目录
- 一、基于场景图的文本生成图像
- 二、基于对话的文本生成图像
- 三、基于属性驱动的文本生成图像
- 四、基于边界框标注的文本生成图像
- 五、基于关键点的文本生成图像
- 六、其他基于辅助信息的文本生成图像
在传统的T2I方法中,常常使用一个固定的随机噪声向量作为输入,然后通过生成器网络来生成图片。而条件变量增强的T2I方法则通过引入额外的条件信息来生成更具特定要求的图片,
这个条件信息可以是任何与图片相关的文本信息,比如图片的描述、标签或者语义向量。
一、基于场景图的文本生成图像
基于场景图的文本生成图像方法是一种利用场景图信息来生成图像的图像生成方法。在这个方法中,场景图是用来描述场景中对象之间关系和属性的图形化表示,包括物体、属性、关系等,基于场景图的文本生成图像方法一般分为两步:
- 利用场景图生成物体区域:首先,将场景图中的物体和关系映射到图像的像素空间中。这可以通过使用先进的物体检测、语义分割和关系推理技术实现。通过这个过程,可以获得每个物体的位置、尺寸以及每个物体和其他物体之间的关系。
- 根据区域生成图像:在第一步中获得物体区域后,可以使用图像生成模型(如生成对抗网络、变分自编码器等)来生成新的图像。因为物体区域已经确定,所以生成的图像会更加准确地反映场景图中物体和关系的特征。生成的图像有时可能需要一些后处理,例如重建场景和合成物体,来使它们看起来更加自然真实。

在学术上,Johnson 等人跳出了文本描述指导图像生成的限制,提出了 Sg2im模型,该模型使用场景图(Scene graph)对文本对象及其关系进行建模,通过预测每个对象的边界框和分割掩模来计算场景布局。单独的对象框和掩模经过组合形成场景布局,随后被级联优化网络[57]用于生成图像。
该模型主要由两个模型组成:
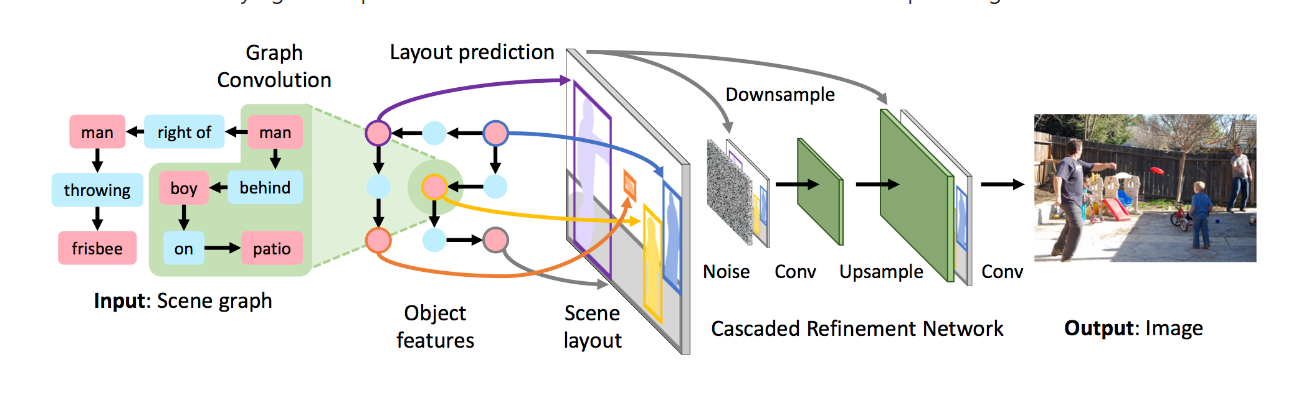
- 图像生成模型:以包含对象和对象间关系的场景图作为模型输入,经过图卷积网络 (GCN)进行处理,GCN 沿场景图的边进行计算得到对象的嵌入向量。将这些向量传入物 体布局预测网络(Object layout network)得到预测对象的边界框(Bounding boxes)和语义 掩膜(Segmentation masks),然后将两者结合得到预测对象的布局,再将所有对象布局结 合就可以得到场景布局(Scene layout),最后将场景布局输入到细化级联网络(CRN)中即 可得到图像。该生成模型使用同一对判别器模型进行对抗训练。
- 一对判别器模型 D i D_i Di和 D o D_o Do: D i D_i Di是图像判别器,用来鉴别生成图像的整体外观是否真实; D o D_o Do是对象判别器,用来鉴别图像中的每个对象是否真实,输入的是对象的像素,利用双线性插值裁剪像素,并缩放至固定的大小。 D o D_o Do不仅能够预测图中对象的分类是否正确,还确保了对象可以通过预测对象类别的辅助分类器进行识别。
Li 等人在 2019 年也提出了场景图到图像的生成模型PasteGAN,该模型的训练过程包括两个分支,一个是利用外部存储器中检索切片生成多样化的图像,另一个分支是利用原始切片重构真实图像。
首先利用图卷积网络对场景图进行处理,得到包含每个对象上下文信息的潜在向量,用于预测对象的位置,并通过切片选择器在外部存储器中检索最匹配的上下文对象切片,然后切片编码器来处理对象切片用来编码其视觉外观。然后将其特征映射和谓词向量一同输入到分类其中,并将该成对特征合并到视觉特征中,然后通过对象图像融合得到场景画布。另一个潜在画布则是通过使用切片沿重建路径进行构造得到的。最后,图像解码器重构真实图像并基于两个潜在画布生成新图像。该模型同样包含一对𝐷𝑖和𝐷𝑜判别器进行端到端训练。
二、基于对话的文本生成图像
基于对话的文本生成图像是一种通过对话信息来指导图像生成的方法。在这种方法中,对话信息中的文本内容用于描述所需生成的图像,图像生成模型则根据对话信息生成相应的图像。
具体地说,基于对话的文本生成图像方法通常包括以下几个步骤:
- 对话信息准备:首先,需要准备对话信息,这可以是用户与系统的交互对话,其中用户通过文本描述了所需生成的图像内容。
- 特征提取:从对话中提取有关图像内容的特征,例如物体的种类、属性、状态,场景的背景、时间、情绪等。这一步可以通过自然语言处理方法来分析和提取相关特征。
- 图像生成:利用图像生成模型根据提取出的对话特征生成相应的图像。生成模型可以将对话特征作为条件输入,以确保生成的图像符合对话信息的要求。
- 输出图像:生成模型生成图像后,可以将其输出为可视化的图像结果。
Sharma 等人提出了ChatPainer 来利用对话数据。作者使用 Visual Dialog 数据集,每个对话由 10 个问答对话组成,并将其与 COCO 标题配对。作者用递归和非递归编码器进行了实验,结果表明递归编码器性能更好。
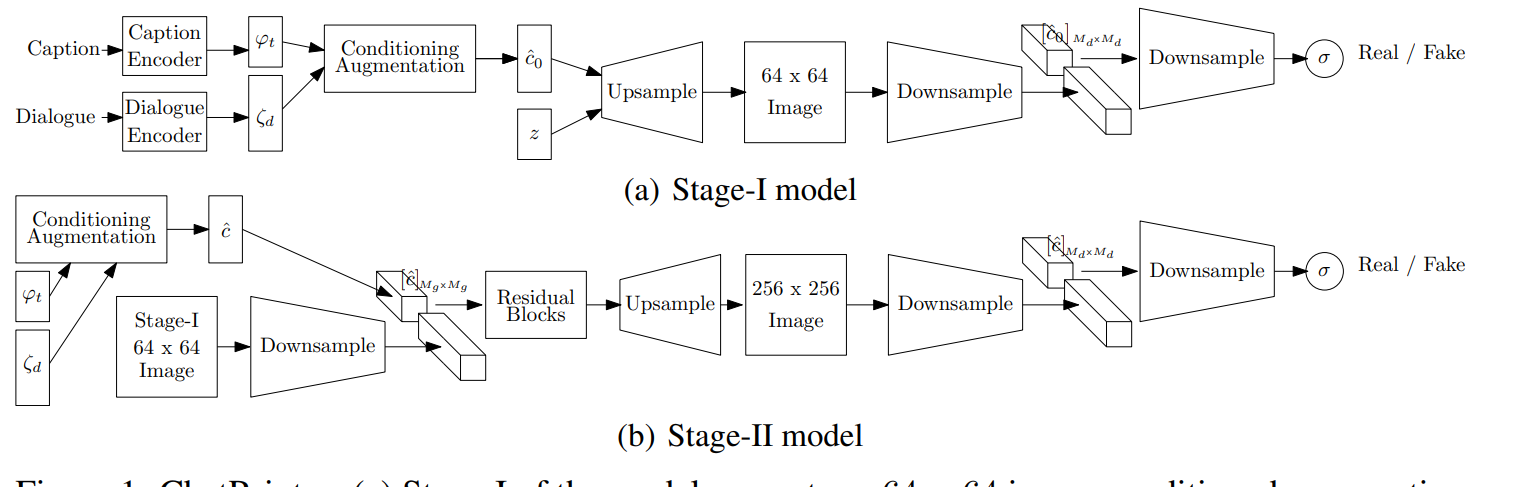
Niu 等人建议以局部相关文本为条件来生成图像,即局部图像区域或对象的描述,而不是整个图像的描述,提出 VAQ-GAN。VAQ-GAN 使用 VQA 2.0数据集中的问答(Questions and Answers, QA)对作为局部相关文本信息来生成图像,它包含三个关键模块:层次 QA 编码器、QA 条件 GAN 和外部 VQA 损失。
层次QA 编码器将 QA 对作为输入,以产生全局和局部表示;QA 条件 GAN 从层次 QA编码器获得表示并生成图像;外部 VQA 损失通过与训练一个 VQA 模型实现以增强 QA 对和生成图像的一致性。这些模块有助于有效地利用新的输入,实验证明了该模型的有效性。
Frolov 等人提出在不改变网络结构的情况下利用 VQA 数据的方法。通过简单地拼接 QA 对,并将它们用作额外的训练样本,辅助以外部 VQA 损失,可以有效提高图像质量和图像-文本对齐度。与 VAQ-GAN相比,这是一种简单而有效的技术,可以应用于任意 T2I 模型。

三、基于属性驱动的文本生成图像
基于属性控制的文本生成图像是一种基于属性描述生成图像的图像生成方法。在这个方法中,首先通过属性描述来指定所需生成的图像的属性,然后通过图像生成模型来生成符合指定属性的图像。具体来说,基于属性控制的文本生成图像方法一般包括以下几个步骤:
- 属性定义:定义属性集合,包括所需生成图像的属性,如颜色、形状、大小、纹理等。
- 属性编码:将属性信息编码,并将其输入到图像生成模型中。例如,可以使用向量编码或矩阵编码来对每个属性进行编码表示。
- 生成图像:根据编码后的属性信息,使用图像生成模型来生成符合所需属性的图像。
- 调整属性:如果生成的图像不完全符合预期属性,可以调整属性编码,然后再次生成图像,直到生成的图像符合预期属性

在一句话中直接利用有限的信息会遗漏一些关键的属性描述,而这些属性描述是准确描述图像的关键因素,基于此,Adma-GAN提出了一种有效的带有属性信息补充的文本生成图像方法,主要包括以下创新点:
- 构造属性存储库,首先收集数据集中所有可能的属性描述作为属性库,并将它们转换为属性内存,然后提取属性的标签组合形成公共属性库,具体来说,作者构造了一个图来表示数据集中的属性相关性,并使用图卷积网络来提取属性特征,获得用于属性驱动条件生成的最佳属性内存。
- 设计了一种属性-句子联合条件生成器学习方案,用于处理多种表示(即句子、属性、图像)之间的转换,使用对比学习增强多个表示之间的语义一致性。在公共空间将图像与句子和属性对齐,属于同一样本的属性图像和句子图像对被拉得更近,而不同样本的对被推得更远。

四、基于边界框标注的文本生成图像
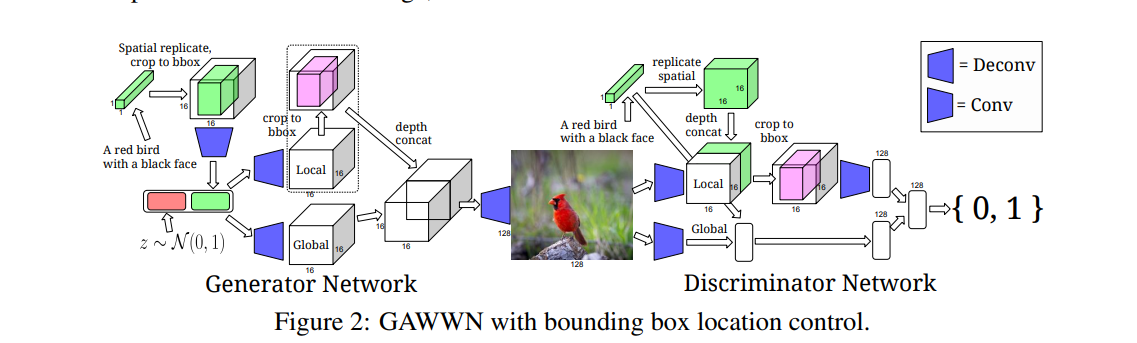
基于边界框的文本生成图像是一种根据边界框信息生成图像的方法。在这种方法中,通过提供物体的边界框坐标信息,图像生成模型可以生成符合指定边界框的图像。具体来说,基于边界框的文本生成图像方法一般包括以下几个步骤:
- 边界框定义:首先,需要定义边界框的位置和大小,可以通过指定物体的左上角和右下角坐标、中心点和宽高等方式来定义。边界框可以用于指定想要生成的物体或物体的位置。
- 图像生成模型:选择合适的图像生成模型将边界框信息作为输入条件或约束,以生成对应的图像。
- 图像生成:通过图像生成模型生成图像,并确保生成的图像符合边界框的要求。生成模型会根据输入的边界框信息,学习并生成相应的图像内容。
- 调整边界框:如果生成的图像在边界框内部不完全符合预期特征,可以调整边界框的位置或尺寸,然后重新生成图像。
五、基于关键点的文本生成图像
与边界框稍有不同,基于关键点的文本生成图像是一种根据给定的关键点信息生成图像的方法。关键点通常是指图像中重要物体或人脸部位的位置坐标,如人脸的眼睛、鼻子、嘴巴等。通过使用这些关键点信息,图像生成模型可以生成符合描述的真实图像。
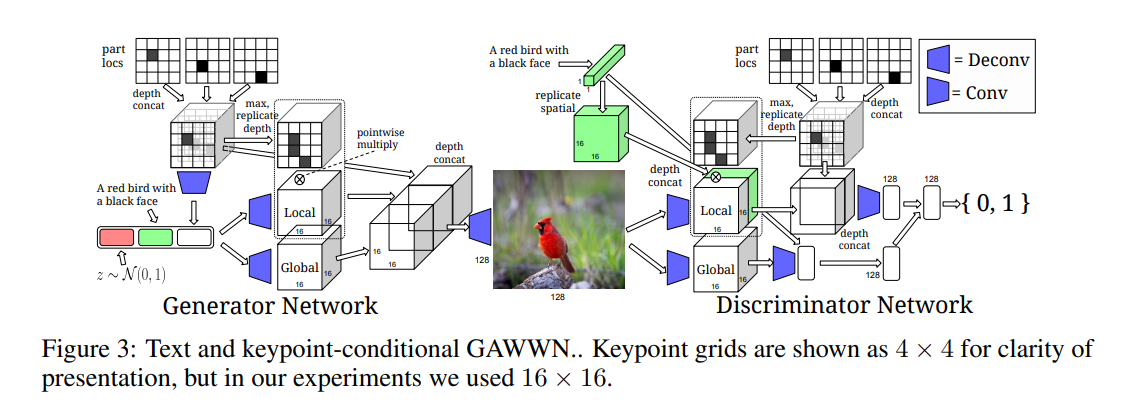
基于关键点的文本生成图像核心点在于需要明确定义关键点的数量和类型。关键点可以是预定义的或自定义的,取决于具体的任务要求,例如人脸识别中的眼睛和嘴巴等,其次将关键点的坐标信息编码成合适的向量或矩阵表示,作为输入条件输入到图像生成模型中。基于关键点的文本生成图像方法可以应用于人脸图像合成、姿态生成、人物动画等领域。通过提供精确的关键点信息,实现更精确和个性化的图像生成。
六、其他基于辅助信息的文本生成图像
除了上述提到的之外,还有很多模型在做文本生成图像任务时,引入条件变量或者说辅助信息额外帮助模型生成图像,比如草图、多标题、短文本、风格、噪声等等:
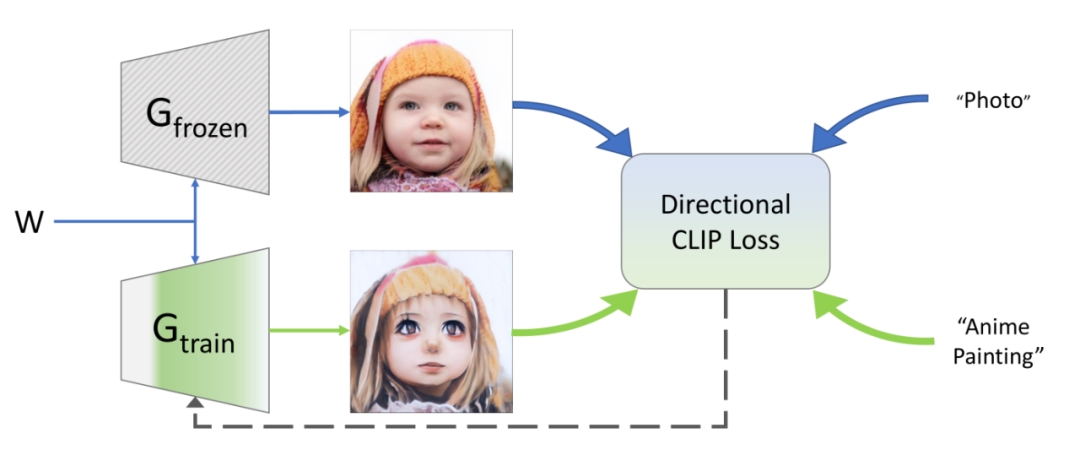
风格迁移:风格迁移是一种常见的基于辅助信息的图像生成方法。它通过将输入文本描述和一个特定风格图像进行输入,借助卷积神经网络等技术实现将输入图像的内容与指定风格的图像的风格进行融合,生成新的图像。这种方法可以用于创造具有不同绘画风格的图像,如梵高风格、毕加索风格等。
噪声扰动:通过向生成模型输入合适的噪声向量,算法可以控制生成图像的整体风格和样式。例如,在文本生成图像任务中,可以通过调整噪声向量的不同分量来控制生成图像的颜色、纹理等特征。


![[答疑]QQ泡妞序列图上的参数名称对吗?](https://img-blog.csdnimg.cn/img_convert/7a9fe492b4cc5e28aa371804762bb218.png)