clock();
printf("StartClk = %d\n",clk_start);
QThread::msleep(100);
QThread * thread1 = new QThread;
QThread * thread2 = new QThread;
TestObj * obj1 = new TestObj;
TestObj * obj2 = new TestObj;
obj1->setObjectName("OBJ1");
obj2->setObjectName("OBJ2");
obj1->setBuddy(obj2);
obj1->connect(obj1,&TestObj::test_sig1,obj2,&TestObj::test_slot16,Qt::QueuedConnection);
//...
obj1->connect(obj1,&TestObj::test_sig26,obj2,&TestObj::test_slot16,Qt::QueuedConnection);
obj1->connect(obj2,&TestObj::test_sig16,obj1,&TestObj::test_slot1,Qt::QueuedConnection);
//...
obj1->connect(obj2,&TestObj::test_sig16,obj1,&TestObj::test_slot26,Qt::QueuedConnection);
obj1->moveToThread(thread1);
obj2->moveToThread(thread2);
thread1->start();
thread2->start();
printf("Test signals & slots, Events...\n");
QCoreApplication::processEvents();
a.connect (obj1,&TestObj::sig_finished,[=]()->void{
QThread::msleep(1000);
QCoreApplication::postEvent(obj1,new QEvent(TestMsg::startEvt()));
});
a.connect (obj2,&TestObj::sig_finished,[=]()->void{
QThread::msleep(1000);
QCoreApplication::postEvent(obj2,new QEvent(TestMsg::startEvt()));
});
a.connect (obj1,&TestObj::evt_finished,[=]()->void{
QThread::msleep(1000);
QCoreApplication::postEvent(obj1,new QEvent(TestMsg::quitEvt()));
});
a.connect (obj2,&TestObj::evt_finished,[=]()->void{
QThread::msleep(1000);
QCoreApplication::postEvent(obj2,new QEvent(TestMsg::quitEvt()));
});
QThread::msleep(1000);
QCoreApplication::processEvents();
QCoreApplication::postEvent(obj1,new QEvent(TestMsg::startSig()));
QCoreApplication::postEvent(obj2,new QEvent(TestMsg::startSig()));
a.processEvents();
thread1->wait();
thread2->wait();
QThread::msleep(2000);
obj1->runDirectCall();
printf("Finished.\n");
thread1->deleteLater();
thread2->deleteLater();
obj1->deleteLater();
obj2->deleteLater();
QThread::msleep(1000);
QCoreApplication::processEvents();
return 0;
}
4. 测试结果
测试环境:i7 10代 win11 Mingw64 Qt6.6
4.1 Debug, Strlen=0,20000次
StartClk = 2
Test signals & slots, Events...
OBJ1 (1AD52AD73E0) run 20000 Signals, total costs 2089.00 ms, AVG cost 104.45 us / test.
OBJ2 (1AD52AD74C0) run 20000 Signals, total costs 32.00 ms, AVG cost 1.60 us / test.
OBJ2 (1AD52AD74C0) run 20000 Events, total costs 14.00 ms, AVG cost 0.70 us /test.
OBJ1 (1AD52AD73E0) run 20000 Events, total costs 27.00 ms, AVG cost 1.35 us /test.
Test Direct Call...
OBJ1 (1AD52AD73E0) run 20000 Direct Calls, total costs 6.00 ms, AVG cost 0.30 us / test.
Finished.
4.2 Debug, Strlen=1000,20000次
StartClk = 2
Test signals & slots, Events...
OBJ1 (21AFB83BBA0) run 20000 Signals, total costs 2541.00 ms, AVG cost 127.05 us / test.
OBJ2 (21AFB83B820) run 20000 Signals, total costs 1630.00 ms, AVG cost 81.50 us / test.
OBJ2 (21AFB83B820) run 20000 Events, total costs 1373.00 ms, AVG cost 68.65 us /test.
OBJ1 (21AFB83BBA0) run 20000 Events, total costs 1403.00 ms, AVG cost 70.15 us /test.
Test Direct Call...
OBJ1 (21AFB83BBA0) run 20000 Direct Calls, total costs 1377.00 ms, AVG cost 68.85 us / test.
Finished.
4.3 Release, Strlen=0,100000次
StartClk = 5
Test signals & slots, Events...
OBJ1 (294D24BB5F0) run 100000 Signals, total costs 2236.00 ms, AVG cost 22.36 us / test.
OBJ2 (294D24BB930) run 100000 Signals, total costs 25.00 ms, AVG cost 0.25 us / test.
OBJ2 (294D24BB930) run 100000 Events, total costs 12.00 ms, AVG cost 0.12 us /test.
OBJ1 (294D24BB5F0) run 100000 Events, total costs 38.00 ms, AVG cost 0.38 us /test.
Test Direct Call...
OBJ1 (294D24BB5F0) run 100000 Direct Calls, total costs 14.00 ms, AVG cost 0.14 us / test.
Finished.
4.4 Release, Strlen=1000,100000次
StartClk = 4
Test signals & slots, Events...
OBJ1 (154799851A0) run 100000 Signals, total costs 1358.00 ms, AVG cost 13.58 us / test.
OBJ2 (154799854E0) run 100000 Signals, total costs 620.00 ms, AVG cost 6.20 us / test.
OBJ2 (154799854E0) run 100000 Events, total costs 543.00 ms, AVG cost 5.43 us /test.
OBJ1 (154799851A0) run 100000 Events, total costs 547.00 ms, AVG cost 5.47 us /test.
Test Direct Call...
OBJ1 (154799851A0) run 100000 Direct Calls, total costs 527.00 ms, AVG cost 5.27 us / test.
Finished.
5. 结果分析
可以看见,
- Release下,Event 和 直接调用的性能几乎完全一样。Debug下略慢。
- Release下,如果发射的信号只对应一个槽,则比直接调用的性能稍微差一些,但远没有10倍的差距,比如Obj2发射的某个信号,只连接到Obj1 的1个槽,其实区别不大。
- Release下,如果发射的信号对应多个槽,则性能显著下降,正如obj1发射的一个信号,连接到多个槽,结果就很耗时。发射的信号会给每个槽都走一遭。
- 如果存在大量的new\delete,则无论何方式,区别都不大。new/delete非常耗时。
6. 开发建议
对于密集的点对点异步调用,显然是Event比较好。如果是广播性质的多对多,Event需要循环,则使用信号与槽会利于开发。此外信号与槽会自动维护双方的可用性,在目的析构后不再调用槽。Events因为要给入指针,则必须自己确保指针的有效性。
提高速度的关键还是使用静态内存,避免频繁new、delete。
7. 改进效果
taskBus的异步调用最后一步队列操作,使用Event而不是信号,来通知线程干活,只获得了大概10ms的延迟优化,是因为大部分延迟实际是在缓存、滤波器上,并不在信号-槽中。使用了QEvent后,构造的全通无线网络,在 128kbps的带宽下,还是要稍微顺畅一些。