手把手带你做一个文本分类实战项目(模型+代码解读)
https://www.bilibili.com/video/BV15Z4y1S7aR/?spm_id_from=333.788.recommend_more_video.-1&vd_source=c47fbb8166930edc486d8fdc405bf569
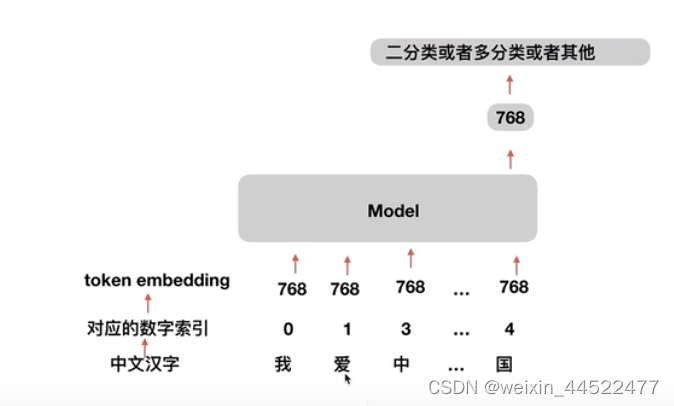
中文汉字对应的数字索引
之后对应的数字索引
之后找到tokn embedding的东西
1、模型预处理
2、模型构建
3、损失函数构建
词袋模型
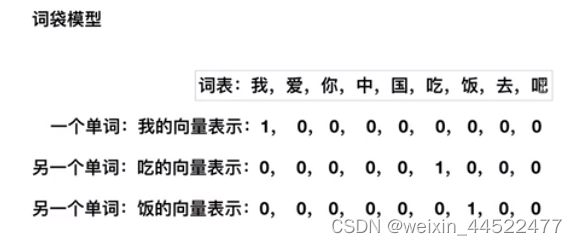
我们得到了单词的向量表示
那么我们如何得到文本的向量表示
再所有的词出现变为0
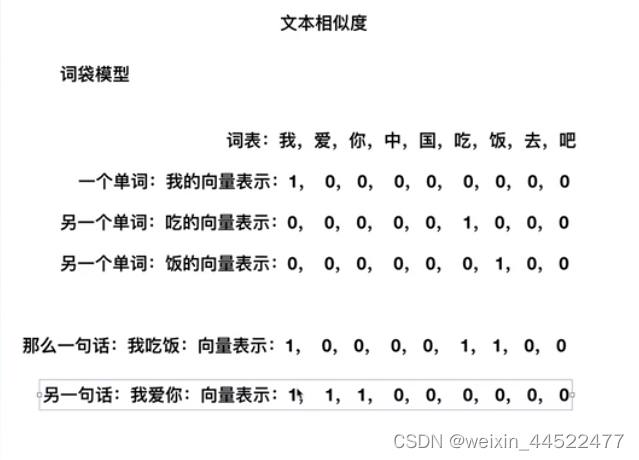
词袋模型的问题在哪里?
词袋模型也有一种表示叫做one-hot表示
我和吃,吃和饭,我和饭这两个词之间的距离是一样的,但实际上是不一样的,这个就是表达的意思是缺失的。
1、维度会很大
词表是2万个字
one-hot来表示
2、信息表达缺失
词向量:每个维度都有值,维度可控

每一个索引对应一个向量
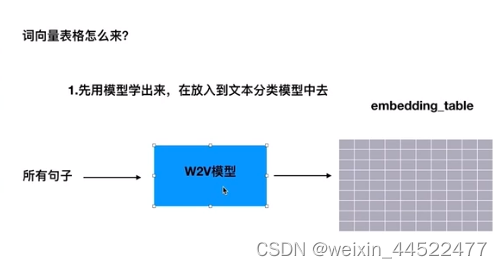
词向量表格怎么来?
(1)先用模型学出来,再放到文本分类模型中去
(2) 随机初始化,放入文本分类模型中学习
如何生成词表
最简单:从零开始给一个数字索引
但是考虑一个问题:是所有的词我都要嘛?
UNK
删掉的词再出现
线上的遇到没看到的词
PAD符号
为了方便矩阵化处理,一个batch保持一致
把所有句子最开始pad到一个长度
把一个Batch pad到一个长度,不同abtch长度可能不同
模型是为了得到一个句子的表达