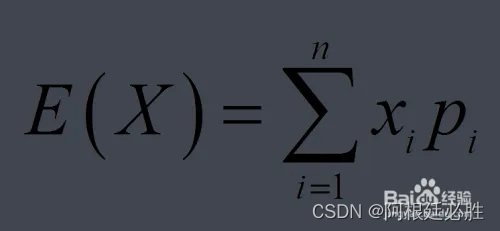基于Django开发的图书管理推荐、电影推荐、课程推荐系统、大众点评店铺推荐系统、健身课程管理系统、资讯推荐系统
一、简介
推荐系统的目的是信息过载所采用的措施,面对海量的数据,从中快速推荐出用户可能喜欢的物品。
推荐系统的方法有以下几种:
1、基于物品协同过滤,即利用物品与用户的特征信息,给用户推荐那些具有用户喜欢的特征的物品(基于用户行为数据,例如点击、浏览、收藏、购买、评论等);
2、基于用户协同过滤,即利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品(基于用户信息例如:个人信息,喜好标签,上下文信息);
3、基于机器学习协同过滤,即把用户注册时选择的类型分成不同的聚类,然后新用户注册时根据选择的类型归类,再把该类型的典型物品推荐给新用户。
简单概括:知你所想,物以类聚,人以群分。
二、Demo
1、图书管理系统
可参考网站,点我跳转

2、电影推荐系统
可参考网站,点我跳转

3、课程推荐系统
可参考网站,点我跳转

三、实现流程
1、搭建开发环境
这个环节包括创建虚拟环境、创建Django项目、创建数据库、设计表模型、爬取数据、UI界面功能。
2、创建虚拟环境
python解释器使用3.7,MySQL使用5.7,Django使用3版本以上,前端采用Django后端渲染,后台管理使用xadmin版本3。
常用命令:
python -m venv book_manager
django-admin startproject book_manager
python manage.py startapp book
python manage.py makemigrations
python manage.py migrate
python manage.py createcachetable
python manage.py collectstatic
python manage.py createsuperuser
python manage.py runserver
创建数据库使用图形化工具Navicat,字符集使用utf8mb4:

3、表(模型)设计
常用的表有:用户表、图书表、标签表、用户选择类型表、借阅表、购物车、评分表、收藏表、点赞表、评论表、评论点赞表、搜索关键字表。

4、获取数据
获取数据可以通过爬虫实现,比如图书管理系统,先到网上找一个图书网站,分析每个页面的特征,然后编程把图书爬下来,
1)基础页面
2)获取各类别url
3)获取总页数
4)获取具体数据
5)保存图片、保存数据
代码示例:
import json
import time
import urllib.request, urllib.error # 制定url,获取网页数据
from bs4 import BeautifulSoup # 网页解析,获取数据
from fake_useragent import UserAgent # 随机请求头
# URL的网页内容
def ask_url(url): # 模拟浏览器头部信息,向服务器发送消息
count = 0
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"
} # 用户代理:表示告诉目标服务器,我们是什么类型的机器;浏览器:本质上告诉服务器,我们能够接收什么水平的内容
while count < 10:
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request, timeout=20) # 传递封装好的request对象,包含所访问的网址和头部信息
html = response.read().decode("utf-8")
return html
except Exception as e:
print('第{}次请求报错'.format(count), e)
head = {"User-Agent": UserAgent().random}
count += 1
return
def save_img(url, name):
# 保存图片
filename = 'media/book_cover/{}.jpg'.format(name)
count = 0
head = {
"Content-type": "application/x-www-form-urlencoded",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36",
}
while count < 10:
try:
request = urllib.request.Request(url, headers=head)
response = urllib.request.urlopen(request, timeout=10)
with open(filename, 'wb') as f:
f.write(response.read())
return True
except Exception as e:
print('第{}次爬取【{}】图片出错'.format(count, name), e)
head = {"User-Agent": UserAgent().random}
count += 1
return False
def save_txt(data):
# 保存为txt文件
with open('book.txt', 'a') as f:
f.write(json.dumps(data))
f.write('\r\n')
def read_txt():
# 读取txt文件
data_list = []
with open('book.txt', 'r') as f:
for data in f.readlines():
if data != '\n' and data not in data_list:
data_list.append(json.loads(data))
return data_list
def get_data(url):
# 获取数据
# print('url',url)
html = ask_url(url)
if not html:
return
soup = BeautifulSoup(html, "html.parser")
d_dict = {}
div = soup.find('div', id='book_info')
if not div:
return {}
d_dict['标题'] = div.find('h2').text
content = div.find('div', class_='intro')
text = ''
ps = content.find_all('p')
for p in ps:
text += '<p>'
text += p.text
text += '</p>'
d_dict['内容'] = text.replace('\xa0', '')
# 获取作者、翻译、标签
infos = div.find_all('h4')
author = ''
for info in infos:
key = info.text.split(':')[0]
values = []
for a in info.find_all('a'):
if key == '标签' and a.text == author:
continue
values.append(a.text)
if key == '作者' and values:
author = values[0]
d_dict[key] = values
time.sleep(0.5)
return d_dict
def get_pages(url):
# 获取总页数
html = ask_url(url)
if not html:
return
soup = BeautifulSoup(html, "html.parser")
# 获取总页数
for a in soup.find_all('a', class_='other'):
if a.text == '尾页':
pages = int(a.attrs['href'].split('page=')[1])
print('总页数', pages)
return pages
return 1
def get_page_urls(url):
# 获取每一页中各图书的url
html = ask_url(url)
if not html:
return
soup = BeautifulSoup(html, "html.parser")
urls = []
ul = soup.find('ul', id='list_box').find_all('li')
if not ul:
return []
for li in ul:
url = li.find('a', class_='Aimg').attrs['href']
img = 'http:{}'.format(li.find('img').attrs['src'])
code = url.split('book')[1].replace('/', '').replace('index.htm', '')
save_img(img, code) # 保存图片
urls.append([url, code])
time.sleep(0.4)
return urls
def get_type_urls(url):
# 获取各类别url
html = ask_url(url) # 获取页面
if not html:
return
soup = BeautifulSoup(html, "html.parser")
ul = soup.find('ul', class_='type_box').find_all('li') # 查找类元素为type_box的ul标签
urls = {}
for li in ul:
# 通过正则匹配获取所有li标签中的href值
urls[li.text.replace('\n', '').replace('\t', '')] = li.a.attrs['href']
time.sleep(0.5)
return urls
def get_all_data(baseurl):
# 获取页面图书url
d_list = []
# 获取各类别的url
urls = get_type_urls(baseurl)
if not urls:
return
time.sleep(1)
count = 1
for name, url in urls.items():
print('爬取 {} 的数据'.format(name))
time.sleep(0.5)
pages = get_pages(url) + 1
if not pages:
continue
for page in range(1, pages):
time.sleep(0.5)
page_url = '{}&page={}'.format(url, page)
book_urls = get_page_urls(page_url) # 获取类别下的图书url
if not book_urls:
continue
for pu in book_urls:
time.sleep(0.2)
d_dict = get_data(pu[0])
if not d_dict:
continue
d_dict['code'] = pu[1]
save_txt(d_dict) # 保存数据
print('第{}本'.format(count), d_dict)
count += 1
d_list.append(d_dict)
time.sleep(0.5)
return d_list
def main(baseurl):
'''
:param baseurl:
:return:
'''
get_all_data(baseurl)
if __name__ == '__main__':
# 爬取的页面地址
baseurl = '基础页面'
main(baseurl)
5、UI界面功能
登录:

人脸识别登录:

注册:

首页、新书速递、热门书籍、图书分类、猜你喜欢:

购物车:

个人中心:

数据分析:

协同算法图像对比:

6、后台管理
使用xadmin库对数据进行后台管理,界面如下:

四、后记
总体上,一个推荐系统就开发出来了,整个开发过程中收获还是很多的,使用到的知识点也是很多,对django、爬虫、图表、推荐算法都能够熟练掌握。