CUDA Libraries简介

上图是CUDA 库的位置,本文简要介绍cuSPARSE、cuBLAS、cuFFT和cuRAND,之后会介绍OpenACC。
- cuSPARSE线性代数库,主要针对稀疏矩阵之类的。
- cuBLAS是CUDA标准的线代库,不过没有专门针对稀疏矩阵的操作。
- cuFFT傅里叶变换
- cuRAND随机数
CUDA库和CPU编程所用到的库没有什么区别,都是一系列接口的集合,主要好处是,只需要编写host代码,调用相应API即可,可以节约很多开发时间。而且我们完全可以信任这些库能够达到很好的性能,写这些库的人都是在CUDA上的大能,一般人比不了。当然,完全依赖于这些库而对CUDA性能优化一无所知也是不行的,我们依然需要手动做一些改进来挖掘出更好的性能。
下图是《CUDA C编程》中提到的一些支持的库,具体细节可以在NVIDIA开发者论坛查看:
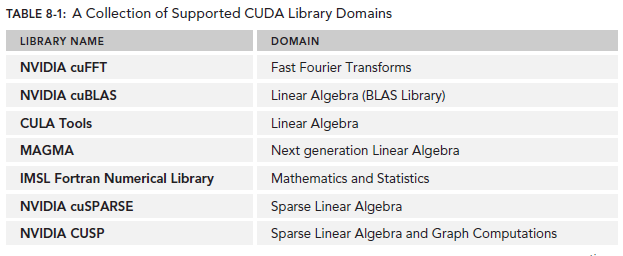
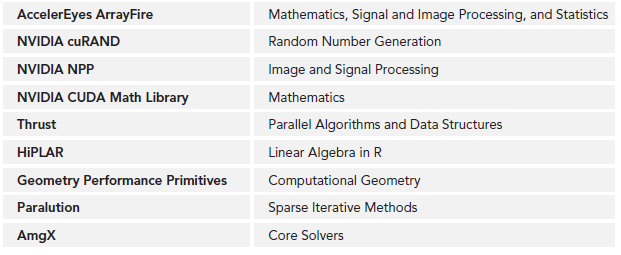
如果大家的APP属于上面库的应用范围,非常建议大家使用。
A Common Library Workflow
下面是一个使用CUDA库的具体步骤,当然,各个库的使用可能不尽相同,但是不会逃脱下面的几个步骤,差异基本上就是少了哪几步而已。
- 创建一个库的句柄来管理上下文信息。
- 分配device存储空间给输入输出。
- 如果输入的格式并不是库中API支持的需要做一下转换。
- 填充device Memory数据。
- 配置library computation以便执行。
- 调用库函数来让GPU工作。
- 取回device Memory中的结果。
- 如果取回的结果不是APP的原始格式,就做一次转换。
- 释放CUDA资源。
- 继续其它的工作。
下面是这几个步骤的一些细节解释:
Stage1:Creating a Library Handle
CUDA库好多都有一个handle的概念,其包含了该库的一些上下文信息,比如数据格式、device的使用等。对于使用handle的库,我们第一步就是初始化这么一个东西。一般的,我们可以认为这是一个存放在host对程序员透明的object,这个object包含了跟这个库相关联的一些信息。例如,我们可定希望所有的库的操作运行在一个特别的CUDA stream,尽管不同的库使用不同函数名字,但是大多数都会规定所有的库操作以一定的stream发生(比如cuSPARSE使用cusparseSetSStream、cuBLAS使用cublasSetStream、cuFFT使用cufftSetStream)。stream的信息就会保存在这个handle中。
Stage2:Allocating Device Memory
本文所讲的库,其device存储空间的分配依然是cudaMalloc或者库自己调用cudaMalloc。只有在使用多GPU编程的库时,才会使用一些定制的API来实现内存分配。
Stage3:Converting Inputs to a Library-Supported Format
如果APP的数据格式和库要求的输入格式不同的话,就需要做一次转化。比如,我们APP存储一个row-major的2D数组,但是库却要求一个column-major,这就需要做一次转换了。为了最优性能,我们应该尽量避免这种转化,也就是尽量和库的格式保持一致。
Stage4:Populating Device Memory with Inputs
完成上述三步后,就是将host的数据传送到device了,也就是类似cudaMemcpy的作用,之所说类似,是引文大部分库都有自己的API来实现这个功能,而不是直接调用cudaMemcpy。例如,当使用cuBLAS的时候,我们要将一个vector传送到device,使用的就是cubalsSetVector,当然其内部还是调用了cudaMemcpy或者其他等价函数来实现传输。
Stage5:Configuring the Library
有步骤3知道,数据格式是个明显的问题,库函数需要知道自己应该使用什么数据格式。某些情况下,类似数据维度之类的数据格式信息会直接当做函数参数配置,其它的情形下,就需要手动来配置下之前说的库的handle了。还有个别情况是,我们需要管理一些分离的元数据对象。
Stage6:Executing
执行就简单多了,做好之前的步骤,配置好参数,直接调用库API。
Stage7:Retrieving Results from Device Memory
这一步将计算结果从device送回host,当然还是需要注意数据格式,这一步就是步骤4的反过程。
Stage8:Converting Back to Native Format
如果计算结果和APP的原始数据格式不同,就需要做一次转化,这一步是步骤3的反过程。
Stage9:Releasing CUDA Resources
如果上面步骤使用的内存资源不再使用就需要释放掉,正如我们以前介绍的那样,内存的分配和释放是非常大的负担,所以希望尽可能的资源重用。比如device Memory、handles和CUDA stream这些资源。
Stage10:Continuing with the Application
继续干别的。
再次重申,上面的步骤可能会给大家使用库是非常麻烦低效的事儿,但其实这些步骤一般是冗余的,很多情况下,其中的很多步骤是不必要的,在下面的章节我们会介绍几个主要的库以及其简要使用,相信看过后,你就不会认为使用库得不偿失了。
THE CUSPARSE LIBRARY
cuSPARSE就是一个线性代数库,对稀疏矩阵之类的操作尤其独到的用法,使用很宽泛。他当对稠密和稀疏的数据格式都支持。
下图是该库的一些函数调用,从中可以对其功能有一个大致的了解。cuSPARSE将函数以level区分,所有level 1的function仅操作稠密和稀疏的vector。所有level2函数操作稀疏矩阵和稠密vector。所有level3函数操作稀疏和稠密矩阵。
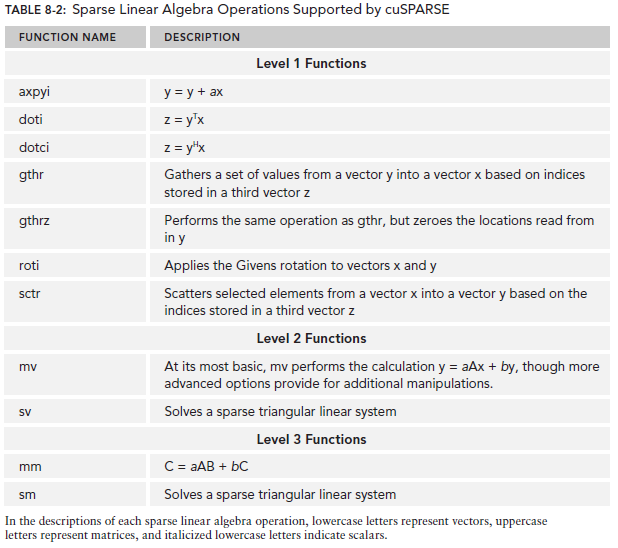
cuSPARSE Data Storage Formats
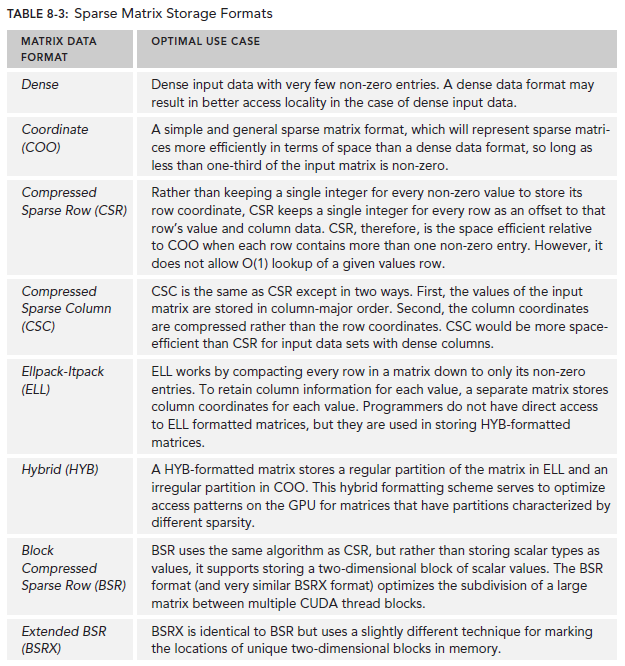
稠密矩阵就是其中的值大部分非零。稠密矩阵所有值都是存储在一个多维的数组中的。相对而言,稀疏矩阵和vector中元素主要是零,所以其存储就可以做一些文章。比如我们可以仅仅保存非零值和其坐标。cuSPARSE支持很多种稀疏矩阵的存储方式,本文只介绍其中三种。
先看一下稠密(dens)矩阵的存储方式,图示很明显,不多说了:
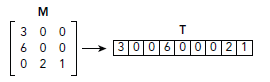
Coordinate(COO)
对于稀疏矩阵中的每个非零值,COO方式都保存其行和列坐标,因此,当通过行列检索矩阵值的时候,如果该行列值没有在存储格式中匹配到的话,必然就是零了。
我们应该注意到了,所谓稀疏矩阵要稀疏到什么程度才能使用COO呢?这个需要具体问题具体分析了,主要跟元素数据类型和索引数据类型有关。比如,一个存储32-bit的浮点类型数据的稀疏矩阵,索引使用32-bit的整型格式,那么只有当非零数据少于于矩阵的三分之一的时候才会节约存储空间。
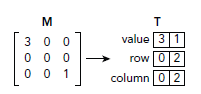
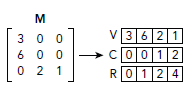
Compressed Sparse Row(CSR)
CSR和COO相似,唯一不同就是非零值的行索引。COO模式下,所有非零值都会对应一个int的行索引,而CSR则是存储一个偏移值,这个偏移值是所有属于同一行的值拥有的属性。如下图所示,相比COO,减少了row:
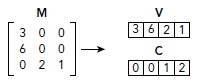
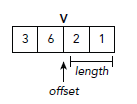
因为所有存储在同一行的数据在内存中是相邻的,要找到某一行对应的值只需要一个偏移量和length。例如,如果只想知道第三行的非零值,我们可以使用偏移量为2,length为2在V中检索,如下图所示:
对图中的C使用相同的偏移和length就能定位列索引,也就能完全确定一个value在矩阵中的位置。当存储一个很大的矩阵且相对来说每行数据都很多的时候,使用CSR比存储每个非零值的索引要有效得多。
现在我们要考虑这些偏移地址和length的存储了,最简单的方式是创建两个数组Ro和Rl,每个都对应一个nRows用作length。如果矩阵有大量的行就需要分配两个很大的数组。鉴于此,我们可以使用单独的一个length为nRows+1的数组R,第i行的偏移地址就存储在R[i]。第i行的长度可以通过比较R[I+1]和R[i]值来做出判断,还有就是R[i+1]是用来存储矩阵非零值的总数的。本例中R数组如下:
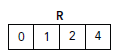
由上图知,0行的偏移地址是0,1行偏移地址是1,2行偏移地址是2,共有4个非零元素,我们可以找矩阵行为0的值及其列索引,由于R[1]-R[0]=1-0=1,说明第一行仅有一个非零值,其列索引为0,其值为3。
这样,对于每行都有多个非零值的稀疏矩阵存储,CSR比COO要节约空间。下图是CSR的完整示意图:
使用CSR格式稀疏矩阵的function很直观,首先,我们在host定义一个CSR格式的稀疏矩阵,其代码如下:
float *h_csrVals; int *h_csrCols; int *h_csrRows;
h_csrVals用来存储非零值个数,h_csrCols存储列索引,h_csrRows存储行偏移,接下来就是分配device内存之类的常规操作:
cudaMalloc((void **)&d_csrVals, n_vals * sizeof(float)); cudaMalloc((void **)&d_csrCols, n_vals * sizeof(int)); cudaMalloc((void **)&d_csrRows, (n_rows + 1) * sizeof(int)); cudaMemcpy(d_csrVals, h_csrVals, n_vals * sizeof(float),cudaMemcpyHostToDevice); cudaMemcpy(d_csrCols, h_csrCols, n_vals * sizeof(int),cudaMemcpyHostToDevice); cudaMemcpy(d_csrRows, h_csrRows, (n_rows + 1) * sizeof(int),cudaMemcpyHostToDevice);
上述三种(包括稠密矩阵)数据格式各有各擅长的方面。下图列出了cuSPARSE支持的一些数据格式以及各自的最佳使用场景:
Formatting Conversion with cuSPARSE
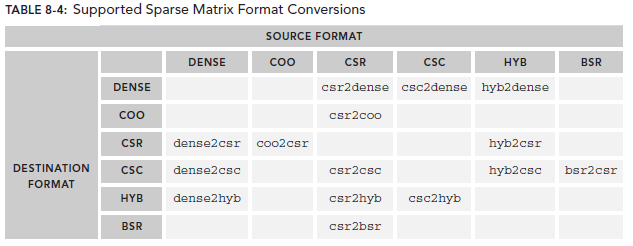
从前文可知,这个过程应该尽量避免,转换不仅需要有计算的开销,还有额外存储的空间浪费。还有就是在使用cuSPARSE也应该尽量发挥其在稀疏矩阵存储上的优势,因为好多APP的latency就是仅仅简单的使用稠密矩阵存储方式。因为cuSPARSE的数据格式众多,其用来转换的API也不少,下图列出了这些转换API。左边那一列是你要转换的目标格式,为空表示不支持两种数据格式的转换,尽管如此,你还可以通过多次转换来实现未显示支持的转换API,比如dense2bsr没有被支持,但是我们可以使用dense2csr和csr2bsr两个过程来达到目的。
Demonstrating cuSPARSE
这部分示例代码会涉及到矩阵向量相乘,数据格式转换,以及其他cuSPARSE的特征。
![]()
// Create the cuSPARSE handle cusparseCreate(&handle); // Allocate device memory for vectors and the dense form of the matrix A ... // Construct a descriptor of the matrix A cusparseCreateMatDescr(&descr); cusparseSetMatType(descr, CUSPARSE_MATRIX_TYPE_GENERAL); cusparseSetMatIndexBase(descr, CUSPARSE_INDEX_BASE_ZERO); // Transfer the input vectors and dense matrix A to the device ... // Compute the number of non-zero elements in A cusparseSnnz(handle, CUSPARSE_DIRECTION_ROW, M, N, descr, dA,M, dNnzPerRow, &totalNnz); // Allocate device memory to store the sparse CSR representation of A ... // Convert A from a dense formatting to a CSR formatting, using the GPU cusparseSdense2csr(handle, M, N, descr, dA, M, dNnzPerRow,dCsrValA, dCsrRowPtrA, dCsrColIndA); // Perform matrix-vector multiplication with the CSR-formatted matrix A cusparseScsrmv(handle, CUSPARSE_OPERATION_NON_TRANSPOSE,M, N, totalNnz, &alpha, descr, dCsrValA, dCsrRowPtrA,dCsrColIndA, dX, &beta, dY); // Copy the result vector back to the host cudaMemcpy(Y, dY, sizeof(float) * M, cudaMemcpyDeviceToHost);
![]()
上述代码的过程可以总结为:
- 使用cusparseCreate创建库的handle。
- 使用cudaMalloc分配device内存空间用来存储矩阵和向量,并分别使用dense和CSR两种格式存储。
- cusparseCreateMatDescr和cusparseSetMat*使用来配置矩阵属性的,cudaMemcpy用来拷贝数据到device,cusparseSdense2csr来生成CSR格式的数据,非零数据个数有cusparseSnnz计算得到。
- cusparseScsrmv是矩阵和向量乘操作函数。
- 再次使用cudaMemcpy将结果拷贝回host。
- 释放资源。
编译:
$ nvcc -lcusparse cusparse.cu –o cusparse
Important Topics in cuSPARSE Development
尽管cuSPARSE提供了一个相对来说最快速和简洁的方式以达到高性能的线性代数库,我们仍需要谨记cuSPARSE使用的一些关键点。
第一点就是,要保证正确的矩阵和向量的数据格式,cuSPARSE本身没有什么能力来检测出错误的或者不恰当的数据格式,而一次错误的格式操作就可能导致段错误,这也算是给自己debug提供一种方向吧,虽然段错误五花八门。对于矩阵和向量规模比较小的情况下,手动验证其数据格式还是可行的。我们可以将转换后的数据进行一次逆转换过程来和原始数据比对。
第二点是cuSPARSE的默认异步行为。当然这对于GPU编程来说,已经习以为常了,但是对于传统的host端阻塞式的数学库来说,GPU的计算结果会很有趣。对于cuSPARSE来说,如果使用了cudaMemcpy拷贝数据后,host会自动阻塞住,等待device的计算结果。但是如果cuSPARSE库被配置来使用CUDA steam和cudaMemcpyAsync,我们就需要多留一个心眼,使用确保正确的同步行为来获取device的计算结果。
最后一点比较新奇的是标量的使用,这里要使用标量的引用形式。如下代码中的beta变量:
float beta = 4.0f; ... // Perform matrix-vector multiplication with the CSR-formatted matrix A cusparseScsrmv(handle, CUSPARSE_OPERATION_NON_TRANSPOSE, M, N, totalNnz, &alpha, descr, dCsrValA, dCsrRowPtrA, dCsrColIndA, dX, &beta, dY);
如果不小心直接传递了beta这个参数,APP会报错(SEGFAULT),不注意的话这个bug很不好查。除此外,当标量作为输出参数时,可以使用指针。cuSPARSE提供了cusparseSetPointMode这个API来调整是否使用指针来获取计算结果。
THE cuBLAS LIBRARY
cuBLAS也是一个线代库,不同于cuSPARSE,cuBLAS传统线代库的接口,BLAS即Basic Linear Algebra Subprograms的意思。cuBLAS level1是专门的vector之间操作。level2是矩阵和向量之间的操作。level3是矩阵和矩阵之间的操作。相对于cuSPARSE,cuBLAS不支持稀疏矩阵数据格式,他只支持而且善于稠密矩阵和向量的使用。
由于BLAS库最初是由FORTRAN语言编写,他就是用了column-major和one-based的方式存储数据,而cuSPARSE则是使用的row-major。下图是这种方式的存储格式,一看便明:
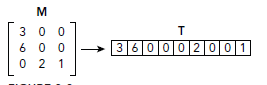
我们可以比较下row-major和column-major将二维转化为一维的过程公式:
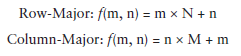
为了考虑兼容性,cuBLAS也使用了column-major的方式存储,所以,对于习惯C/C++的人来说,这可能比较让人困惑吧。
另一方面,就像C和其它语言那样,one-based索引意味着数组中第一个元素的引用使用1而不是0,也就是说,一个有N个元素的数组,其最后一个值的索引是N而不是N-1。
但是,cuBLAS没有办法决定C/C++(cuBLAS使用C/C++)编程的语境,所以他就必须使用zero-based索引,这就导致了一个奇怪的混乱情况,要满足FORTRAN的column-major,但one-based却不行。
cuBLAS提出了两个API,cuBLASASLegacy API是cuBLAS最开始的一个实现,已经废弃,当前使用cuBLAS API,二者差异很小。
看过接下来的内容,你会发现,cuBLAS的使用流程跟cuSPARSE有很多相同之处,所以对于这些库代码编写基本可以触类旁通。
Managing cuBLAS Data
相较于cuSPARSE,cuBLAS的数据格式要简单的多,所有操作都作用在稠密向量或矩阵。同样是使用cudaMalloc来分配device内存空间,但是使用cublasSetVector/cublasGetVector和cubalsSetMartix/cublasGetMartix在device和host之间传送数据(其实相对cuSPARSE也没多大差别)。本质上,这些API底层都是调用cudaMemcpy,而且,他们对Strided和unstrided数据都有很好的优化,比如下面的代码:
cublasStatus_t cublasSetMatrix(int rows, int cols, int elementSize,const void *A, int lda, void *B, int ldb);
这些参数大部分看名字就知道什么意思了,其中lda和ldb指明了源矩阵A和目的矩阵B的主维度(leading dimension),所谓主维就是矩阵的行总数,这个参数只在需要host矩阵一部分数据的时候很有用。也就是说,当需要完整的矩阵时,lda和ldb都应该是M。
如果我们使用一个稠密的二维column-major的矩阵A,其元素是单精度浮点类型,矩阵大小为MxN,则使用下面的函数传输矩阵:
cublasSetMatrix(M, N, sizeof(float), A, M, dA, M);
也可以如下传输一个只有一列的矩阵A到一个向量dV:
cublasStatus_t cublasSetVector(int n, int elemSize, const void *x, int incx,void *y, int incy);
x是host上源起始地址,y是device上目的起始地址,n是要传送数据的总数,elemSize是每个元素的大小,单位是byte,incx/incy是要传送的元素之间地址间隔,或者叫步调,传送一个单列长度M的column-major 矩阵A到向量dV如下:
cublasSetVector(M, sizeof(float), A, 1, dV, 1);
也可以如下传送一个单行的矩阵A到一个向量dV:
cublasSetVector(N, sizeof(float), A, M, dV, 1);
通过这些例子可以发现,使用cuBLAS要比cuSPARSE容易的多,所以除非我们的APP对稀疏矩阵需求比较大,一般都是用cuBLAS,保证性能的同时,还能提高开发效率。
Demonstrating cuBLAS
这部分代码主要关注cuBLAS的一些统一使用并理解他为什么易于使用。得益于GPU的高性能计算,表现要比在CPU上的BLAS号15倍,而且cuBLAS的开发也就比传统的BLAS稍微费事儿。
![]()
// Create the cuBLAS handle cublasCreate(&handle); // Allocate device memory cudaMalloc((void **)&dA, sizeof(float) * M * N); cudaMalloc((void **)&dX, sizeof(float) * N); cudaMalloc((void **)&dY, sizeof(float) * M); // Transfer inputs to the device cublasSetVector(N, sizeof(float), X, 1, dX, 1); cublasSetVector(M, sizeof(float), Y, 1, dY, 1); cublasSetMatrix(M, N, sizeof(float), A, M, dA, M); // Execute the matrix-vector multiplication cublasSgemv(handle, CUBLAS_OP_N, M, N, &alpha, dA, M, dX, 1,&beta, dY, 1); // Retrieve the output vector from the device cublasGetVector(M, sizeof(float), dY, 1, Y, 1);
![]()
使用cuBLAS比较直观,易于理解,其使用步骤基本如下:
- 使用cublasCreateHandle创建handle。
- 使用cudaMalloc分配device资源。
- 使用cublasSetVector和cublasSetMartix向device填充数据。
- 使用cublasSgemv执行矩阵和向量的乘操作。
- 使用cublasGetVector获取计算结果。
- 释放资源。
编译命令:
$ nvcc -lcublas cublas.cu
Porting from BLAS
将一个传统的C实现的APP(使用BLAS库)转化为cuBLAS也是比较直观的,基本可以归纳为以下几步:
- 增加device Memory的分配操作(cudaMalloc)和其资源释放操作。
- 增加device和host之间数据传送的过程。
- 变更BLAS的API为等价的cuBLAS API。这一步比较麻烦,这里以之前的代码为例:
![]()
// Allocate device memory cudaMalloc((void **)&dA, sizeof(float) * M * N); cudaMalloc((void **)&dX, sizeof(float) * N); cudaMalloc((void **)&dY, sizeof(float) * M); // Transfer inputs to the device cublasSetVector(N, sizeof(float), X, 1, dX, 1); cublasSetVector(M, sizeof(float), Y, 1, dY, 1); cublasSetMatrix(M, N, sizeof(float), A, M, dA, M); // Execute the matrix-vector multiplication cublasSgemv(handle, CUBLAS_OP_N, M, N, &alpha, dA, M, dX, 1,&beta, dY, 1); // Retrieve the output vector from the device cublasGetVector(M, sizeof(float), dY, 1, Y, 1);
![]()
其等价的BLAS代码是:
void cblas_sgemv(const CBLAS_ORDER order, const CBLAS_TRANSPOSE TransA,const MKL_INT M, const MKL_INT N, const float alpha, const float *A,const MKL_INT lda, const float *X, const MKL_INT incX, const float beta, float *Y,const MKL_INT incY);
二者还是有很多相似之处的,不同的是,BLAS有个order参数来使用户能够指定输入数据是row-major还是column-major。还有就是BLAS的beta和alpha没有使用引用形式,
4. 最后就是在实现功能后调节性能了,比如:
- 复用device资源而不是释放。
- device和host之间数据传输尽量减少冗余数据。
- 使用stream-based执行来实现异步传输。
Important Topics in cuBLAS Development
相较于cuSPARSE,如果大家对BLAS熟悉的话,cuBLAS更容易上手。不过需要注意的是,虽然cuBLAS的行为更容易理解,但是有时候恰恰是这份理所当然的理解会造成一些认识误区,毕竟cuBLAS并不等于BLAS。
对于大部分习惯于row-major的编程语言,使用cuBLAS就得分外小心了,我们可能很熟悉将一个row-major的多维数组展开,但是过度到column-major会有点不适应,下面的宏定义可以帮我们实现row-major到column-major的转换:
#define R2C(r, c, nrows) ((c) * (nrows) + (r))
不过,当使用上述的宏时,仍然需要一些循环的顺序问题,对于C/C++程序猿来说,会经常用下面的代码:
for (int r = 0; r < nrows; r++) {
for (int c = 0; c < ncols; c++) {
A[R2C(r, c, nrows)] = ...
}
}
代码当然没什么问题,但是却不是最优的,因为他在访问A的时候,不是线性扫描内存空间的。如果nrows非常大的话,cache命中率基本为零了。因此,我们需要下面这样的代码:
for (int c = 0; c < ncols; c++) {
for (int r = 0; r < nrows; r++) {
A[R2C(r, c, nrows)] = ...
}
}
所以,做优化要步步小心,因为一个没注意,就有可能导致很差的cache命中。