一、说明
二、PYTHON 中的类继承
继承允许您定义一个新类,该新类可以访问已定义的另一个类的方法和属性。具有将被另一个类继承的方法和属性的类称为父类。能够访问父类的属性和方法的类称为子类。
萨德拉赫·皮埃尔的更多作品Python 中的函数包装器:模型运行时和调试
2.1 什么是类继承?
继承允许您定义一个新类,该新类可以访问已定义的另一个类的方法和属性。具有将被另一个类继承的方法和属性的类称为父类。您可能遇到的父类的其他名称是基类和超类。能够访问父类的属性和方法的类称为子类。子类也称为子类。除了定义从现有类继承的类之外,还可以定义从多个父类继承的子类。
2.2 如何创建子类
子类继承父类的方法和属性。子类的其他名称是子类和派生类。子类可用于通过添加新方法和属性来扩展父类的功能。它还可用于覆盖或自定义父类。
子类是通过将父类作为参数传递给子类来定义的:
Class ChildClass(ParentClass):
def __init__(self):
super().__iniit__(attribute)
def print_attribute(self):
print(“attribute inherited from Parent Class:”, self.attribute)
2.3 如何创建父类
父类具有由新子类继承的方法和属性。父类具有可以由子类覆盖或自定义的方法和属性。在Python中定义父类的方法很简单,就是定义一个带有方法和属性的类,就像通常定义一个普通的类一样。
下面,我们定义一个简单的父类示例。该init方法是存在的,就像我们对普通类一样。在该init方法中,我们定义一个类属性并在该类属性中存储一些值。然后我们定义一个名为的类方法,print_attribute该方法打印该方法中定义的属性init:
Class ParentClass:
def __init__(self, attribute):
self.attribute = attribute
def print_attribute(self):
print(Self.attribute)
2.4 继承的好处
继承非常强大,因为它允许开发人员限制代码重复。通过设计类的层次结构,您可以防止执行相同任务的重复代码行。这不仅使代码易于阅读,而且还显着提高了可维护性。例如,如果代码中有很多地方要计算模型预测的错误率,则可以将其重构为由子类继承的父类方法。
当层次类设计(继承)做得好时,它也使测试和调试变得更加容易。这是因为明确定义的任务将被本地化到代码库中的单个位置,因此当需要更改任务的完成方式时,找到需要更改的必要代码应该很简单。此外,一旦对父类中的方法进行更改,该更改就会传播到所有无关的子类。
三、Python 中类继承的示例
我们用于机器学习的许多包(例如Scikit-learn和Keras)都包含从父类继承的类。例如,线性回归、支持向量机和随机森林等类都是从称为 BaseEstimator 的父类继承的子类。基本估计器类包含大多数数据科学家应该熟悉的预测和拟合等方法。
一个更有趣的应用是通过使用多个包来定义从 Python 中的父类继承的自定义子类。例如,您可以编写一个自定义 DataFrame 类作为继承自Pandas中的 DataFrame 类的子类。同样,您可以定义一个继承自父类RandomForestClassifier的自定义分类类。
您还可以定义自定义父类和子类。例如,您可以定义指定特定类型分类模型的自定义父类和分析模型输出的子类。例如,您还可以编写父类和子类来进行模型预测数据可视化。父类可以指定分类模型的类型及其输入和输出的属性。然后,子类可以生成可视化效果(例如混淆矩阵)来分析模型输出。
对于我们的分类模型,我们将使用虚构的 Telco 流失数据集,该数据集在 Kaggle 上公开提供。该数据集在Apache 2.0 License下可以免费使用、修改和共享 。
3.1 扩展 PYTHON 包中的现有类
我们首先将流失数据读入 Pandas 数据框:
import pandas as pd
df = pd.read_csv('telco_churn.csv')接下来,让我们定义输入和输出。我们将使用 MonthlyCharges、Gender、Tenure、InternetService 和 OnlineSecurity 字段来预测流失率。让我们将分类列转换为机器可读的值:
df['gender'] = df['gender'].astype('category')
df['gender_cat'] = df['gender'].cat.codes
df['InternetService'] = df['InternetService'].astype('category')
df['InternetService_cat'] = df['InternetService'].cat.codes
df['OnlineSecurity'] = df['OnlineSecurity'].astype('category')
df['OnlineSecurity_cat'] = df['OnlineSecurity'].cat.codes
df['Churn'] = np.where(df['Churn']=='Yes', 1, 0)
cols = ['MonthlyCharges', 'tenure', 'gender_cat', 'InternetService_cat', 'OnlineSecurity_cat']接下来,让我们定义输入和输出:
from sklearn.model_selection import train_test_split
X = df[cols]
y = df['Churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)现在我们可以定义我们的自定义子类。让我们从 Scikit-learn 导入随机森林分类器并定义一个名为 CustomClassifier 的空类。CustomClassifier 将采用 RandomForestClassifier 类作为参数:
from sklearn.ensemble import RandomForestClassifier
class CustomClassifier(RandomForestClassifier):
pass test_size我们将在我们的方法中指定一个init,使我们能够指定测试和训练样本的大小。我们还将使用 super 方法来允许我们的自定义类继承随机森林类的方法和属性。这将使用任何其他自定义方法扩展父随机森林类。
from sklearn.ensemble import RandomForestClassifier
class CustomClassifier(RandomForestClassifier):
def __init__(self, test_size=0.2, **kwargs):
super().__init__(**kwargs)
self.test_size = test_size现在我们将定义一种方法来分割数据以进行训练和测试:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
class CustomClassifier(RandomForestClassifier):
def __init__(self, test_size=0.2, **kwargs):
super().__init__(**kwargs)
self.test_size = test_size
def split_data(self):
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=self.custom_param, random_state=42) 接下来,我们可以定义类的实例。我们将为我们的 传递一个值 0.2 test_size。这意味着测试集将由 20% 的数据组成,训练集将由其余 80% 的数据组成:
rf_model = CustomClassifier(0.2)
rf_model.split_data()我们可以通过打印子类的属性和方法来了解我们的子类:
print(dir(rf_model))我们将看到,通过子类,我们拥有父随机森林对象可访问的所有方法和属性:
['__abstractmethods__', '__annotations__', '__class__',
'__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__getitem__',
'__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__iter__', '__le__', '__len__', '__lt__', '__module__', '__ne__',
'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',
'__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__',
'_abc_impl', '_check_feature_names', '_check_n_features',
'_compute_oob_predictions', '_estimator_type', '_get_oob_predictions',
'_get_param_names', '_get_tags', '_make_estimator', '_more_tags',
'_repr_html_', '_repr_html_inner', '_repr_mimebundle_',
'_required_parameters', '_set_oob_score_and_attributes',
'_validate_X_predict', '_validate_data', '_validate_estimator',
'_validate_y_class_weight', 'apply', 'base_estimator', 'bootstrap',
'ccp_alpha', 'class_weight', 'criterion', 'decision_path',
'estimator_params', 'feature_importances_', 'fit', 'get_params',
'max_depth', 'max_features', 'max_leaf_nodes', 'max_samples',
'min_impurity_decrease', 'min_samples_leaf', 'min_samples_split',
'min_weight_fraction_leaf', 'n_estimators', 'n_features_', 'n_jobs',
'oob_score', 'predict', 'predict_log_proba', 'predict_proba',
'random_state', 'score', 'set_params', 'split_data', 'test_size',
'verbose', 'warm_start']为了表明我们的自定义子类实例可以访问父随机森林类的方法和属性,让我们尝试通过自定义类实例将随机森林模型拟合到我们的训练数据:
rf_model = CustomClassifier(0.2)
rf_model.split_data()
rf_model.fit(rf_model.X_train, rf_model.y_train)尽管我们正在调用属于外部类的方法,但该代码执行时没有错误。这就是Python继承的美妙之处!它允许您轻松扩展现有类的功能,无论它们是包的一部分还是自定义的。
除了方法之外,我们还可以访问随机森林分类器类属性。例如,特征重要性是随机森林分类器类的属性。让我们使用类实例访问并显示随机森林特征的重要性:
importances = dict(zip(rf_model.feature_names_in_,
rf_model.feature_importances_))
print("Feature Importances: ", importances)
这给出了以下结果:
Feature Importances: {'MonthlyCharges': 0.5192056776242303,
'tenure': 0.3435083140171441,
'gender_cat': 0.015069195786109523,
'InternetService_cat': 0.0457071535620191,
'OnlineSecurity_cat': 0.07650965901049701}软件工程的更多内容如何使用GDB
3.2 扩展自定义父类
Python 继承的另一个机器学习用例是使用子类扩展自定义父类功能。例如,我们可以定义一个训练随机森林模型的父类。然后,我们可以定义一个子类,它使用继承的测试集和预测属性生成混淆矩阵。
让我们首先定义将用于构建模型的类。对于此示例,我们将使用Seaborn库和度量模块中的混淆度量方法。我们还将训练集和测试集存储为父级的属性:
from sklearn.metrics import confusion_matrix
import seaborn as sns
class Model:
def __init__(self):
self.n_estimators = 10
self.max_depth = 10
self.y_test = y_test
self.y_train = y_train
self.X_train = X_train
self.X_test = X_test接下来,我们可以定义一个拟合方法,将随机森林分类器适合我们的训练数据:
from sklearn.metrics import confusion_matrix
import seaborn as sns
class Model:
...
def fit(self):
self.model = RandomForestClassifier(n_estimators = self.n_estimators, max_depth = self.max_depth, random_state=42)
self.model.fit(self.X_train, self.y_train)最后,我们可以定义一个返回模型预测的预测方法:
from sklearn.metrics import confusion_matrix
import seaborn as sns
class Model:
...
def predict(self):
self.y_pred = self.model.predict(X_test)
return self.y_pred现在我们可以定义我们的子类了。我们将我们的子类命名为“ModelVisulaization”。这个类将继承我们的Model类的方法和属性:
class ModelVisualization(Model):
def __init__(self):
super().__init__()我们将通过添加生成混淆矩阵的方法来扩展我们的模型类:
class ModelVisualization(Model):
def __init__(self):
super().__init__()
def generate_confusion_matrix(self):
cm = confusion_matrix(self.y_test, self.y_pred)
cm = cm / cm.astype(np.float).sum(axis=1)
sns.heatmap(cm, annot=True, cmap='Blues')现在我们可以定义子类的实例并绘制混淆矩阵:
results = ModelVisualization()
results.fit()
results.predict()
results.generate_confusion_matrix()这会生成以下内容:
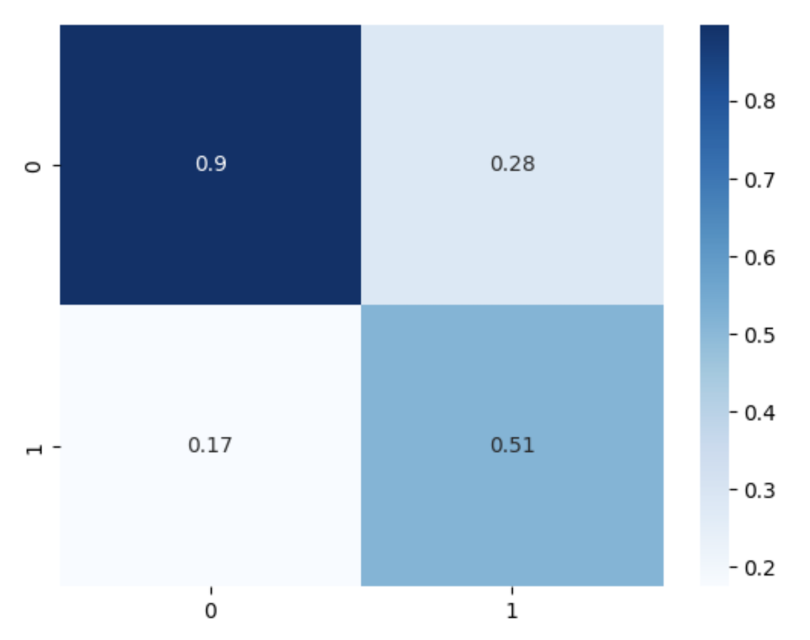
图片:屏幕截图。
显然,如何设计自定义类有一定的自由度,无论它们是现有包中的类的子类还是其他自定义父类的子类。根据您的用例,一条路线可能比另一条路线更有意义。例如,如果您只想添加少量附加属性和方法,则扩展现有类可能更合适。如果需要定制大量任务,构建定制的父类和子类会更合适。
Python 类继承对于数据科学和机器学习任务非常有用。扩展现有机器学习包中的类的功能是一个常见的用例。虽然我们在这里介绍了扩展随机森林分类器类,但您还可以扩展 Pandas 数据帧类和数据转换类的功能,例如标准缩放器和最小最大缩放器。对于数据科学家和机器学习工程师来说,大致了解如何使用 Python 继承来扩展现有类非常有价值。
此外,在某些情况下,属于不同工作流程的许多任务需要自定义。我们考虑了扩展自定义类的示例,我们使用该类来构建具有可视化功能的分类模型。这允许我们继承建模类的方法和属性,并在子类中生成可视化。
这篇文章中的代码可以在 GitHub上找到。





![[答疑]QQ泡妞序列图上的参数名称对吗?](https://img-blog.csdnimg.cn/img_convert/7a9fe492b4cc5e28aa371804762bb218.png)
